本文整理自 2024 云栖大会,阿里云智能集团高级技术专家聂大鹏、NVIDIA 解决方案架构师金国强演讲议题《Serverless GPU:助力 AI 推理加速》
近年来,AI 技术发展迅猛,企业纷纷寻求将 AI 能力转化为商业价值,然而,在部署 AI 模型推理服务时,却遭遇成本高昂、弹性不足及运维复杂等挑战。本文将探讨云原生 Serverless GPU 如何从根本上解决这些问题,以实现 AI 技术的高效落地。
AI 落地的三大难题与趋势
- 成本高昂: GPU 资源利用率低下,因缺乏 GPU 虚拟化、业务潮汐效应及资源调度问题,导致昂贵的 GPU 显卡未能充分利用。
- 弹性受限: 自建 GPU 集群难以应对流量波动,尤其在实时推理和离线任务处理时,缺乏快速弹性扩展能力。
- 运维复杂: AI 团队不愿承担 GPU 集群的管理和维护,涉及硬件软件维护、故障处理及多业务混部问题。
趋势显示,用户自建 GPU 集群正向云平台 Serverless 形态转变,期望通过低成本、高弹性和免运维方式,专注于业务价值创造。
Serverless GPU 算力创新:助力 AI 落地降本
Serverless GPU 模式通过智能区分 GPU 实例的忙闲状态,提供差异化定价策略,实现了成本优化与性能保障的双重目标。这种模式下的算力供应具备三个显著优势:
- 弹性模式: 无需预留资源,按需快速弹出 GPU 容器,适合准实时或离线场景,大幅降低成本。
- 预留模式: 保证无冷启动,但成本较高,适用于 24/7 连续运行的需求。
- 闲置 GPU 模式: 结合弹性与预留模式的优点,通过区分 GPU 实例的忙闲状态,提供差异化定价,既保证低延迟,又显著降低成本。
![]()
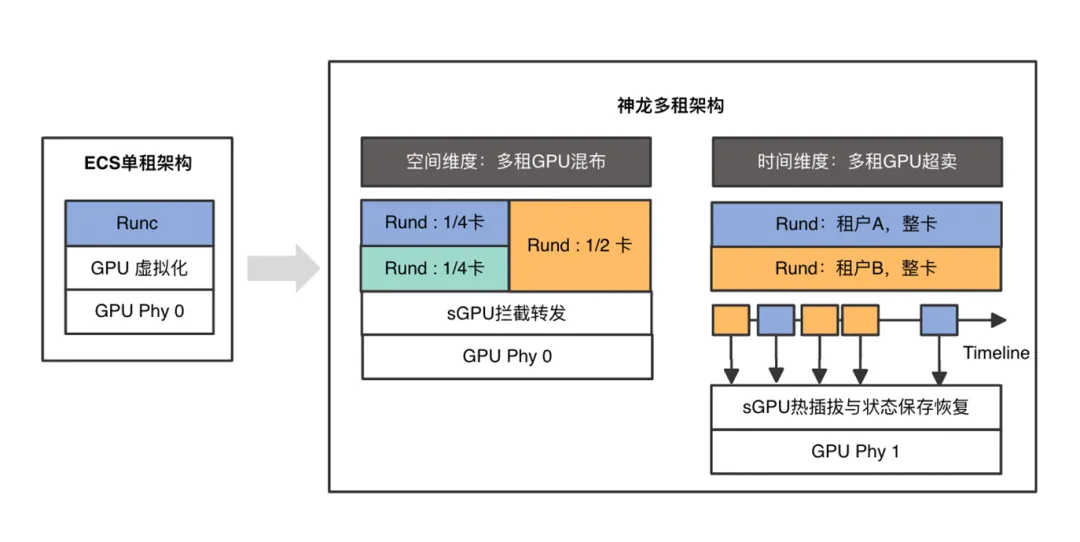
实现这些优势的关键在于阿里云函数计算生态的 GPU 架构升级,即神龙多租 GPU 架构。该架构支持空间维度上的多租户 GPU 卡切分与时间维度上的超卖复用,从而实现秒级弹性 GPU 规格解耦,最终释放更经济高效的 GPU 技术红利。
![]()
闲置 GPU 模式的内部机制与优势
- GPU checkpoint 至内存池,闲置成本远低于 GPU 显存,实现低延时与成本优化。
- 解冻过程根据模型大小决定,冷启动时间控制在合理范围。
- 通过工作负载分析,智能调整 GPU 冻结时机,确保热工作负载性能接近原生 GPU。
神龙多租 GPU 架构与技术创新
- 实现空间维度上的多租户 GPU 切分混布,时间维度上的超卖复用,提高 GPU 资源利用率。
- 提供秒级弹性、GPU 切分规格、CPU/ MEM/GPU 规格解耦、忙闲时分开定价等特性,释放 GPU 技术红利。
随着传统 Web 场景下的调度算法(比如:RR 调度策略、最小连接数调度策略)在 AI 场景有诸多弊端:如恶化后端 GPU 资源饿死胖死现象,造成业务请求 RT 急剧抖动。函数计算平台提供请求负载感知的调度策略,根据函数的请求并发度来最大化压榨后端集群的处理能力,提升用户 GPU 实例、用户自建 GPU 集群的资源利用率。
英伟达案例:NVIDA TensorRT 与 AI 推理加速
阿里云函数计算是一种无服务器(Serverless)计算服务,它允许用户在无需管理底层基础设施的情况下,直接运行代码。函数计算以其高灵活性和弹性扩展能力,让用户专注于业务逻辑的开发,自动处理计算资源的分配、扩展和维护。此外,函数计算支持 GPU 算力,使其成为 AI 任务的理想选择,如模型推理和图像生成,能够大幅提高效率并降低计算成本。
NVIDIA TensorRT 是英伟达为深度学习推理优化的高性能库,通过权重量化、层融合和内存优化等技术,极大地提升了模型的推理速度,同时减少了资源消耗。TensorRT 支持从多种框架(如 TensorFlow、PyTorch)导出的模型,包括大语言模型和多模态视觉语言模型,使开发者能够充分利用 GPU 的计算能力,快速部署 AI 应用。
针对当前热门的大模型推理,英伟达还推出了 NVIDIA TensorRT-LLM(LLM,Large Language Models),这是一个专为加速大语言模型推理设计的高性能深度学习推理库,不仅覆盖了主流大语言模型,还支持丰富的数据精度选项,通过系统内核和优化计算库,实现了模型推理性能的显著提升。
在 Serverless GPU 创新的基础上,英伟达的 NVIDIA TensorRT 成为加速 AI 推理的重要利器。TensorRT 作为高性能深度学习模型推理的 SDK,通过数据精度混合处理、模型融合、算子优化等技术手段,显著提升了模型推理效率。函数计算的无缝计算体验与 NVIDIA 的高性能推理库相结合,为开发者提供了一个强大的平台,让他们能够以更低的成本、更高的效率完成复杂的 AI 任务,加速技术落地和应用创新。
![]()
在实际应用中,这种合作模式的优势尤为明显。例如,在大规模模型推理场景下,使用 TensorRT 可以将平均推理耗时降低约 20%, 这在处理千万级参数的大模型时效果尤为显著。而 TensorRT-LLM 进一步针对大语言模型进行了优化,确保即使在处理极为复杂的模型时,也能保持高精度和低延迟。
结论
Serverless GPU 算力创新不仅解决了 AI 落地过程中的成本、弹性和运维难题,更为企业带来了全新的算力管理模式。通过与英伟达等技术巨头的合作,阿里云函数计算等平台正引领着 AI 算力服务的新时代,为企业提供更加高效、灵活且经济的 AI 解决方案。在未来,Serverless GPU 将成为推动 AI 技术普及和商业化的关键力量,助力各行各业实现智能化转型。