升级内容:
1、基于React重构Web端,提升Web端操作体验;
2、支持自定义存储引擎和rpc组件功能;
3、文档优化和部分代码逻辑优化
一键部署,一行代码接入,无需大数据研发运维经验,轻松实现海量数据实时统计,使用 XL-LightHouse 后:
- 1、再也不需要用 Flink、Spark、ClickHouse 或者基于 Redis 这种臃肿笨重的方案跑数了;
- 2、再也不需要疲于应付对个人价值提升没有多大益处的数据统计需求了,能够帮助您从琐碎反复的数据统计需求中抽身出来,从而专注于对个人提升、对企业发展更有价值的事情;
- 3、轻松帮您实现任意细粒度的监控指标,是您监控服务运行状况,排查各类业务数据波动、指标异常类问题的好帮手;
- 4、培养数据思维,辅助您将所从事的工作建立数据指标体系,量化工作产出,做专业严谨的职场人,创造更大的个人价值;
概述
- XL-LightHouse 是针对互联网领域繁杂的流式数据统计需求而开发的一套集成了数据写入、数据运算、数据存储和数据可视化等一系列功能,支持超大数据量,支持超高并发的【通用型流式大数据统计平台】。
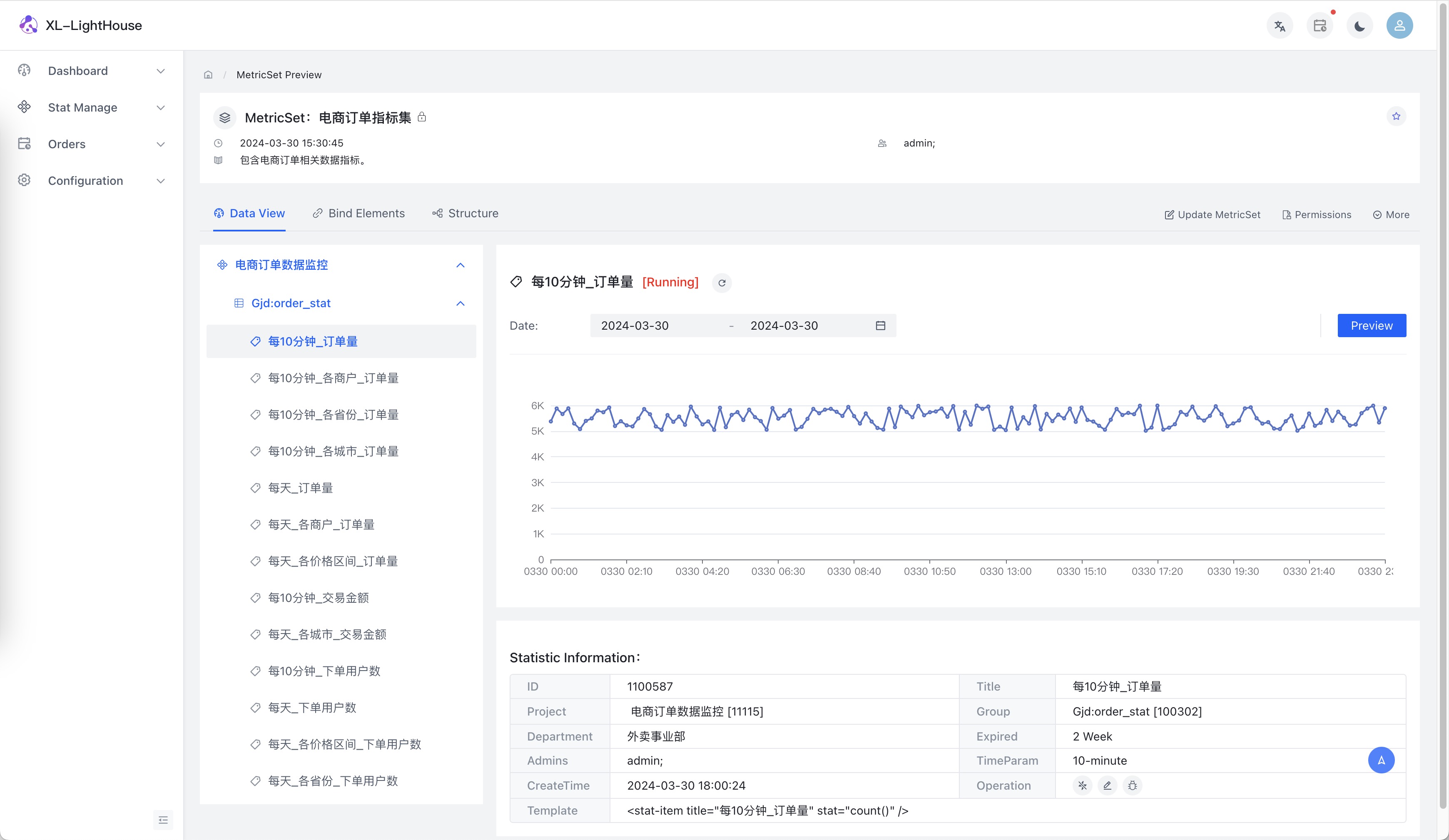
- XL-LightHouse 目前已基本涵盖了常见的流式数据统计场景,包括 count、sum、max、min、avg、distinct、topN/lastN 等多种运算,支持多维度计算,支持分钟级、小时级、天级多个时间粒度的统计,支持自定义统计周期的配置。
- XL-LightHouse 内置丰富的转化类函数、支持表达式解析,可以满足各种复杂的条件筛选和逻辑判断。
- XL-LightHouse 是一套功能完备的流式大数据统计领域的数据治理解决方案,它提供了比较友好和完善的可视化查询功能,并对外提供 API 查询接口,此外还包括数据指标管理、权限管理、统计限流等多种功能。
- XL-LightHouse 支持时序性数据的存储和查询。
产品优势
- 一套系统三种用途,可作为:通用型流式大数据统计系统、数据指标管理系统和数据指标可视化系统。
- XL-LightHouse面向企业繁杂的流式数据统计需求,可以帮助企业在极短时间内快速实现数以万计、数十万计的数据指标,而这是Flink、Spark、ClickHouse、Doris之类技术所远不能比拟的,XL-LightHouse帮助企业低成本实现数据化运营,数据指标体系可遍布企业运转的方方面面;
- 对单个流式统计场景的数据量无限制,可以非常庞大,也可以非常稀少,您既可以使用它完成十亿级用户量APP的DAU统计、十几万台服务器的运维监控、一线互联网大厂数据量级的日志统计、也可以用它来统计一天只有零星几次的接口调用量、耗时状况;
- 支持高并发查询统计结果;
- 一键部署、一行代码接入,无需专业的大数据研发人员,普通工程人员就可以轻松驾驭;
- 有完善的数据指标可视化以及数据指标管理维护等功能;
收益
- XL-LightHouse 可以帮助企业更快速的搭建起一套较为完善的、稳定可靠的数据化运营体系,节省企业在数据化运营方面的投入,主要体现在以下几个方面:
- 减少企业在流式大数据统计方面的研发成本和数据维护成本。
- 帮助企业节省时间成本,辅助互联网产品的快速迭代。
- 为企业节省较为可观的服务器运算资源。
- 便于数据在企业内部的共享和互通。
- 此外,XL-LightHouse 对中小企业友好,它大大降低了中小企业使用流式大数据统计的技术门槛,通过简单的页面配置和数据接入即可应对繁杂的流式数据统计需求。
项目地址
https://github.com/xl-xueling/xl-lighthouse.git
https://gitee.com/xl-xueling/xl-lighthouse.git
演示站点
演示站点:http://119.91.203.220:19232/ 测试账号:admin,密码:123456
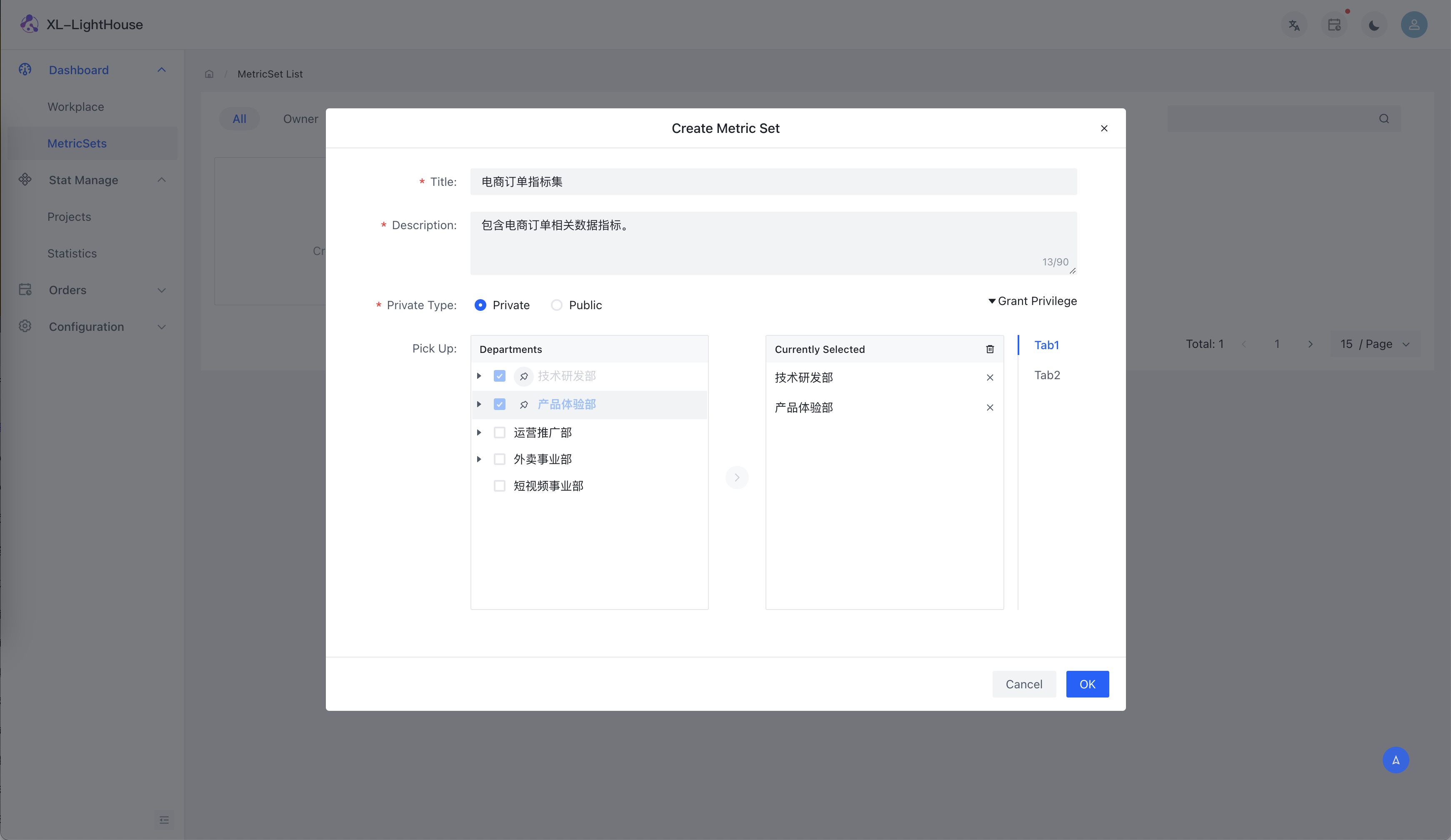
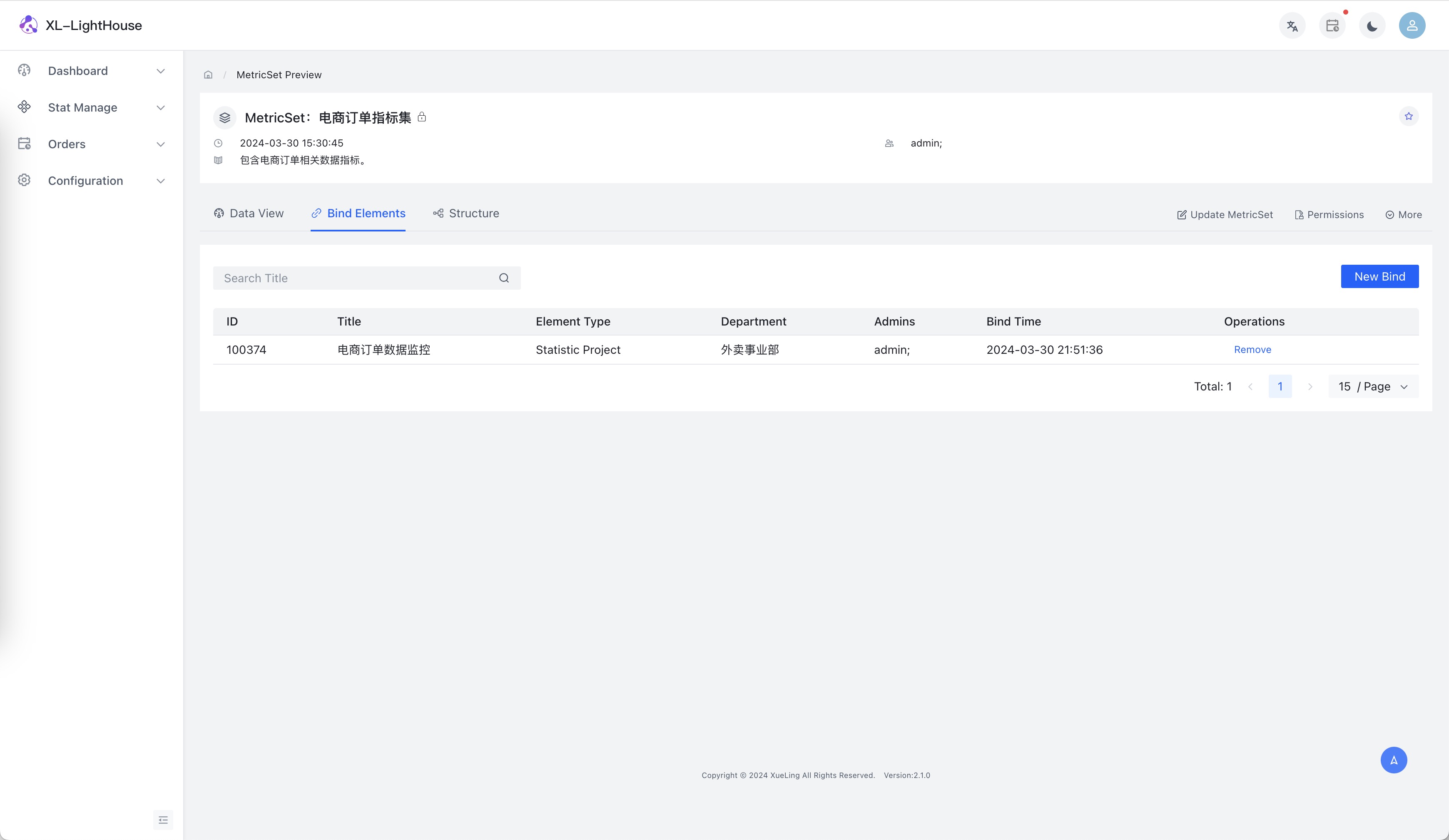
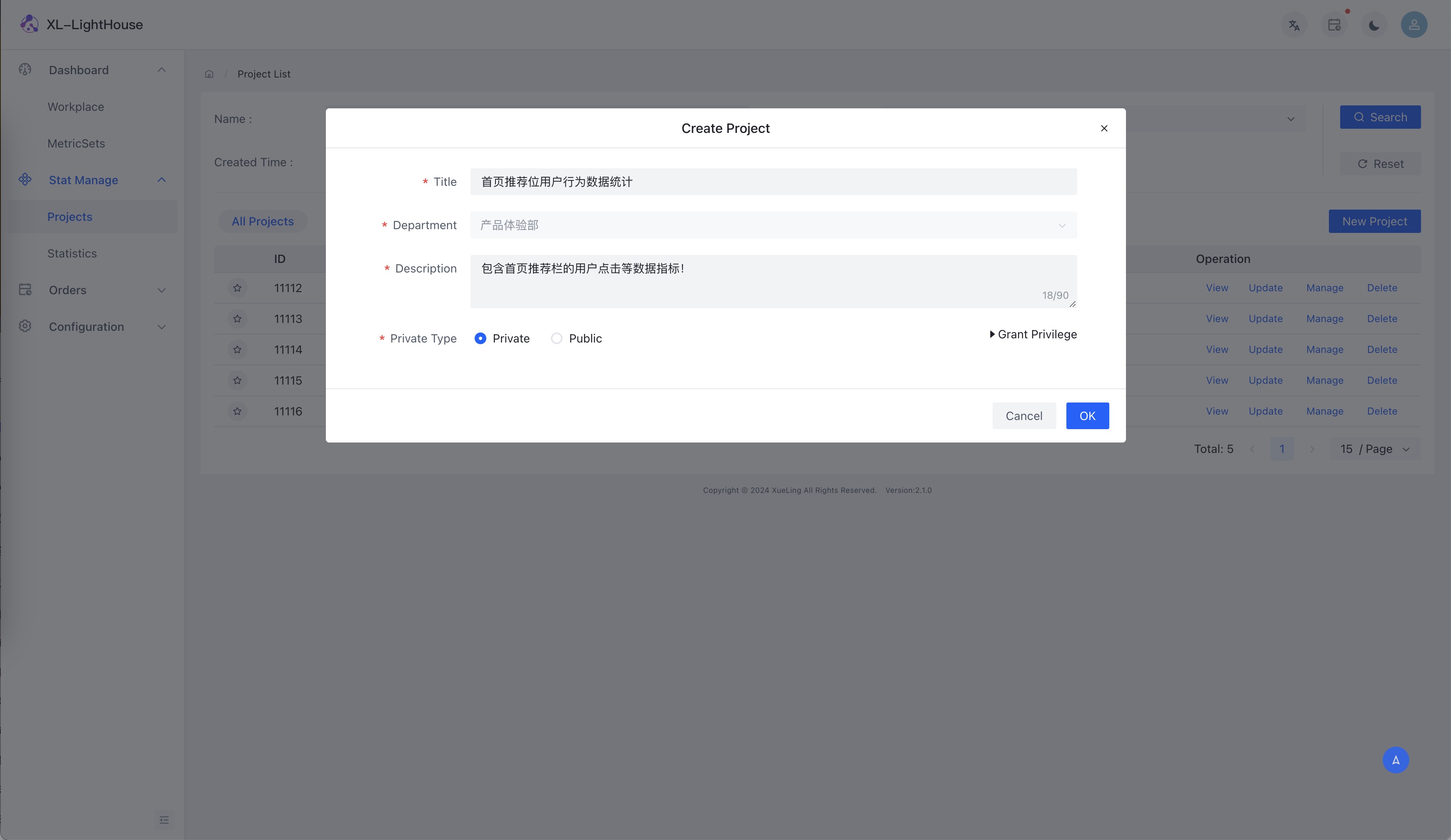
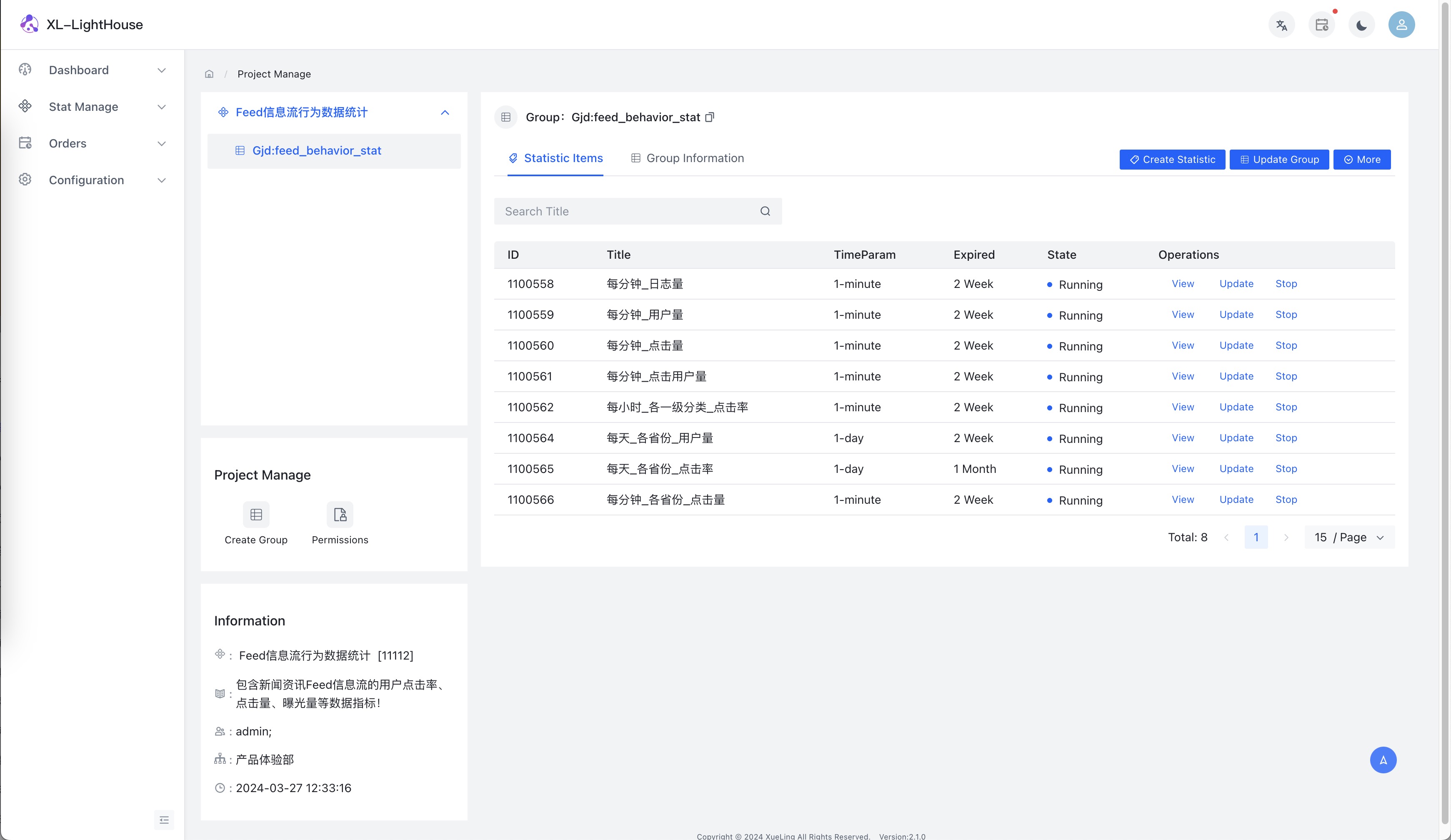
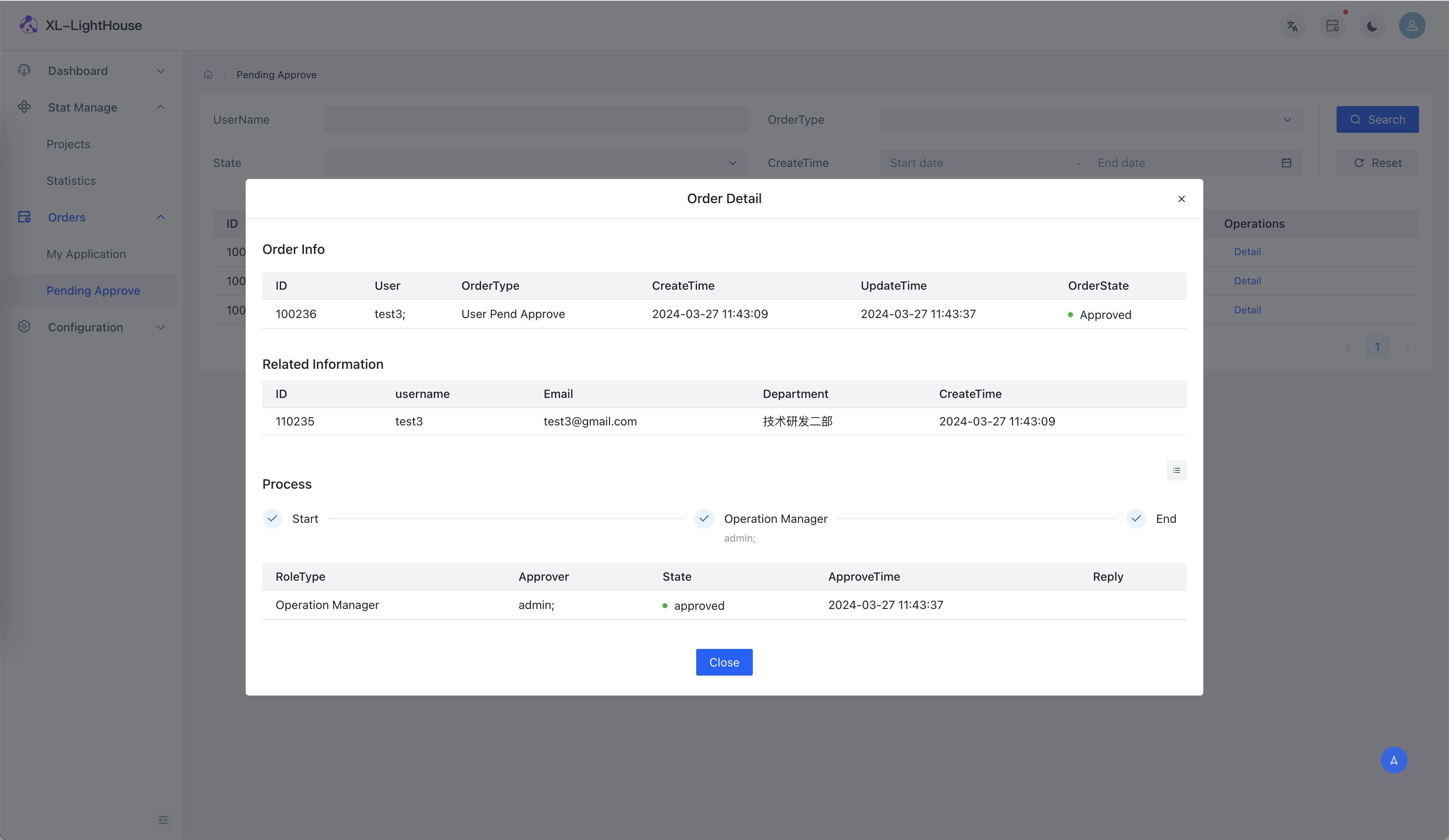
部分功能预览
![]()
![]()
![]()
![]()
![]()
![]()
![]()