一、前言
很多同学都有在 Windows电脑上连接本地iOS设备 去进行测试的需求,其中tidevice库是大家在Windows上使用的最多的iOS通信库,其中有一些接口是我们比较常用的,所以Airtest这边对一些常用的接口进行了封装,供大家日常写脚本的时候去进行调用。那么我们今天一起来看一下Airtest封装的一些接口吧~
二、Airtest封装的Tidevice接口
2.1 devices() :列出USB连接的所有设备的 UDID 列表
这个接口可以将本地中通过usb连接的所有iOS设备的 UDID 列表返回出来。
devices = TIDevice.devices()
print(devices)
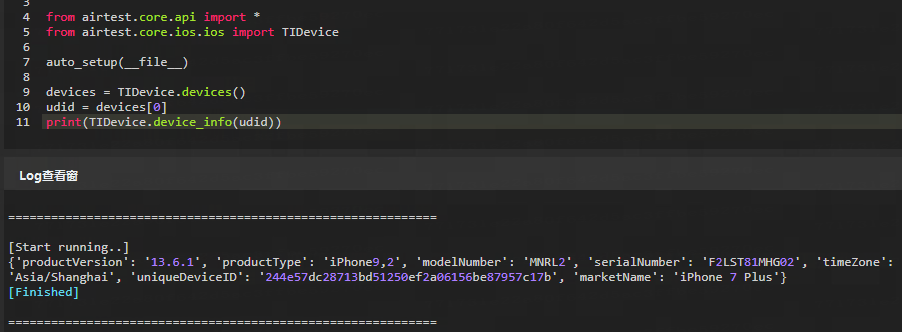
2.2 device_info(udid) :获取手机信息
通过输入 udid 去进行检索设备,并将检索到的设备信息返回输出,其中包括下述内容:
-
productVersion(str) :产品的版本。
-
-
-
serialNumber(str) :设备的序列号。
-
phoneNumber(str) :与设备关联的电话号码。
-
-
uniqueDeviceID(str) :设备的唯一标识符。
-
marketName(str) :设备的市场名称。
from airtest.core.ios.ios import TIDevice
print(TIDevice.device_info(udid))
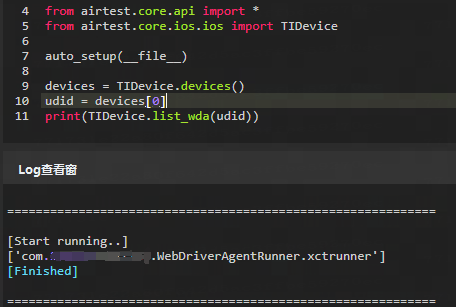
2.3 list_wda(udid) :列出手机上安装的所有WDA的 bundleID
通过该接口可以在符合特定命名规则的设备上获取该设备的所有 WDA ,并返回每个 WDA 包名,默认是返回 TIDevice.list_wda(udid)[0] 。
from airtest.core.ios.ios import TIDevice
print(TIDevice.list_wda(udid))
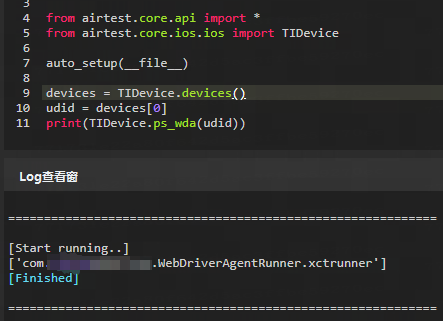
2.4 ps_wda(udid) :获取当前启动中的WDA列表
获取满足特定命名规则的设备上所有正在运行的 WDA ,并返回每个 WDA 包名,默认是返回 TIDevice.list_wda(udid)[0] 。
from airtest.core.ios.ios import TIDevice
print(TIDevice.ps_wda(udid))
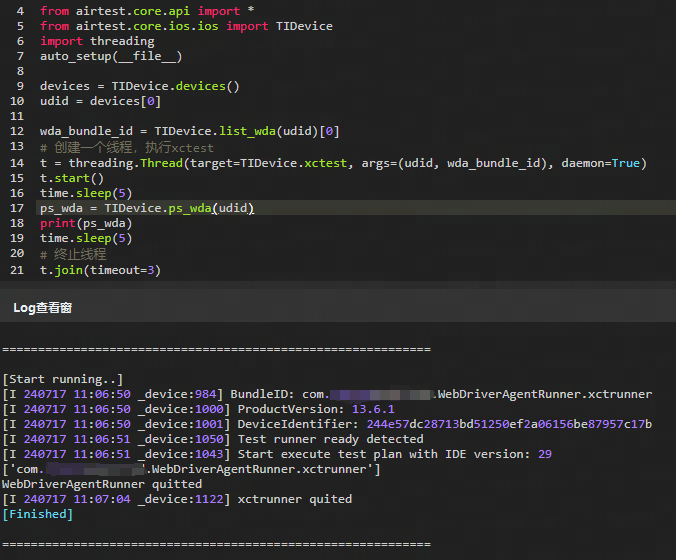
2.5 xctest(wda_bundle_id):启动WDA
通过该接口可以启动指定的 WDA ,通过传入 WDA 的指定包名,调用接口即可打开对应的 WDA 。
from airtest.core.ios.ios import TIDevice
import threading
wda_bundle_id = TIDevice.list_wda(udid)[0]
# 创建一个线程,执行xctest
t = threading.Thread(target=TIDevice.xctest, args=(udid, wda_bundle_id), daemon=True)
t.start()
time.sleep(5)
ps_wda = TIDevice.ps_wda(udid)
print(ps_wda)
time.sleep(5)
# 终止线程
t.join(timeout=3)
三、完整演示案例
结合上面的样例,我们通过一个小小的例子来看一下具体使用的情况是怎么样的。
我们这边是先打开AirtestIDE连接上我们所需要测试的iOS设备,连接上设备后,我们先是读取并输出了所连接设备的 UDID ,设备信息等内容,然后读取并输出连接的iOS设备所安装的全部 WDA ,并启动第一个 WDA ,将当前在使用的 WDA 进行输出可以看到 WDA 包名是相对应的,最后直接关闭 WDA 服务。
# -*- encoding=utf8 -*-
__author__ = "Airtest"
from airtest.core.api import *
from airtest.core.ios.ios import TIDevice
import threading
auto_setup(__file__)
#输出电脑所连接的iOS设备udid
devices = TIDevice.devices()
print("电脑上连接的iOS设备的UDID是:{}".format(devices))
udid = devices[0]
#输出所连接设备的信息
print("该设备的信息为:")
print(TIDevice.device_info(udid))
#输出该设备安装的全部wda包名
print("该设备安装的全部wda如下:")
for wda_item in TIDevice.list_wda(udid):
print(wda_item)
#获取第一个wda的包名
wda_bundle_id = TIDevice.list_wda(udid)[0]
# 创建一个线程,执行xctest,启动第一个wda
t = threading.Thread(target=TIDevice.xctest, args=(udid, wda_bundle_id), daemon=True)
t.start()
time.sleep(5)
#输出当前启动的wda包名
ps_wda = TIDevice.ps_wda(udid)
print("当前设备所启动的wda是:{}".format(ps_wda))
time.sleep(5)
# 终止线程
t.join(timeout=3)
四、小结
今天我们介绍了五个Airtest封装的tidevice接口以及其使用方式跟效果。
-
devices :列出USB连接的所有设备的 UDID 列表
-
-
list_wda :列出手机上安装的所有WDA的 bundleID
-
-
通过上面五个接口可以直接获取本地usb连接设备的一些信息,包括设备出厂信息、wda包名、iOS型号等等,这些信息可以帮助我们提取所需要的内容去进行调用。
同时如果大家在使用过程中有一些新的使用方式或者遇到了问题,又或者有任何想要深入了解的知识点,欢迎在官方交流群(526033840)里告诉我们或者提交issue,也欢迎大家投稿其他不同的使用小技巧。我们下篇推文继续介绍Airtest封装的tidevice的其他接口~