编者按: 向量嵌入技术真的能像宣传的那样精确地帮助检索和理解信息吗?检索增强生成(RAG)技术的可靠性真的像我们想象的那么高吗?
本文揭示了 RAG 技术中最为致命的技术短板 ------ 向量嵌入技术的语义匹配可靠性。作者并非停留在批评,而是提供了一个务实的解决方案:将向量嵌入作为搜索结果的优化工具,与传统的同义词搜索等方法配合使用,而非唯一检索依据。
本文系原作者观点,Baihai IDP 仅编译转载。
作者 | Michael Wood
编译 | 岳扬
![]()
在 RAG 系统中,其核心任务是找出那些与查询内容相似度最高的存储信息。然而,向量相似度搜索并不能实现这一点,这也是 RAG 在实际应用中遭遇挫折的原因。
01 选错了工具
RAG 在生产环境中的失败,归咎于使用了向量嵌入来衡量信息的相似度,这显然不是一个恰当的选择。 我们可以通过一个简单的例子来说明这一点。假设有三个词汇:
- King(国王)
- Queen(王后)
- Ruler(统治者)
"国王"和"统治者"可能指的是同一人(因此它们可以被视为同义词),但"国王"和"王后"则明显指的是不同的人。按照相似度的百分比来衡量,"国王/统治者"应该有较高的相似度得分,而"国王/王后"的得分则应该是零。
换句话说,如果查询的内容是关于"国王"的,那么包含"王后"信息的文本片段应该是不相关的;而包含"统治者"信息的文本片段则可能相关。但是,向量嵌入却认为"王后"与"国王"的关联度高于"统治者"。以下是在使用 OpenAI 的 ADA-002 嵌入模型时,"王后"和"统治者"与"国王"的向量相似度得分:
- King(国王)
- Queen(王后):92%
- Ruler(统治者):83%
这意味着,当搜索关于"国王"的信息时,系统会优先展示关于"王后"的文本片段,而不是关于"统治者"的,尽管后者在内容上可能更为相关,而关于"王后"的信息则完全不相关。
02 向量嵌入在处理"谁、什么、何时、何地、如何"这类问题时并不适用
向量嵌入的问题不仅出现在涉及人物的词汇(如国王)上,也出现在涉及其他事物的词汇上。
设想一个关于猫的特性的查询。理论上,提到狗的文本在相似度上应该是零,而关于猫科动物的文本则应该有极高的相似度得分。但是,向量嵌入又一次给出了错误的结果:
- 猫(Cat)
- 狗(Dog):86%
- 猫科动物(Feline):85%
尽管两者分数只差 1 %,但这仍然意味着讨论狗的文本会优先于讨论猫科动物的文本;这显然不合理,因为讨论狗的文本与查询毫不相关,而讨论猫科动物的文本则极为相关。
绝对同义词指的是意义完全相同的词汇。然而,即便是在处理绝对同义词时,向量嵌入也会错误地优先考虑那些根本不是同义词的词汇 ------ 下面的例子就进一步证明了这一点。
"The Big Apple"是纽约市的别称。假设苏珊是一位新泽西州的居民,她在博客中记录了自己在家乡的餐馆、博物馆和其他地点的体验。但在一篇帖子中,苏珊提到她在"The Big Apple"举行的婚礼。当一位访客在苏珊的网站上询问 Chatbot:"苏珊去过纽约吗?"时,问题出现了。
非常遗憾,关于新泽西的大量内容会排在苏珊提及结婚的那篇帖子之前。原因何在?从向量嵌入的角度来看,"新泽西"在语义上比"The Big Apple"更接近"纽约":
- 纽约(New York)
- 新泽西(New Jersey):90%
- The Big Apple:89%
根据涉及"新泽西"的帖子数量,对"The Big Apple"的提及有可能在 Chatbot 检索到的数百个候选内容中都被忽略。这表明,向量嵌入在处理地点信息(如纽约(New York))时同样可能出错,正如它在处理人物(如国王(Kings))、其他食物(如猫(cat))时的表现一样。
实际上,向量嵌入在处理行为操作时也存在问题。
- bake a cake
- bake a pie: 93%
- make a chocolate cake: 92%
以"烘焙蛋糕(bake a cake)"为例,讨论"烘焙派(bake a pie)"(得分93%)的文本可能会优先于"制作巧克力蛋糕(make a chocolate cake)"(得分92%)的内容;尽管前者与查询完全无关,而后者则直接相关。
上述例子表明,向量相似度并不是衡量内容相同度的可靠方法。它不仅不适用于人物(如国王)、事物(如猫)和地点(如纽约),也不适用于行为操作(如烘焙蛋糕)。换言之,向量嵌入在回答关于人物、事物、地点以及行为操作等问题的相似度百分比时,并不具备可靠性。 换句话说,向量嵌入在处理人们可能提出的几乎所有类型的问题上都有其固有的缺陷。
03 RAG 爱好者未曾透露的真相
你可能会怀疑上述例子是否经过了筛选,或者百分比分数是否真的重要。让我们对比一下 RAG 的误导性描述与其实际运作方式。
- RAG 的误导性描述是这样的:将数以百万计的文本片段的向量嵌入存储在向量数据库中。获取用户查询的向量嵌入,然后通过余弦相似度算法,找出与之最匹配的前三个片段,并将这些片段连同用户查询一起发送给大语言模型(LLM)。这被标榜为一种"快速、精确且可扩展"的解决方案(引自一位知名 AI 作者,其公司已培训超过 40 万人------详见下文)。
- 然而,最先进的 RAG 实际操作是这样的:将数千份文档的向量加载到向量数据库中,检索出近 50,000 个字符的文本片段,与用户查询一起发送给 LLM,结果却是一个可靠性不高的 Chatbot(例如,F1 score 低于50)。
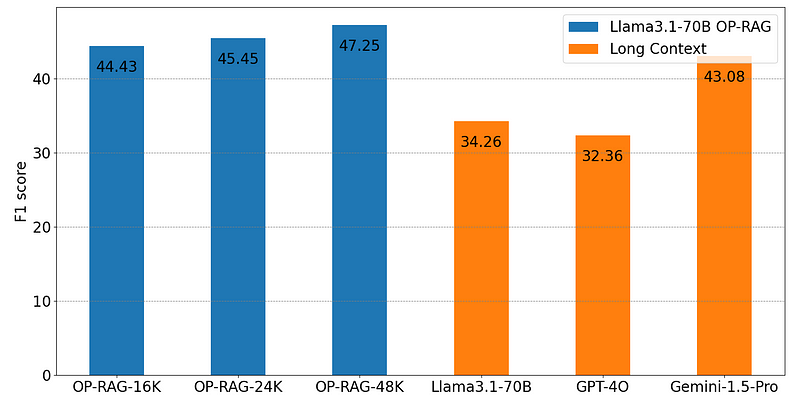
以 2024 年 9 月 3 日发布的 OP-RAG[1] 为例。
![]()
OP-RAG 是 Nvidia 三位研究者的研究成果,因此这项研究来自声誉卓著的研究人员。
再来看上述图表所示的结果,这些是基于 EN.QA 数据集的评估数据。数据集中的前两个问题是:
- 《行尸走肉》第八季的最后一集何时播出?
- 希腊神话中的春之女神是谁?
这些问题的答案都很简短,不需要复杂的解释。而且,这个数据集仅占整个维基百科语料库的3.8%。
尽管 Nvidia 拥有丰富的资源,数据集的大小适中,答案也相对简短,但研究者们还是通过一种新的 RAG 方法,发送 48K 的文本片段并连同用户查询一起,打破了之前的最先进水平,实现了 47.25 的 F1 score(如果发送的内容更少,F1 score 会更低)。
这些 Nvidia 的研究者难道没有意识到,他们本应该能够存储超过现在 25 倍的向量,并且始终能在前三个匹配内容中找到相关答案吗?当然不是。实际上,RAG 在现实世界中的运作并非如此。同样,Nvidia 在 2024 年 11 月 1 日发布的 LongRAG[2] 也是一个绝佳的例证。
04 更大型的 LLMs 也救不了场
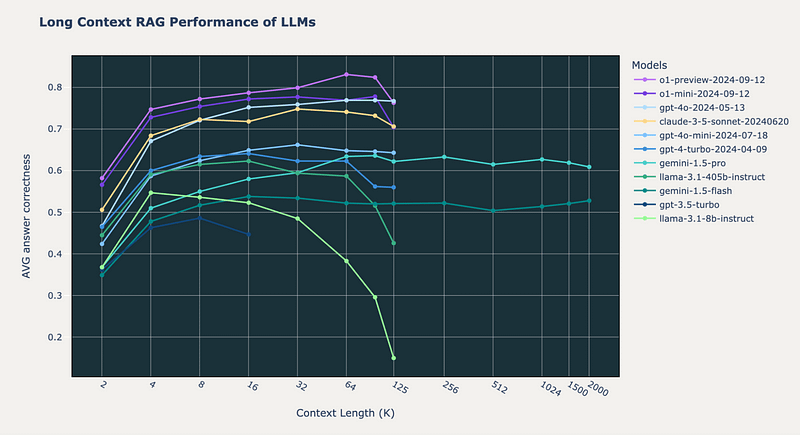
看看 2024 年 10 月 Databricks[3] 发布的研究成果。
![]()
要想正确率超过 80 %,RAG 得向 OpenAI 的 o1 模型发送 64K 字符的文本片段。其他模型,包括 GPT-4o、GPT-4 Turbo 和 Claude-3.5 Sonnet,无一达到这一标准。但 o1 模型的结果问题重重。
首先,其产生信息的幻觉率居高不下。
其次,即便处理的是简短内容,o1 的速度也慢得让人无法忍受。处理 64 K的文本简直慢到让人难以接受。
再者,运行 o1 的成本也是一笔不小的开销。
更有甚者,业界传言称即将推出的一批新模型在性能上并未带来明显提升 ------ Anthropic 甚至无限期推迟了新模型的发布。
即便大模型能够解决问题,它们也会变得更慢、更贵。换句话说,对于实际应用来说,它们未免太慢也太贵了。企业会愿意为一个 Chatbot 支付比真人更高的费用吗?尤其是这个机器人每给出一个不可靠的答案都需要花费近一分钟的时间。
这就是 RAG 的现状。这就是依赖向量嵌入带来的后果。
05 别责怪自己,问题出在它们身上
我之所以撰写此文,是因为我发现论坛上有许多数据科学家和程序员在自我怀疑,认为自己操作不当。通常情况下,总有人会热心地提出一系列解决方案:比如重排序、改写查询语句、使用 BM25 算法、构建知识图谱等等,希望能撞大运找到解决之道。
![]()
但问题在于,成千上万的人所学到的东西根本就是错误的。以下内容摘自一本 2024 年 10 月更新的书籍,作者是一家培训过 40 万人的公司的联合创始人:
RAG 最适合处理那些数据量庞大、无法一次性装入 LLM 上下文窗口,且需要快速响应和低延迟的场景。... 现在,RAG 系统已经有了一套标准的架构,这一架构已经在众多流行框架中得到应用,开发者无需再从头开始。... 数据转换成向量嵌入后,向量数据库就能迅速找到相似项,因为相似项在向量空间中以相近的向量形式存在,我们称之为 vector store(即 storing vectors)。语义搜索在 vector stores 中进行,它通过比较用户查询的嵌入向量与存储数据的嵌入向量来理解用户查询的意义。这样,无论用户查询中使用了哪些关键词,或是搜索的数据类型如何,都能确保搜索结果的相关性和准确性。
数学原理告诉我们,向量嵌入技术并不是通过比较相似度的百分比来定位信息。它们无法理解用户查询的真实意图。即便是面对最简单的用户查询,它们也无法保证搜索结果的相关性,更别提"无论用户查询中使用了哪些关键词,或是搜索的数据类型如何"。
正如 OP-RAG 研究论文所示,即便通过向量搜索能够检索到 400 个数据块,大语言模型(LLM)在最基础的测试中也有超过一半的概率找不到相关信息。尽管如此,教科书上却告诉数据科学家:"在实际操作中,我们可以将整个网站或课程内容上传到 Deep Lake [向量数据库]中,以便在成千上万的文档中进行搜索...... 为了生成回答,我们会提取与用户问题最匹配的前 k 个(比如前 3 个)数据块,整理成提示词,然后以 temperature 参数为 0 的模式发送给模型。"
教科书普遍向学生灌输,向量嵌入技术强大到可以存储"数百万份文档",并且能够从前 3 个最相关的数据块中找到用户查询的答案。但是,根据数学原理和引用的研究结果,这种说法显然是不准确的。
06 通往百分百精确回答的道路
解决问题的关键在于不再单纯依赖向量嵌入技术。
但这并不意味着向量嵌入就毫无价值了。绝非如此! 它们在自然语言处理(NLP)领域扮演着至关重要的角色。
例如,向量嵌入是处理多义词的有力工具。以"glasses"这个词为例,它既可以指代日常饮用的玻璃杯,也可以是指戴在脸上的眼镜。
假设有人提问:朱莉娅·罗伯茨(Julia Roberts)佩戴的是哪种眼镜?通过向量嵌入技术,我们可以确保与眼镜相关的信息位于饮酒玻璃杯相关的信息之上,这正是其语义处理能力的体现。
ChatGPT 的问世,在数据科学界引发了一种不太乐观的变化。像 synonyms、hyponyms、hypernyms、 holonyms 等 NLP 的重要工具,被边缘化,转而更多地关注 Chatbot 的查询。
无疑,大语言模型(LLMs)确实简化了 NLP 的某些方面。但目前,我们似乎把有价值的技术也一同舍弃了。
LLMs 和向量嵌入技术是 NLP 的关键技术,但它们并非完整的解决方案。
举个例子,许多公司发现,当 Chatbot 无法展示访客所需的产品清单时,访客往往会选择离开。为此,这些公司尝试用基于同义词的搜索来替代传统的关键字搜索。
基于同义词的搜索确实能够找到关键字搜索遗漏的产品,但这是有代价的。由于一词多义的存在,常常会有不相关的信息覆盖了访客真正想要的内容。比如,一个想买饮酒玻璃杯的访客,可能会看到一大堆眼镜的清单。
面对这种情况,我们不必全盘否定,向量嵌入技术恰好可以发挥作用。我们不应完全依赖向量嵌入,而应将其作为搜索结果的优化工具。在基于同义词的搜索基础上,利用向量嵌入将最相关的结果推至前列。
Thanks for reading!
Hope you have enjoyed and learned new things from this blog!
About the authors
Michael Wood
AI Engineer and Full-Stack Developer.
Personal site: https://michaelcalvinwood.net.
END
本期互动内容 🍻
❓如果不完全依赖向量嵌入,你认为RAG系统还有哪些可行的信息检索优化路径?欢迎分享你的技术构想。
🔗文中链接🔗
[1]https://arxiv.org/html/2409.01666v1
[2]https://arxiv.org/html/2410.18050v2
[3]https://www.databricks.com/blog/long-context-rag-capabilities-openai-o1-and-google-gemini
原文链接:
https://blog.cubed.run/the-insanity-of-relying-on-vector-embeddings-why-rag-fails-be73554490b2