前言
Excel拥有在办公领域最广泛的受众群体,以其强大的数据处理和可视化功能,成了无可替代的工具。它不仅可以呈现数据清晰明了,还能进行数据分析、图表制作和数据透视等操作,为用户提供了全面的数据展示和分析能力。
今天小编就为大家介绍一下,如何通过葡萄城公司的纯前端表格控件SpreadJS和后端表格组件GcExcel实现一张Excel报表模板并进行数据的录入与填报。
环境准备
Node.js
SpreadJS在线表格编辑器
代码文件(可作为阅读本文的参考)
前端
设计Excel报表模板
1. 加载制作报表的数据源:
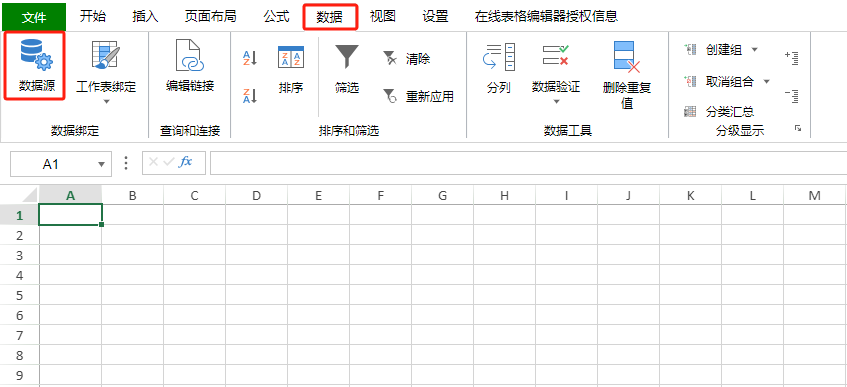
打开SpreadJS在线表格编辑器,在设计分组报表之前,需要数据准备的相关工作,点击表格工具栏上【数据】Tab中的【数据源】按钮,为其添加好数据源。 ![]()
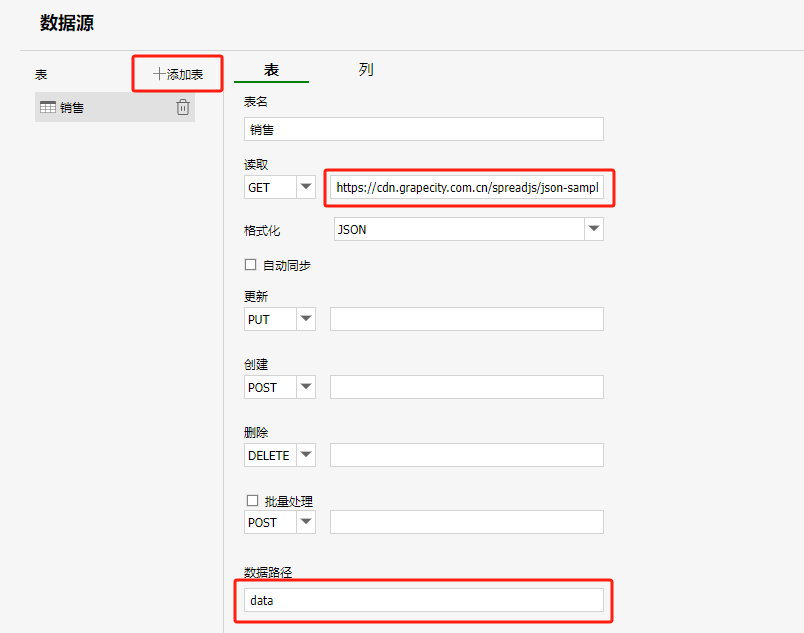
通过【添加表】按钮添加每一个数据源对象(每一个数据源对象对应一张表),并配置读取数据的路径(路径可以是一个请求对应格式数据源的地址,也可以是一个服务端请求的地址,由服务端返回一个符合格式的数据源对象)。
数据路径为可选字段,如果json中包含多个数据源,可以通过设置数据路径进行区分。 ![]()
2. 添加报表模板:
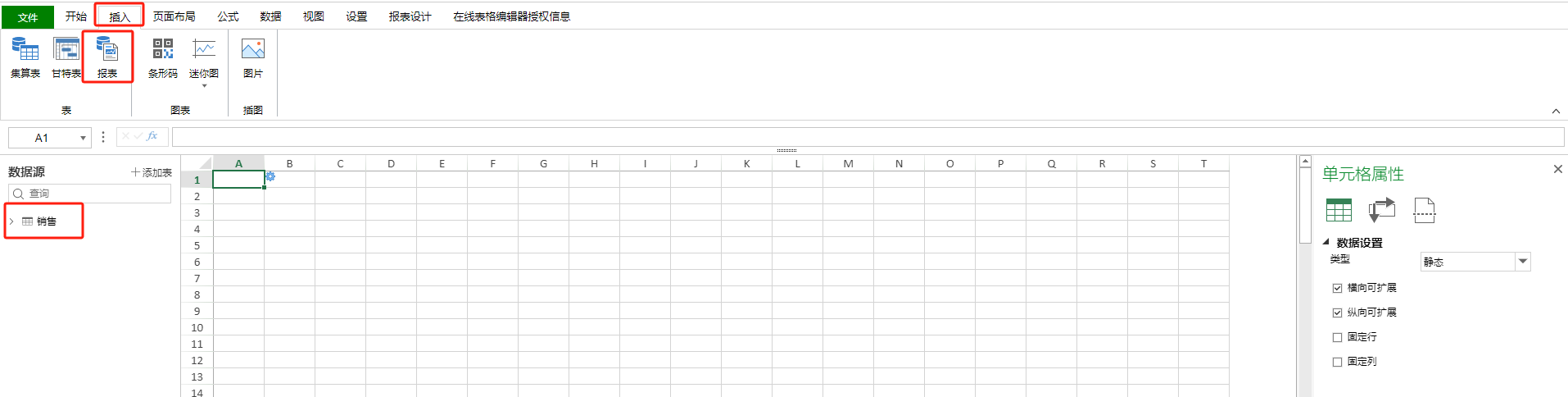
添加完数据源之后,点击【插入】Tab的报表按钮,插入一张新的报表模板,之前添加的数据源对象会在左侧的数据源列表中显示,如下图所示。 ![]()
3. 设置分组报表:
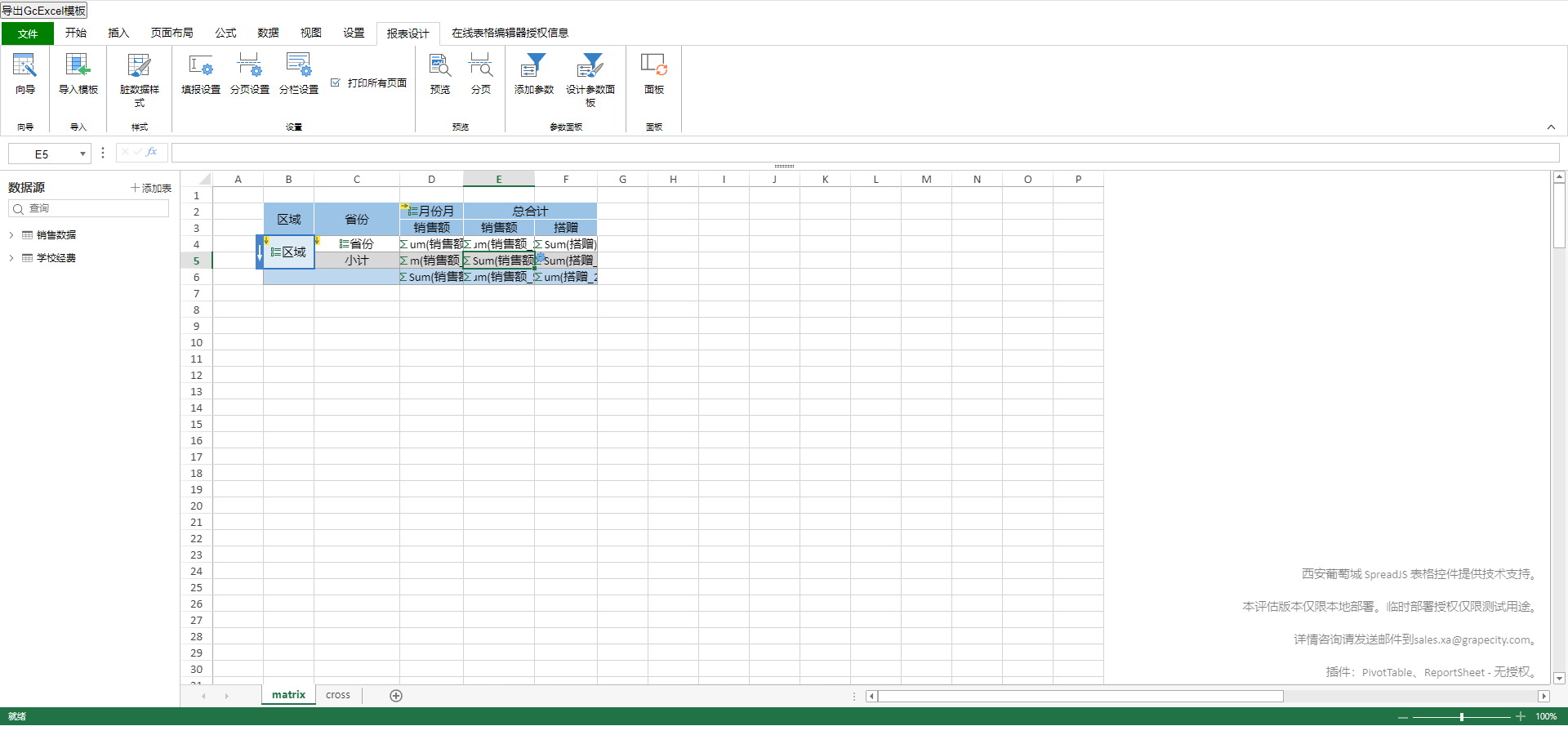
通过拖拽左侧数据源列表中的字段,可以快速构建一个按照销售区域、省市、商品类型字段进行层层分组,统计销售额和利润的报表模板,如下图所示: ![]()
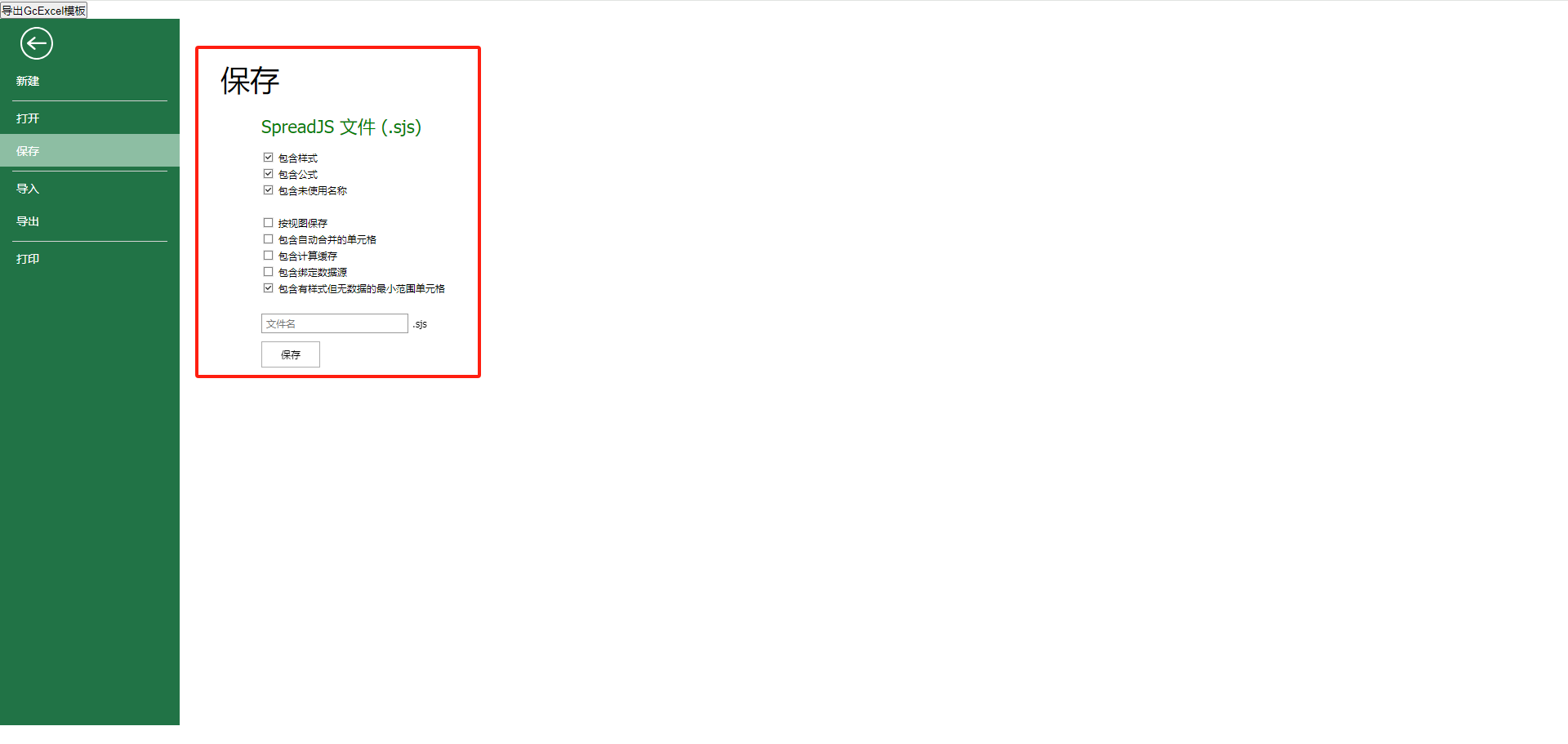
4. 保存Excel模板为sjs文件 ![]()
修改Excel报表模板
将Excel报表模板保存为.sjs文件后,小编现在需要将**Excel报表模板中的部分单元格转换为GcExcel模板语言,**具体操作如下:
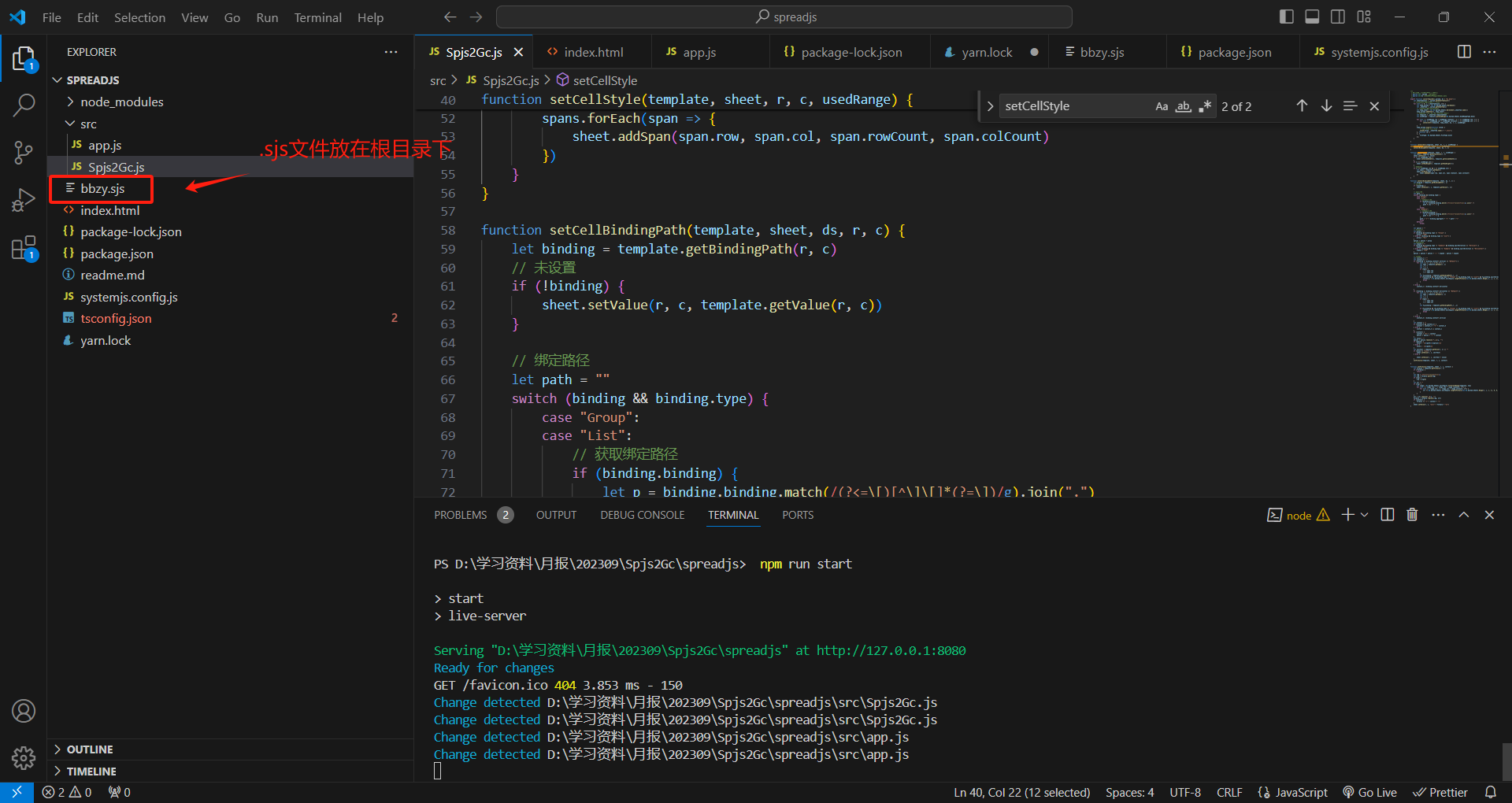
把.sjs文件放到SpreadJS前端代码的根目录下 ![]()
5. 将Excel模板转化为GcExcel模板语法
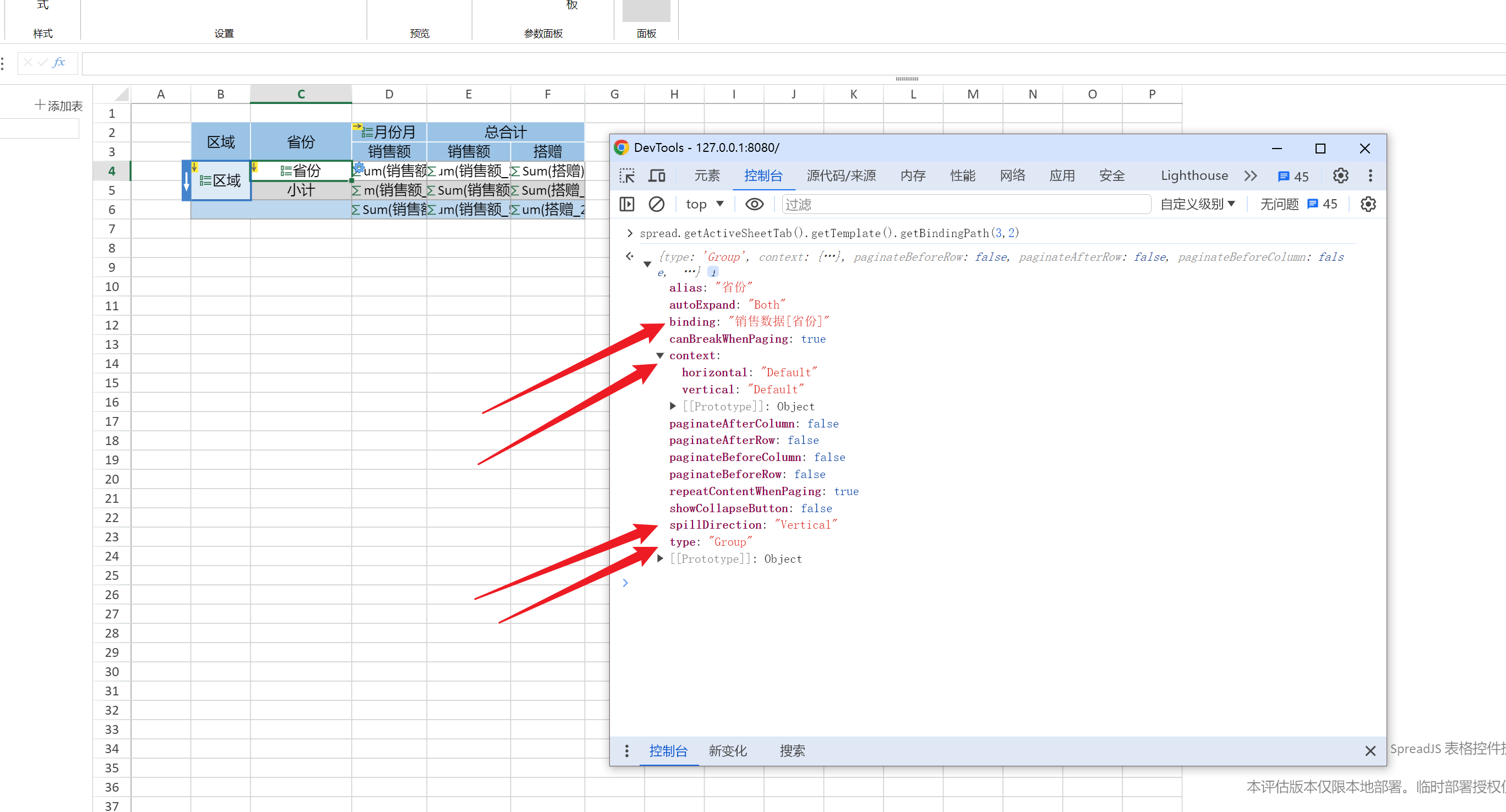
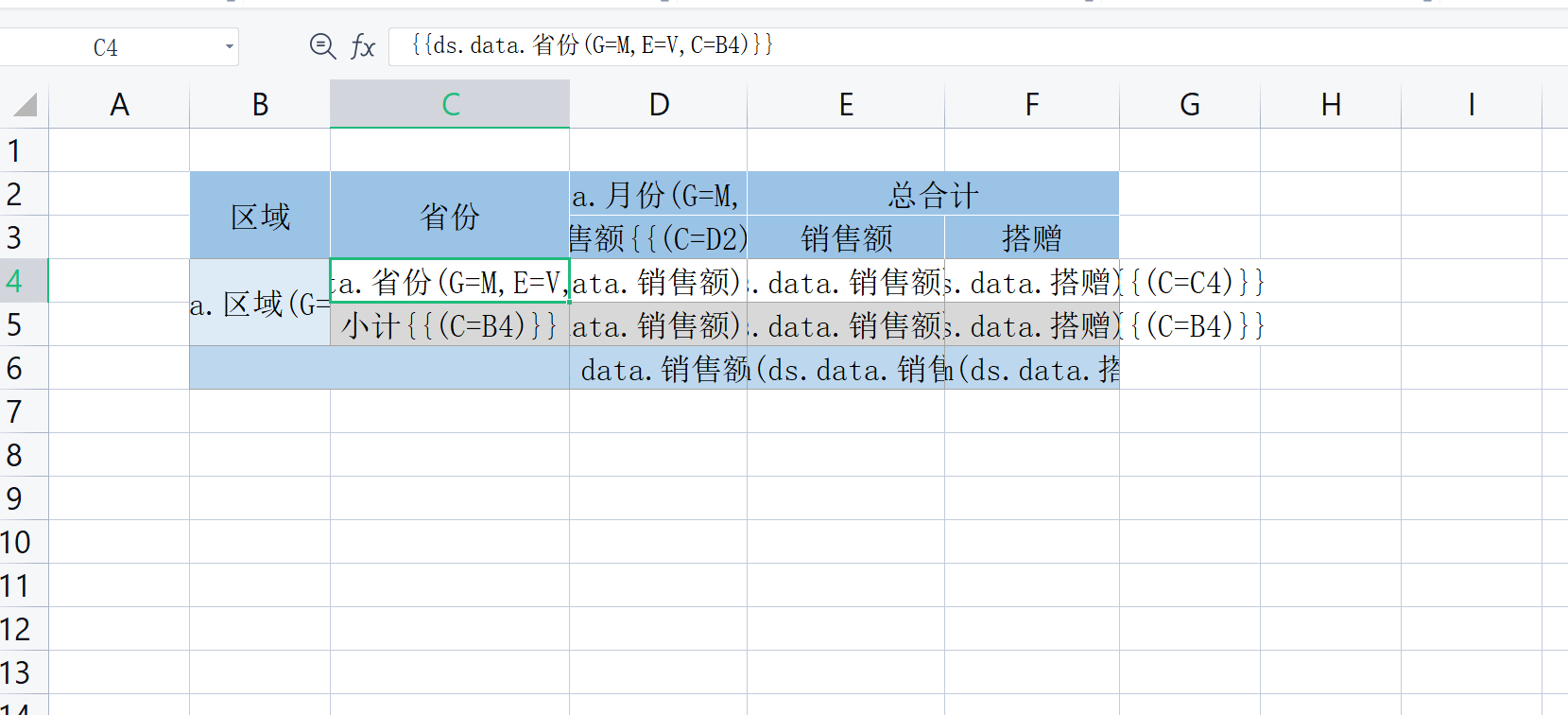
以Excel报表模板(如下图所示)中的C4单元格(省份)为例,小编先通过getBindingPath方法拿到模板api的信息(下图中的DevTools中的队列信息) ![]()
获取到api的信息之后,再解析出它的绑定路径:
//此为部分代码,完整代码在文末的Gitee链接中
let binding = template.getBindingPath(r, c) // binding内容如上图
// ...
// 绑定路径
let path = ""
switch (binding && binding.type) {
case "Group":
case "List":
if (binding.binding) {
let p = binding.binding.match(/(?<=\[)[^\]\[]*(?=\])/g).join(".")
path += ds + "." + p // path="销售数据.省份"
}
break;
// ...
}
然后再解析出其合并类型和扩展方向:
// Group类型
let group = ""
if (binding && binding.type == "Group") {
group = "G=M"
} else if (binding && binding.type == "List") {
group = "G=L"
}
// Expand方向
let expand = ""
if (binding && binding.type != "Summary" && binding.spillDirection == "Vertical") {
expand = "E=V"
} else if (binding && binding.type != "Summary" && binding.spillDirection == "Horizontal") {
expand = "E=H"
}
最后将这些信息整合在一起,加上双花括号后,那么导出的Excel文件中的C4单元格的内容应该是如下的GcExcel模板语法:
{{ds.销售数据.省份(E=V,G=M)}}
6. 运行前端项目,导出Excel模板文件
- 输入指令【npm install】下载依赖
- 输入指令【npm run start】启动项目(启动后如下图所示)
![]()
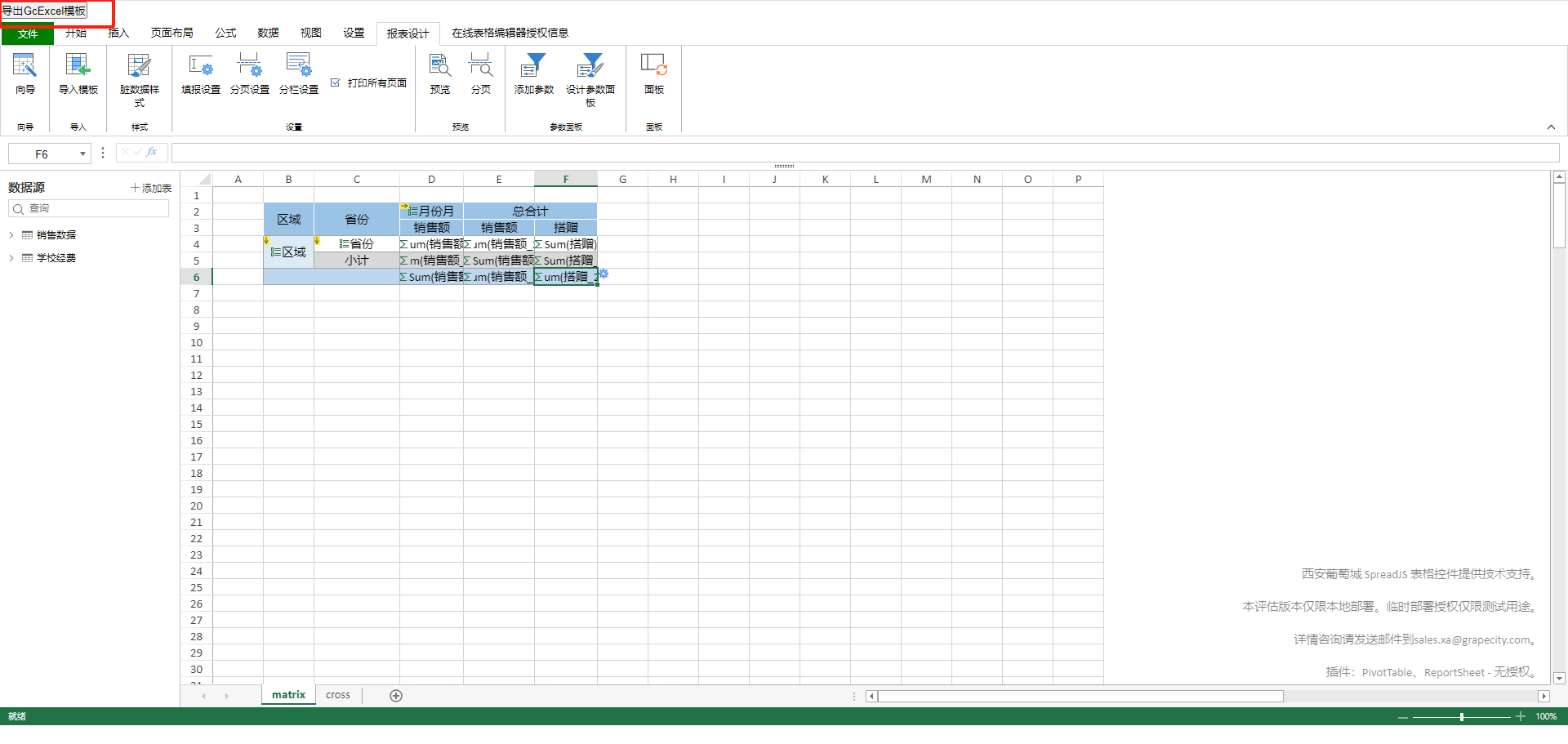
最后将修改后的模板导出为Excel文件,如下图所示,可以看到,省份单元中的信息已经修改为GcExcel模板语法。
![]()
后端
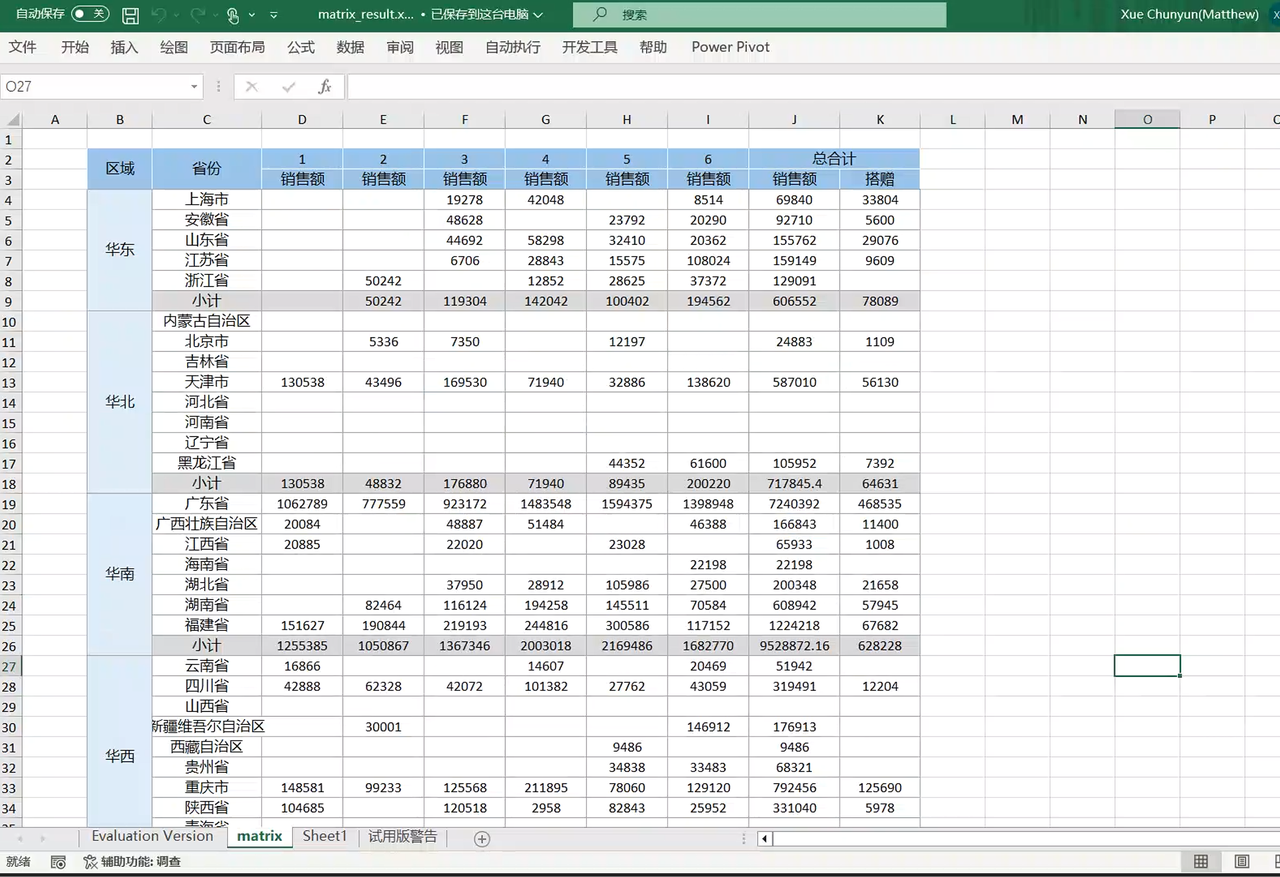
打开GcExcel后端代码,将前面导出的Excel模板文件放到代码文件的根目录下,最后运行的main函数即可将数据传入Excel模板文件,最后会生成一个带数据的Excel报表。 ![]()
结语
以上就是如何使用SpreadJS+GcExcel制作一张Excel报表的全过程,如果您想了解更多信息,欢迎点击这里查看。
扩展链接:
【干货放送】财务报表勾稽分析要点,一文读尽!
为什么你的财务报表不出色?推荐你了解这四个设计要点和!
纯前端类 Excel 表格控件在报表勾稽分析领域的应用场景解析