作者:肖圆,高级研发工程师,负责金山办公私有化产品运维平台研发、监控告警体系建设、可观测性体系建设。
金山私有化项目在可观测性建设中,面临数据孤岛和缺乏全局视图的挑战,影响了问题排查效率。为此,引入 DeepFlow 和 eBPF 技术,打通了指标、追踪和日志数据的联动,提供了全局微服务调用关系。通过分阶段建设,已完成第一期目标,实现了从被动排障到主动观测的转变,提升了系统稳定性和运维效率。
01|业务排障面临的痛点
在当前可观测性建设的背景下,金山私有化项目已成功实现对指标(Metrics)、追踪(Traces)和日志(Logs)的全面数据采集与存储,分别采用 Prometheus、Jaeger 和 Loki 进行管理。这些数据源已集成至 Grafana,以便于数据的展示与查询。然而,项目仍面临以下挑战:
- 数据孤岛问题:三种数据元素之间缺乏有效联动,导致在问题排查时,运维人员需要频繁切换不同数据源。这种孤立的方式不仅增加了故障排查的时间和难度,还可能导致重要信息的遗漏。为了提高排查效率,需要建立统一的视图,将不同类型的数据关联起来,以便于综合分析和快速定位问题根源。
- 缺乏全局视图:由于微服务数量众多,当前系统缺乏清晰的全局服务调用链和拓扑图进行展示,这对系统的理解和管理构成了巨大挑战。没有全局视图,团队在维护和更新微服务架构时,需要耗费大量人力和时间成本。希望引入自动化的拓扑生成工具,可以动态展示服务间的依赖关系,从而提升团队对系统的整体把握能力,减少人为错误。
02|可观测性建设目标
对于金山办公来说,我们可观测性平台建设的核心目标围绕两个痛点来建设,1)解决目前可观测性的数据孤岛问题;2)提供全局视图,即可全局查看微服务的调用关系,又能将系统、网络的路径关系呈现。2022 年中开始探索新兴技术 eBPF 在可观测性平台中的可行性,在次中间关注到 DeepFlow,了解到 DeepFlow 的 AutoTagging 的能力应该可以很好的解决数据孤岛问题,其基于 eBPF 的零侵扰的数据采集可以提供完整的全局微服务调用关系。因此我们引入 DeepFlow 来作为金山办公的可观测性平台。
整个平台的建设,我们计划是分三期来建设,目前我们已经完成了第一期以及第二期的部分内容,此篇文章中也会着力描述第一期建设的成果和难点。
阶段目标完成度一期 (1T)在金山办公室私有化环境中将 DeepFlow 部署起来,评测 DeepFlow 资源开销,形成标准化交付完成
DeepFlow 作为 Grafana 数据源融入现有 Dashboard 体系中,并能与 Loki 数据联动完成
利用 DeepFlow 数据观测未知问题,给研发和运维带来实际价值完成二期 (1个月)提供全栈全链路分布式调用链追踪能力 -- 接入 Jaeger 数据到 DeepFlow,融合 trace 数据完成
提供全栈全链路分布式调用链追踪能力 -- 网关处开启 x-request-id 能力,解决网关追踪问题完成
提供全栈全链路分布式调用链追踪能力 -- 业务注入轻量的全局 ID,解决跨线程追踪问题进行中
基于 DeepFlow 数据二开 UI,并联动 Metrics/Trace/Log 数据 -- 服务性能总览进行中三期 (1个月)Prometheus 数据接入 DeepFlow,融合 Metrics 数据未开始
基于 DeepFlow 数据二开 UI,并联动 Metrics/Trace/Log 数据 -- 服务全景拓扑未开始
基于 DeepFlow 数据二开 UI,并联动 Metrics/Trace/Log 数据 -- 调用链追踪未开始
03|DeepFlow 落地与实践
eBPF 数据与 Log 联动
一期我们只使用 DeepFlow 自采集的数据,还并未将其他数据源接入,所以一期我们需要解决 DeepFlow 与其他平台联动的问题。首先需要明确数据如何才能联动起来,我们了解到 DeepFlow 的 AutoTagging 机制能给增加统一的标签,包含资源标签(K8s 资源、云平台等)、自定义业务标签以及数据特征标签。
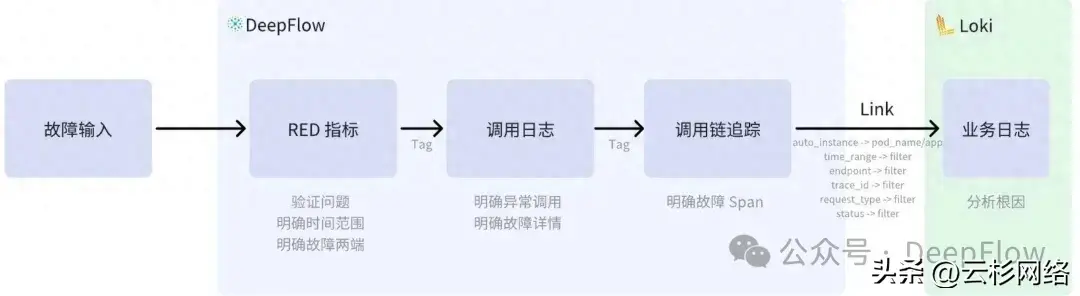
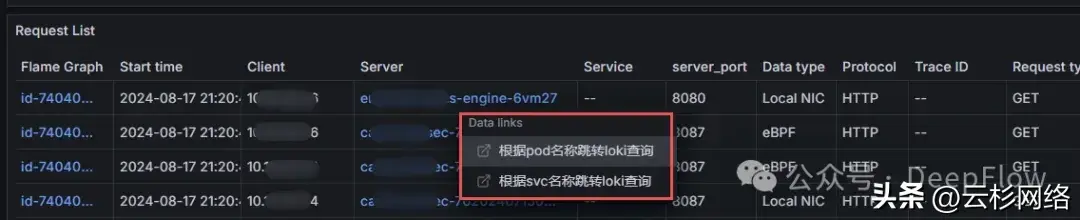
从我们使用场景来说,预期是通过 DeepFlow 指标数据快速定位发现问题的资源及时间点,借助调用日志明确异常调用,发起追踪确定异常 Span,然后跳转到日志数据,分析问题的根因。DeepFlow 自身的数据因为存在相同的 Tag 天然就支持数据联动,因此主要需要将 DeepFlow 的 Span 与 Loki 的业务日志联动起来。我们在 DeepFlow 的 Distributed Tracing Dashboard 的 List 中 Server 列增加了 Data links(Grafana 组件提供),点击 List 中某一条调用日志都可以跳转到 Loki 的 Dashboard 查看对应的业务日志。
![]()
eBPF 数据与 Log 联动架构图
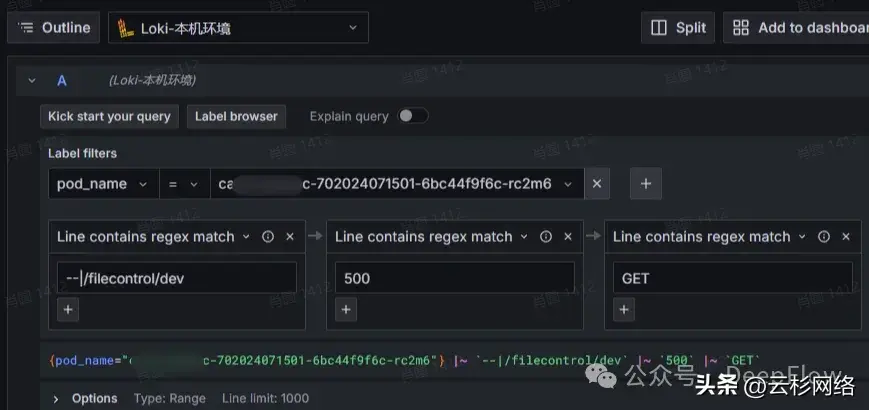
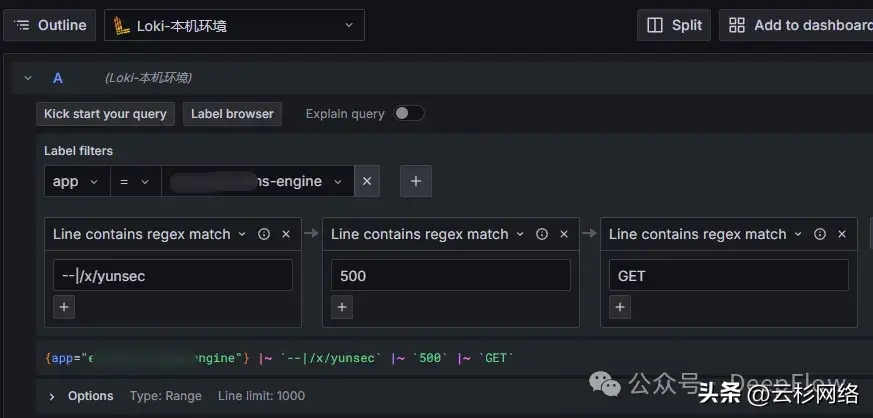
在此过程中,我们发现 DeepFlow 的 Server 列并不是固定的资源,其对应的为一个 auto_instance Tag,这个 Tag 可以自动识别实例,在我们场景中如果服务端为 pod 时,则显示的为 pod_name;而如果服务端为 service 的 cluster_ip 则显示的 service_name。因为 Grafana 中不能支持太复杂的判断逻辑,所以我们简单的提供了两个 Link,借助于文案来协助使用者跳转。Link 中在实例层面会传递 Loki 所需要的 pod_name 与 app,在搜索条件中会传递 endpoint、trace_id、request_type、status 及时间范围,通过的条件的传递来完成 eBPF 的数据与 Log 的联动:
![]()
eBPF 数据与 Log 联动效果图
/explore?schemaVersion=1&panes={"4gv":{"queries":[{"refId":"A","expr":"{pod_name=\"${__data.fields.auto_instance_1} \"} |~ ` ${__data.fields.trace_id} | ${__data.fields.endpoint}` |~ `${__data.fields.response_code}`","queryType":"range","editorMode":"builder"}],"range":{"from":" ${__from} ","to":" ${__to} "}}}&orgId=1
![]()
根据 pod 名称跳转
/explore?schemaVersion=1&panes={"4gv":{"queries":[{"refId":"A","expr":"{app=\"${__data.fields.auto_instance_1} \"} |~ ` ${__data.fields.trace_id} | ${__data.fields.endpoint}` |~ `${__data.fields.response_code}`","queryType":"range","editorMode":"builder"}],"range":{"from":" ${__from} ","to":" ${__to} "}}}&orgId=1
![]()
根据 svc 名称跳转
使用托管服务
在 DeepFlow 的整体架构中,依赖了一些第三方组件,如 MySQL 用于标签存储,Grafana 用于数据可视化,以及 ClickHouse 用于存储可观测性数据。金山私有化部署交付到客户手里中,及希望资源能极致使用同时处于组件统一维护的考虑,我们需要复用目前私有化交付已有的组件。对于此需求,DeepFlow 也都有很好的扩展能力。一期计划中,我们对接了 Grafana 及 MySQL,对于 ClickHouse 目前私有化环境还未引入,后续我们考虑单独引入 Clickhouse 产品线然后将 DeepFlow 切入过去。
- MySQL 的接入比较简单,修改 deepflow_server 侧的配置即可:
global:
externalMySQL:
enabled: true ## Enable external MySQL
ip: 10.*.*.* ## External Mysql IP address, Need to allow deepflow-server and clickhouse access
port: 3*** ## External Mysql port
username: r** ## External Mysql username
password: ******* ## External Mysql password
mysql:
enabled: false ## Close MySQL deployment
- Grafana 的接入需要处理加载 DeepFlow 自研的插件,以及导入官方的 Dashboard 并配置 Data source,deepflow_server 配置也需要修改,详情见 DeepFlow 官方提供的接入文档。
grafana:
enabled: false ## Close Grafana deployment
DeepFlow 官方默认的看板相当丰富,可观测性数据 + 系统监控的总共达到 39 个之多,有一些面板并不适合我们的场景,我们做了一些调整:
- 合并相似度高的面板:例如合并 K8s 和 Cloud 的面板:合并 Server 自监控的面板
- 丢弃目前使用不上的面板:例如对于指标类的面板,我们只保留了 Map 相关的;对于 Continuous Profiling 目前我们还未开启此能力因此也丢弃
![]()
整合 Dashboard
- 优化面板的搜索条件:例如 Tracing 面板,status 默认值调整为 Server Error、Client Error,这样方便聚焦异常调用;增加了 response_code、exclude_endpoint 过滤条件,对于不关注的 url 可以快速过滤
![]()
优化搜索条件
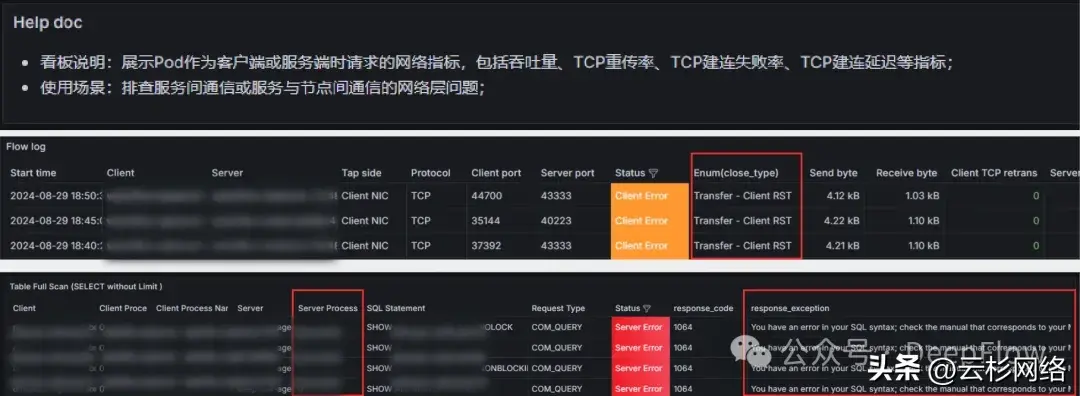
- 优化面板的数据查看:例如我们增加了简洁版的用户使用说明;同时将 Flow Log 与 Request Log 的异常说明字段放出来了,方便用户在看到有异常时,能准确的知道异常原因
![]()
优化数据查看
在对接完第三方组件后,我们同时也将 DeepFlow 现在的服务都改造为了 ClusterIP 类型,一定程度上确保 DeepFlow 服务接口的安全性。
![]()
ClusterIP 改造
DeepFlow 性能优化
- DeepFlow 的后端服务(deepflow-server、deepflow-app、Stella、ClickHouse)独占监控节点。这样做我们大概出于几点考虑:监控节点与业务节点分离,DeepFlow 后端服务即使在极端情况下占用过多的系统资源也不会影响到业务;我们内部的监控节点还运行了 Prometheus、Grafana 等组件,DeepFlow 的数据呈现依赖 Grafana,部署在同监控节点上,可以有效提高 DeepFlow 查看数据的查询性能。
- 调整观测数据的保留时间。鉴于不同私有化客户的资源配置各不相同,对于存储资源有限且需要更严格控制成本的客户,我们通过缩短观测数据的保留周期来减少存储占用,从而有效压缩存储成本。
04|案例:从被动排障到主动观测
在成功部署 DeepFlow 后,我们获得了丰富的可观测性数据,包括应用服务的 RED 指标(请求率、错误率、时延)、调用详情以及网络连接状况。这些数据为我们提供了对系统运行状况的全面洞察。通过对这些数据的分析,我们逐一排查了当前系统的问题。我们的目标是消除所有异常,确保响应时延保持在预期范围内,以提升整体系统的稳定性和性能。
- 对于异常我们锚定三个异常:应用侧的服务端异常、客户端异常以及网络侧的 TCP 建连异常(从应用角度来看,建连异常是非常影响业务的)
- 对于时延我们锚定两个指标量:应用侧响应时延、网络侧 TCP 建连时延(更多体现网络质量)
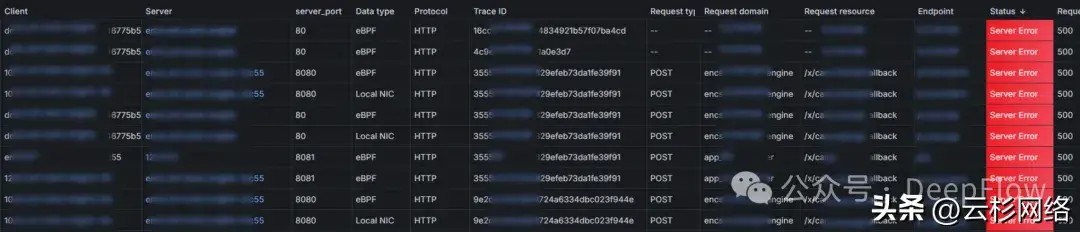
Server Error 定位无效的订阅事件
我们发现所有服务在调用 /x/cm/event/callback 接口时均返回 500 错误。经过调查,确认该接口属于 WOA 平台开发的引擎服务。向服务负责人反馈后,业务方表示业务运作正常。通过深入分析,发现问题源于 WOA 开发平台在 v7eco 环境的应用管理平台中配置了无效的订阅事件回调地址。由于回调失败会持续重试,导致不断产生 500 错误。
这一问题的主要影响是相关应用无法接收到订阅事件。经过与应用负责人沟通,确认订阅事件实际已不再需要。于是我们要求业务方删除该订阅事件。自删除后,500 错误不再出现。
![]()
500 错误
跳转到 Loki 对应的业务日志,也可快速发现日志存在对应的报错。
![]()
业务日志
后续处理措施:与应用负责人沟通,强调不得为应用随意配置回调地址。确保所有配置均经过验证,以避免无效或错误配置导致异常。对于不再使用的应用,需及时下架。建立并遵循严格的应用上下架流程,以减少不必要的异常日志和资源浪费。制定并实施应用配置和管理的标准流程,包括审核和验证步骤,确保每个阶段的合规性和准确性。
业务方未及时修改指标推送模式
在观测过程中发现二开引擎服务的 /metrics/job API 返回了 401 未授权错误。经过分析,这是由于 Prometheus 的指标获取模式从原来的 push 模式改为 pull 模式,以更好地控制指标量。然而,部分二开的服务未及时调整相应配置,导致指标上报失败。目前,我们已通过内部工单跟进此问题,并要求研发团队尽快进行配置更新,以确保所有服务正常上报指标。
![]()
401 错误
推进应用接口日志及响应规范
在二开引擎服务访问安全网关控制服务时,调用 /api/v1/ctrl/key API 返回了 500 错误。经过与相关同事确认,问题是由于安全网关的插件授权到期所致。为解决该问题,需要及时更新授权以恢复正常服务功能。
![]()
500 错误
理论上,这个问题本应通过对 ERROR 日志的监控报警来发现。但在引入 DeepFlow 之前,我们未能检测到这一问题,原因在于二开引擎服务的日志不规范。具体表现为,将 500 错误的日志级别记录为 warning,而业务层的 status_code 则错误地记录为 200。因此,未能及时触发预期的错误报警。
![]()
日志错误
我们已系统梳理了引擎服务相关的请求错误问题,并与引擎服务产品及研发团队沟通,提交工单安排逐步优化。具体措施包括:完善并推行第三方应用接入的标准规范,确保一致性和稳定性。增加引擎服务日志中的关键字告警机制,便于及时发现和响应异常日志。
05|未来愿景与发展规划
展望未来规划,在可观测性建设方面,我们将重点关注以下几个方向:
- 继续完善数据联动:在已实现 eBPF 数据与 Log 联动的基础上,进一步融合 Metrics 和 Trace 数据。通过将 Prometheus 数据接入 DeepFlow,实现指标、日志、追踪数据的全面关联分析,提供更加全面、高效的问题排查能力。
- 构建全景拓扑视图:基于 DeepFlow 采集的数据,二次开发专属的可视化 UI,构建服务全景拓扑图。通过直观呈现服务间的依赖关系和调用链路,帮助运维团队快速理解系统架构,定位性能瓶颈和故障根因。
- 优化调用链追踪:在现有分布式追踪能力的基础上,进一步优化 UI 界面,提供更加清晰、易用的调用链路展示。通过与 Metrics、Log 数据的联动分析,实现端到端的性能剖析与问题诊断。
- 推广可观测性文化:加强团队内部的可观测性实践分享和经验交流,提高全员的可观测性意识。通过定期的培训和工作坊,普及可观测性理念和工具的使用,鼓励研发人员主动参与监控指标的定义和异常告警的设置。
- 探索 AIOps 实践:在海量的可观测性数据基础上,尝试引入机器学习算法,实现智能化的异常检测、根因分析和故障预测。通过 AIOps 技术的应用,进一步提升系统的自愈能力和运维效率。
- 完善监控告警体系:持续优化监控指标和阈值设置,减少无效告警的干扰。建立更加清晰的问题处置流程和通知机制,确保告警能够快速、准确地推送给相关责任人。定期回顾和调整告警规则,不断提升监控告警的时效性和可操作性。
通过以上措施的推进,我们将不断强化可观测性平台的能力,为业务系统的稳定运行保驾护航。同时,我们也将持续关注可观测性领域的最新进展,借鉴业界优秀实践,推动金山办公的可观测性建设迈上新的台阶。让我们携手并进,共同打造更加智能、高效、可靠的业务运维保障体系。