一、hashMap并发中存在的问题
在我们开发程序过程中,hashMap算是我们最常用的数据结构了,那么如果我们在高并发下使用hashMap可能会出现什么问题呢?
1、拿到的结果不是我们想要的。(非线程安全)
2、扩容而导致程序死循环。致使CPU100%;(JDK1.7版本扩容,1.8暂无此问题。严重)
为什么会出现死循环,接下来我们进行分析一下。首先我们了解下hashMap的源码,以及put操作。
1.1 1.7HashMap源码简析
1.1.1 构造函数解析
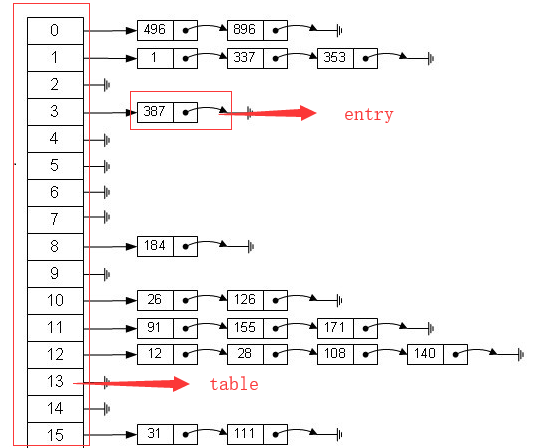
hashMap代价都比较熟悉了,这里就简单介绍HashMap几个关键点。HashMap的数据结构就是数组+链表的数据结构,如下
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
当实例化一个HashMap时,系统会创建一个长度为Capacity的Entry数组,这个长度被称为容量(Capacity),在这个数组中可以存放元素的位置我们称之为“桶”(bucket),每个bucket都有自己的索引,系统可以根据索引快速的查找bucket中的元素。 每个bucket中存储一个元素,即一个Entry对象,但每一个Entry对象可以带一个引用变量,用于指向下一个元素,因此,在一个桶中,就有可能生成一个Entry链。 Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
在存储一对值时(Key—->Value对),实际上是存储在一个Entry的对象e中,程序通过key计算出Entry对象的存储位置。换句话说,Key—->Value的对应关系是通过key—-Entry—-value这个过程实现的,所以就有我们表面上知道的key存在哪里,value就存在哪里。
![]()
构造函数里的参数值
//默认初始化化容量,即16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//最大容量,即2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认装载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//HashMap内部的存储结构是一个数组,此处数组为空,即没有初始化之前的状态
static final Entry<?,?>[] EMPTY_TABLE = {};
//空的存储实体
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
//实际存储的key-value键值对的个数
transient int size;
//阈值,当table == {}时,该值为初始容量(初始容量默认为16);当table被填充了,也就是为table分配内存空间后,threshold一般为 capacity*loadFactory。HashMap在进行扩容时需要参考threshold
int threshold;
//负载因子,代表了table的填充度有多少,默认是0.75,当超过容量*负载因子时会进行扩容
final float loadFactor;
//用于快速失败,由于HashMap非线程安全,在对HashMap进行迭代时,如果期间其他线程的参与导致HashMap的结构发生变化了(比如put,remove等操作),需要抛出异常ConcurrentModificationException
transient int modCount;
1.2.2 put源码分析
1、当我们将一个元素放入hashMap中,首先判断map是否为空,如果是空,对数组进行填充
2、如果Key为null,则将值存储在table[0]的位置或table[0]的链表冲突连上
3、对key值再进行hash散列,使其散列均匀,然后通过indexFor进行确定table的位置,该方法为h & (length-1);就是拿当前hash的值如table长度-1做与运算,其实本质等于hash值除table长度取余。
4、然后循环遍历链表,查看链表里的key是否存在,存在的话替换旧值。然后return 老的值
5、如果不存在,则在尾部添加新的entry节点。
public V put(K key, V value) {
//如果table数组为空数组{},进行数据填充
if (table == EMPTY_TABLE) {
inflateTable(threshold);//分配数组空间
}
//如果key为null,存储位置为table[0]或table[0]的冲突链上
if (key == null)
return putForNullKey(value);
int hash = hash(key);//对key的hashcode进一步hash计算,确保散列均匀
int i = indexFor(hash, table.length);//获取在table中的实际位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);//调用value的回调函数,其实这个函数也为空实现
return oldValue;
}
}
modCount++;//保证并发访问时,若HashMap内部结构发生变化,快速响应失败
addEntry(hash, key, value, i);//新增一个entry
return null;
}
1.2.3 addEntry节点方法以及扩容
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//当size超过临界阈值threshold,并且即将发生哈希冲突时进行扩容,新容量为旧容量的2倍
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);//扩容后重新计算插入的位置下标
}
//把元素放入HashMap的桶的对应位置
createEntry(hash, key, value, bucketIndex);
}
//创建元素
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex]; //获取待插入位置元素
table[bucketIndex] = new Entry<>(hash, key, value, e);//这里执行链接操作,使得新插入的元素指向原有元素。
//这保证了新插入的元素总是在链表的头
size++;//元素个数+1
}
1、当我们对要插入的元素定好位置之后,则需要对当前链表进行判断是否需要扩容
2、当前table数组长度大于threashold(表默认长度*负载因子)的时候,则需要对数组进行扩容,扩容方式为当前的数组长度的两倍
3、当数组扩容完毕,需要重新计算所有的元素的位置,然后插入对应的位置当中。扩容方法主要为resize以及resize中的transfer方法,不在细说
如图
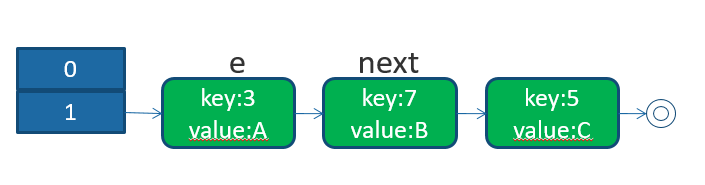
扩容前,3,7,5对数组长度2取摩都是值1,所以都是在1的位置.
![]()
扩容后数组table长度为4,7,3取摩后为位置为3,5取摩为位置为1
![]()
4、最后执行createEntry方法,将生成的节点插入对应位置的头部。
1.3、HashMap死循环分析
了解了hashMap中put以及扩容操作之后,我们模拟一个场景。有原hashMap如下
![]()
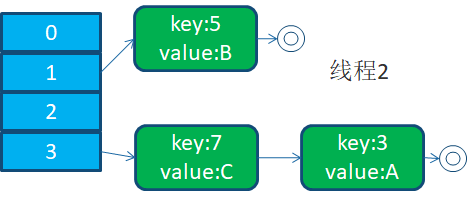
在多线程环境下有线程一和线程二,同时对该map进行扩容执行扩容。
![]()
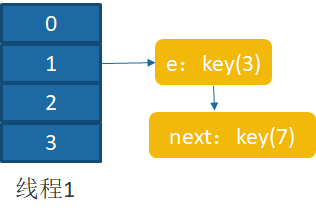
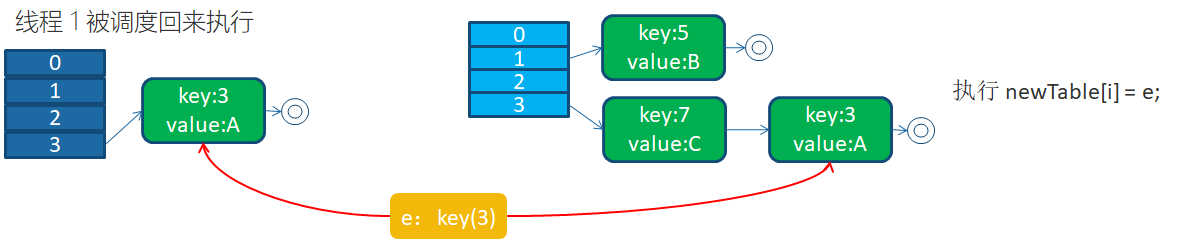
当线程一执行到如下代码时被挂起
![]()
此时线程1的数据结构为,table已经扩容完毕,重新计算每个元素位置时被挂起,此时key为3的还在1位置,3.next为7。
![]()
这时,线程2完成扩容,扩容后的数据结构为
![]()
当线程1被调度回来执行之后,因为线程一执行的e.next =newTable[i];将key3插入到3号位置,同时3.next=key7。此时e=key3,next=key7;
![]()
![]()
当执行到e=next的时候,e=key7,next=key7;
然后开始下一轮while。但此时因为线程二已经将key=7的next设置为key3(问题就在这里,线程二执行的时候,key7.next已经是null了,但这里线程一去执行的时候key7.next却是key3)。所以当第二轮循环开始,执行next=e.next后,next = key3。
![]()
之后通过头插法,将key7插入key3之前。在执行完next=e.next 之后,e=key3,next=key3;
![]()
然后开始第三轮循环。e和next都是key3。所以根据头插法。key3又要插入key7之前,这就导致了key3.next为key7,key7.next为key3
![]()
所以当我们去get值得时候,当定位到3的时候,就会产生死循环。导致永远拿不到数据。
总结
HashMap之所以在并发下的扩容造成死循环,是因为,多个线程并发进行时,因为一个线程先期完成了扩容,将原Map的链表重新散列到自己的表中,并且链表变成了倒序,后一个线程再扩容时,又进行自己的散列,再次将倒序链表变为正序链表。于是形成了一个环形链表,当get表中不存在的元素时,造成死循环。在1.8当中,链表扩容转为红黑树,没有相关的问题。
其他阅读 并发编程专题,大家有问题可以加我微信哈~
![481021518c4b8fa00ba60ef9609c53b2b5f.jpg]()