![]()
指令微调 是一种技术,它能让大语言模型 (LLMs) 更好地理解和遵循人类的指令。但是,在编程任务中,大多数模型的微调都是基于人类编写的指令 (这需要很高的成本) 或者是由大型专有 LLMs 生成的指令 (可能不允许使用)。我们推出了一个叫做 StarCoder2-15B-Instruct-v0.1 的模型,这是第一个完全自我对齐的大型代码模型,它是通过一个完全开放和透明的流程进行训练的。我们的开源流程使用 StarCoder2-15B 生成了成千上万的指令-响应对,然后用这些对来微调 StarCoder-15B 本身,而不需要任何人类的注释或者从大型专有 LLMs 中提取的数据。
-
StarCoder2-15B-Instruct-v0.1
https://hf.co/bigcode/starcoder2-15b-instruct-v0.1
StarCoder2-15B-Instruct 在 HumanEval 上的得分是 72.6,甚至超过了 CodeLlama-70B-Instruct 的 72.0 分! 在 LiveCodeBench 上的进一步评估表明,自我对齐的模型甚至比在从 GPT-4 提炼的数据上训练的同一模型表现得更好,这意味着 LLM 可能能从自己分布内的数据中更有效地学习,而不是从教师 LLM 的偏移分布中学习。
理论
![]()
我们的数据生成流程主要包括三个步骤:
-
从 The Stack v1 中提取高质量和多样化的种子函数。The Stack v1 是一个拥有大量允许使用许可的源代码的大型语料库。
-
创建包含种子函数中不同代码概念的多样化且现实的代码指令 (例如,数据反序列化、列表连接和递归)。
-
对每个指令,通过执行引导的自我验证生成高质量的响应。
-
The Stack v1
https://hf.co/datasets/bigcode/the-stack
在接下来的部分中,我们将详细探讨这些方面的内容。
收集种子代码片段
为了充分解锁代码模型的遵循指令能力,它应该接触到涵盖广泛编程原则和实践的多样化指令集。受到 OSS-Instruct 的启发,我们通过从开源代码片段中挖掘代码概念来进一步推动这种多样性,特别是来自 The Stack V1 的格式良好的 Python 种子函数。
-
OSS-Instruct
https://github.com/ise-uiuc/magicoder
对于我们的种子数据集,我们仔细提取了 The Stack V1 中所有带有文档字符串的 Python 函数,使用 autoimport 推断所需的依赖关系,并在所有函数上应用以下过滤规则:
-
autoimport
https://lyz-code.github.io/autoimport/
-
类型检查: 我们应用 Pyright 启发式类型检查器来移除所有产生静态错误的函数,这可能是错误的信号。
-
去污处理: 我们检测并移除我们评估的所有基准项。我们同时在解决方案和提示上使用精确字符串匹配。
-
文档字符串质量过滤: 我们使用 StarCoder2-15B 作为评判来移除文档质量差的函数。我们给基础模型提供 7 个少样本示例,要求它用“是”或“否”来回应是否保留该条目。
-
近似去重: 我们使用 MinHash 和局部敏感哈希,设置 Jaccard 相似性阈值为 0.5,以过滤数据集中的重复种子函数。这是应用于 StarCoder 训练数据的 相同过程。
-
Pyright
https://github.com/microsoft/pyright
-
相同过程
https://hf.co/blog/dedup
这个过滤流程从带有文档字符串的 500 万个函数中筛选出了 25 万个 Python 函数的数据集。这个过程在很大程度上受到了 MultiPL-T 中使用的数据收集流程的启发。
-
MultiPL-T
https://hf.co/datasets/nuprl/MultiPL-T
Self-OSS-Instruct
在收集了种子函数之后,我们使用 Self-OSS-Instruct 生成多样化的指令。具体来说,我们采用上下文学习的方式,让基础 StarCoder2-15B 模型从给定的种子代码片段中自我生成指令。这个过程使用了 16 个精心设计的少样本示例,每个示例的格式为*(代码片段,概念,指令)*。指令生成过程分为两个步骤:
-
概念提取: 对于每个种子函数,StarCoder2-15B 被提示生成一个存在于函数中的代码概念列表。代码概念指的是编程中使用的基础原则和技术,例如 模式匹配 和 数据类型转换 ,这些对开发者掌握至关重要。
-
指令生成: 然后提示 StarCoder2-15B 自我生成一个包含已识别代码概念的编程任务。
最终,这个过程生成了 23.8 万条指令。
响应自我验证
我们已经有了 Self-OSS-Instruct 生成的指令,我们的下一步是将每条指令与高质量的响应相匹配。先前的实践通常依赖于从更强大的教师模型 (如 GPT-4) 中提炼响应,这些模型有望展现出更高的质量。然而,提炼专有模型会导致非许可的许可问题,而且更强大的教师模型可能并不总是可用的。更重要的是,教师模型也可能出错,而且教师和学生之间的分布差距可能是有害的。
我们提议通过显式指示 StarCoder2-15B 在生成交织自然语言的响应后生成测试来进行自我验证,这个过程类似于开发者测试他们的代码实现。具体来说,对于每条指令,StarCoder2-15B 生成 10 个*(自然语言响应,测试)*格式的样本,我们在沙箱环境中执行测试以过滤掉那些被测试证伪的样本。然后我们为每个指令随机选择一个通过的响应作为最终的 SFT 数据集。总共,我们为 23.8 万条指令生成了 240 万 (10 x 23.8 万) 个响应,其中 50 万个通过了执行测试。去重后,我们剩下 5 万条指令,每条指令配有一个随机通过的响应,最终我们将其用作我们的 SFT 数据集。
评估
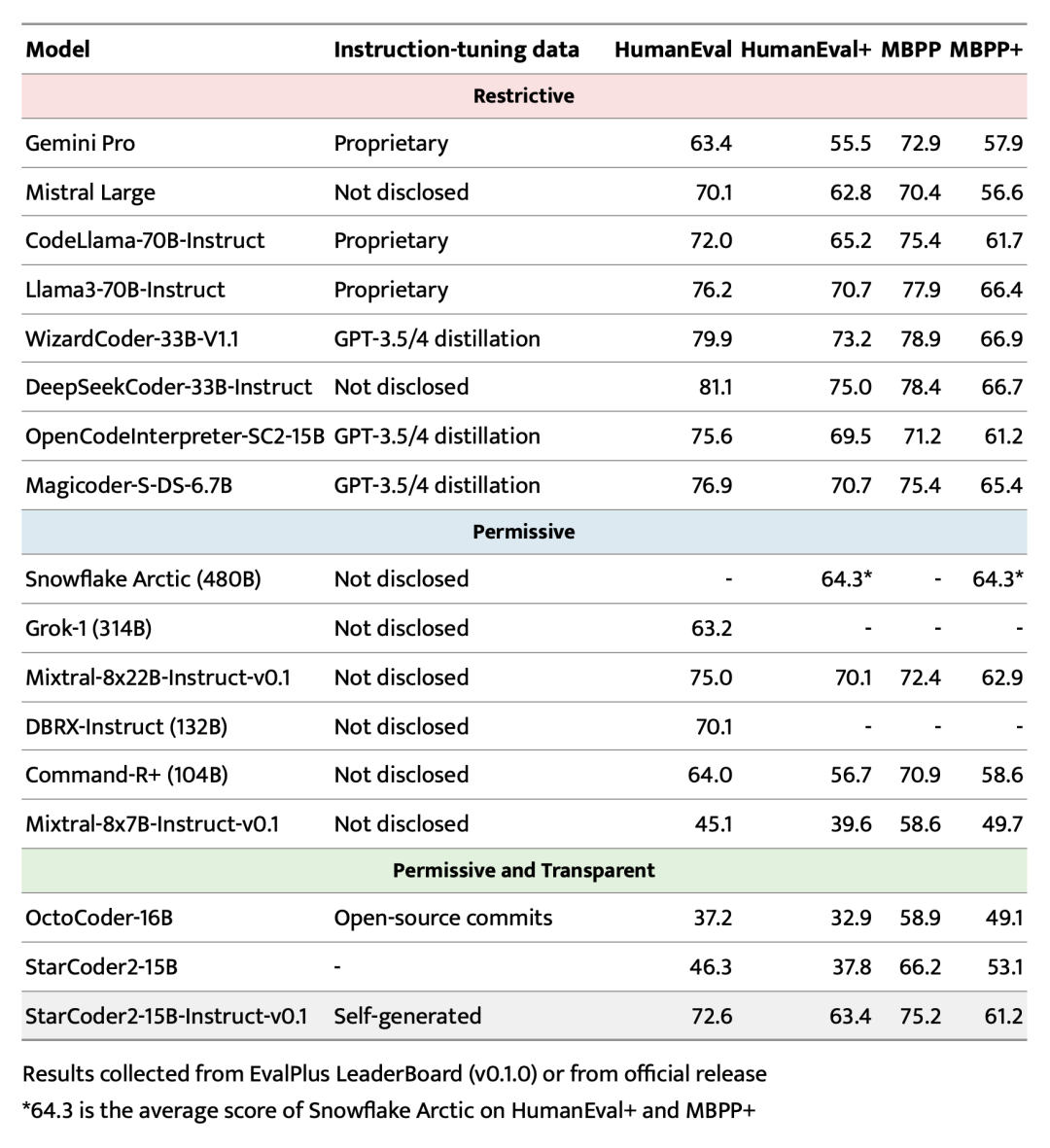
在流行且严格的 EvalPlus 基准测试中,StarCoder2-15B-Instruct 在其规模上作为表现最佳的拥有许可的 LLM 脱颖而出,超过了更大的 Grok-1 Command-R+ 和 DBRX,与 Snowflake Arctic 480B 和 Mixtral-8x22B-Instruct 相近。据我们所知,StarCoder2-15B-Instruct 是第一个具有完全透明和许可流程,达到 70+ HumanEval 分数的代码 LLM。它大大超过了之前的最佳透明许可代码 LLM OctoCoder。
-
EvalPlus
https://github.com/evalplus/evalplus
即使与具有限制性许可的强大 LLM 相比,StarCoder2-15B-Instruct 仍然具有竞争力,超过了 Gemini Pro 和 Mistral Large,与 CodeLlama-70B-Instruct 相当。此外,仅在自我生成数据上训练的 StarCoder2-15B-Instruct 与在 GPT-3.5/4 提炼数据上微调 StarCoder2-15B 的 OpenCodeInterpreter-SC2-15B 非常接近。
![]()
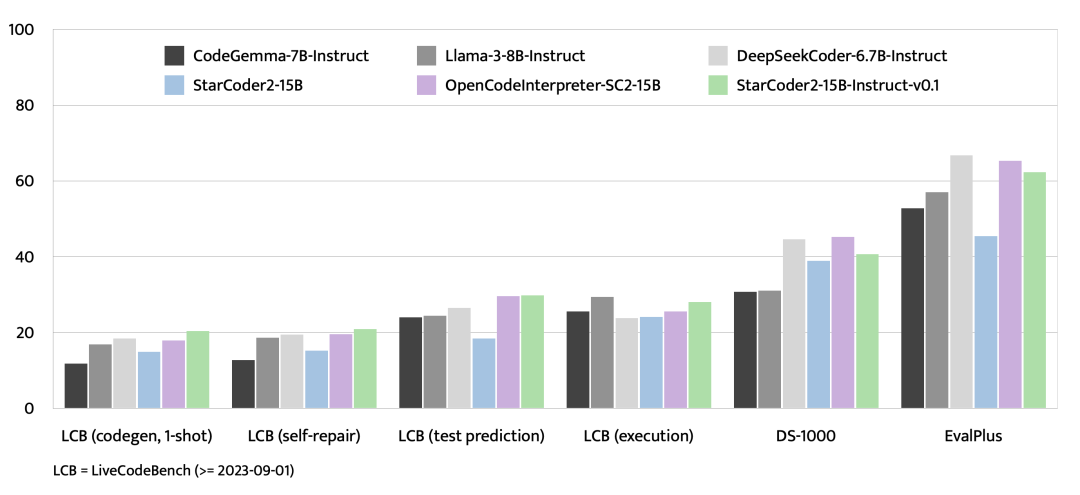
除了 EvalPlus,我们还对具有相似或更小规模的最新开源模型在 LiveCodeBench 上进行了评估,LiveCodeBench 包括 2023 年 9 月 1 日之后创建的新编程问题,以及针对数据科学程序的 DS-1000。在 LiveCodeBench 上,StarCoder2-15B-Instruct 在评估的模型中取得了最佳结果,并且一致优于从 GPT-4 数据中提炼的 OpenCodeInterpreter-SC2-15B。在 DS-1000 上,尽管 StarCoder2-15B-Instruct 只在非常有限的数据科学问题上进行了训练,但它仍然具有竞争力。
-
LiveCodeBench
https://livecodebench.github.io
-
DS-1000
https://ds1000-code-gen.github.io
![]()
结论
StarCoder2-15B-Instruct-v0.1 首次展示了我们可以在不依赖像 GPT-4 这样的更强大的教师模型的情况下,创建出强大的指令微调代码模型。这个模型证明了自我对齐——即模型使用自己生成的内容来学习——对于代码也是有效的。它是完全透明的,并允许进行提炼,这使得它与其它更大规模但非透明的许可模型如 Snowflake-Arctic、Grok-1、Mixtral-8x22B、DBRX 和 CommandR+ 区别开来。我们已经将我们的数据集和整个流程,包括数据整理和训练,完全开源。我们希望这项开创性的工作能够激发该领域更多的未来研究和开发。
资源
-
StarCoder2-15B-Instruct-v0.1: 指令微调模型
https://hf.co/bigcode/starcoder2-15b-instruct-v0.1
-
starcoder2-self-align: 自我对齐流程
https://github.com/bigcode-project/starcoder2-self-align
-
StarCoder2-Self-OSS-Instruct: 自我生成的、用于指令微调的数据集
https://hf.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/
英文原文: https://hf.co/blog/sc2-instruct
原文作者: Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Harm de Vries, Leandro von Werra, Arjun Guha, Lingming Zhang
译者: innovation64