欢迎阅读 OSCHINA 编辑部出品的开源日报,每天更新一期。
# 2025.1.13
今日要闻
1 月 13 日消息,华为常务董事、终端 BG 董事长、智能汽车解决方案 BU 董事长余承东发布了新年第一封全员信。余承东表示:“时代的洪流冲天下,鸿蒙三分天下有其一,是历史赋予我们这代终端人的责任与使命。”
他还提到,2025 年鸿蒙生态要压强投入,10 万个应用是生态成熟标志,这是未来半年到一年时间的关键目标。
DeepSeek 推出了官方移动版 APP,提供深度思考和联网搜索功能,可以生成内部思维链,逐步分析问题并得出结论。此外,该 APP 还提供图片、文件等多模态输入模式。
![]()
据介绍,该 APP 由 DeepSeek-R1-Lite 模型和 DeepSeek V3模型提供支持。
受美国拜登政府计划对人工智能芯片出口实施新限制措施消息的影响,1 月 10 日美股开盘后,英伟达股价大跌超 3%,AMD 股价大跌近 6%,博通股价下跌超 2%。
此前有消息称,拜登政府预计最早于 1 月 10 日发布一项新的芯片出口禁令,将制定三层芯片限制:美国的少数盟友仍将拥有美国半导体的全部使用权,但大多数国家将面临新的芯片出口限制,并将对另一些国家完全禁止出口数据中心芯片。
英伟达发给第一财经记者的回应中,英伟达政府事务副总裁内德・芬克尔(Ned Finkle)表示,全球用户日常使用的游戏 PC 已经普遍搭载数据中心计算机和技术,试图对其实施控制是没有意义的。
美国半导体行业协会(SIA)也就拜登政府计划发布的新规发表声明称:“这一潜在的监管行动预计将对美国先进集成电路的出口实施全球限制和繁重的许可要求。我们对这项潜在法规所涉及的空前范围和复杂性深感担忧。”
美国网络安全与基础设施安全局 (CISA) 发布了一份新的信息技术 (IT) 行业特定目标 (SSG)。
据该组织称,IT SSG 是对跨部门网络安全绩效目标 (CPG) 的补充,并提供 “具有高影响力安全行动的额外自愿实践”。组织可以使用它们来提高其软件开发实践的安全性。
![]()
详情:https://www.cisa.gov/resources-tools/resources/information-technology-it-sector-specific-goals-ssgs
2025 年 1 月 13 日,人人可用的开源 BI 工具 DataEase 正式发布桌面版。用户可以免费下载 DataEase 桌面版安装包,将其安装在 Windows、MacOS 和 Linux 系统中,快捷地开展数据可视化分析工作。
DataEase(github.com/dataease)是飞致云旗下的一款开源 BI 工具,于 2021 年 6 月发布。DataEase 可以帮助用户快速分析数据并洞察业务趋势,从而实现业务的改进与优化。DataEase 支持丰富的数据源连接,能够通过拖拉拽方式快速制作图表,并可以方便地与他人分享。
![]()
今日观察
社交观察
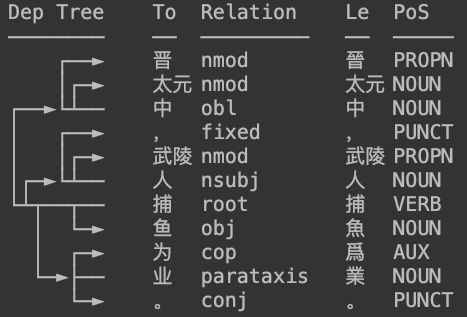
在陆续支持了简繁中英日俄法德在内的130种语言后,HanLP今日正式发布开源古汉语模型,以支持古汉语自动分词、词形、词性标注和依存句法分析。得益于多任务学习技术,只需一个模型就可以支持这些任务,以及粗分/细分、UPOS/XPOS/PKU词性标注集。
![]()
- 微博 hankcs
【The GAN is dead; long live the GAN! A Modern GAN Baseline】
![]()
https://huggingface.co/papers/2501.05441
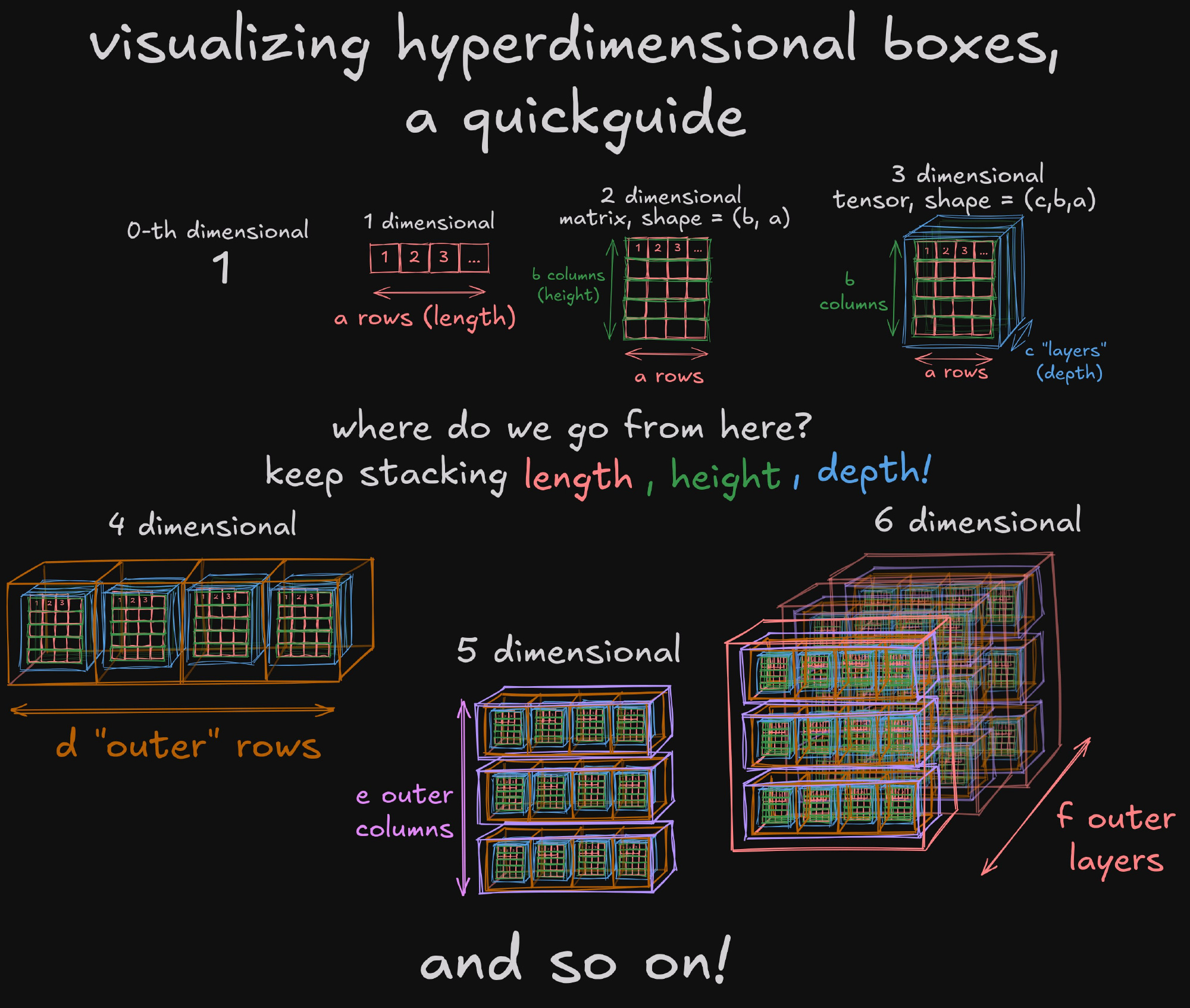
spikedoanz发的一张图,描述了一种在脑海中可视化任意高维空间的方法。
![]()
- 微博 蚁工厂
最近 X 上在讨论为什么大语言模型 O1,有时候会用中文思考?
转发一段 Hugging Face 王铁震老师的想法:
我一直觉得,会两种语言不仅仅是能用两种语言交流,而是能根据话题和场景,自然地用更合适的语言去思考。比如,我更喜欢用中文做加减乘除,因为每个数字只有一个音节,算起来干脆利落。但一提到“无意识偏见”这种话题,我就会不自觉地切换到英语,毕竟这些概念我最开始就是从英语里学来的。
这让我想到编程语言:大多数程序用什么语言都能写,但我还是会用 Bash 写命令行脚本,用 Python 搞机器学习,因为每种语言都有自己最顺手的地方。现实中的语言也一样,我们会根据语言的特点和自己的习惯,选择最顺手的语言去表达特定的内容。
这也是为什么我觉得,在训练大语言模型(LLM)时,保持所有语言和文化的多样性和包容性特别重要。就像哲学家维特根斯坦说的:“语言的界限就是世界的界限。”只有包容每一种语言的细微差别,才能让模型学到更全面的思维。即使两种语言里的两个词意思一样,它们在模型中的 Embedding 也可能完全不同,因为它们背后的文化和使用方式截然不同。在我看来,这种包容性不仅能打造更公平、更准确的模型,还能让它处理更多样化的任务,汇聚全人类的智慧。
媒体观察
与前四年的总和相比,这是一个巨大的投资增长。在这四年中,英伟达仅参与了38笔AI交易。这些投资不包括其正式的企业风险投资基金NVentures的投资。过去两年,该基金也大幅增加了投资。(据PitchBook,NVentures在2024年参与了24笔交易,而2022年只有2笔。)
- 芯东西
近期AI领域的一些进展确实令人瞩目。AI在狭窄智能体、模态能力方面的进展显著。我们最应该担心的,不是各AI大厂的时间表是否正确,而是是否已经为即将到来的变革做好准备。
- 华尔街见闻
飞利浦旗下的MEMS部门曾处于亏损状态。Xiver的新任董事长Kees Wesdorp表示,这家健康科技公司主要利用该技术来支持内部产品开发。“这并非对飞利浦的批评,但如果一个部门仅服务于自身业务,就会限制其潜力。现在我们独立了,可以将技术更广泛地推向市场并吸引新客户。”
- 半导体行业观察
所以,自然语言在软件开发中的真正使用,在于软件开发人员和软件的最终用户之间发生的探索性对话。LLM可能会促进这种对话,但取代编程还遥遥无期。
- 新智元
眼下,通用大模型已演变成一个“超级烧钱”的游戏,成为了只有巨头才能参与的“富豪局”。没有足够资金的公司将不得不退出这场竞争。
此前的共识是,要在基础大模型的“金钱战”中脱颖而出,除了短期内是否有充足的资金支持外,长远来看,自身的造血能力至关重要,而AI应用则是实现这一目标的关键方向。
- 市象
当ChatGPT等大模型出现,开始扮演起“占卜师”“命理师”的角色,可以随时随地回应,不限次、不限时地帮人答疑解惑,占卜、算命快速成为年轻人使用AI的高频场景之一。
唯一的问题是,AI算命,能比人更准吗?
- 镜相工作室
今日推荐
开源项目
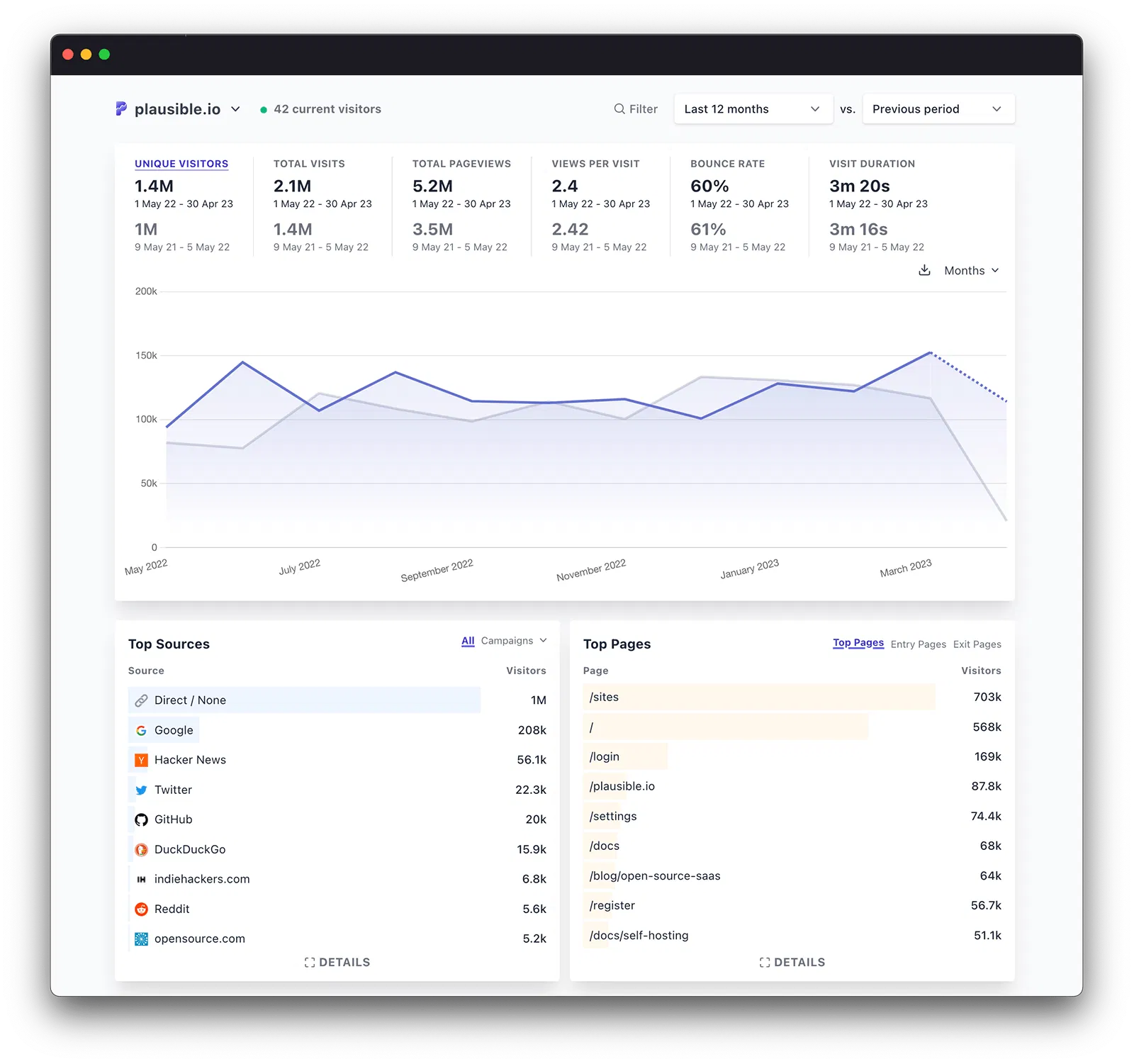
![]()
https://github.com/plausible/analytics
Plausible Analytics 是一款易于使用、轻量级、开源和隐私友好的 Google Analytics 替代软件。它不使用cookies,完全符合GDPR、CCPA 和 PECR 标准。
每日一博
LTS 版本还是值得去了解,有条件的话也是比较推荐在生产环境去做使用的,因为不管是上述哪个方面带来的提升,对开发以及系统运维来说,都是属于易得的红利。
![]()
开源之声
用户观点
- 观点 1:都别争了,前端今年都开始大量被ai替代了
- 观点 2:前端的AI可替代性确实比后端强。
- 观点 3:反了吧 界面交互因人而已的体感 AI 难搞定,对不见的服务端只关注性能和逻辑才更能被替代
- 观点 4:前端娱乐圈
- 观点 5:有啥好打的,不如直接Vue整合模板渲染用JSX语法写,又不是不能一起用
- 观点 6:现在转安卓还来的及吗
- 观点 7:资深圈内人表示:工作都找不到,选啥都没用
- 观点 8:反正都是封装的一堆黑盒,没必要比谁更不黑盒,能用能看懂就完事了
- 观点 9:在speedometer3.0跑分里面,Preact、svelte、lit的速度最快
- 观点 10:要不是前端天生就奇怪,哪里会有这些框架的诞生,也就不用这么吵了,写前端程序,你要学3种技术,结合起来才能干活,这在软件届也是独一无二的存在了。
- 观点 11:Angular一直没有存在感
- 观点 12:我都行,看场景
- 观点 1:为何这个还没人来喷中文编程无用?
- 观点 2:因为大家知道这是乐子
- 观点 3:因为这玩意就是个人的玩具作品,学编译原理的时候,或者纯感兴趣,自己搓个小编译器太正常了。这玩意的重点也就是这个前端语法风格,目的也不是实用。冲着实用去那重点就会放在核心语法设计以及后端优化还有周边工具链。都不是为了实用,为啥要批评无用呢。
- 观点 4:快进到写符咒等于编程
- 观点 5:早就有类似的project了:wenyan-lang(文言),号称“文言文編程語言”,GitHub上1万多star,不过早就停止开发了。
- 观点 6:梦回易语言
- 观点 7:用全角这个角度看,比易语言合理多了
- 观点 8:行,就是begin 终就是end 有一种Fortran的感觉
- 观点 9:这种设计17年大家就尝试过了,中文汉字编程可以用lisp句法 或 forth句法进行设计,不管是实际代码还是伪代码。完全不局限于用什么当关键字
---END---
![]()