前言
io hang对于数据库/存储系统而言是致命的,因此,如何模拟一个较为真实的io hang环境,并对自己的系统代码进行测试显得尤为重要。io hang的模拟根据模拟的层次可以有很多方法,比较简单的有使用LD_PRELOAD对用户态函数进行偷梁换柱、或者使用Fuse实现用户态文件系统、稍微深一点的有使用systemtap工具hook内核系统调用,还有一些其他的内核错误注入工具等。这些io hang模拟方法虽然层次不同,但是它们其实并没有模拟到最底层,也就是不能模拟完整的io路径。通常,我们所谓的io hang,都是指最底层的物理设备(磁盘)出现问题,比如坏块过多导致整理gc延迟过大、或者磁盘直接出现硬件故障无法正常读写数据等。可以看到,我们需要模拟这种块设备的io hang,才能最接近真实的io hang场景。
那么如何才能对一个块设备进行模拟,其实,模拟一个磁盘还是很简单的,就是写一个简单的块设备驱动就好了(参考LDD3中subll的例子很简单)。当然,如果懒得写,在linux内核中,我们也可以在源码/driver/block目录下找到一个块设备驱动,如果用过linux下的ramdisk设备(通常为/dev/ram0、/dev/ram1等等),那么就会对这个代码很熟悉。使用ramdisk类似的方式,不但可以完整的产生一个块设备,和真实磁盘相比,还不用关心具体设备协议(如nvme、ahci等),可以说非常方便了。
这里直接使用ramdisk驱动,稍作修改。
块设备驱动
首先,在内核中找到你机器上对应内核版本的代码,比如:https://elixir.bootlin.com/linux/v3.10/source/drivers/block/brd.c ,然后在文件中DECLARE_WAIT_QUEUE_HEAD(io_hang_q)声明一个等待队列,因为我们主要测试write/read hang,因此这里我们直接在copy_to_brd(表示从用户态拷贝数据到ramdisk)和copy_from_brd(表示从ramdisk读数据到用户态)两个函数中分别加入如下代码,表示如果io_hang不为0,则在TASK_UNINTERRUPTIBLE状态睡眠io_hang秒(或者io_hang被修改为0)。
if(io_hang){
pr_info("Simulation of IO hang for read ,will hang %d seconds\n",io_hang);
wait_event_timeout(io_hang_q, io_hang == 0,msecs_to_jiffies(io_hang * 1000));
pr_info("Simulation of IO hang for read finish\n");
}
if(io_hang){
pr_info("Simulation of IO hang for read ,will hang %d seconds\n",io_hang);
wait_event_timeout(io_hang_q, io_hang == 0,msecs_to_jiffies(io_hang * 1000));
pr_info("Simulation of IO hang for read finish\n");
}
同时,我们需要一个参数来控制ramdisk的磁盘行为(它一开始不能hang,因为我们需要格式化文件系统,写superblock等),这里只要加一个开关控制:
module_param(io_hang,int,S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
MODULE_PARM_DESC(io_hang,"io hang switch");
这里注意参数的权限设置,必须要能在用户态可以修改,后续我们将通过用户态sysfs对这个参数进行修改。
这些改动做完之后,写一个简单的Makefile将其编译为内核模块(注:为了简明我把brd.c改为ramdisk.c):
obj-m := ramdisk.o
SRC = /lib/modules/$(shell uname -r)/build
ko:
make -C $(SRC) M=$(PWD) modules
clean:
make -C $(SRC) M=$(PWD) clean
然后直接make即可生成ramdisk.ko。
ramdisk.c代码如下:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/moduleparam.h>
#include <linux/major.h>
#include <linux/blkdev.h>
#include <linux/bio.h>
#include <linux/highmem.h>
#include <linux/mutex.h>
#include <linux/radix-tree.h>
#include <linux/fs.h>
#include <linux/slab.h>
#ifdef CONFIG_BLK_DEV_RAM_DAX
#include <linux/pfn_t.h>
#endif
#include <asm/uaccess.h>
#define SECTOR_SHIFT 9
#define PAGE_SECTORS_SHIFT (PAGE_SHIFT - SECTOR_SHIFT)
#define PAGE_SECTORS (1 << PAGE_SECTORS_SHIFT)
DECLARE_WAIT_QUEUE_HEAD(io_hang_q);
static int io_hang = 0;
/*
* Each block ramdisk device has a radix_tree brd_pages of pages that stores
* the pages containing the block device's contents. A brd page's ->index is
* its offset in PAGE_SIZE units. This is similar to, but in no way connected
* with, the kernel's pagecache or buffer cache (which sit above our block
* device).
*/
struct brd_device {
int brd_number;
struct request_queue *brd_queue;
struct gendisk *brd_disk;
struct list_head brd_list;
/*
* Backing store of pages and lock to protect it. This is the contents
* of the block device.
*/
spinlock_t brd_lock;
struct radix_tree_root brd_pages;
};
/*
* Look up and return a brd's page for a given sector.
*/
static DEFINE_MUTEX(brd_mutex);
static struct page *brd_lookup_page(struct brd_device *brd, sector_t sector)
{
pgoff_t idx;
struct page *page;
/*
* The page lifetime is protected by the fact that we have opened the
* device node -- brd pages will never be deleted under us, so we
* don't need any further locking or refcounting.
*
* This is strictly true for the radix-tree nodes as well (ie. we
* don't actually need the rcu_read_lock()), however that is not a
* documented feature of the radix-tree API so it is better to be
* safe here (we don't have total exclusion from radix tree updates
* here, only deletes).
*/
rcu_read_lock();
idx = sector >> PAGE_SECTORS_SHIFT; /* sector to page index */
page = radix_tree_lookup(&brd->brd_pages, idx);
rcu_read_unlock();
BUG_ON(page && page->index != idx);
return page;
}
/*
* Look up and return a brd's page for a given sector.
* If one does not exist, allocate an empty page, and insert that. Then
* return it.
*/
static struct page *brd_insert_page(struct brd_device *brd, sector_t sector)
{
pgoff_t idx;
struct page *page;
gfp_t gfp_flags;
page = brd_lookup_page(brd, sector);
if (page)
return page;
/*
* Must use NOIO because we don't want to recurse back into the
* block or filesystem layers from page reclaim.
*
* Cannot support DAX and highmem, because our ->direct_access
* routine for DAX must return memory that is always addressable.
* If DAX was reworked to use pfns and kmap throughout, this
* restriction might be able to be lifted.
*/
gfp_flags = GFP_NOIO | __GFP_ZERO;
#ifndef CONFIG_BLK_DEV_RAM_DAX
gfp_flags |= __GFP_HIGHMEM;
#endif
page = alloc_page(gfp_flags);
if (!page)
return NULL;
if (radix_tree_preload(GFP_NOIO)) {
__free_page(page);
return NULL;
}
spin_lock(&brd->brd_lock);
idx = sector >> PAGE_SECTORS_SHIFT;
page->index = idx;
if (radix_tree_insert(&brd->brd_pages, idx, page)) {
__free_page(page);
page = radix_tree_lookup(&brd->brd_pages, idx);
BUG_ON(!page);
BUG_ON(page->index != idx);
}
spin_unlock(&brd->brd_lock);
radix_tree_preload_end();
return page;
}
static void brd_free_page(struct brd_device *brd, sector_t sector)
{
struct page *page;
pgoff_t idx;
spin_lock(&brd->brd_lock);
idx = sector >> PAGE_SECTORS_SHIFT;
page = radix_tree_delete(&brd->brd_pages, idx);
spin_unlock(&brd->brd_lock);
if (page)
__free_page(page);
}
static void brd_zero_page(struct brd_device *brd, sector_t sector)
{
struct page *page;
page = brd_lookup_page(brd, sector);
if (page)
clear_highpage(page);
}
/*
* Free all backing store pages and radix tree. This must only be called when
* there are no other users of the device.
*/
#define FREE_BATCH 16
static void brd_free_pages(struct brd_device *brd)
{
unsigned long pos = 0;
struct page *pages[FREE_BATCH];
int nr_pages;
do {
int i;
nr_pages = radix_tree_gang_lookup(&brd->brd_pages,
(void **)pages, pos, FREE_BATCH);
for (i = 0; i < nr_pages; i++) {
void *ret;
BUG_ON(pages[i]->index < pos);
pos = pages[i]->index;
ret = radix_tree_delete(&brd->brd_pages, pos);
BUG_ON(!ret || ret != pages[i]);
__free_page(pages[i]);
}
pos++;
/*
* This assumes radix_tree_gang_lookup always returns as
* many pages as possible. If the radix-tree code changes,
* so will this have to.
*/
} while (nr_pages == FREE_BATCH);
}
/*
* copy_to_brd_setup must be called before copy_to_brd. It may sleep.
*/
static int copy_to_brd_setup(struct brd_device *brd, sector_t sector, size_t n)
{
unsigned int offset = (sector & (PAGE_SECTORS-1)) << SECTOR_SHIFT;
size_t copy;
copy = min_t(size_t, n, PAGE_SIZE - offset);
if (!brd_insert_page(brd, sector))
return -ENOSPC;
if (copy < n) {
sector += copy >> SECTOR_SHIFT;
if (!brd_insert_page(brd, sector))
return -ENOSPC;
}
return 0;
}
static void discard_from_brd(struct brd_device *brd,
sector_t sector, size_t n)
{
while (n >= PAGE_SIZE) {
/*
* Don't want to actually discard pages here because
* re-allocating the pages can result in writeback
* deadlocks under heavy load.
*/
if (0)
brd_free_page(brd, sector);
else
brd_zero_page(brd, sector);
sector += PAGE_SIZE >> SECTOR_SHIFT;
n -= PAGE_SIZE;
}
}
/*
* Copy n bytes from src to the brd starting at sector. Does not sleep.
*/
static void copy_to_brd(struct brd_device *brd, const void *src,
sector_t sector, size_t n)
{
struct page *page;
void *dst;
unsigned int offset = (sector & (PAGE_SECTORS-1)) << SECTOR_SHIFT;
size_t copy;
/**
* Simulation of IO hang
*
* per 1 second
*/
if(io_hang){
pr_info("Simulation of IO hang for write,will hang %d seconds\n",io_hang);
wait_event_timeout(io_hang_q, io_hang == 0,msecs_to_jiffies(io_hang * 1000));
pr_info("Simulation of IO hang for write finish\n");
}
copy = min_t(size_t, n, PAGE_SIZE - offset);
page = brd_lookup_page(brd, sector);
BUG_ON(!page);
dst = kmap_atomic(page);
memcpy(dst + offset, src, copy);
kunmap_atomic(dst);
if (copy < n) {
src += copy;
sector += copy >> SECTOR_SHIFT;
copy = n - copy;
page = brd_lookup_page(brd, sector);
BUG_ON(!page);
dst = kmap_atomic(page);
memcpy(dst, src, copy);
kunmap_atomic(dst);
}
}
/*
* Copy n bytes to dst from the brd starting at sector. Does not sleep.
*/
static void copy_from_brd(void *dst, struct brd_device *brd,
sector_t sector, size_t n)
{
struct page *page;
void *src;
unsigned int offset = (sector & (PAGE_SECTORS-1)) << SECTOR_SHIFT;
size_t copy;
/**
* Simulation of IO hang
*
* per 1 second
*/
if(io_hang){
pr_info("Simulation of IO hang for read ,will hang %d seconds\n",io_hang);
wait_event_timeout(io_hang_q, io_hang == 0,msecs_to_jiffies(io_hang * 1000));
pr_info("Simulation of IO hang for read finish\n");
}
copy = min_t(size_t, n, PAGE_SIZE - offset);
page = brd_lookup_page(brd, sector);
if (page) {
src = kmap_atomic(page);
memcpy(dst, src + offset, copy);
kunmap_atomic(src);
} else
memset(dst, 0, copy);
if (copy < n) {
dst += copy;
sector += copy >> SECTOR_SHIFT;
copy = n - copy;
page = brd_lookup_page(brd, sector);
if (page) {
src = kmap_atomic(page);
memcpy(dst, src, copy);
kunmap_atomic(src);
} else
memset(dst, 0, copy);
}
}
/*
* Process a single bvec of a bio.
*/
static int brd_do_bvec(struct brd_device *brd, struct page *page,
unsigned int len, unsigned int off, bool is_write,
sector_t sector)
{
void *mem;
int err = 0;
if (is_write) {
err = copy_to_brd_setup(brd, sector, len);
if (err)
goto out;
}
mem = kmap_atomic(page);
if (!is_write) {
copy_from_brd(mem + off, brd, sector, len);
flush_dcache_page(page);
} else {
flush_dcache_page(page);
copy_to_brd(brd, mem + off, sector, len);
}
kunmap_atomic(mem);
out:
return err;
}
static blk_qc_t brd_make_request(struct request_queue *q, struct bio *bio)
{
struct block_device *bdev = bio->bi_bdev;
struct brd_device *brd = bdev->bd_disk->private_data;
struct bio_vec bvec;
sector_t sector;
struct bvec_iter iter;
sector = bio->bi_iter.bi_sector;
if (bio_end_sector(bio) > get_capacity(bdev->bd_disk))
goto io_error;
if (unlikely(bio_op(bio) == REQ_OP_DISCARD)) {
if (sector & ((PAGE_SIZE >> SECTOR_SHIFT) - 1) ||
bio->bi_iter.bi_size & ~PAGE_MASK)
goto io_error;
discard_from_brd(brd, sector, bio->bi_iter.bi_size);
goto out;
}
bio_for_each_segment(bvec, bio, iter) {
unsigned int len = bvec.bv_len;
int err;
err = brd_do_bvec(brd, bvec.bv_page, len, bvec.bv_offset,
op_is_write(bio_op(bio)), sector);
if (err)
goto io_error;
sector += len >> SECTOR_SHIFT;
}
out:
bio_endio(bio);
return BLK_QC_T_NONE;
io_error:
bio_io_error(bio);
return BLK_QC_T_NONE;
}
static int brd_rw_page(struct block_device *bdev, sector_t sector,
struct page *page, bool is_write)
{
struct brd_device *brd = bdev->bd_disk->private_data;
int err = brd_do_bvec(brd, page, PAGE_SIZE, 0, is_write, sector);
page_endio(page, is_write, err);
return err;
}
#ifdef CONFIG_BLK_DEV_RAM_DAX
static long brd_direct_access(struct block_device *bdev, sector_t sector,
void **kaddr, pfn_t *pfn, long size)
{
struct brd_device *brd = bdev->bd_disk->private_data;
struct page *page;
if (!brd)
return -ENODEV;
page = brd_insert_page(brd, sector);
if (!page)
return -ENOSPC;
*kaddr = page_address(page);
*pfn = page_to_pfn_t(page);
return PAGE_SIZE;
}
#else
#define brd_direct_access NULL
#endif
static int brd_ioctl(struct block_device *bdev, fmode_t mode,
unsigned int cmd, unsigned long arg)
{
int error;
struct brd_device *brd = bdev->bd_disk->private_data;
if (cmd != BLKFLSBUF)
return -ENOTTY;
/*
* ram device BLKFLSBUF has special semantics, we want to actually
* release and destroy the ramdisk data.
*/
mutex_lock(&brd_mutex);
mutex_lock(&bdev->bd_mutex);
error = -EBUSY;
if (bdev->bd_openers <= 1) {
/*
* Kill the cache first, so it isn't written back to the
* device.
*
* Another thread might instantiate more buffercache here,
* but there is not much we can do to close that race.
*/
kill_bdev(bdev);
brd_free_pages(brd);
error = 0;
}
mutex_unlock(&bdev->bd_mutex);
mutex_unlock(&brd_mutex);
return error;
}
static const struct block_device_operations brd_fops = {
.owner = THIS_MODULE,
.rw_page = brd_rw_page,
.ioctl = brd_ioctl,
.direct_access = brd_direct_access,
};
/*
* And now the modules code and kernel interface.
*/
static int rd_nr = CONFIG_BLK_DEV_RAM_COUNT;
module_param(rd_nr, int, S_IRUGO);
MODULE_PARM_DESC(rd_nr, "Maximum number of brd devices");
int rd_size = CONFIG_BLK_DEV_RAM_SIZE;
module_param(rd_size, int, S_IRUGO);
MODULE_PARM_DESC(rd_size, "Size of each RAM disk in kbytes.");
static int max_part = 1;
module_param(max_part, int, S_IRUGO);
MODULE_PARM_DESC(max_part, "Num Minors to reserve between devices");
module_param(io_hang,int,S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
MODULE_PARM_DESC(io_hang,"io hang switch");
MODULE_LICENSE("GPL");
MODULE_ALIAS_BLOCKDEV_MAJOR(RAMDISK_MAJOR);
MODULE_ALIAS("rd");
#ifndef MODULE
/* Legacy boot options - nonmodular */
static int __init ramdisk_size(char *str)
{
rd_size = simple_strtol(str, NULL, 0);
return 1;
}
__setup("ramdisk_size=", ramdisk_size);
#endif
/*
* The device scheme is derived from loop.c. Keep them in synch where possible
* (should share code eventually).
*/
static LIST_HEAD(brd_devices);
static DEFINE_MUTEX(brd_devices_mutex);
static struct brd_device *brd_alloc(int i)
{
struct brd_device *brd;
struct gendisk *disk;
brd = kzalloc(sizeof(*brd), GFP_KERNEL);
if (!brd)
goto out;
brd->brd_number = i;
spin_lock_init(&brd->brd_lock);
INIT_RADIX_TREE(&brd->brd_pages, GFP_ATOMIC);
brd->brd_queue = blk_alloc_queue(GFP_KERNEL);
if (!brd->brd_queue)
goto out_free_dev;
blk_queue_make_request(brd->brd_queue, brd_make_request);
blk_queue_max_hw_sectors(brd->brd_queue, 1024);
blk_queue_bounce_limit(brd->brd_queue, BLK_BOUNCE_ANY);
/* This is so fdisk will align partitions on 4k, because of
* direct_access API needing 4k alignment, returning a PFN
* (This is only a problem on very small devices <= 4M,
* otherwise fdisk will align on 1M. Regardless this call
* is harmless)
*/
blk_queue_physical_block_size(brd->brd_queue, PAGE_SIZE);
brd->brd_queue->limits.discard_granularity = PAGE_SIZE;
blk_queue_max_discard_sectors(brd->brd_queue, UINT_MAX);
brd->brd_queue->limits.discard_zeroes_data = 1;
queue_flag_set_unlocked(QUEUE_FLAG_DISCARD, brd->brd_queue);
#ifdef CONFIG_BLK_DEV_RAM_DAX
queue_flag_set_unlocked(QUEUE_FLAG_DAX, brd->brd_queue);
#endif
disk = brd->brd_disk = alloc_disk(max_part);
if (!disk)
goto out_free_queue;
disk->major = RAMDISK_MAJOR;
disk->first_minor = i * max_part;
disk->fops = &brd_fops;
disk->private_data = brd;
disk->queue = brd->brd_queue;
disk->flags = GENHD_FL_EXT_DEVT;
sprintf(disk->disk_name, "ramdisk%d", i);
set_capacity(disk, rd_size * 2);
return brd;
out_free_queue:
blk_cleanup_queue(brd->brd_queue);
out_free_dev:
kfree(brd);
out:
return NULL;
}
static void brd_free(struct brd_device *brd)
{
put_disk(brd->brd_disk);
blk_cleanup_queue(brd->brd_queue);
brd_free_pages(brd);
kfree(brd);
}
static struct brd_device *brd_init_one(int i, bool *new)
{
struct brd_device *brd;
*new = false;
list_for_each_entry(brd, &brd_devices, brd_list) {
if (brd->brd_number == i)
goto out;
}
brd = brd_alloc(i);
if (brd) {
add_disk(brd->brd_disk);
list_add_tail(&brd->brd_list, &brd_devices);
}
*new = true;
out:
return brd;
}
static void brd_del_one(struct brd_device *brd)
{
list_del(&brd->brd_list);
del_gendisk(brd->brd_disk);
brd_free(brd);
}
static struct kobject *brd_probe(dev_t dev, int *part, void *data)
{
struct brd_device *brd;
struct kobject *kobj;
bool new;
mutex_lock(&brd_devices_mutex);
brd = brd_init_one(MINOR(dev) / max_part, &new);
kobj = brd ? get_disk(brd->brd_disk) : NULL;
mutex_unlock(&brd_devices_mutex);
if (new)
*part = 0;
return kobj;
}
static int __init brd_init(void)
{
struct brd_device *brd, *next;
int i;
/*
* brd module now has a feature to instantiate underlying device
* structure on-demand, provided that there is an access dev node.
*
* (1) if rd_nr is specified, create that many upfront. else
* it defaults to CONFIG_BLK_DEV_RAM_COUNT
* (2) User can further extend brd devices by create dev node themselves
* and have kernel automatically instantiate actual device
* on-demand. Example:
* mknod /path/devnod_name b 1 X # 1 is the rd major
* fdisk -l /path/devnod_name
* If (X / max_part) was not already created it will be created
* dynamically.
*/
if (register_blkdev(RAMDISK_MAJOR, "ramdisk"))
return -EIO;
if (unlikely(!max_part))
max_part = 1;
for (i = 0; i < rd_nr; i++) {
brd = brd_alloc(i);
if (!brd)
goto out_free;
list_add_tail(&brd->brd_list, &brd_devices);
}
/* point of no return */
list_for_each_entry(brd, &brd_devices, brd_list)
add_disk(brd->brd_disk);
blk_register_region(MKDEV(RAMDISK_MAJOR, 0), 1UL << MINORBITS,
THIS_MODULE, brd_probe, NULL, NULL);
pr_info("brd: module loaded\n");
return 0;
out_free:
list_for_each_entry_safe(brd, next, &brd_devices, brd_list) {
list_del(&brd->brd_list);
brd_free(brd);
}
unregister_blkdev(RAMDISK_MAJOR, "ramdisk");
pr_info("brd: module NOT loaded !!!\n");
return -ENOMEM;
}
static void __exit brd_exit(void)
{
struct brd_device *brd, *next;
list_for_each_entry_safe(brd, next, &brd_devices, brd_list)
brd_del_one(brd);
blk_unregister_region(MKDEV(RAMDISK_MAJOR, 0), 1UL << MINORBITS);
unregister_blkdev(RAMDISK_MAJOR, "ramdisk");
pr_info("brd: module unloaded\n");
}
module_init(brd_init);
module_exit(brd_exit);
格式化、挂载
上面我们实现了一个块设备驱动,并编译出来一个ramdisk.ko,现在可以注册这个块设备驱动:
sudo insmod ramdisk.ko
![]()
可以看到/dev下多出来很多ramdisk设备,这些都是块设备,你可以把它当做一个真实的磁盘,只是这些磁盘都是memory backend。
这里我使用ramdisk0做测试,首先对其格式化:
mkfs -t ext4 /dev/ramdisk0
然后将其挂载到一个目录(选一个测试目录,比如io_hang_test)
sudo mount -t ext4 /dev/ramdisk0 /mnt/io_hang_test
挂载之后可以运行mount命令看下挂载效果(最后一行)。
![]()
控制
好了,现在/mnt/io_hang_test目录对应的就是我们的ramdisk0,所有在/mnt/io_hang_test目录下进行的io操作,都会经过ext4文件系统后转为对ramdisk0的读写操作,可以直接在上面创建一个文件试一试,只是这些文件是在内存里,重启后就丢失了。
如果前面一切正常,则可以开始模拟io hang。还记得之前那个内核参数io_hang,它目前还是0,因为不会io hang,现在来修改它:
sudo bash -c " echo 10 > /sys/module/ramdisk/parameters/io_hang"
这条命令会修改内核参数io_hang,将其值改为10,这样的话下一次读写的时候,ramdisk驱动会对每一次的read/write hang 10 秒钟(不精确)。如果想关闭io hang,执行:
sudo bash -c " echo 0 > /sys/module/ramdisk/parameters/io_hang"
测试
为了测试read和write,我这里写一个简单的测试代码,测试read和write,同时,为了避开page cache的影响和使用同步io,使用O_DIRECT和O_SYNC方式open。
#define _GNU_SOURCE
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <sys/mman.h>
#define BUF_SIZE 1024
int main(){
int fd,size,len;
int ret = 0;
char *write_buf,*read_buf;
ret = posix_memalign((void **)&write_buf, 512, BUF_SIZE);
if (ret) {
perror("posix_memalign:");
exit(1);
}
ret = posix_memalign((void **)&read_buf, 512, BUF_SIZE);
if (ret) {
perror("posix_memalign:");
exit(1);
}
strcpy(write_buf,"direct osync mode");
len = strlen("direct osync mode");
if ((fd = open("hello.c", O_CREAT | O_TRUNC | O_RDWR | O_DIRECT | O_SYNC,0666 ))<0) {
perror("open:");
exit(1);
}
if ((size = write(fd, write_buf, BUF_SIZE)) < 0){
perror("write:");
exit(1);
}
lseek(fd, 0, SEEK_SET );
if ((size = read( fd, read_buf, BUF_SIZE))<0) {
perror("read:");
exit(1);
}
if(strncmp(read_buf,write_buf,len) != 0){
perror("strncmp:");
exit(1);
}
if (close(fd) < 0 ) {
perror("close:");
exit(1);
}
}
假设测试代码为test.c,则为了测试方便可以写一个简单的shell:
#!/bin/sh
mkdir io_hang_test
gcc -o test test.c
sudo umount io_hang_test
sudo rmmod ramdisk.ko
make
sudo insmod ramdisk.ko
sudo mkfs -t ext4 /dev/ramdisk0
sudo mount -t ext4 /dev/ramdisk0 io_hang_test
sudo cp test io_hang_test/
然后在io_hang_test目录下sudo ./test,然后看test进程处于D状态。
![]()
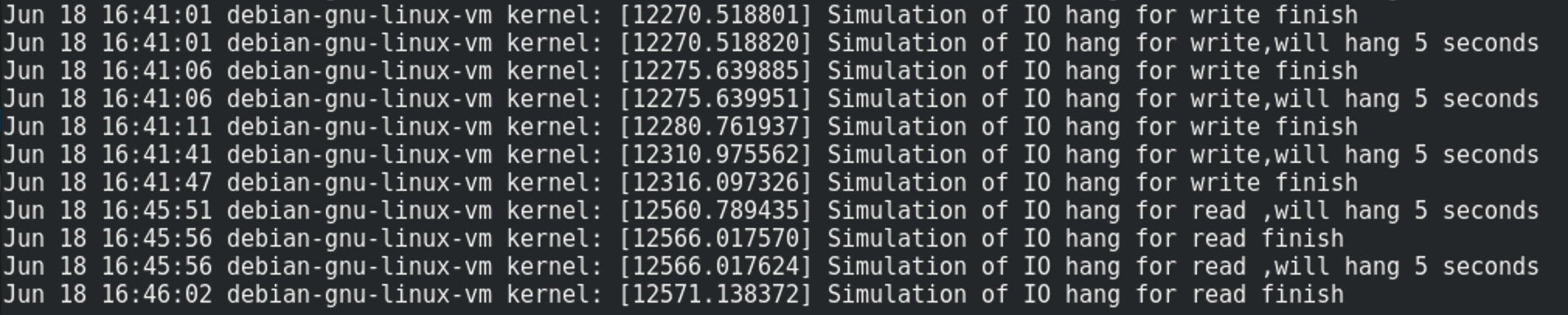
同时sudo tail -f /var/log/kern.log看下内核的持续输出。
![]()
总结
本文只是提供了一种较为简单、在块设备层模拟io hang的方法。好处是不依赖真实磁盘设备、不会影响系统真实磁盘的读写(磁盘大小可自定义),只有处于测试挂载点的读写才会hang,并且umount之后自动清理测试文件,没有垃圾。在此基础上,还可以定制驱动扩展自己的io hang策略(本文只阐述了一种简单的延时hang策略),控制性很强。
这里之所以不使用自己写块设备驱动,是因为内核版本很多,这样在调试不同内核版本时需要移植,如果直接使用ramdisk,那么内核中不同版本下都直接有相应的源码(3.x和5.x差别还是很大的),稍微加一下自己的代码就可以编译使用。非常方便。
如果非要自己写一个简单一点的ramdisk,也可以参考下面的代码(参考LDD,修改支持blk_mq):
#include <linux/module.h>
#include <linux/moduleparam.h>
#include <linux/init.h>
#include <linux/sched.h>
#include <linux/kernel.h> /* printk() */
#include <linux/slab.h> /* kmalloc() */
#include <linux/fs.h> /* everything... */
#include <linux/errno.h> /* error codes */
#include <linux/types.h> /* size_t */
#include <linux/fcntl.h> /* O_ACCMODE */
#include <linux/hdreg.h> /* HDIO_GETGEO */
#include <linux/kdev_t.h>
#include <linux/vmalloc.h>
#include <linux/genhd.h>
#include <linux/blk-mq.h>
#include <linux/buffer_head.h>
#include <linux/bio.h>
#ifndef BLK_STS_OK
typedef int blk_status_t;
#define BLK_STS_OK 0
#define OLDER_KERNEL 1
#endif
#ifndef BLK_STS_IOERR
#define BLK_STS_IOERR 10
#endif
#ifndef SECTOR_SHIFT
#define SECTOR_SHIFT 9
#endif
#define size_to_sectors(size) ((size) >> SECTOR_SHIFT)
#define sectors_to_size(size) ((size) << SECTOR_SHIFT)
MODULE_LICENSE("Dual BSD/GPL");
static int sbull_major;
module_param(sbull_major, int, 0);
static int logical_block_size = 512;
module_param(logical_block_size, int, 0);
static char* disk_size = "256M";
module_param(disk_size, charp, 0);
static int ndevices = 1;
module_param(ndevices, int, 0);
static bool debug = false;
module_param(debug, bool, false);
/*
* The different "request modes" we can use.
*/
enum {
RM_SIMPLE = 0, /* The extra-simple request function */
RM_FULL = 1, /* The full-blown version */
RM_NOQUEUE = 2, /* Use make_request */
};
/*
* Minor number and partition management.
*/
#define SBULL_MINORS 16
/*
* We can tweak our hardware sector size, but the kernel talks to us
* in terms of small sectors, always.
*/
#define KERNEL_SECTOR_SIZE 512
/*
* The internal representation of our device.
*/
struct sbull_dev {
int size; /* Device size in sectors */
u8 *data; /* The data array */
spinlock_t lock; /* For mutual exclusion */
struct request_queue *queue; /* The device request queue */
struct gendisk *gd; /* The gendisk structure */
struct blk_mq_tag_set tag_set;
};
static struct sbull_dev *Devices;
/* Handle an I/O request */
static blk_status_t sbull_transfer(struct sbull_dev *dev, unsigned long sector,
unsigned long nsect, char *buffer, int op)
{
unsigned long offset = sectors_to_size(sector);
unsigned long nbytes = sectors_to_size(nsect);
if ((offset + nbytes) > dev->size) {
pr_notice("Beyond-end write (%ld %ld)\n", offset, nbytes);
return BLK_STS_IOERR;
}
if (debug)
pr_info("%s: %s, sector: %ld, nsectors: %ld, offset: %ld,"
" nbytes: %ld",
dev->gd->disk_name,
op == REQ_OP_WRITE ? "WRITE" : "READ", sector, nsect,
offset, nbytes);
/* will be only REQ_OP_READ or REQ_OP_WRITE */
if (op == REQ_OP_WRITE)
memcpy(dev->data + offset, buffer, nbytes);
else
memcpy(buffer, dev->data + offset, nbytes);
return BLK_STS_OK;
}
static blk_status_t sbull_queue_rq(struct blk_mq_hw_ctx *hctx,
const struct blk_mq_queue_data *bd)
{
struct request *req = bd->rq;
struct sbull_dev *dev = req->rq_disk->private_data;
int op = req_op(req);
blk_status_t ret;
blk_mq_start_request(req);
spin_lock(&dev->lock);
if (op != REQ_OP_READ && op != REQ_OP_WRITE) {
pr_notice("Skip non-fs request\n");
blk_mq_end_request(req, BLK_STS_IOERR);
spin_unlock(&dev->lock);
return BLK_STS_IOERR;
}
ret = sbull_transfer(dev, blk_rq_pos(req),
blk_rq_cur_sectors(req),
bio_data(req->bio), op);
blk_mq_end_request(req, ret);
spin_unlock(&dev->lock);
return ret;
}
/*
* The device operations structure.
*/
static const struct block_device_operations sbull_ops = {
.owner = THIS_MODULE,
};
static const struct blk_mq_ops sbull_mq_ops = {
.queue_rq = sbull_queue_rq,
};
static struct request_queue *create_req_queue(struct blk_mq_tag_set *set)
{
struct request_queue *q;
#ifndef OLDER_KERNEL
q = blk_mq_init_sq_queue(set, &sbull_mq_ops,
2, BLK_MQ_F_SHOULD_MERGE | BLK_MQ_F_BLOCKING);
#else
int ret;
memset(set, 0, sizeof(*set));
set->ops = &sbull_mq_ops;
set->nr_hw_queues = 1;
/*set->nr_maps = 1;*/
set->queue_depth = 2;
set->numa_node = NUMA_NO_NODE;
set->flags = BLK_MQ_F_SHOULD_MERGE | BLK_MQ_F_BLOCKING;
ret = blk_mq_alloc_tag_set(set);
if (ret)
return ERR_PTR(ret);
q = blk_mq_init_queue(set);
if (IS_ERR(q)) {
blk_mq_free_tag_set(set);
return q;
}
#endif
return q;
}
/*
* Set up our internal device.
*/
static void setup_device(struct sbull_dev *dev, int which)
{
long long sbull_size = memparse(disk_size, NULL);
memset(dev, 0, sizeof(struct sbull_dev));
dev->size = sbull_size;
dev->data = vzalloc(dev->size);
if (dev->data == NULL) {
pr_notice("vmalloc failure.\n");
return;
}
spin_lock_init(&dev->lock);
dev->queue = create_req_queue(&dev->tag_set);
if (IS_ERR(dev->queue))
goto out_vfree;
blk_queue_logical_block_size(dev->queue, logical_block_size);
dev->queue->queuedata = dev;
/*
* And the gendisk structure.
*/
dev->gd = alloc_disk(SBULL_MINORS);
if (!dev->gd) {
pr_notice("alloc_disk failure\n");
goto out_vfree;
}
dev->gd->major = sbull_major;
dev->gd->first_minor = which*SBULL_MINORS;
dev->gd->fops = &sbull_ops;
dev->gd->queue = dev->queue;
dev->gd->private_data = dev;
snprintf(dev->gd->disk_name, 32, "myramdisk%c", which + 'a');
set_capacity(dev->gd, size_to_sectors(sbull_size));
add_disk(dev->gd);
return;
out_vfree:
if (dev->data)
vfree(dev->data);
}
static int __init sbull_init(void)
{
int i;
/*
* Get registered.
*/
sbull_major = register_blkdev(sbull_major, "myramdisk");
if (sbull_major <= 0) {
pr_warn("myramdisk: unable to get major number\n");
return -EBUSY;
}
/*
* Allocate the device array, and initialize each one.
*/
Devices = kmalloc(ndevices * sizeof(struct sbull_dev), GFP_KERNEL);
if (Devices == NULL)
goto out_unregister;
for (i = 0; i < ndevices; i++)
setup_device(Devices + i, i);
return 0;
out_unregister:
unregister_blkdev(sbull_major, "myramdisk");
return -ENOMEM;
}
static void sbull_exit(void)
{
int i;
for (i = 0; i < ndevices; i++) {
struct sbull_dev *dev = Devices + i;
if (dev->gd) {
del_gendisk(dev->gd);
put_disk(dev->gd);
}
if (dev->queue)
blk_cleanup_queue(dev->queue);
if (dev->data)
vfree(dev->data);
}
unregister_blkdev(sbull_major, "myramdisk");
kfree(Devices);
}
module_init(sbull_init);
module_exit(sbull_exit);