异常检测是机器学习领域常见的应用场景,例如金融领域里的信用卡欺诈,企业安全领域里的非法入侵,IT运维里预测设备的维护时间点等。我们今天就来看看异常检测的基本概念,算法,然后看看如何利用TensorflowJS来进行异常检测。
什么是异常点?
异常点是指数据中和其它点不一样的点,异常检测就是要找到这些点。通常有以下这些不同类型的异常:
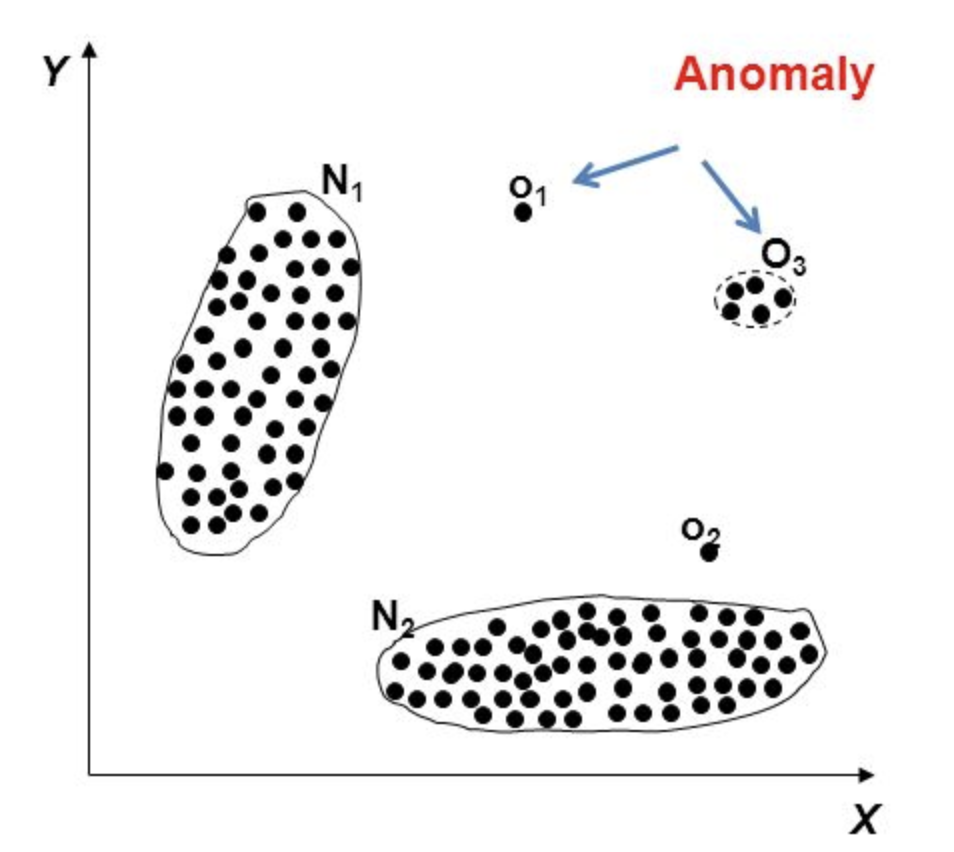
- 点异常 Point Anomalies
单个点和其它数据显著的不同
![]()
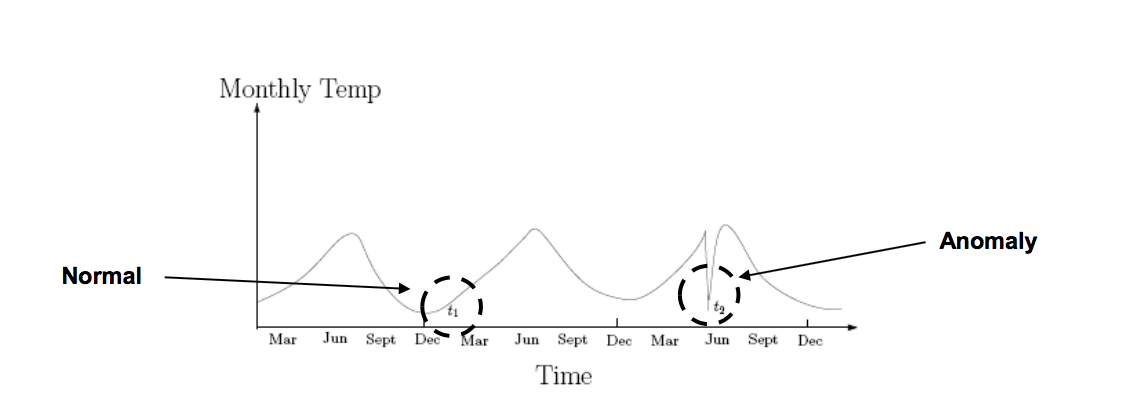
- 上下文异常 Contextual Anomalies
数据在所在的上下文环境中是个异常,例如下图t1不是异常而t2是因为t2前后的数据和t2有显著的差异。
![âContextual Anomaliesâçå¾çæç´¢ç»æ]()
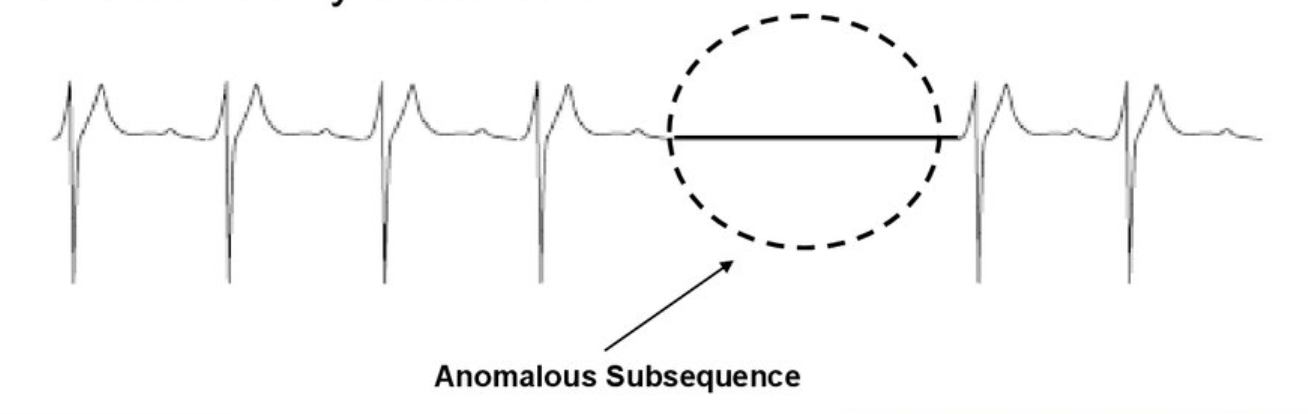
- 集合异常 Collective Anomalies.
集合异常是指一组数据点和其它的数据有显著的不同,这一组数据的集合构成异常
![]()
从数据维度的角度来看,异常也分为单变量(univariate)和多变量异常(multivariate)。
异常检测的算法主要包括基于统计的算法和基于机器学习的算法。
异常检测的统计学方法
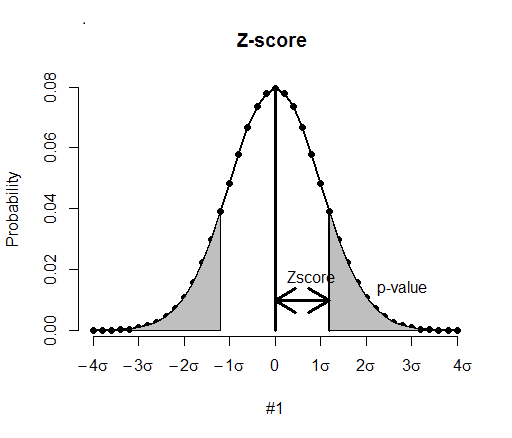
利用统计方法来进行异常检测有两种,第一种是参数化的,就是假定正常的数据是基于某种参数分布的,那么我们可以通过训练数据估计出数据的分布概率,那么对于每一个要分析的数据点都计算出该数据点在这个概率分布下生成的概率。这个值越高,说明该数据是正常点的可能性就越大,该数值越低,就说明这个点就越有可能是异常点。
![]()
最常见的方式就是ZScore,假定数据符合正态分布,ZScore计算数据点偏离均值多少个标准差。ZScore越大说明数据偏离均值越远,那么它是异常的概率就越高。
非参数化的方法并不假定数据的先验分布,数据的分布是从训练数据中学习而来的。
其它还有一些统计方法诸如:
利用统计方法做异常检测非常容易理解,计算效率也很好。但是这种方法存在一些挑战:
- 数据点中的噪声和异常可能拥有类似的统计特征,那么就很难检测出来。
- 异常的定义可能会发生变化,一个固定的伐值可能并不适用。例如应用zscore,到底是大于3是异常还是大于4是异常,这很难定义。
异常检测的机器学习方法
从监督学习和非监督学习的角度来看,如果已经有了标记异常点的大量训练数据,异常检测可以简单的转化为分类问题,也就是数据分两类,正常点和异常点。但是在现实中,往往很难找到大量标记好异常点的训练数据,所以往往需要非监督学习来进行异常检测。
利用数据的相似度来检测异常的基本假设是,如果被检测的数据和已有的数据相似度大,那么它是正常数据的可能性就大。相似度的学习主要有基于距离的(KNN)和基于密度的(LOF)。
基于聚类的异常检测的基本假设是,正常数据聚集在一起,异常数据聚集在一起。
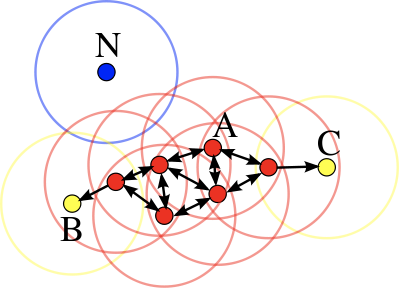
DBSCAN是异常检测常用的聚类方法。关于DBSCAN算法的介绍,大家可以参考我的博客图解机器学习
![]()
如上图所示,DBSCAN可以学习出正常聚类的中心点A,边缘点BC以及异常点N。
但是DBSCAN对于各个超参数的设定非常敏感,利用该方法虽然不需要标记异常点,但是找到合适的超参数并不容易。
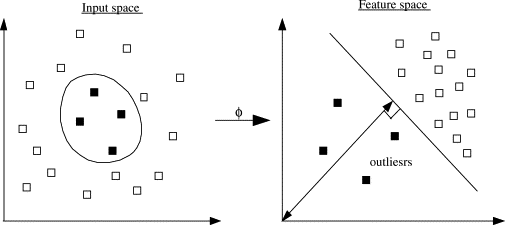
支持向量机(SVM)是一种监督学习的分类方法,单类支持向量机(OneClassSVM)是SVM的一种扩展,可以用于非监督的检测异常。
![]()
该算法可以学习出正常点和异常点之间的边界。
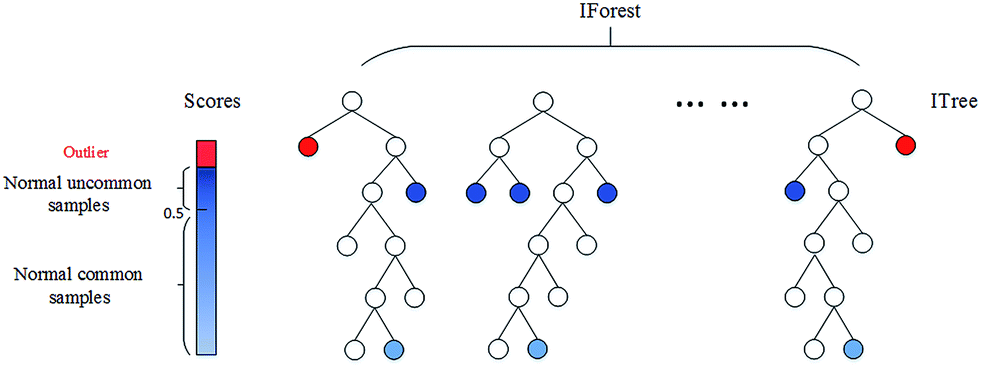
隔离森林(isolation forests)是检测数据中异常值或新颖性的一种有效方法。这是一种基于二元决策树的方法。
隔离森林的基本原则是异常值很少,而且与其他观测结果相差甚远。为了构建树(训练),算法从特征空间中随机选取一个特征,并在最大值和最小值之间随机选择一个随机分割值。这是针对训练集中的所有观察结果。为了建造森林,树木整体被平均化为森林中的所有树木。
然后,为了预测,它将观察与“节点”中的分裂值进行比较,该节点将具有两个节点子节点,在该子节点上将进行另一次随机比较。由算法为实例做出的“分裂”的数量被命名为:“路径长度”。正如预期的那样,异常值的路径长度将比其他观察值更短。
![]()
利用深度学习进行异常检测
好了我们了解了异常检测的基本概念和方法,那么如何利用深度学习来进行异常检测呢?
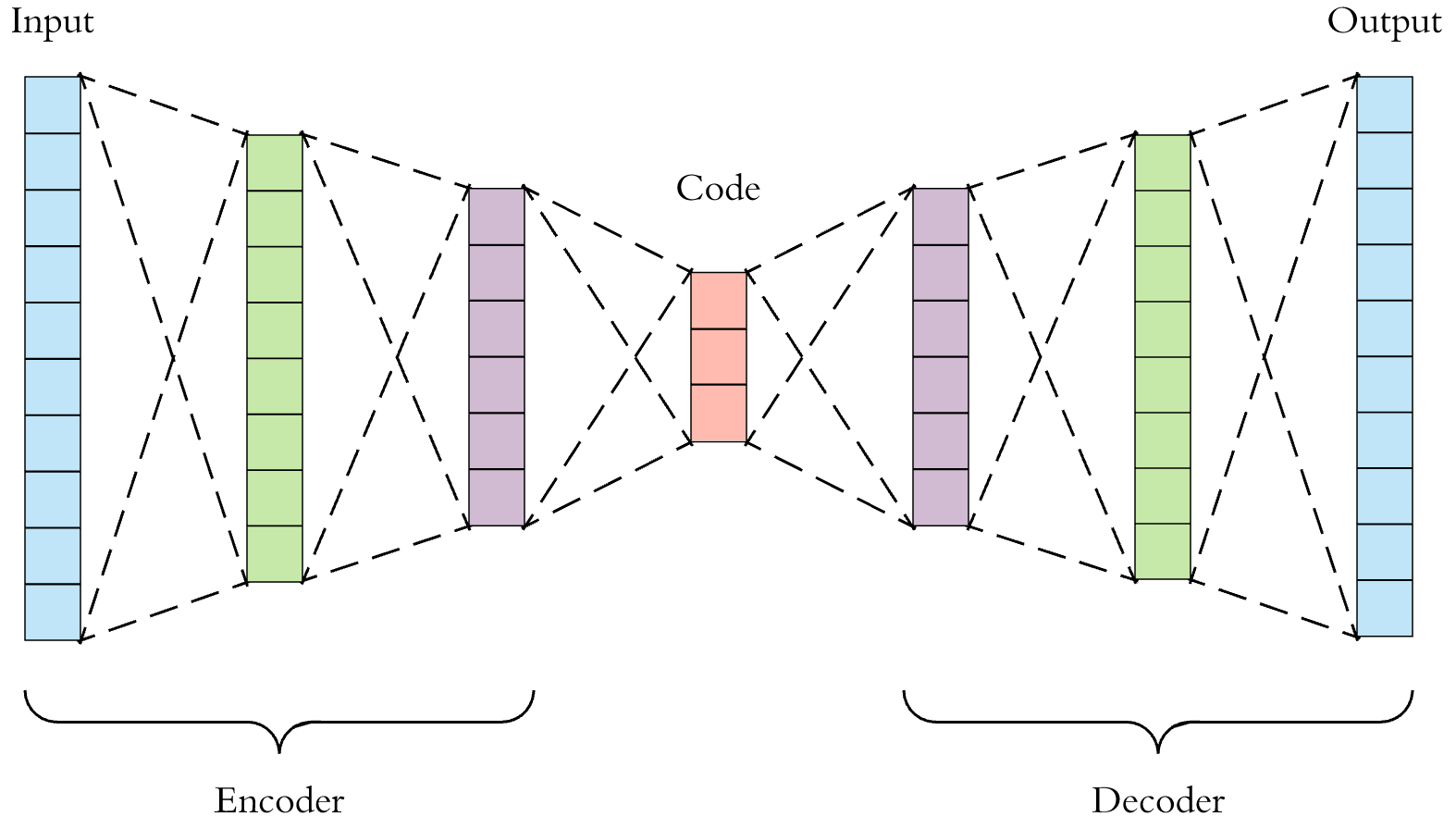
虽然神经网络的主要应用是监督学习,但是其实也可以利用它来进行非监督学习,这里我们就需要了解自编码器(Autoencoder)了。
![âautoencoderâçå¾çæç´¢ç»æ]()
自编码器就是类似上图的一个网络,包含编码和解码两个主要的部分,我们利用训练数据集对该网络进行训练,输出的目标等于输入的数据。也就是说我们训练了一个可以重建输入数据的深度神经网络。那么这样做有什么用能。
我们可以看出编码的过程其实类似一个PCA的降维过程,就是经过编码,找到数据中的主要成分,利用该主要成份能够重建原始数据,就好像数据压缩和解压缩的过程,用更少的数据来取代原始数据。对于一般的自编码器的应用,训练好的自编码器不会全部用于构建网络,一般是使用编码的部分来进行数据的特征提取,降维,以达到更有效的计算。
利用自编码器,我们假定正常数据通过自编码器应该会还原,也就是输入和输出是一样的,而对于异常数据,还原出来的数据和原始数据存在差异。基本假设就是还原出来的数据和输入数据差异越小,那么它是正常数据的可能性就越大,反之它是异常数据的可能性就越大。
下面我们就来看一个利用自编码器用tensorflowJS来检测信用卡欺诈数据的例子。数据集来自Kaggle,考虑到TensorflowJS在浏览器中的性能问题,我对原始数据取样10000条记录来演示。
加载数据
该数据经过kaggle处理,包含Time交易时间,Amount交易数额,V1-V28是经过处理后的特征,Class表示交易的类别,1为欺诈交易。
async function loadData(path) {
return await d3.csv(path);
}
const dataset = await loadData(
"https://cdn.jsdelivr.net/gh/gangtao/datasets@master/csv/creditcard_sample_raw.csv"
);
数据预处理
function standarize(val, min, max) {
return (val - min) / (max - min);
}
function prepare(dataset) {
const processedDataset = dataset.map(item => {
const obj = {};
for (let i = 1; i < 29; i++) {
const key = `V${i}`;
obj[key] = parseFloat(item[key]);
}
obj["Class"] = item["Class"];
obj["Time"] = parseFloat(item["Time"]);
obj["Amount"] = parseFloat(item["Amount"]);
return obj;
});
const timeMax = d3.max(processedDataset.map(i => i.Time));
const timeMin = d3.min(processedDataset.map(i => i.Time));
const amountMax = d3.max(processedDataset.map(i => i.Amount));
const amountMin = d3.min(processedDataset.map(i => i.Amount));
processedDataset.forEach(item => {
item.stdTime = standarize(item.Time, timeMax, timeMin);
item.stdAmount = standarize(item.Amount, amountMax, amountMin);
});
return processedDataset;
}
const preparedDataset = prepare(dataset);
在数据预处理阶段我们对Time和Amount做标准化处理使它的值在(0-1)之间。
生成训练数据集
function makeTrainData(dataset) {
console.log(dataset.length);
const normalData = dataset.filter(item => item.Class == "0");
const anomalData = dataset.filter(item => item.Class == "1");
const sliceIndex = normalData.length*0.8;
const normalTrainData = normalData.slice(0,sliceIndex);
const normalTestData = normalData.slice(sliceIndex+1, normalData.length);
console.log(normalData.length);
const trainData = { x: [], y: [] };
normalTrainData.forEach(item => {
const row = [];
for (let i = 1; i < 29; i++) {
const key = `V${i}`;
row.push(item[key]);
}
row.push(item["stdAmount"]);
row.push(item["stdTime"]);
trainData.x.push(row);
trainData.y.push(row);
});
const testData = normalTestData.map(item => {
const row = [];
for (let i = 1; i < 29; i++) {
const key = `V${i}`;
row.push(item[key]);
}
row.push(item["stdAmount"]);
row.push(item["stdTime"]);
return row;
});
const testAnomalData = anomalData.map(item => {
const row = [];
for (let i = 1; i < 29; i++) {
const key = `V${i}`;
row.push(item[key]);
}
row.push(item["stdAmount"]);
row.push(item["stdTime"]);
return row;
});
return [trainData, testData, testAnomalData];
}
const [trainData, testData, testAnomalData] = makeTrainData(preparedDataset);
我们选择80%的正常数据做训练,另外20%的正常交易数据和所有的异常交易数据做测试。
构建模型和训练
function buildModel() {
const model = tf.sequential();
//encoder Layer
const encoder = tf.layers.dense({
inputShape: [INPUT_NUM],
units: FEATURE_NUM,
activation: "tanh"
});
model.add(encoder);
const encoder_hidden = tf.layers.dense({
inputShape: [FEATURE_NUM],
units: HIDDEN_NUM,
activation: "relu"
});
model.add(encoder_hidden);
//decoder Layer
const decoder_hidden = tf.layers.dense({
units: HIDDEN_NUM,
activation: "tanh"
});
model.add(decoder_hidden);
//decoder Layer
const decoder = tf.layers.dense({
units: INPUT_NUM,
activation: "relu"
});
model.add(decoder);
//compile
const adam = tf.train.adam(0.005);
model.compile({
optimizer: adam,
loss: tf.losses.meanSquaredError
});
return model;
}
async function watchTraining() {
const metrics = ["loss", "val_loss", "acc", "val_acc"];
const container = {
name: "show.fitCallbacks",
tab: "Training",
styles: {
height: "1000px"
}
};
const callbacks = tfvis.show.fitCallbacks(container, metrics);
return train(model, data, callbacks);
}
async function trainBatch(data, model) {
const metrics = ["loss", "val_loss", "acc", "val_acc"];
const container = {
name: "show.fitCallbacks",
tab: "Training",
styles: {
height: "1000px"
}
};
const callbacks = tfvis.show.fitCallbacks(container, metrics);
console.log("training start!");
tfvis.visor();
// Save the model
// const saveResults = await model.save('downloads://creditcard-model');
const epochs = config.epochs;
const results = [];
const xs = tf.tensor2d(data.x);
const ys = tf.tensor2d(data.y);
const history = await model.fit(xs, ys, {
batchSize: config.batchSize,
epochs: config.epochs,
validationSplit: 0.2,
callbacks: callbacks
});
console.log("training complete!");
return history;
}
const model = buildModel();
model.summary();
const history = await trainBatch(trainData, model);
我们的自编码器的模型如下:
_________________________________________________________________
Layer (type) Output shape Param #
=================================================================
dense_Dense1 (Dense) [null,16] 496
_________________________________________________________________
dense_Dense2 (Dense) [null,8] 136
_________________________________________________________________
dense_Dense3 (Dense) [null,8] 72
_________________________________________________________________
dense_Dense4 (Dense) [null,30] 270
=================================================================
Total params: 974
Trainable params: 974
Non-trainable params: 0
前两层是编码,后两层是解码。
分析异常值
自编码器模型训练好了以后我们就可以用它来分析异常,我们对测试数据的正常交易记录和异常交易记录用该模型预测,理论上正常交易的输出更接近原始值,而异常交易记录应该偏离原始值比较多,我们利用欧式距离来分析自编码器的输出结果。
async function distance(a, b ){
const axis = 1;
const result = tf.pow(tf.sum(tf.pow(a.sub(b), 2), axis), 0.5);
return result.data();
}
async function predict(model, input) {
const prediction = await model.predict(tf.tensor(input));
return prediction;
}
const predictNormal = await predict(model, testData);
const predictAnomal = await predict(model, testAnomalData);
const distanceNormal = await distance(tf.tensor(testData), predictNormal);
const distanceAnomal = await distance(tf.tensor(testAnomalData), predictAnomal);
const resultData = [];
distanceNormal.forEach(item => {
const obj = {};
obj.type = "normal";
obj.value = item;
obj.index = Math.random();
resultData.push(obj);
})
distanceAnomal.forEach(item => {
const obj = {};
obj.type = "outlier";
obj.value = item;
obj.index = Math.random();
resultData.push(obj);
})
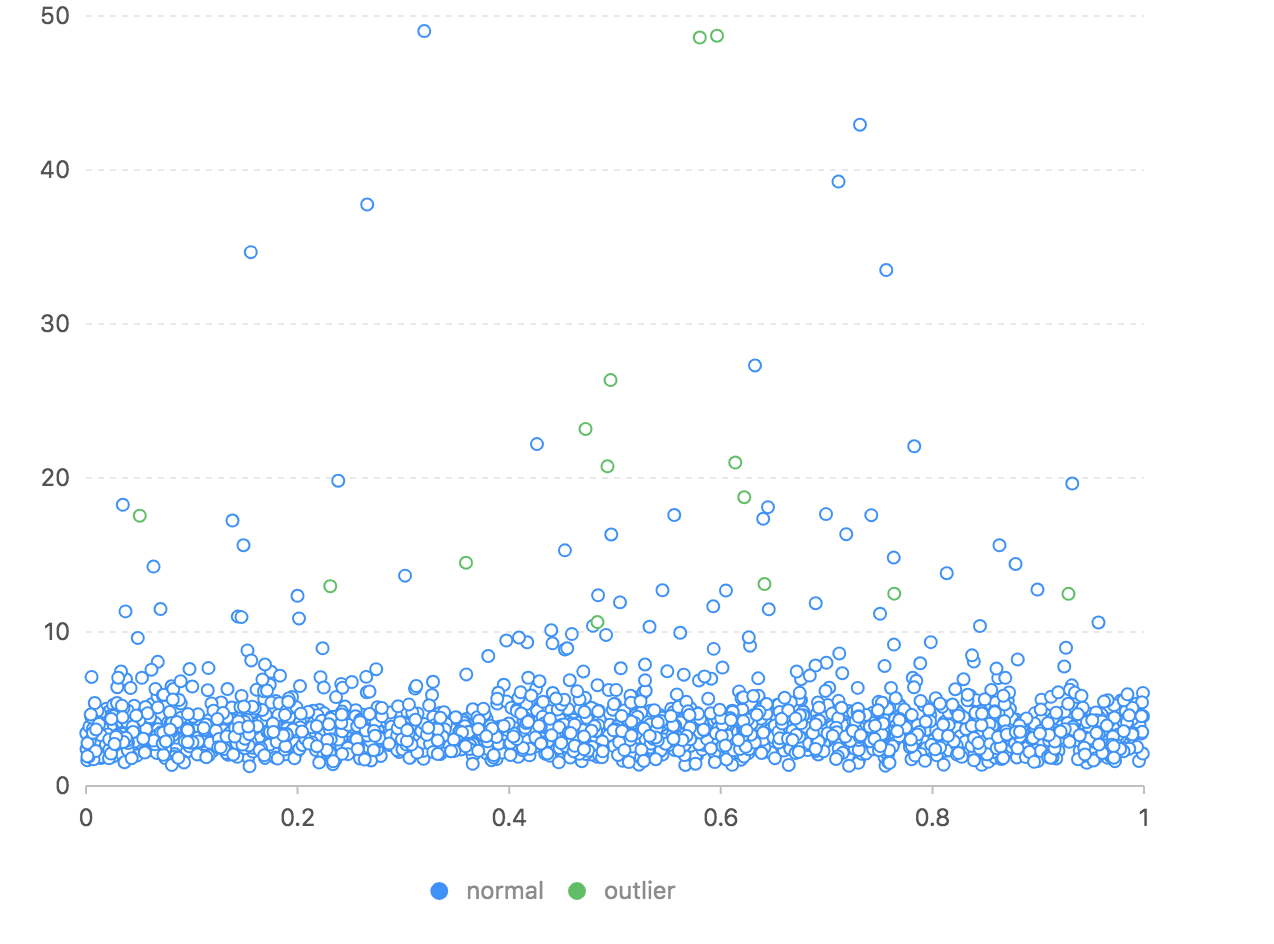
测试结果如下图:
![]()
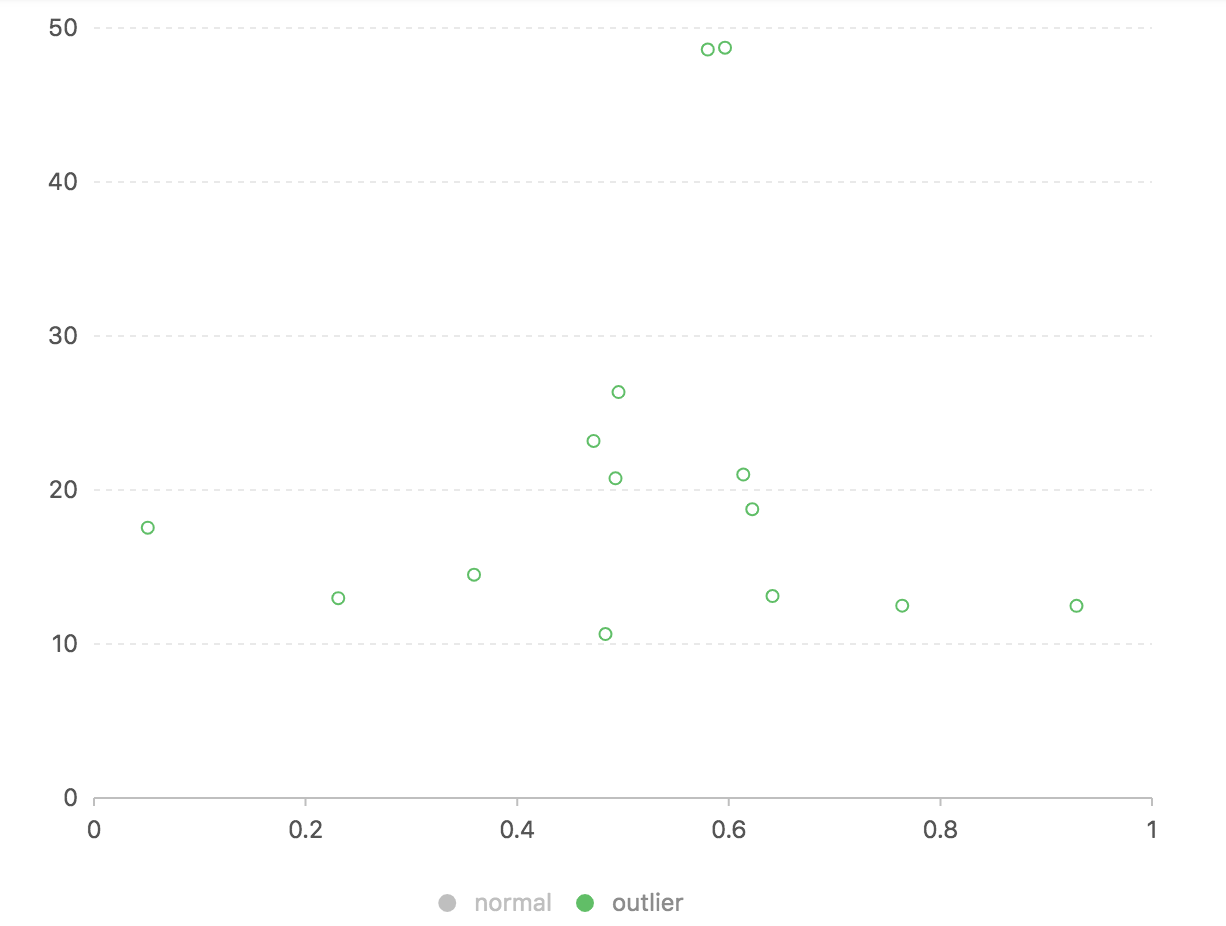
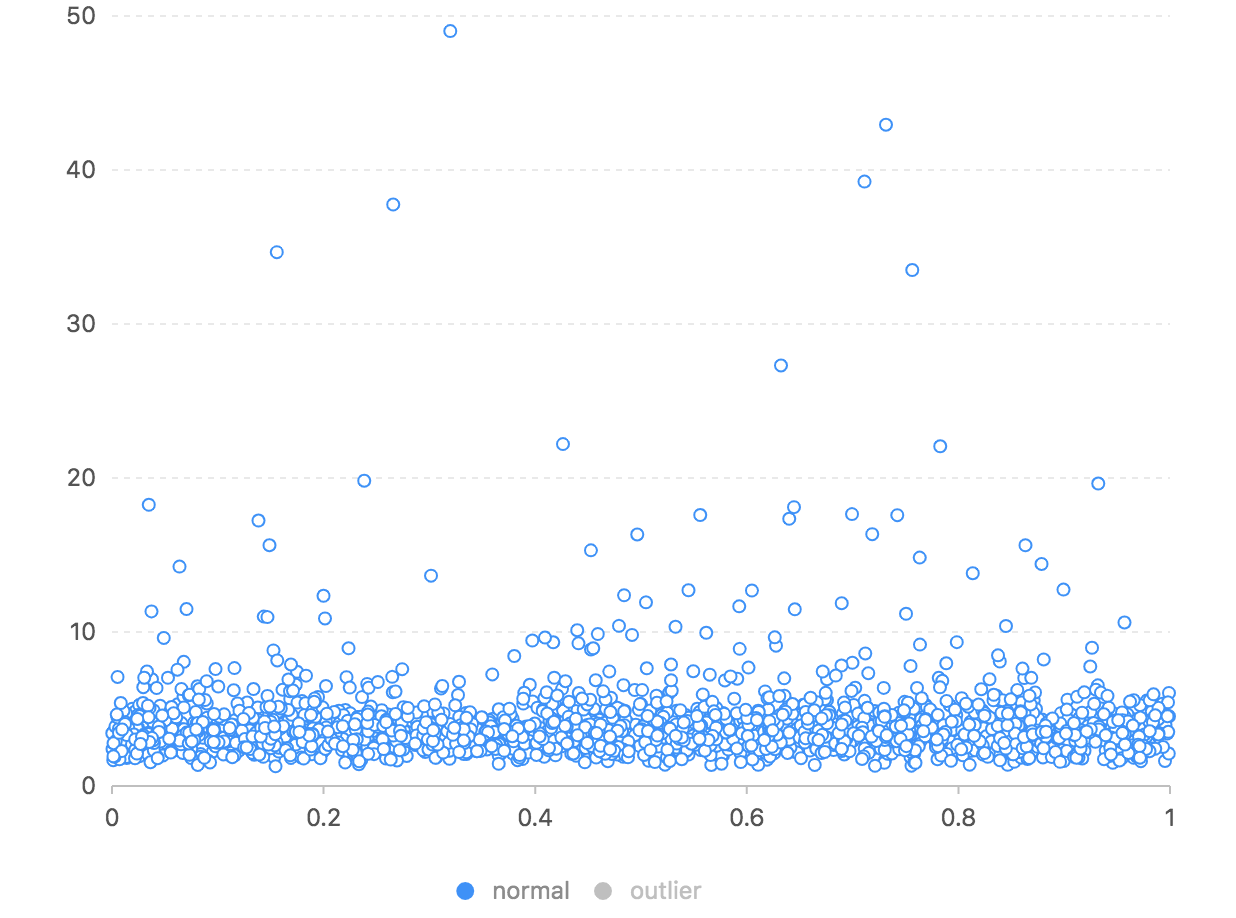
上图绿色是异常交易,蓝色是正常交易。因为正常交易的数量较多,我们可能看不太清楚,我们分别显示如下图:
![]()
![]()
我们看到异常交易的自编码器输出和原始结果的距离都是大于10的,而绝大部分正常交易集中在10以下的区域,如果我们以10为伐值,应该可以找到大部分的异常交易,当然会有大量的正常交易误报。也就是该模型是无法做到完全的分辨正常和异常交易的。
完整的代码见我的Codepen
总结
本文介绍了各种异常检测的主要方法,无论是统计方法,机器学习的方法还是深度学习的方法,其中主要问题都是对于伐值或者参数的设置。
对于统计方法,需要确定究竟生成概率多少的事件是异常是百年一遇的洪水是异常,还是千年一遇的洪水是异常?
对于各种监督学习,我们往往缺乏异常点的标记,而对于非监督学习,调整各种参数会对异常点的判断有很大的影响。
对于基于自编码器的方法而言,我们看到,我们利用利用自编码器的输出和输入的差异来判断该事件是否为异常事件,然而究竟偏离多少来定义为异常,仍然需要用户来指定。
我们希望的完全通过数据和算法来自动发现异常仍然是一个比较困难的问题。
参考