作者:来自 Elastic Mark Hoy
继与 Mistral AI 团队密切合作之后,今天我们很高兴地宣布,Elasticsearch 向量数据库现在可以存储并自动分块来自 mistral-embed 模型的嵌入,并与 open inference API 和 semantic_text 字段进行原生集成。对于构建 RAG 应用程序的开发人员来说,这种集成消除了设计定制分块策略的需要,并且使使用向量存储进行分块变得像添加 API 密钥一样简单。
Mistral AI 提供流行的开源和优化的 LLMs,可用于企业用例。Elasticsearch open inference API使开发人员能够创建推理端点并使用领先 LLM 提供商的机器学习模型。作为两家扎根于开放性和社区的公司,我们合作是理所当然的!
在此博客中,我们将在检索增强生成 (RAG) 设置中使用 Mistral AI 的 mistral-embed 模型。
开始使用
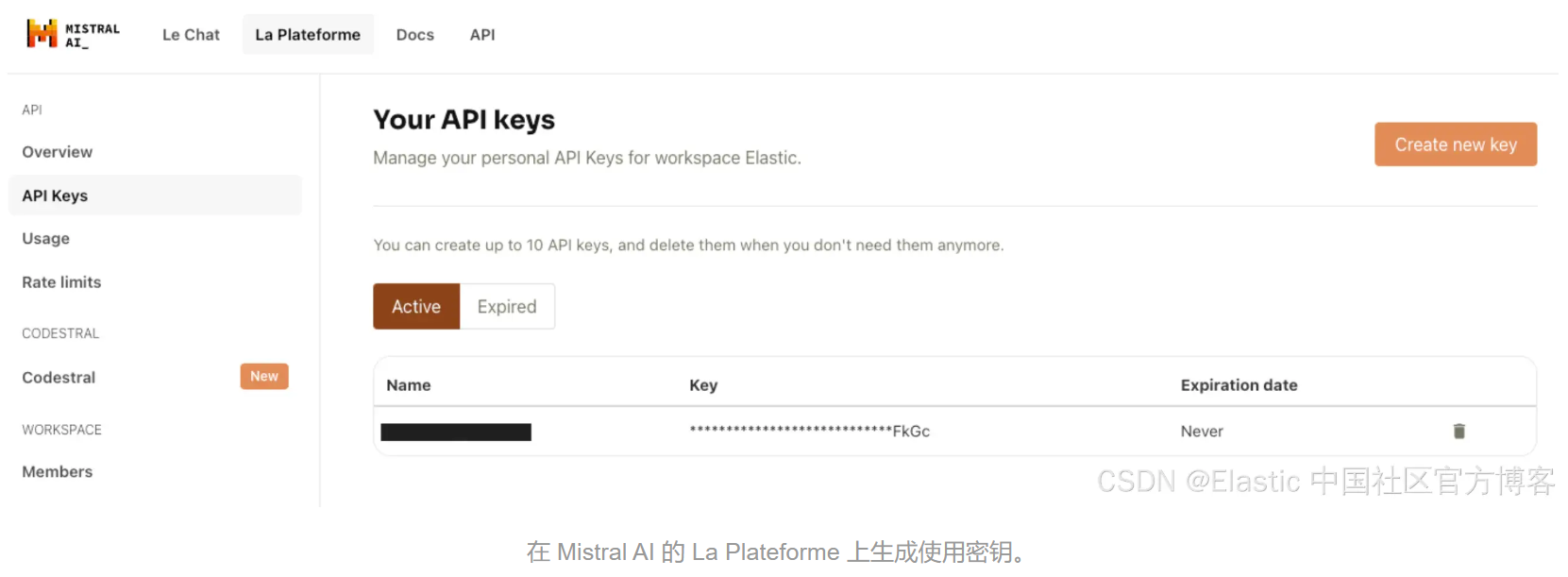
要开始使用,你需要在 La Plateforme 上拥有一个 Mistral 帐户,并为你的帐户生成一个 API 密钥。
![]()
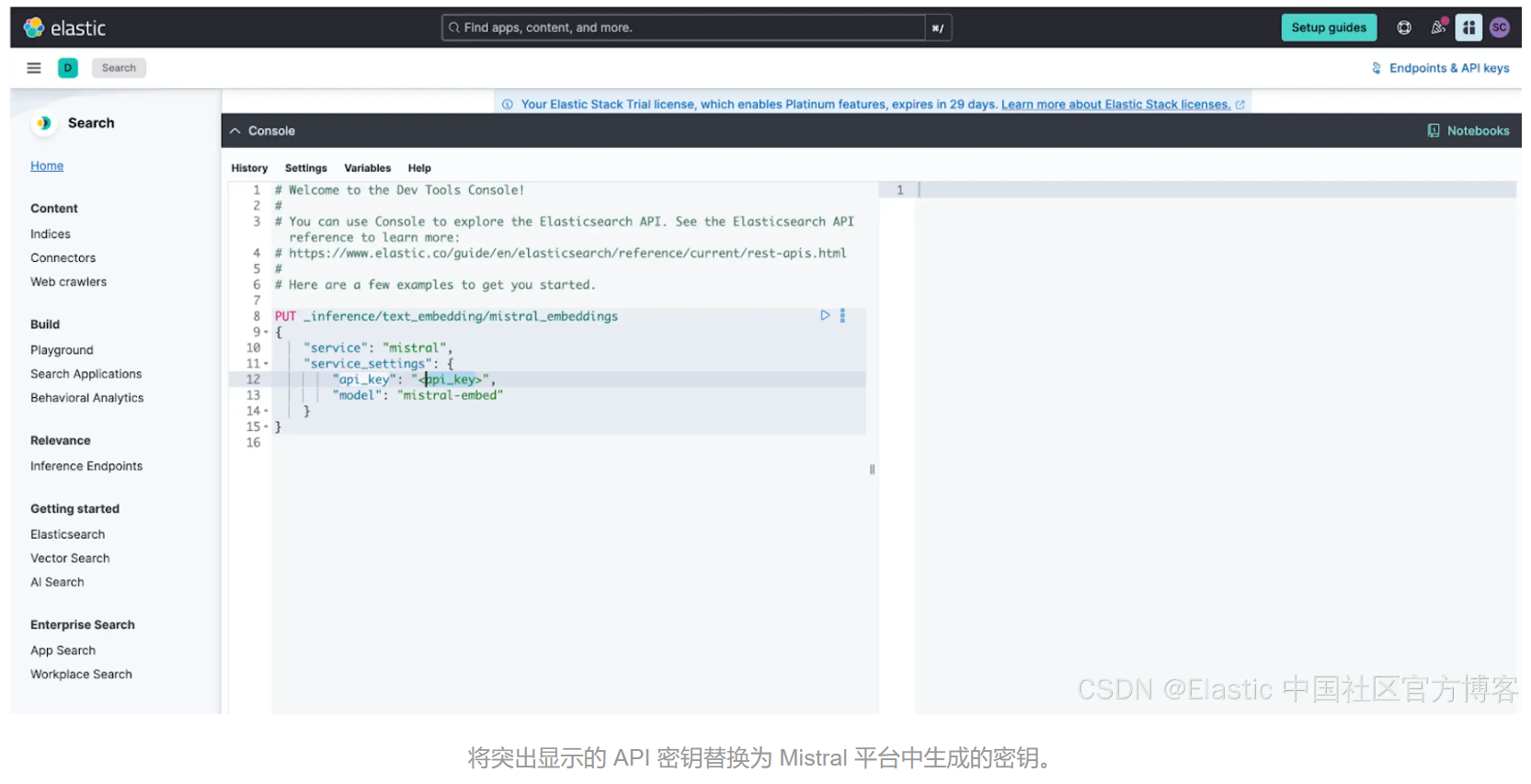
现在,打开你的 Elasticsearch Kibana UI 并展开开发控制台以进行下一步。
![]()
你将使用 create inference API 并提供你的 API 密钥和 Mistral 嵌入模型的名称来创建推理端点。作为推理端点配置的一部分,我们将指定 mistral-embed 模型来创建名为 “mistral_embeddings” 的 “text_embedding” 端点。
PUT _inference/text_embedding/mistral_embeddings
{
"service": "mistral",
"service_settings": {
"api_key": "<api_key>",
"model": "mistral-embed"
}
}
你将收到来自 Elasticsearch 的响应,其中表示端点已成功创建:
{
"model_id": "mistral_embeddings",
"task_type": "text_embedding",
"service": "mistral",
"service_settings": {
"model": "mistral-embed",
"dimensions": 1024,
"similarity": "dot_product",
"rate_limit": {
"requests_per_minute": 240
}
},
"task_settings": {}
}
请注意,模型创建无需额外设置。Elasticsearch 将自动连接到 Mistral 平台以测试你的凭据和模型,并为你填写维度数量和相似度度量。
接下来,让我们测试我们的端点以确保一切设置正确。为此,我们将调用执行推理 API:
POST _inference/text_embedding/mistral_embeddings
{
"input": "Show me some text embedding vectors"
}
API 调用将返回为提供的输入生成的嵌入,它看起来像这样:
{
"text_embedding": [
{
"embedding": [
0.016098022,
0.047546387,
… (additional values) …
0.030654907,
-0.044067383
]
}
]
}
对向量化数据进行自动分块
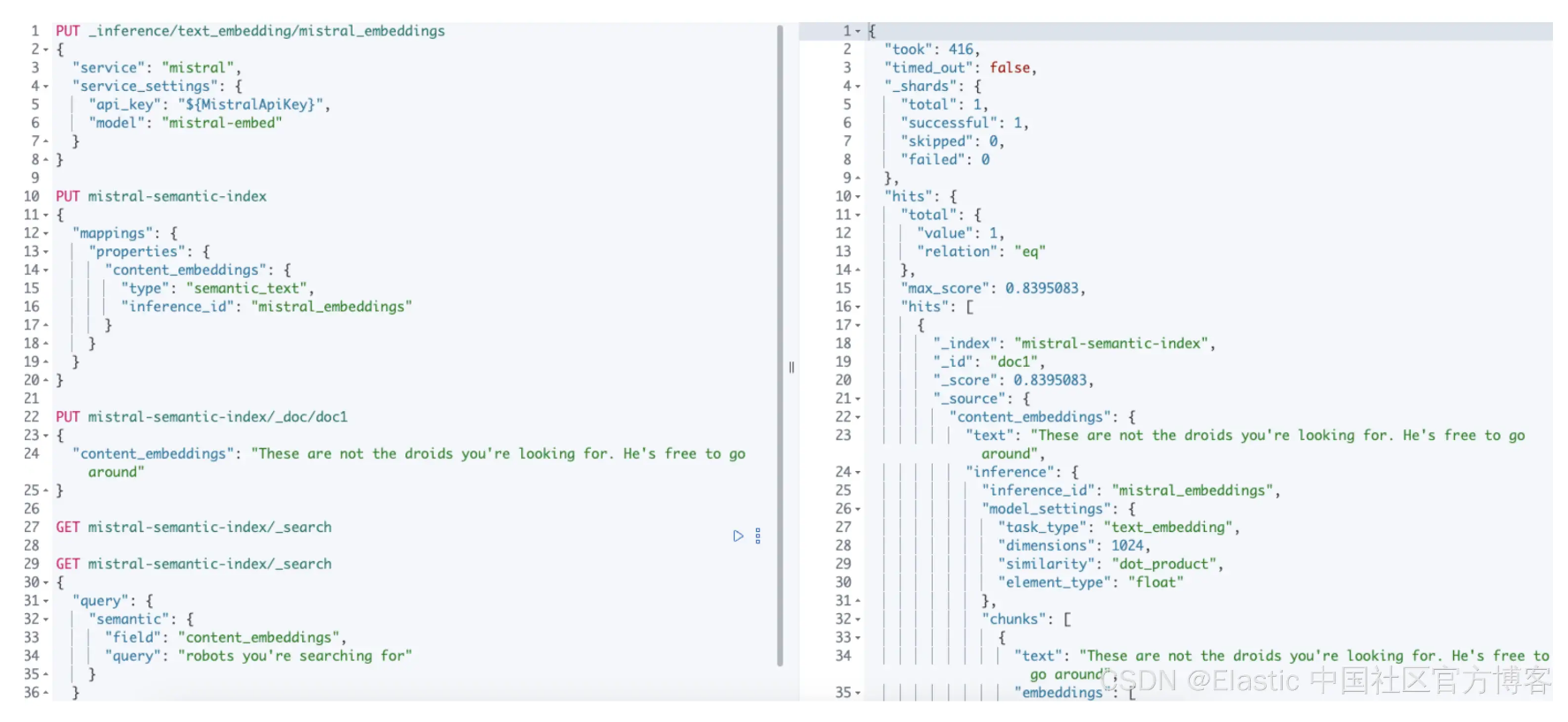
现在,我们已经设置好了推理端点,并验证了它是否有效,我们可以使用带有索引的 Elasticsearch semantic_text 映射,以便在索引时使用它来自动创建嵌入向量。为此,我们首先创建一个名为 “mistral-semantic-index” 的索引,其中包含一个字段来保存名为 content_embeddings 的文本:
PUT mistral-semantic-index
{
"mappings": {
"properties": {
"content_embeddings": {
"type": "semantic_text",
"inference_id": "mistral_embeddings"
}
}
}
}
设置完成后,我们只需索引文档即可立即开始使用推理端点。例如:
PUT mistral-semantic-index/_doc/doc1
{
"content_embeddings": "These are not the droids you're looking for. He's free to go around"
}
现在,如果我们检索文档,你将看到,在内部对文本进行索引时,我们的推理端点被调用,并且文本嵌入以及有关用于推理的模型的一些其他元数据被自动添加到我们的文档中。在底层,semantic_text 字段类型将自动提供分块,以将较大的输入文本分解为可管理的块,然后对其进行推理。
GET mistral-semantic-index/_search
{
…
"hits": {
…
"hits": [
{
"_index": "mistral-semantic-index",
"_id": "doc1",
"_score": 1,
"_source": {
"content_embeddings": {
"text": "These are not the droids you're looking for. He's free to go around",
"inference": {
"inference_id": "mistral_embeddings",
"model_settings": {
"task_type": "text_embedding",
"dimensions": 1024,
"similarity": "dot_product",
"element_type": "float"
},
"chunks": [
{
"text": "These are not the droids you're looking for. He's free to go around",
"embeddings": [
-0.039367676,
0.022644043,
-0.0076675415,
-0.020507812,
0.039489746,
0.0340271,
…
太棒了!现在我们已经完成了设置,并且已经看到它的实际效果,我们可以将数据加载到索引中。你可以使用任何你喜欢的方法。我们更喜欢批量索引 API。在索引数据时,提取管道将使用我们的推理端点对 content_embedding 字段数据执行推理,并将其传递给 Mistral API。
由 Mistral AI 提供支持的语义搜索
最后,让我们使用我们的数据运行语义搜索。使用语义查询类型,我们将搜索短语 “robots you’re searching for”。
GET mistral-semantic-index/_search
{
"query": {
"semantic": {
"field": "content_embeddings",
"query": "robots you're searching for"
}
}
}
![]()
就是这样!运行查询时,Elasticsearch 的语义文本查询将使用我们的 Mistral 推理端点来获取查询向量,并在后台使用该向量在 “content_embeddings” 字段上搜索我们的数据。
我们希望你喜欢使用此集成,它现已在 Elastic Serverless 中提供,或即将在 Elastic Cloud Hosted 版本 8.15 中提供。前往 Search Labs 上的 Mistral AI 页面开始使用。
祝你搜索愉快!
准备好自己尝试一下了吗?开始免费试用。
Elasticsearch 集成了 LangChain、Cohere 等工具。加入我们的高级语义搜索网络研讨会,构建你的下一个 GenAI 应用程序!
原文:Mistral AI embedding models now available via Elasticsearch Open Inference API — Search Labs