![]()
在数据驱动的时代,我们每天都在产生大量数据:购物记录、健康信息、社交关系......这些数据蕴含巨大价值,但也伴随着隐私泄露的风险。
试想一下:
- 医院希望联合研究某种疾病,但患者数据无法直接共享。
- 银行想合作分析反欺诈信息,但客户隐私数据必须严格保护。
- AI 公司需要使用大量用户数据训练模型,但用户对自己数据的使用方式几乎无法控制。
传统的数据共享方式就像在数据世界里「裸奔」,风险巨大。那么,有没有一种方法能在保护隐私的前提下实现数据的价值共享呢?隐私计算技术应运而生,它能让数据在加密状态下完成计算,真正做到「数据可用不可见」。
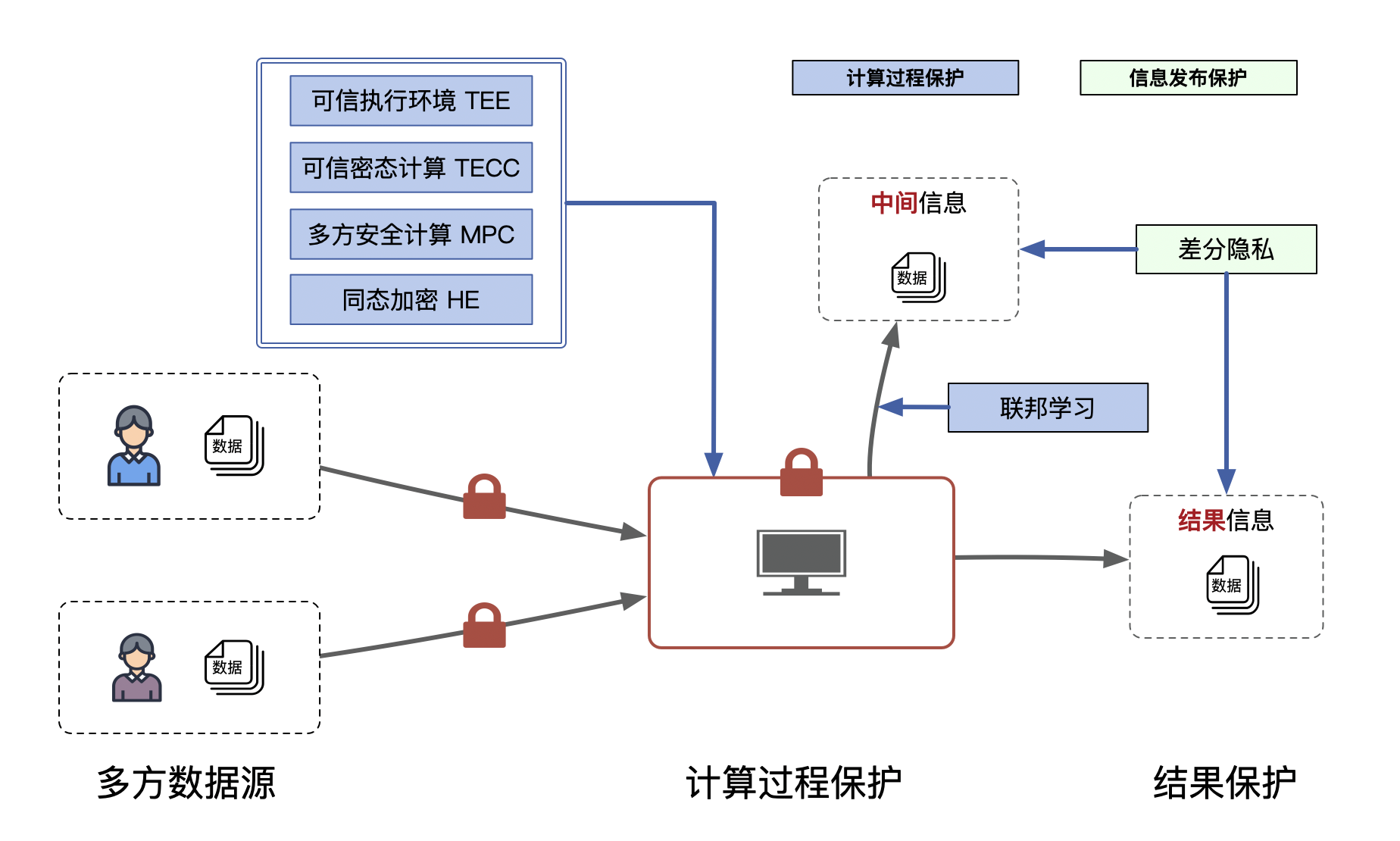
一、为什么要关注隐私计算?
![]()
隐私计算的兴起主要源于两个趋势:
- 法规严格:欧盟《通用数据保护条例》(GDPR)、中国《数据安全法》《个人信息保护法》等法规都对数据隐私提出了严格要求;
- 业务诉求紧迫:数据孤岛现象阻碍了各个行业创新突破,隐私计算成为平衡隐私安全与数据价值的桥梁。
到了 2025 年,随着生成式 AI 的普及,「AI 生成内容的归属权」已成为数据隐私领域的焦点问题。当企业利用用户数据训练 AI 模型时,谁拥有最终生成内容的权利?数据提供者如何确保自己的隐私不被侵犯?
面对这些挑战,今天我们将介绍一款当前非常流行且易用的隐私计算框架------SecretFlow(隐语),它能让数据在加密状态下完成计算,真正实现"可用不可见"的隐私保护理念。
![]()
GitHub 地址:github.com/secretflow/secretflow
最令人惊喜的是,只要你会 Python 就能通过 SecretFlow(隐语)快速上手这一前沿技术。本教程将带你一步步体验隐私计算的神奇与乐趣,让你在数据安全与价值之间找到完美平衡点!
接下来,让我们开始 SecretFlow 的奇妙之旅吧!
二、SecretFlow 是什么?
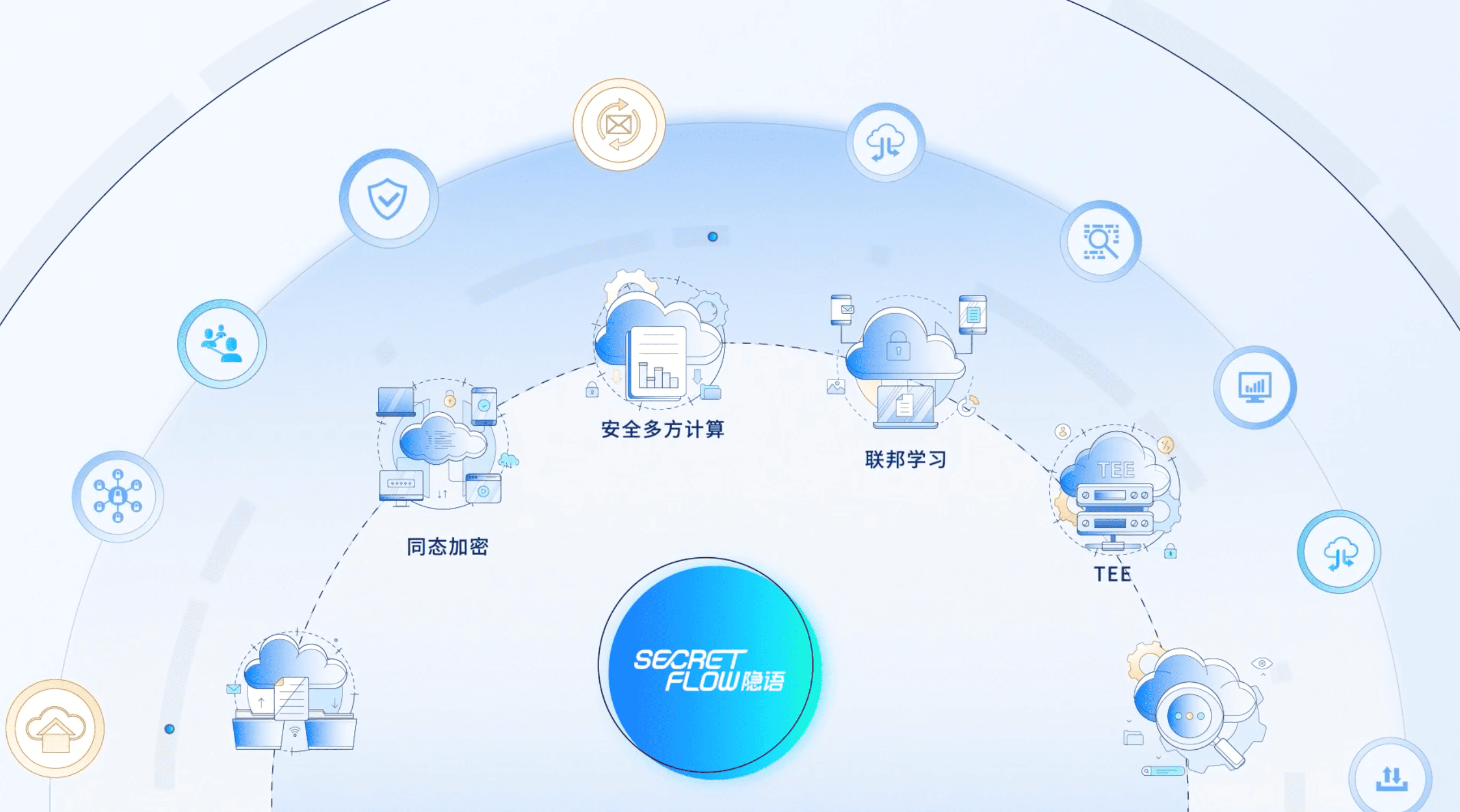
SecretFlow 是由蚂蚁密算团队开源的可信隐私计算框架,它就像数据世界的"安全卫士",让数据在不暴露具体内容的情况下安全地进行计算和分析。有了 SecretFlow,不同机构可以像「戴着眼罩一起玩游戏」,既能高效地协作完成任务,又不会泄露各自数据。
![]()
2.1 优势
- 统一集成,一站式搞定:内置安全多方计算、联邦学习、差分隐私等主流隐私计算技术,无需再单独学习多个框架。
- 原生易用,零门槛上手:支持 SQL、Python 和 AI 等开发接口,用户可以快速上手减少学习成本。
- 灵活拓展,积木式架构:模块化设计,方便根据业务需求自由扩展和组合,快速迭代轻松应对业务变化。
- 高性能,经过大规模数据验证:在金融、医疗等实际场景中经过验证,处理数十亿级数据稳稳当当,性能优越可靠。
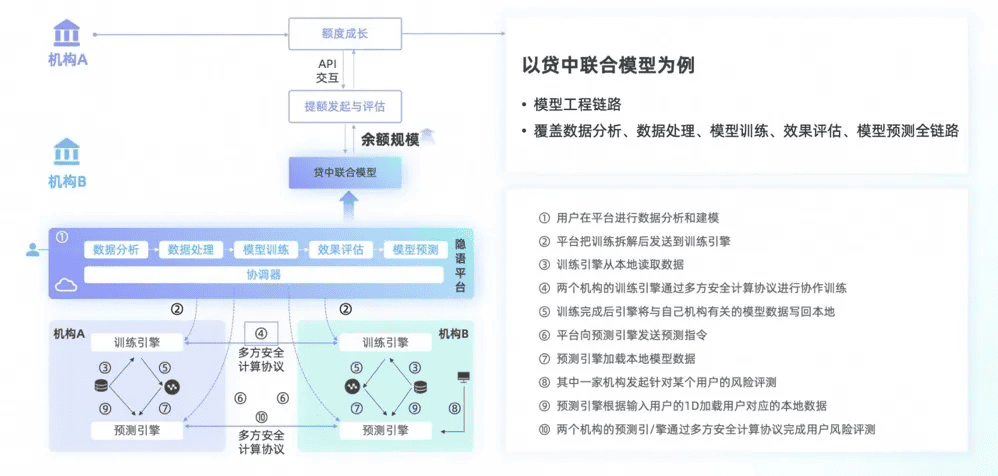
2.2 典型应用场景
![]()
- 医疗研究:医院可以使用 SecretFlow 进行联合研究,不需要共享患者的原始数据,即可进行数据分析,保护患者隐私。
- 金融反欺诈:银行可以合作分析反欺诈信息,使用 SecretFlow 确保客户的隐私数据不被暴露。
- 跨公司合作:多个企业可以在不暴露各自数据的前提下,通过 SecretFlow 进行联合数据分析,提升业务合作的效率和安全性。
- AI 模型训练:AI 公司可以利用 SecretFlow 在保护用户隐私的前提下,使用大量用户数据训练模型,保证用户数据的安全。
三、快速上手:你的第一个 SecretFlow 程序
要体验 SecretFlow 很简单,官方提供 Docker 镜像,包含完整依赖直接启动即可使用。
3.1 安装步骤
你可以选择完整版本或 lite 版本(不包含深度学习)。
# 完整版本
docker run -it secretflow/secretflow-anolis8:latest
# Lite 版本(更小巧)
docker run -it secretflow/secretflow-lite-anolis8:latest
3.2 安全多方计算从零到一
我们用一个简单的例子「安全多方计算」来实际体验一下 SecretFlow,如何实现数据的「可用不可见」。
什么是安全多方计算?
安全多方计算(Secure Multi-Party Computation,MPC)是一种密码学技术,允许多个参与方在保护隐私的情况下,共同完成计算任务。
举个例子:
Alice、Bob 和 Carol 想知道他们三人的平均收入,但又不想泄露各自的收入数额。安全多方计算可以让他们输入各自数据后,仅输出最终平均值,而不暴露任何人的具体收入。
我们后续会用到几个概念:
- 参与方(Party):拥有数据并参与计算的实体;
- 计算协议(Protocol):确保数据安全计算的规则;
- 秘密共享(Secret Sharing):将敏感数据拆分为多个碎片,单个碎片无法还原原始数据,只有足够多碎片组合才能还原。
3.3 快速体验:使用 SecretFlow 安全计算三人收入平均值
前面我们介绍了安全多方计算(MPC)的基本概念。接下来,我们以一个具体实例来展示 SecretFlow 如何让多个参与方安全计算数据的平均值,而不暴露任何人的具体收入数据。
场景回顾
Alice、Bob 和 Carol 想计算他们三个人的平均收入,但又不想让彼此知道各自具体的收入。这是典型的安全多方计算应用场景。
第一步:初始化隐私计算环境(创建参与方集群)
首先,我们创建一个本地模拟环境,包含三个参与方:Alice、Bob 和 Carol。
import secretflow as sf
# 初始化 SecretFlow 本地模拟环境,包含三个参与方
sf.init(
parties={'Alice', 'Bob', 'Carol'},
address='local'
)
第二步:为每个参与方创建隐私计算设备(PYU 设备)
每个参与方都会使用专属的计算设备来保存自己的数据。我们分别为 Alice、Bob 和 Carol 创建设备:
alice = sf.PYU('Alice')
bob = sf.PYU('Bob')
carol = sf.PYU('Carol')
第三步:各参与方安全地输入自己的收入数据
为保护隐私,每个参与方通过自己的设备输入各自的收入数据:
# 假设 Alice、Bob 和 Carol 的收入分别是 5000、6000 和 7000
alice_income = alice(lambda: 5000)()
bob_income = bob(lambda: 6000)()
carol_income = carol(lambda: 7000)()
注意:
- 每个参与方的数据只存在于自己的专属设备内。
- 其他参与方无法直接访问到这份数据。
第四步:使用安全多方计算协议,计算收入平均值
我们使用 SecretFlow 提供的安全计算协议(例如 SPU 设备)来安全地计算三个人的平均收入:
# 创建一个安全计算设备(SPU),用于多方安全计算
spu = sf.SPU(sf.utils.testing.cluster_def(['Alice', 'Bob', 'Carol']))
# 将三人的收入数据安全地汇总到 SPU 设备,并计算平均值
average_income = spu(lambda x, y, z: (x + y + z) / 3)(alice_income, bob_income, carol_income)
在此过程中:
- Alice、Bob 和 Carol 的收入数据以加密或秘密共享的形式送入 SPU 设备。
- SPU 设备安全地完成计算,参与方无法访问彼此的原始数据。
第五步:安全地查看计算结果(平均收入)
直接打印结果会看到一个加密后的对象:
print(average_income)
# 输出示例:<SPUObject object at 0x7fdec24a15b0>
此时数据仍处于加密状态,我们需要使用 sf.reveal 方法安全地解密并查看结果:
# 安全地解密并查看结果
print("三人收入的平均值是:", sf.reveal(average_income))
# 输出:三人收入的平均值是: 6000.0
# 即 (5000+6000+7000)/3 = 6000
小结
通过本实例,我们完整体验了 SecretFlow 如何在保护数据隐私的前提下实现安全多方计算。每位参与方输入了自己的敏感数据,却不会暴露给其他人,最终大家都得到了想要的计算结果(平均收入),真正实现了数据「可用不可见」。
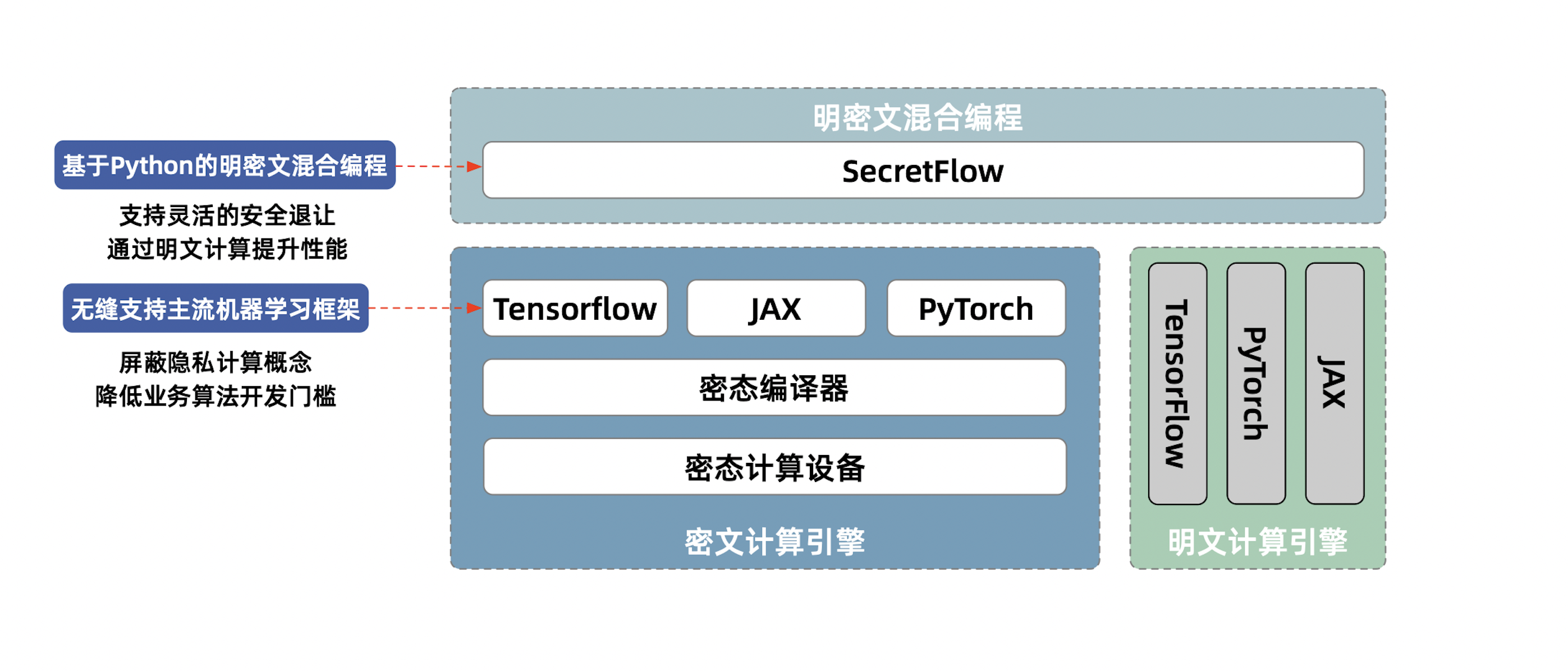
四、技术架构
![]()
SecretFlow 通过以下几个层次来实现隐私保护的数据分析和机器学习:
- 抽象设备层:由普通设备和秘密设备组成,秘密设备封装了各种加密协议。
- 设备流层:将更高层次的算法建模为设备对象流和DAG。
- 算法层:用于处理水平或垂直分区数据进行数据分析和机器学习。
- 工作流层:无缝集成数据处理、模型训练和超参数调整。
此外,SecretFlow 还关联了多个相关项目,如 Kuscia(一个轻量级隐私保护计算任务编排框架)、SCQL(一个允许多个不信任方联合分析的系统)、SPU(一个提供计算能力并保护私有数据的安全计算设备)、HEU(一个高性能同态加密算法库)和 YACL(一个包含密码学、网络和 IO 模块的 C++ 库)。
我们可以把 SecretFlow 想象成一座数字化的「智能工厂」:
- 数据全程加密保护:数据就像工厂的贵重原料,从进入工厂就被锁入保险柜(全程加密),计算时决不泄露。
- 安全高效跨团队合作:不同机构好比不同车间工人,彼此协作却不暴露原始数据。
- 高效计算不卡顿:工厂拥有高效自动化设备(高性能计算引擎),处理数据又快又稳。
- 灵活扩展适应需求:模块化设计,像乐高积木般灵活拼装,快速适应各种行业和需求。
五、最后
由于篇幅有限,上面的内容仅介绍了 SecretFlow(隐语)的冰山一角。它不仅让上手隐私计算变得简单,也让数据安全不再成为数据价值释放的阻碍。无论你是开发者、研究人员还是数据分析师,SecretFlow 都能助你轻松开启隐私计算之旅。
GitHub 地址:github.com/secretflow/secretflow
如果你想进一步了解更多 SecretFlow 实践案例和高级用法,欢迎访问官方开源社区参与讨论、贡献代码,一起为开源贡献力量吧!