为什么要保障数据质量?
在数据加工链路中,如何确保高质量的数据产出是一个一直需要重点解决的问题。因为一旦数据加工链路中,出现了数据质量问题,轻则数据报表给出不靠谱的业务分析,影响业务决策;重则向用户推送数据错误,严重降低产品用户对产品的信心,甚至失去重要产品客户。根据Gartner的研究报告,“企业每年因低劣的数据质量而蒙受的平均损失高达1290万美元。”(参见Manasi Sakpal于2021年7月14日发布的《如何改进您的数据质量》一文,https://www.gartner.com/cn/information-technology/articles/how-to-improve-your-data-quality-cn)。尤其2022年下半年以来,随着ChatGPT的大规模推广,在全世界范围内掀起了有史以来最大的AI浪潮,高质量的数据诉求变得前所未见的高涨,那句“Garbage in,Garbage out”也变得人尽皆知。
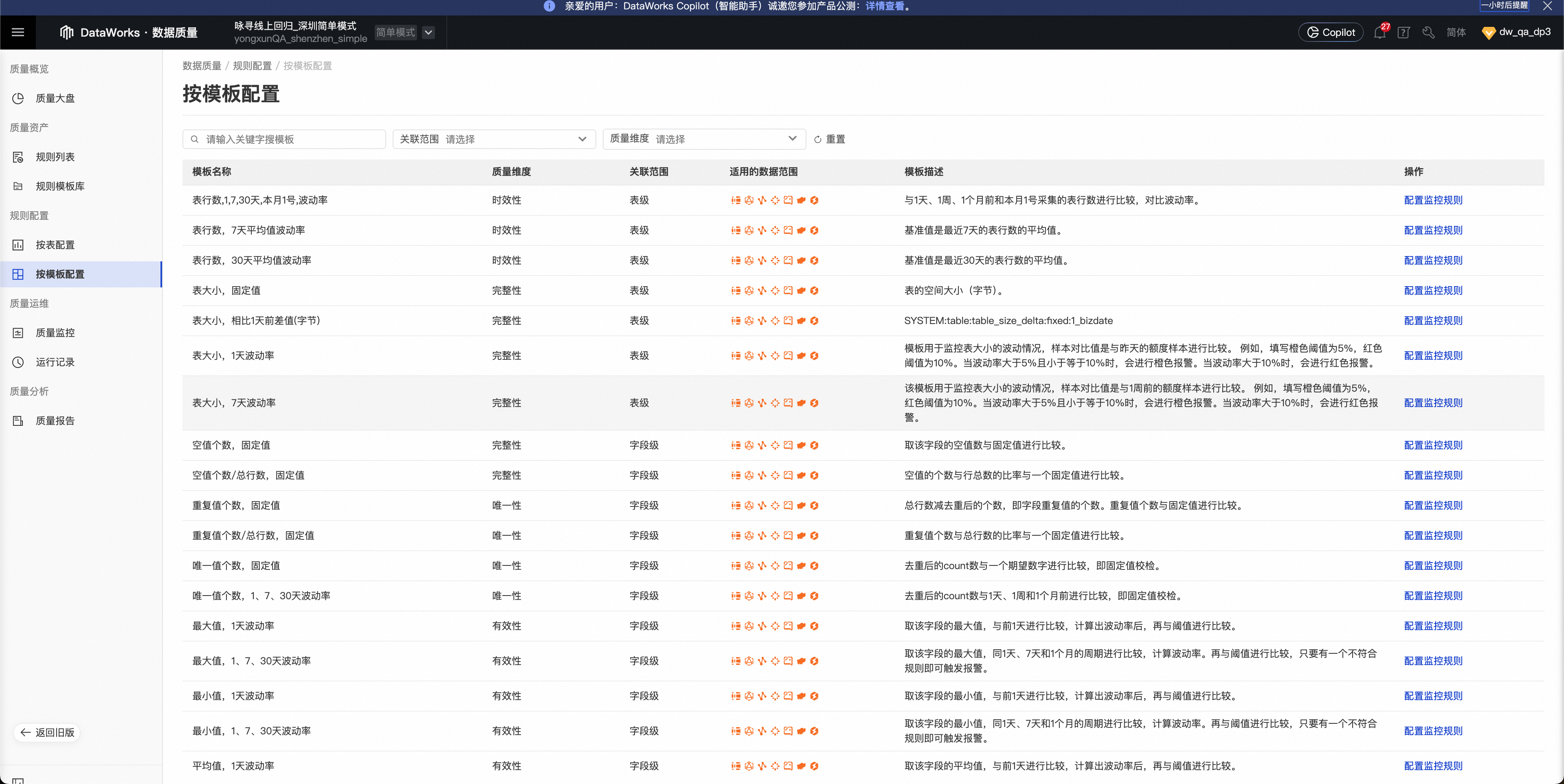
数据质量的评价指标
那么数据质量应该如何确保呢?中国电子技术标准化研究院与相关部门起草了《GB/T 36344-2018 信息技术 数据质量评价指标》。相应的,DAMA也曾经提出过一系列的数据质量体系建设建议,其中在技术层面被最广泛落地的方法论也是类似于这套质量评价指标和根据这套评价指标而衍生出来的一整套数据质量规则。
从各大公司内部衍生孵化出来的各种云产品来看,虽然或多或少的有些出入,但是整体上都不谋而合地在遵循的这套建议思路建设各自的数据质量产品。比如在DataWorks数据质量产品中就包含下列数据质量规则模板,来帮助用户在离线表上定义相关的规则。
![]()
那么DataWorks的数据质量规则模板是如何帮助用户建设数据质量的呢,举个例子,假设您有一张电商交易流水表,建表语句如下:
CREATE TABLE IF NOT EXISTS dws_d_dqc_suggesion_demo (
id BIGINT COMMENT '主键',
user_id STRING COMMENT '用户ID',
item_id STRING COMMENT '商品ID',
shop_id STRING COMMENT '店铺ID',
name STRING COMMENT '用户姓名',
family_name STRING COMMENT '姓氏',
birth STRING COMMENT '生日,格式 yyyy-mm-dd',
birth_time DATETIME COMMENT '日期类型的生日',
order_url STRING COMMENT '下单地址,是一个web页面地址',
create_time DATETIME COMMENT '日期类型的下单时间',
order_time STRING COMMENT '下单时间,业务上order_time、user_id应该是一个唯一值,即一个用户在同一个时刻只能发生一次购买行为',
user_ip STRING COMMENT '下单客户端ip',
user_mac STRING COMMENT '下单客户端mac地址',
user_agent STRING COMMENT '下单时的客户端标识',
email STRING COMMENT '用户账号的邮箱',
phone_number STRING COMMENT '用户的联系方式',
price STRING COMMENT '总价',
amount STRING COMMENT '购买数量',
unit_price DECIMAL COMMENT '单价',
client_token STRING COMMENT '下单时生成的全链路唯一标识,避免失败重试的重复下单',
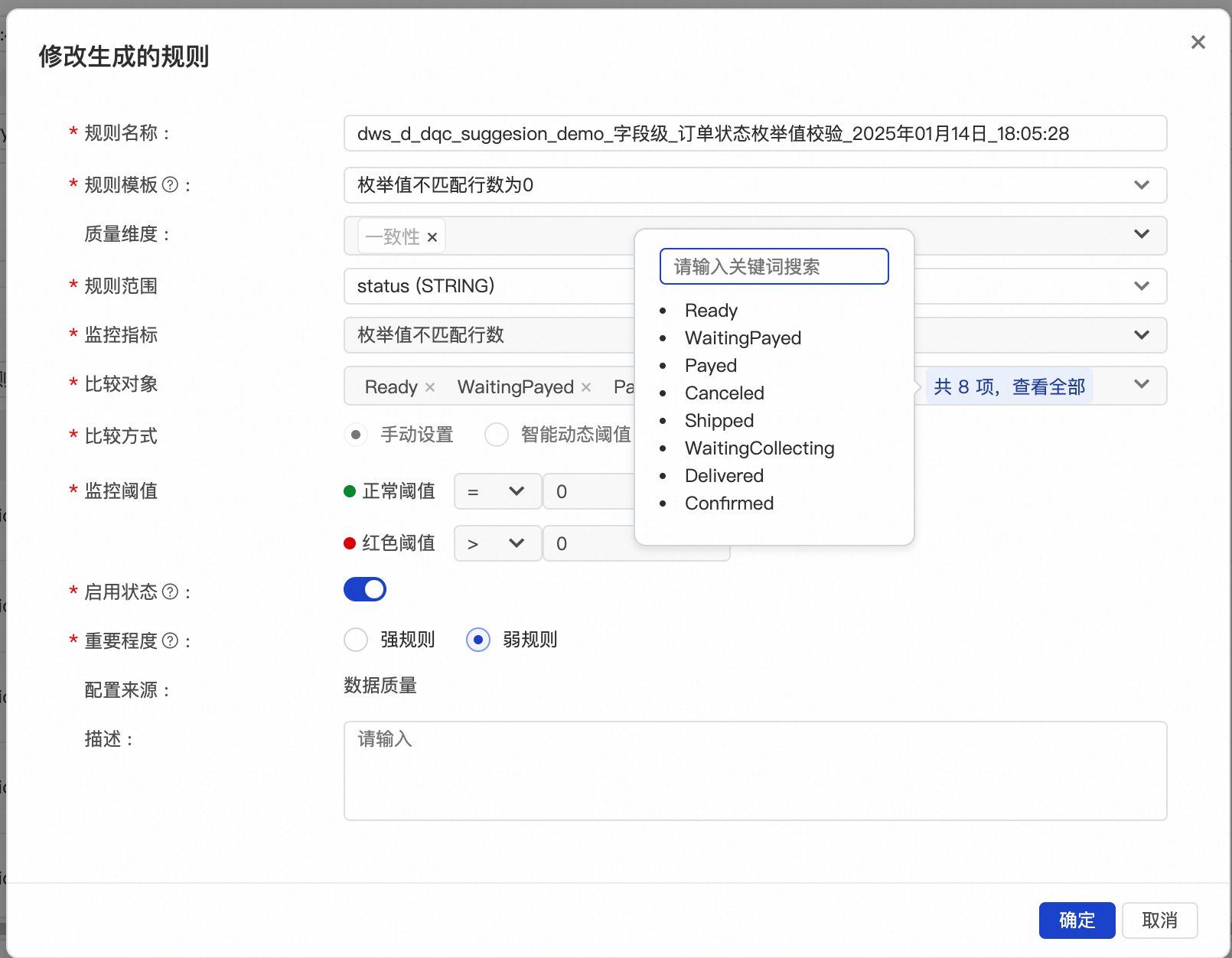
`status` STRING COMMENT '订单状态,Ready - 就绪、WaitingPayed - 待付款、Payed - 已付款待发货、Canceled - 已取消、Shipped - 已发货、WaitingCollecting - 已送达未领取、Delivered - 已收货、Confirmed - 已确认',
status_comment STRING COMMENT '状态说明,比如已送达未领取时,这里可以记录签收地等信息,可空'
)
PARTITIONED BY (ds STRING COMMENT '日期分区,格式yyyymmdd')
STORED AS ALIORC
TBLPROPERTIES ('columnar.nested.type'='true')
LIFECYCLE 365;
按照上面提到的数据质量评价指标,预期的数据质量规则如下:
![]()
看到这张规格表您可能会有些头疼,虽然已经知道了应该配置哪些规则,但是一张表就要手动配置如此大量的规则,每种规则要配置的参数又各不一样,并且表的字段数越多,配置的工作量就越会上升。感觉如果要手动遵循这套数据质量的建设思路来提升数据质量监控覆盖率,是一个很难完成的任务。
为了解决这一问题,DataWorks Copilot 推出了数据质量规则推荐功能,您可以使用这一功能,一键提升数据质量覆盖度。
功能演示
开始推荐
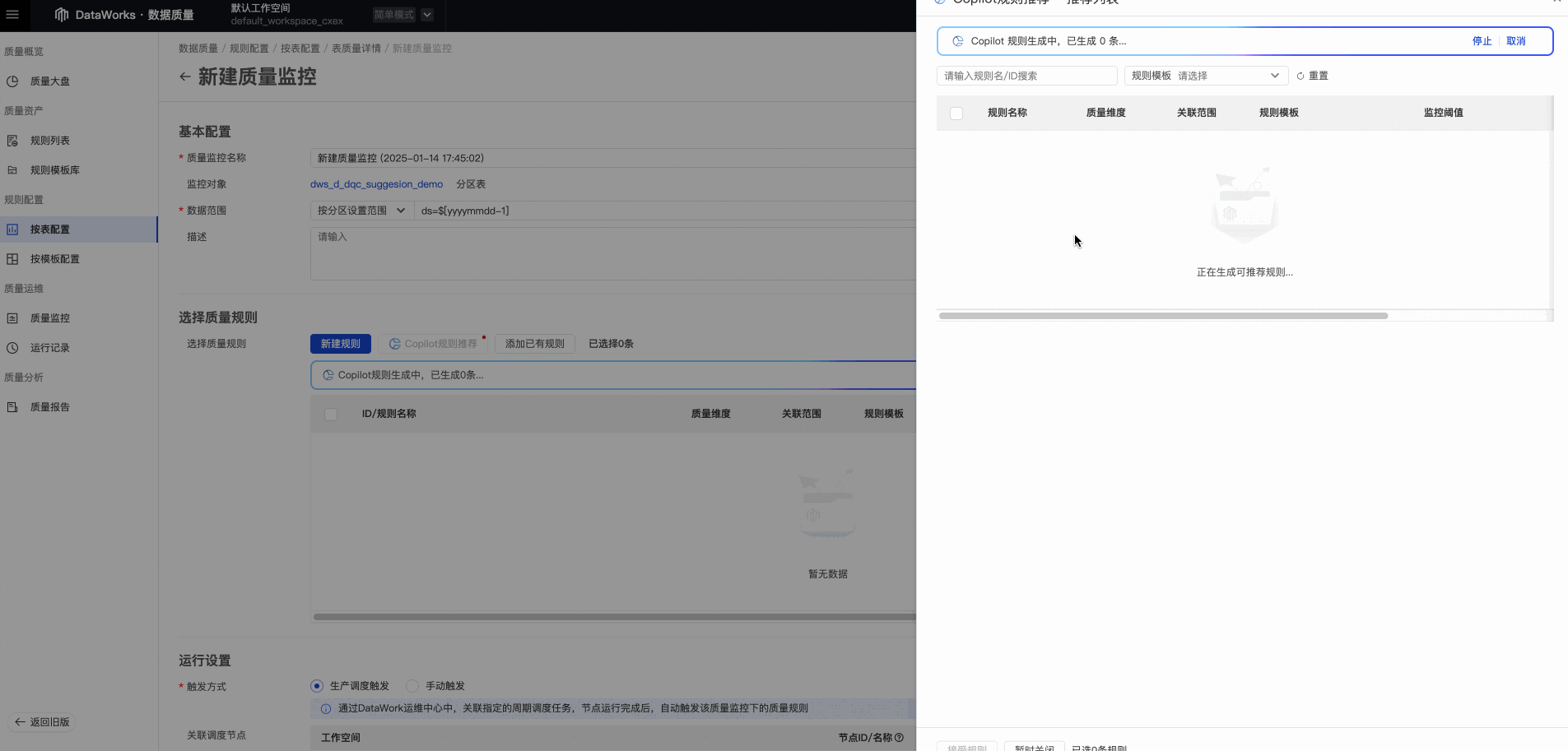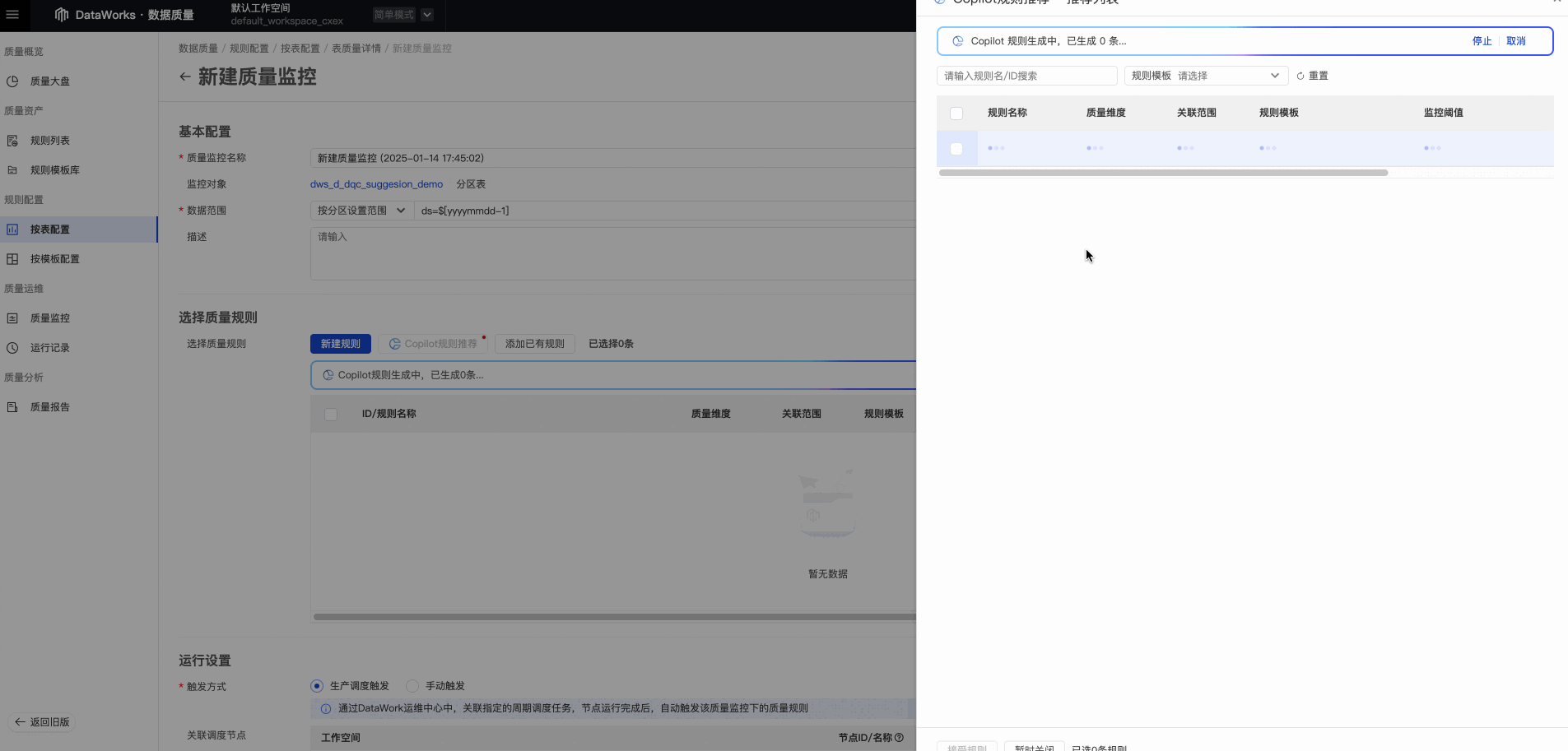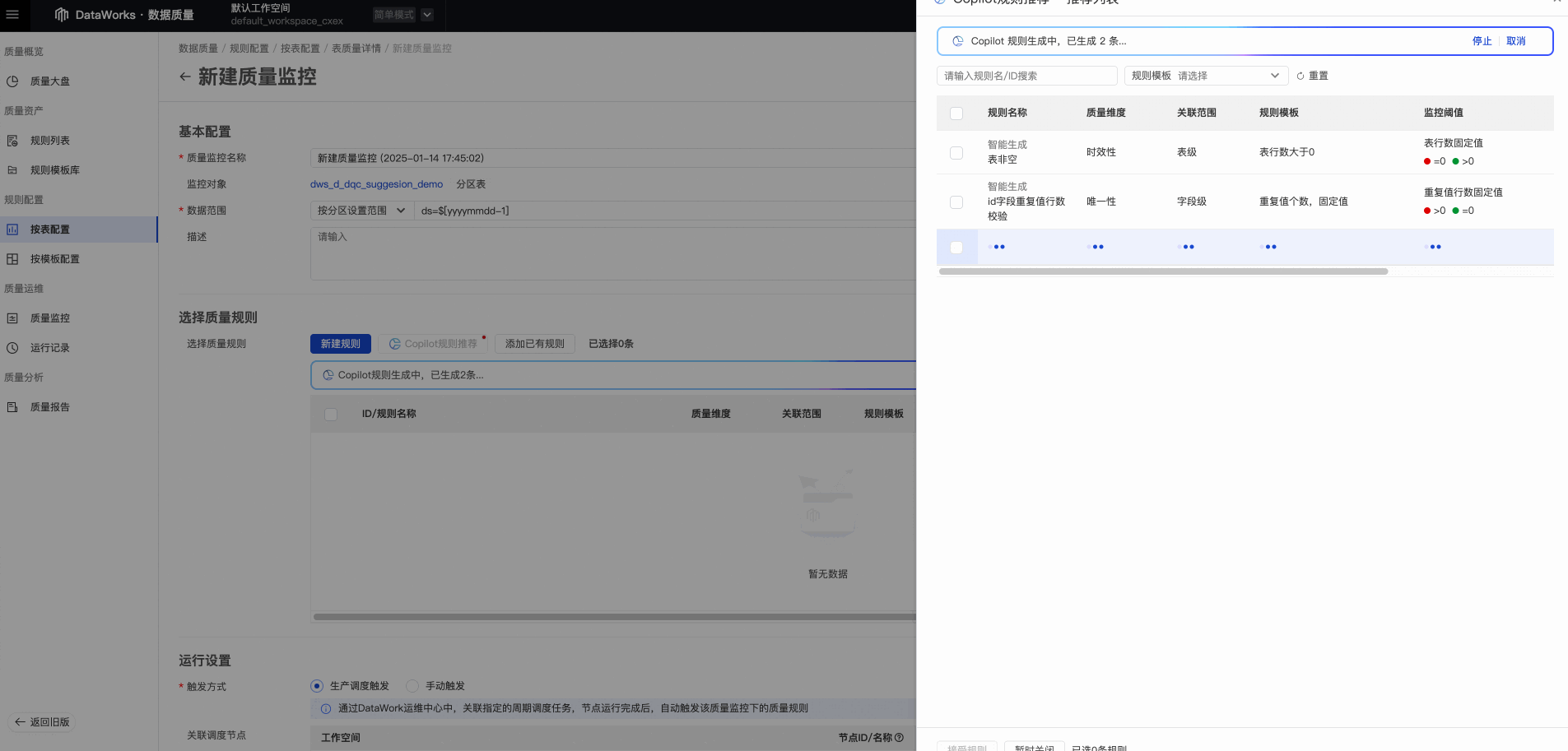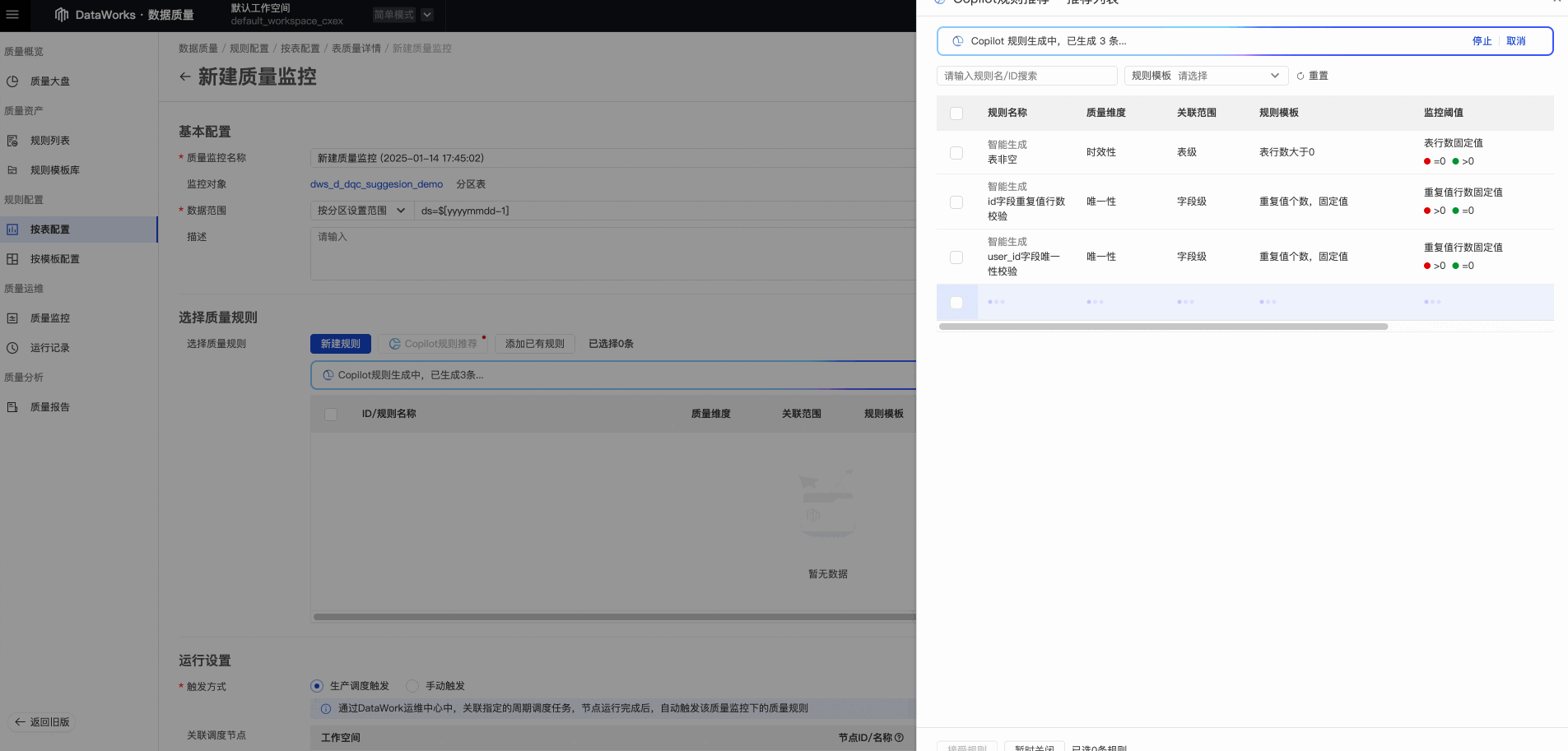
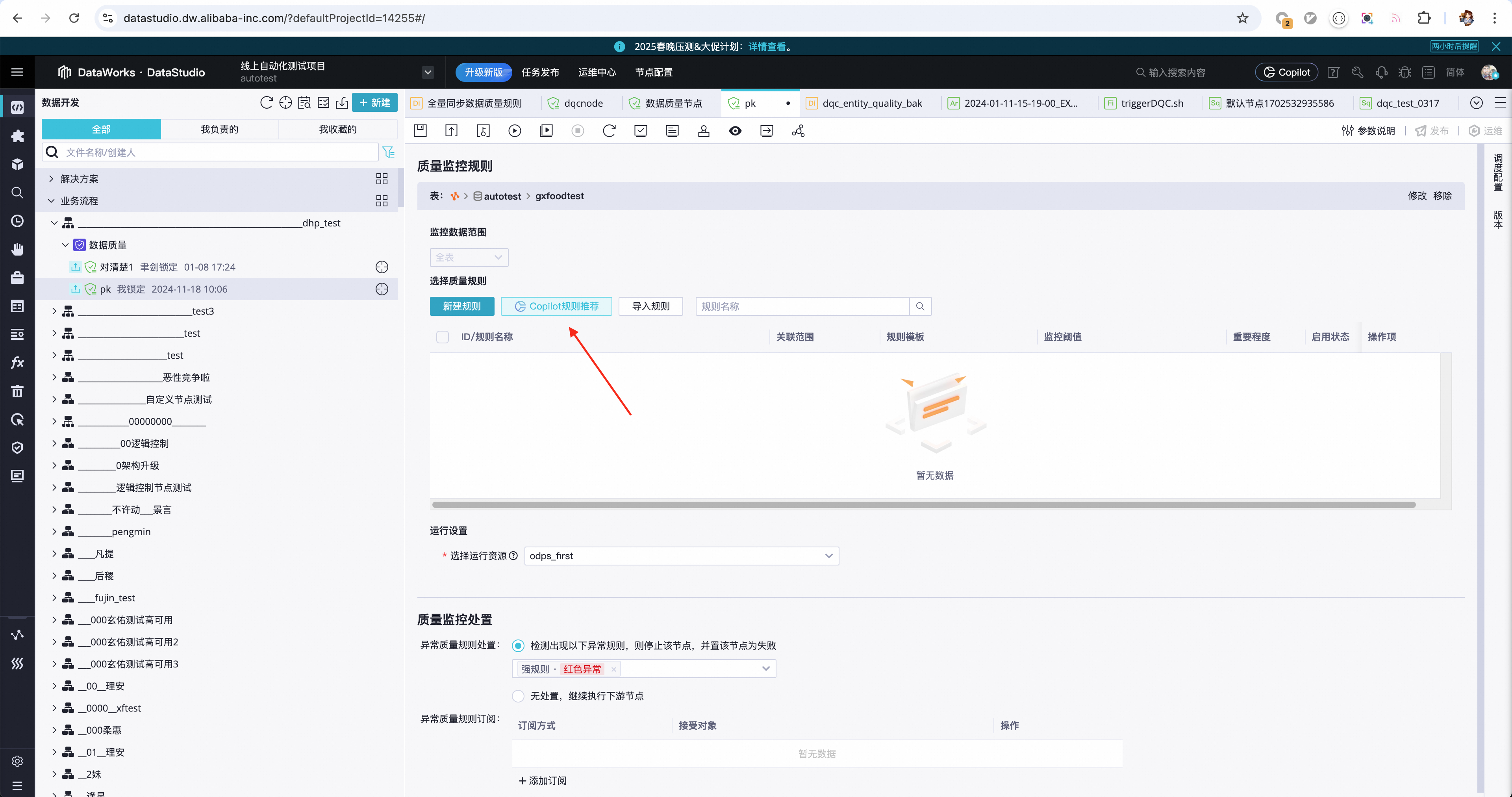
我们在数据质量的规则创建入口,都新增了“Copilot规则推荐”的按钮,我们以下面这张表为例,演示一下规则推荐的使用方式。
点击“Copilot规则推荐”,触发推荐流程,Copilot就会开始自动基于当前表类型、基础信息、字段信息及质量规则模版为您生成相应的规则建议。
![]()
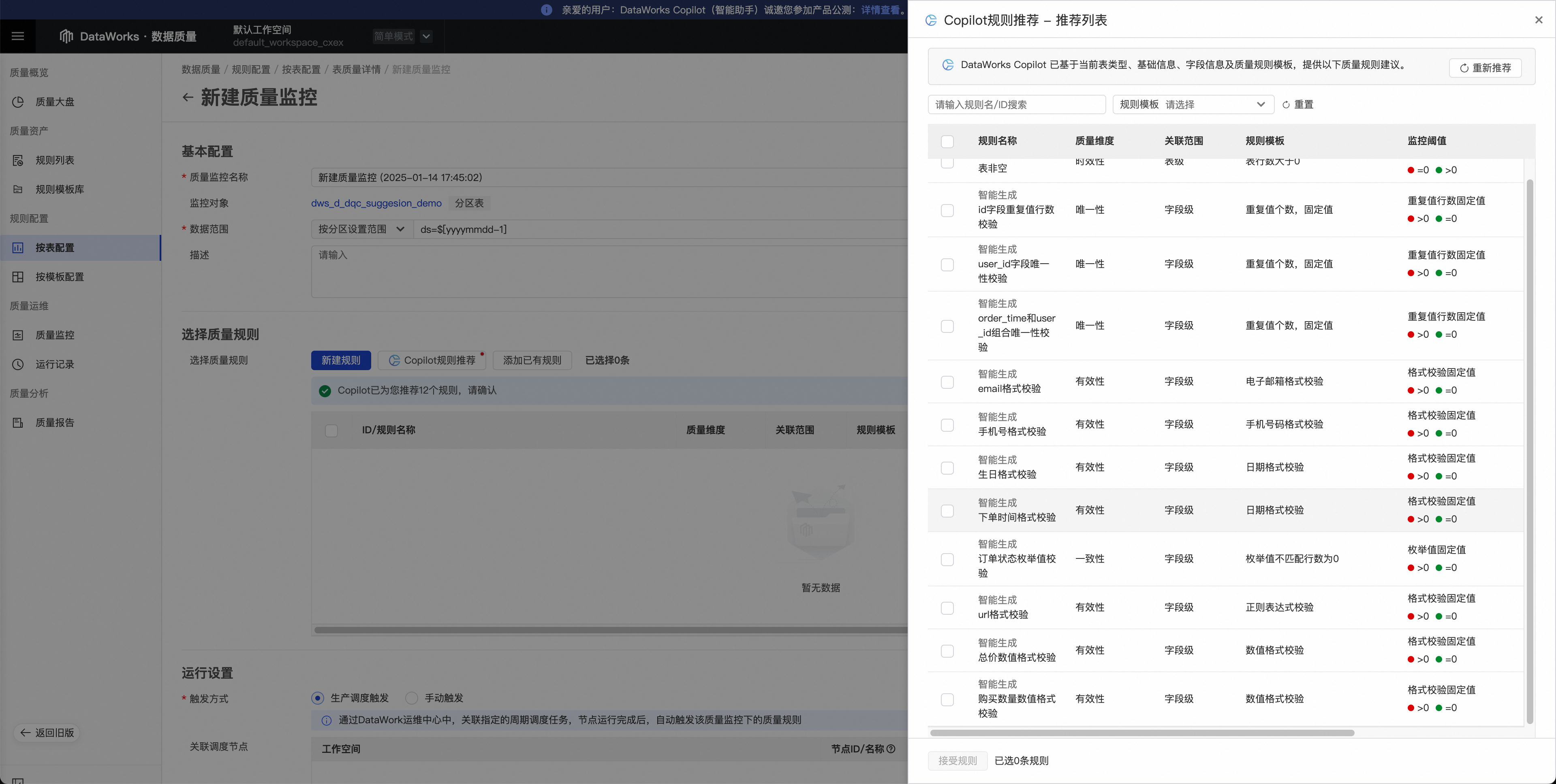
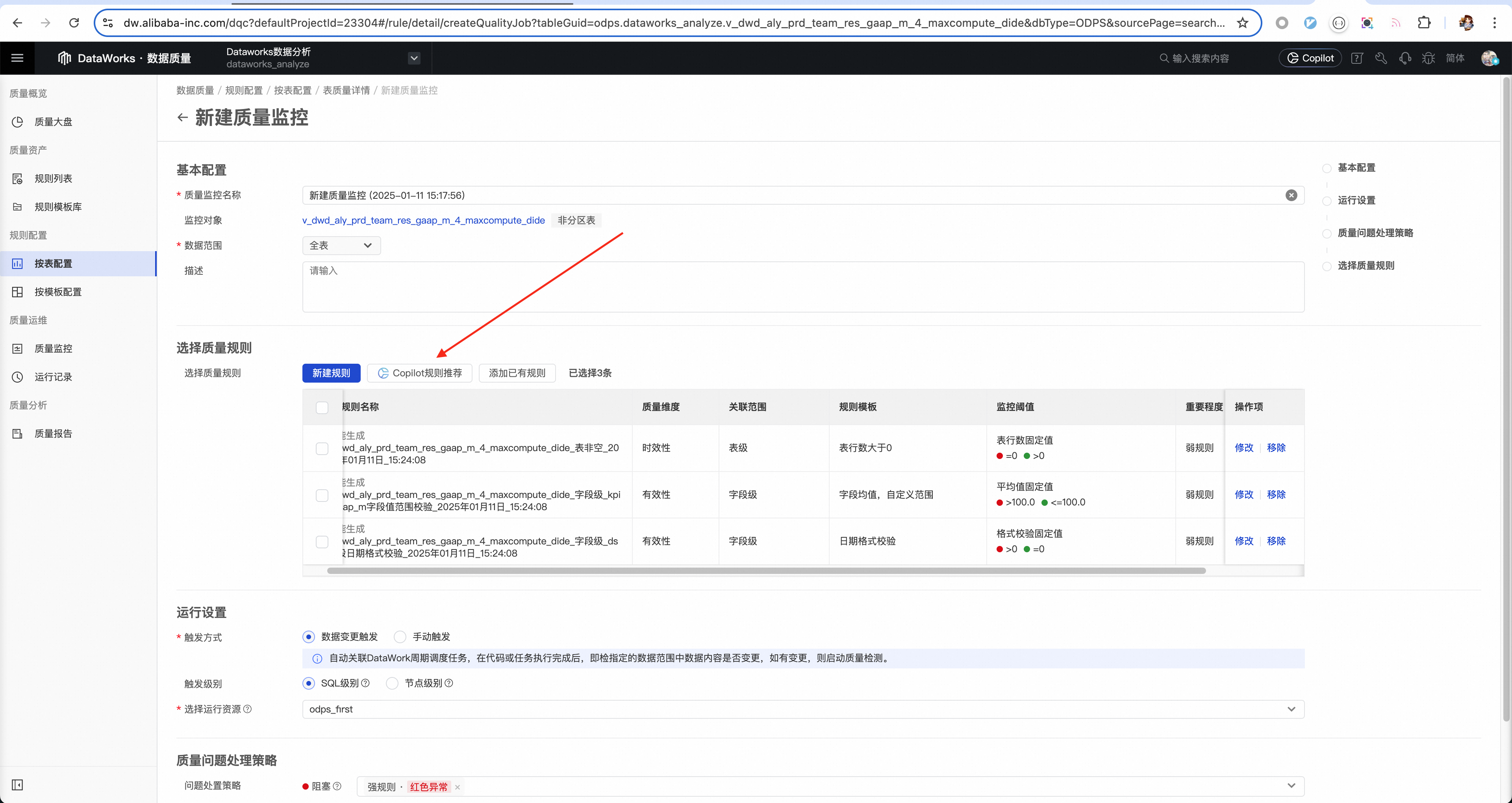
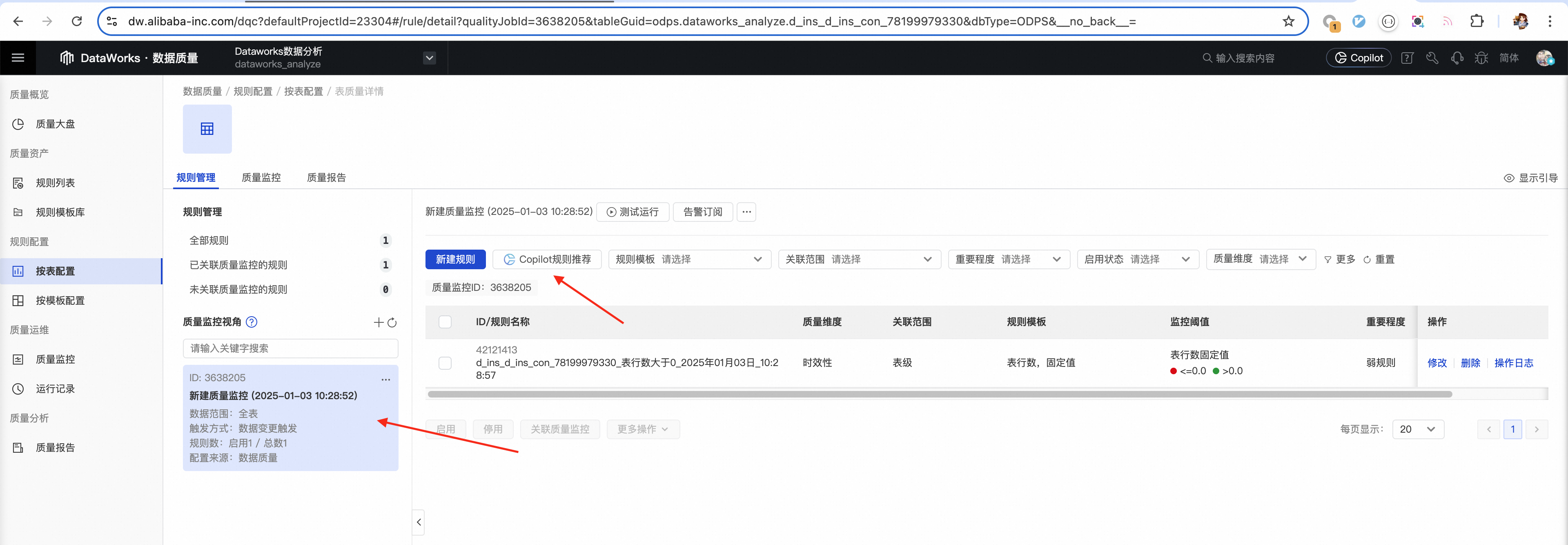
推荐结果展示
![]()
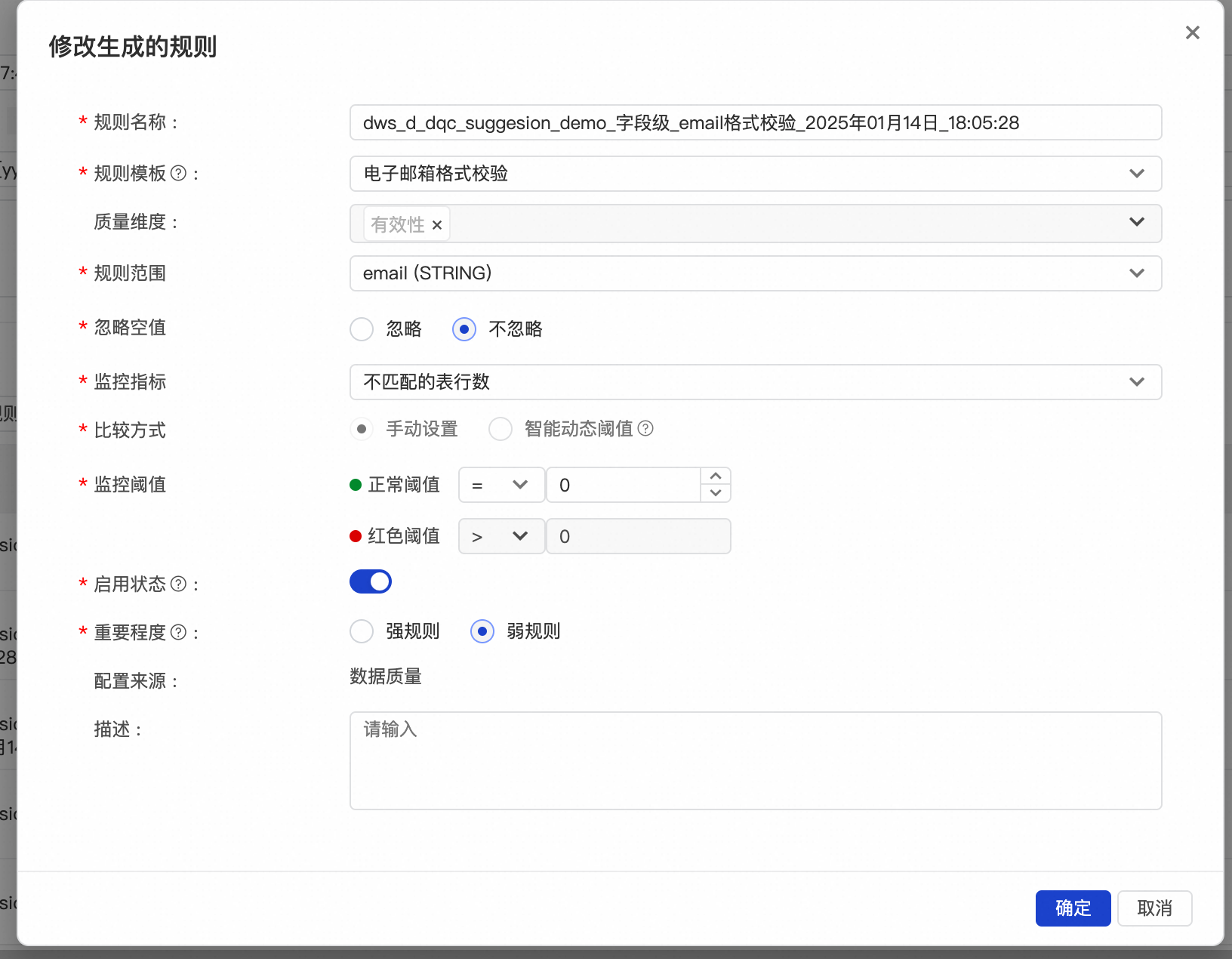
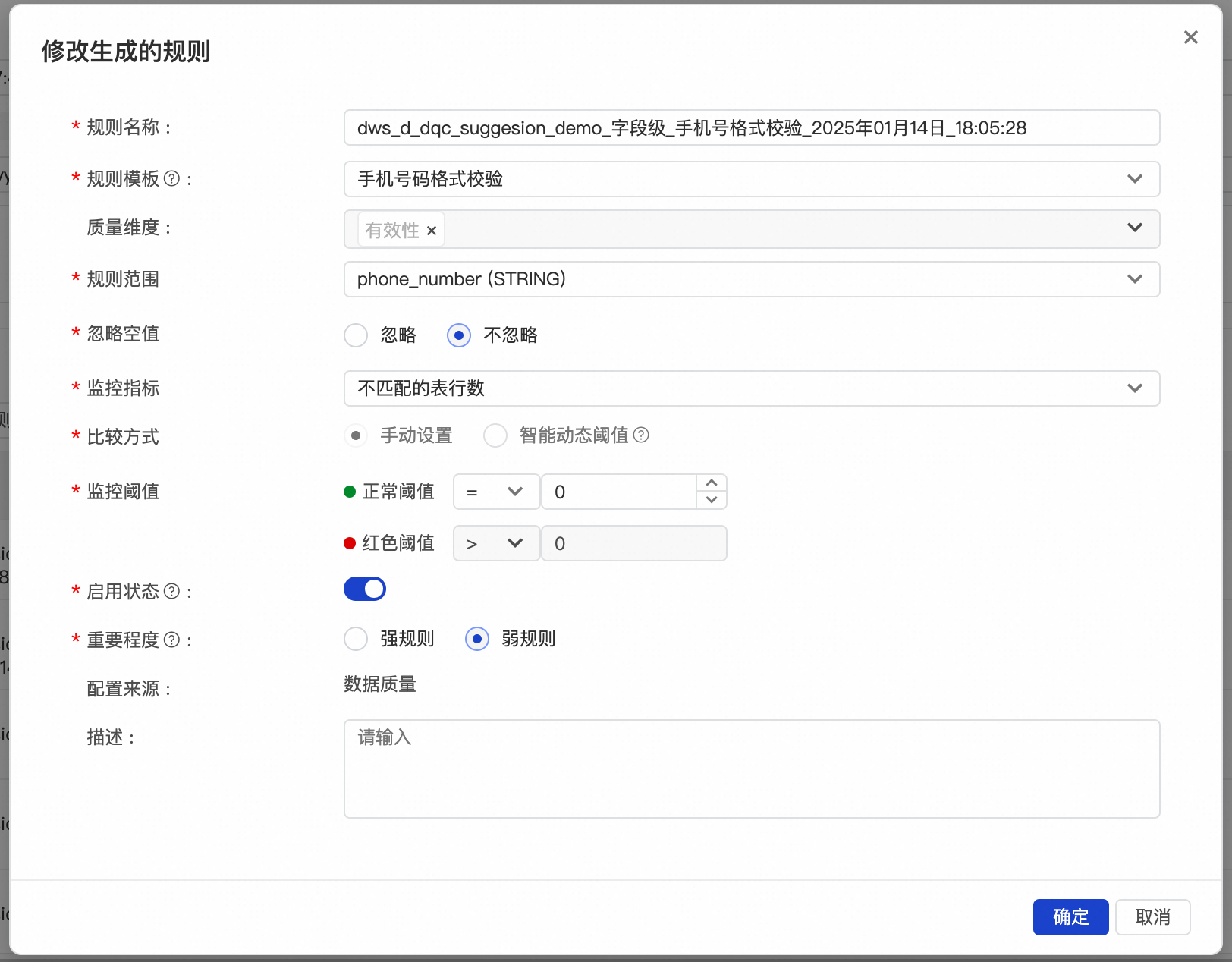
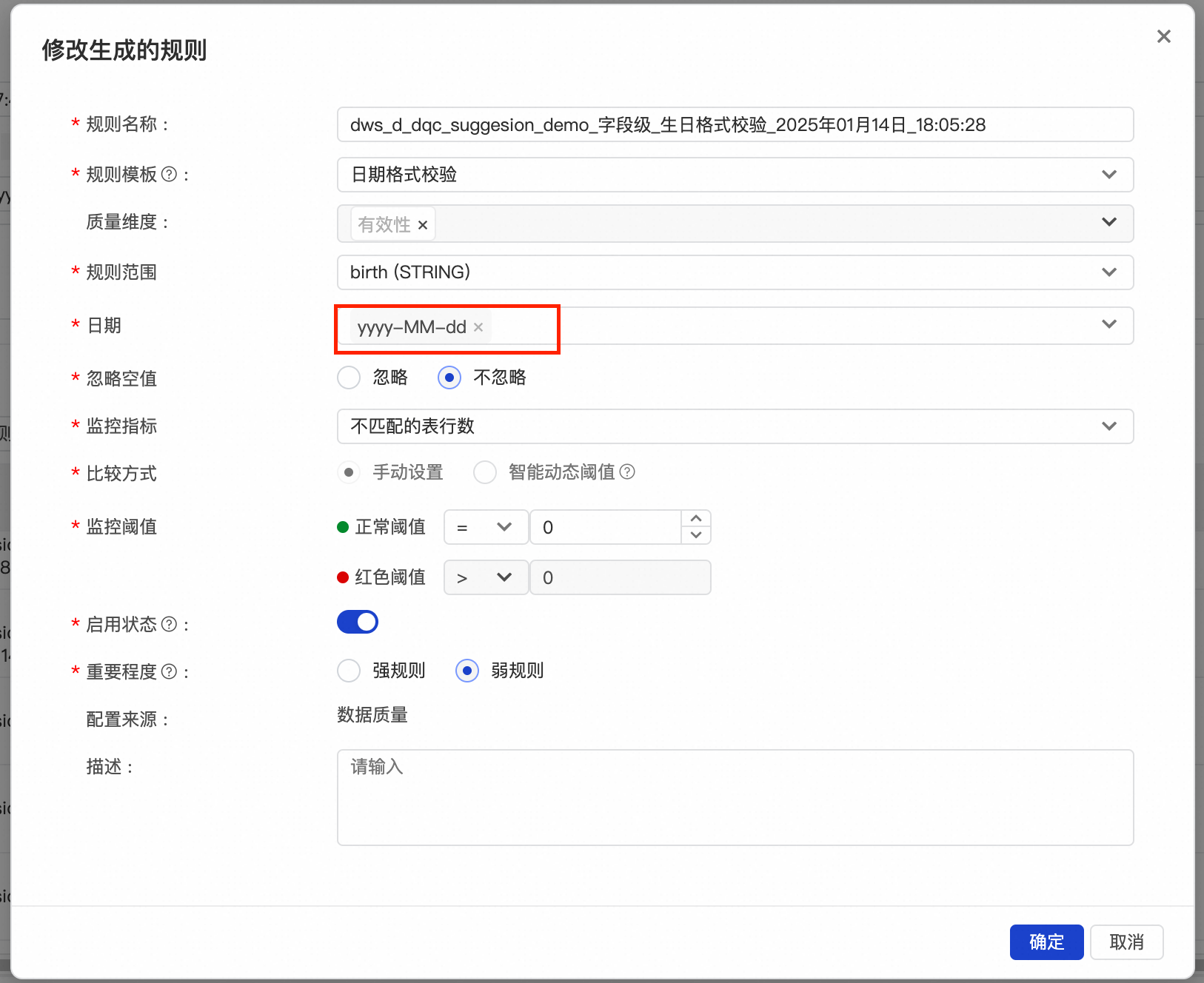
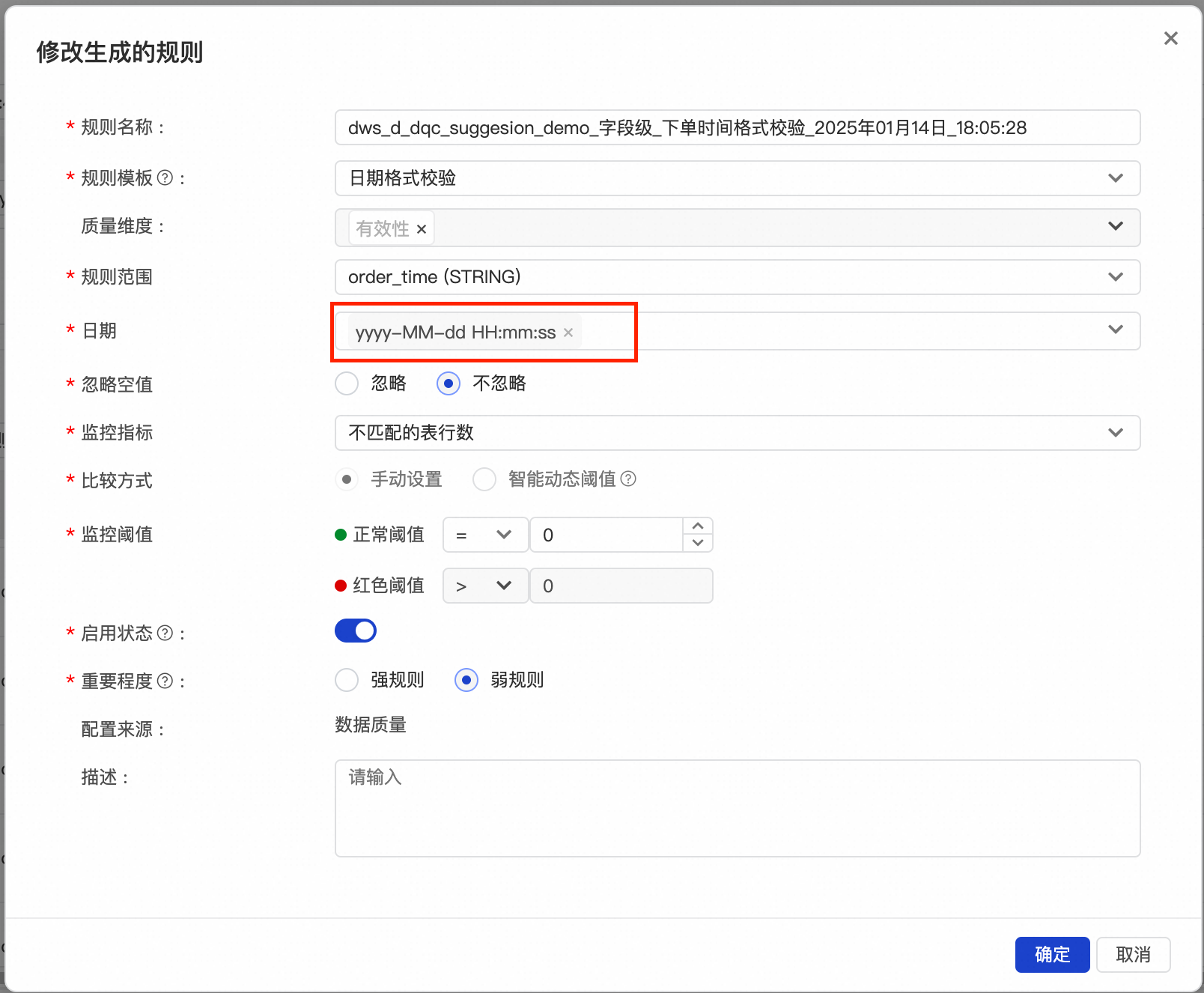
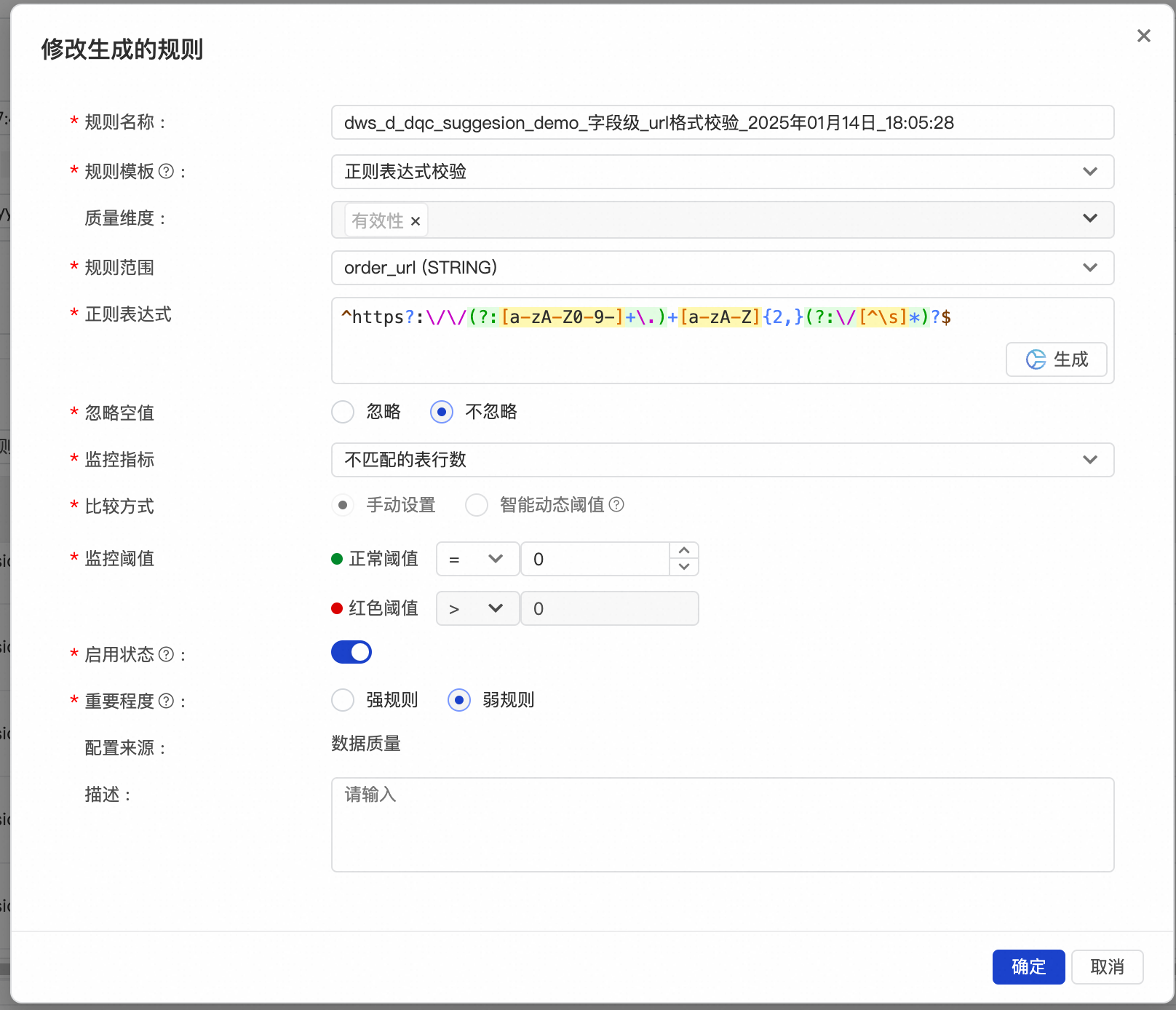
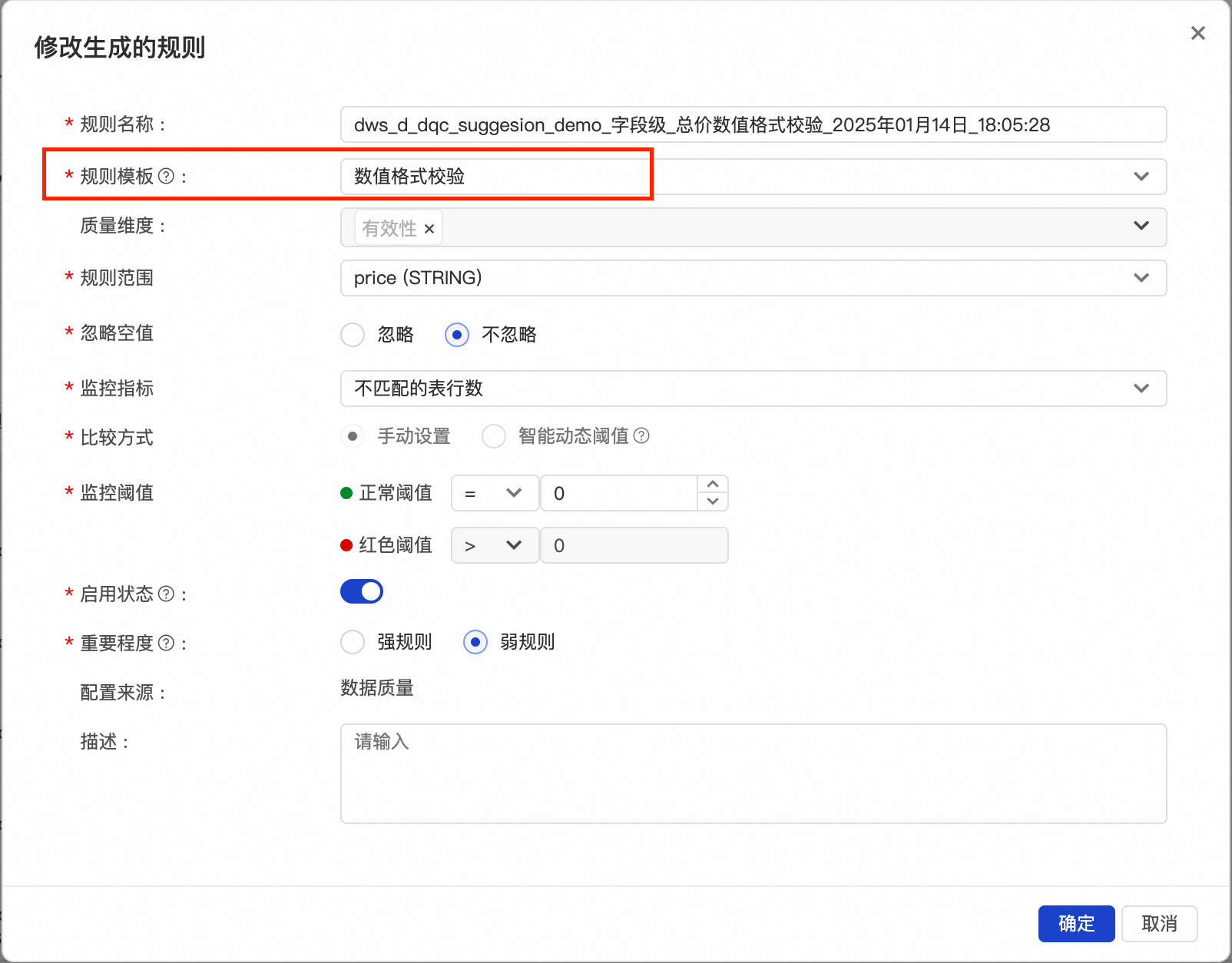
推荐的规则会尽量覆盖每一个字段,对于字段注释中特殊说明了内容类型的字段,会用已有的对应规则类型去覆盖。比如
![]()
![]()
![]()
![]()
![]()
![]()
![]()
规则推荐入口
为了帮助用户快速享受Copilot规则推荐的智能化能力,我们在所有可以配置数据质量规则的地方,都添加了响应的入口,主要包括如下几处
![]()
![]()
![]()
Copilot 规则推荐的奥秘
当前的数据质量产品推荐机制,是通过整合数据质量产品支持的规则类型、适用场景以及需要配置质量规则的表元数据,来形成一个全面的规则提示词。然后借助大模型对文本的理解能力,生成一系列合适的规则推荐列表。因此,推荐结果的准确性在很大程度上依赖于表名、字段名及其描述的精细程度。如果表命名和字段命名遵循一定的规范,并且其描述详尽丰富,最终推荐的效果将更为理想。
然而,基于元数据与大模型结合的方式,在实际应用中仍存在局限性,无法精准推荐某些类型的规则。为此,我们特别提高了经验证效果后表现较好的规则模板的优先级;而对于已知表现不佳的模板,则采取不推荐或降低推荐权重的做法。这些表现优秀的应用场景包括但不限于以下几个方面:
-
业务主键字段:确保非空且无重复值。
-
业务联合主键字段:要求非空,并且多字段组合时不应出现重复记录。
-
ID字段:必须保证非空。
-
枚举类字段:适用于具有固定选项集合的情况。
-
日期类字段:对于时间信息的处理尤为重要。
-
以字符串形式存储的数值型字段:这类特殊情况下也需要特别注意数据格式的一致性和正确性。
随着未来更多新规则模板的引入,我们将持续优化和完善相应的推荐策略,力求为用户提供更为准确高效的服务体验。
当前挑战与未来展望
目前依赖于静态元数据推荐的策略,其效果的好坏取决于表维护者的时间和精力等诸多客观条件。对于元数据不够完善的情况,或者无法通过元数据评估的情况,当前的推荐效果可能不尽如人意。
为了进一步提升推荐效果,我们将纳入更丰富的数据源,例如表的数据内容分布、表的产出信息、最佳实践以及用户自定义的知识库等,提供给大模型进行分析。通过持续迭代,我们希望能够帮助用户更快速、更准确地完成对数据质量监控场景的覆盖。这一过程不仅需要技术上的不断进步,还需要我们在理解用户需求和优化用户体验方面不断努力,以期达到更高的服务水平。
更多功能
DataWorks在数据质量管理方面持续进行功能迭代与革新。除了推出智能的数据质量规则推荐系统外,还引入了数据质量节点、数据对比节点等一系列崭新的功能,进一步帮助用户提升了数据的准确性、一致性和可靠性的同时优化了用户体验。DataWorks致力于通过持续的技术创新和精益求精的态度,构建更加完善的数据质量产品能力体系,为企业决策提供强有力的支持!
-
新增数据质量节点,可通过配置数据质量监控规则,监控相关数据源表的数据质量:https://help.aliyun.com/zh/dataworks/user-guide/data-quality-monitoring-node?spm=a2c4g.11186623.help-menu-72772.d_2_6_0_0_13_15.63401270gn6LSh
-
新增数据对比节点,实现对不同表之间的数据进行多种方式的对比:https://help.aliyun.com/zh/dataworks/user-guide/data-comparison-new-node?spm=a2c4g.11186623.help-menu-72772.d_2_6_0_0_12.3ca72c7alG2RIo&scm=20140722.H_2857667._.OR_help-T_cn~zh-V_1
-
新增规则枚举类、格式校验类的模板: https://help.aliyun.com/zh/dataworks/user-guide/built-in-monitoring-rule-templates?spm=a2c4g.11186623.help-menu-72772.d_2_9_3_4_0.7a905b99llYlnu
-
数据质量规则的完整性、唯一性、准确性等的标记与分析
优惠体验
数据资产管理是DataWorks软件企业版独有功能,现对广大用户送出新年福利:
-
首次购买标准版/专业版或从基础版升级到标准版/专业版,可免费体验企业版独有的数据资产治理功能1个月;
-
标准版/专业版老用户可以免费体验企业版独有的数据资产治理功能45天;
-
首次购买企业版或低版本即将到期(31天内)升级到企业版,可以申请享受首月299元的优惠,申请入口>>;