![]()
作者 | FesianXu
导读
4年前在《AutoDiff理解》 之第一篇“自动求导技术在深度学习中的应用”[1]中打算写一个关于autodiff的系列文章,因为工作和学习上比较忙碌(Lan Duo :P),就一直拖到了现在。刚好最近又在学习OPEN MLSYS[2],借此机会将静态图中的autodiff笔记也一并写完吧。如有谬误请联系指出。
(注意,在阅读本文之前,请确保已经阅读过[1],了解为什么深度学习以自动求导作为主要的训练方式,会对理解本文有所帮助。)
全文8965字,预计阅读时间23分钟。
01 静态图与动态图的区别
之前在[1]中提到过,自动求导(AutoDiff)机制是当前深度学习模型训练采用的主要方法,而在静态图和动态图中对于自动求导的处理是不一样的。作为前置知识,这里简单进行介绍。
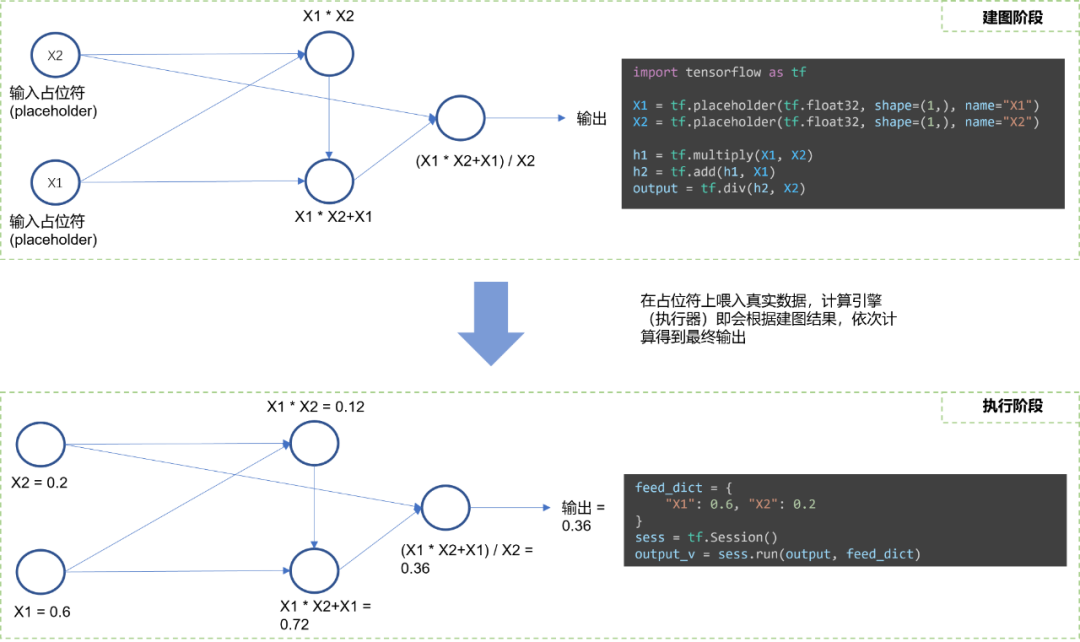
我们都知道静态图建模(如TensorFlow,paddle fluid)是声明式编程,其建图过程和计算过程是分开的,而对于动态图建模而言(如pytorch,paddle)是命令式编程,其计算伴随着建图一起进行。注意,这两种编程范式有着根本上的区别,相信用过tensorflow和pytorch的小伙伴能感受得到。总的来说,动态图边建图边计算的方式容易理解,而静态图先建图,后计算的方式并不是很容易理解,我们完全可以把静态图语言(比如TensorFlow,Paddle)看成是独立于python之外的建图的一种描述语言,其任务主要是建计算图,而其计算部分完全由其C++后端进行计算。静态图的建图和计算独立的过程和示意代码,可以用Fig 1.1进行
![图片]()
△Fig 1.1 静态图建图和计算的过程示意
注意到,动态图边建图边计算,也即是每一次的模型训练都会进行重新建图和计算,这意味着:
1、系统无法感知整个动态图模型的全局信息。有些变量可能后续不会再被引用了,可以释放内存,在动态图系统中由于无法感知到后续图的结构,因此就必须保留下来(除非工程师手动释放),导致显存占用一般会大于静态图(当然也并不一定)。
2、每次都需要重新建图,在计算效率上不如静态图,静态图是一次建图,后续永远都是在这个建图结果的基础上进行计算的。这个就类似于解释性语言(如python)和编译性语言(如C和C++)的区别。
3、由于动态图需要每次重新建图,导致其无法在嵌入式设备上进行部署(两种原因,1是效率问题,2是嵌入式设备通常不具有网站的建图运行时,只支持推理模式),通常需要其以某种形式(比如ONNX)转化为静态图的参数后,通过静态图部署。常见的部署方式包括TensorRT,Paddle Lite,TensorFlow Lite,TensorFlow Serving,NCNN(手机端居多)等等。
02 自动求导 AutoDiff
2.1 动态图
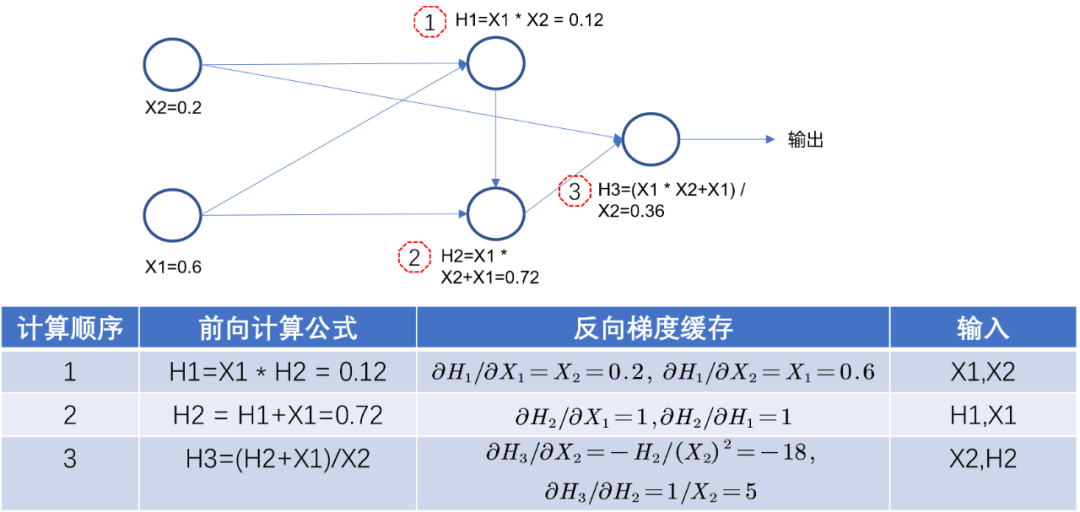
动态图是完全的边建图边计算,注意到是完全,完全,完全!重要的事情说三遍,这意味着在动态图里面的自动求导过程也是边建图边计算完成了。如Fig 2.1所示,在进行前向计算的过程中,除了对前向计算结果进行保存外(简称为前向计算缓存,forward cache),还会同时进行当前可计算的反向梯度的计算(简称为反向计算缓存,backward cache),并且将反向梯度的计算结果同样保存下来。在需要进行端到端的梯度计算的时候,比如调用了pytorch的output.backward(),此时会分析输出节点output和每个叶子节点的拓扑关系,进行反向链式求导。此时其实每一步的梯度都已经求出来了,只需要拼在一起,形成一个链路即可。将早已计算得到的前向缓存和反向缓存结果代入拓扑中,得到最终每个叶子节点的梯度。如式子(2-1)和(2-2)所示。这就是动态图的前向和反向计算逻辑,在建图的同时完成前向计算和反向计算。这种机制使得模型的在线调试变得容易(对比静态图而言),我们待会将会看到静态图是多么的“反人类”(对比动态图而言)。
\(\begin{align} \dfrac{\partial H_3}{\partial X_1} &= \dfrac{\partial H_3}{\partial H_2} (\dfrac{\partial H_2}{\partial X_1}+\dfrac{\partial H_2}{\partial H_1} \dfrac{\partial H_1}{\partial X_1}) \ &= 5(1+1*0.2) = 6 \end{align} \tag{2-1}\)
\(\begin{align} \dfrac{\partial H_3}{\partial X_2} &= \dfrac{\partial H_3}{\partial X_2} + \dfrac{\partial H_3}{\partial H_2} (\dfrac{\partial H_2}{\partial H_1} \dfrac{\partial H_1}{\partial X_2}) \ &= -18 + 510.6 = -15 \end{align} \tag{2-2}\)
![图片]()
△Fig 2.1 动态图的前向和反向计算过程是在建图的时候一起完成的_
不难发现,在进行反向传播的时候整个系统需要缓存,维护多种类型的变量,包括前向计算的结果缓存,反向梯度的缓存,参数矩阵等等。这些都是模型训练过程中占据显存使用的大头。
2.2 静态图
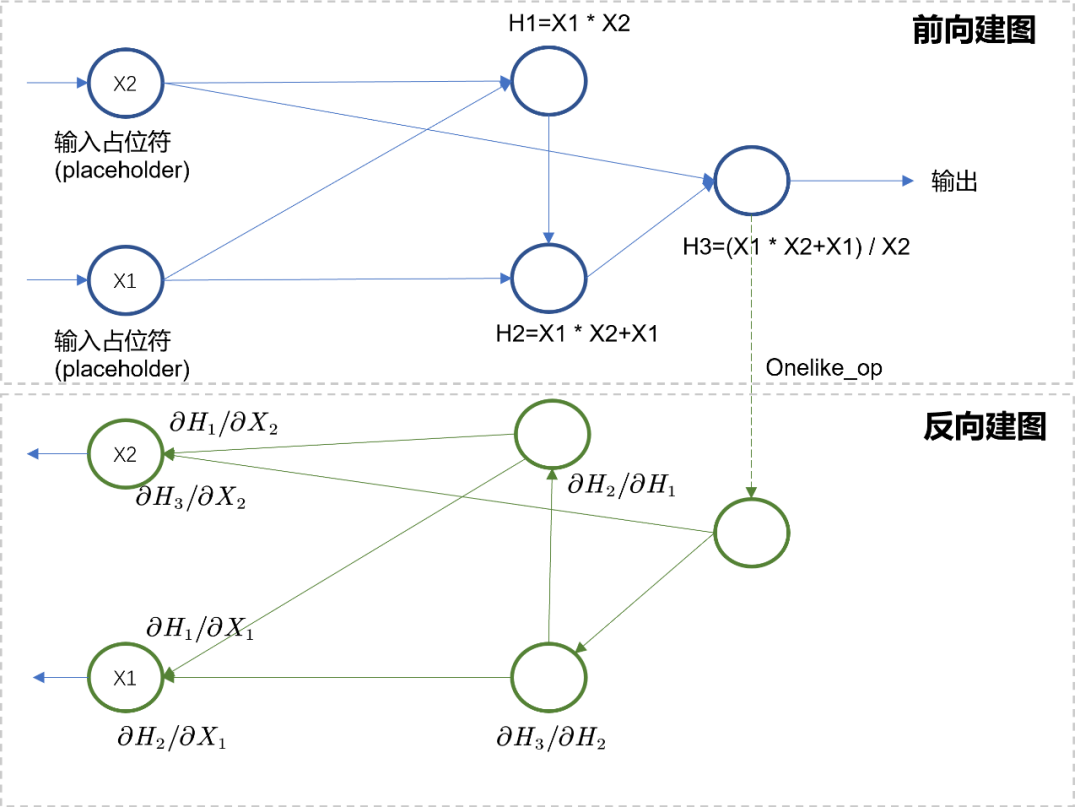
对于静态图而言,建图是一次性完成的,计算可以在这个建好的计算图上反复进行。如Fig 3.2所示,静态图在建图阶段同时将前向计算图和反向计算图都一并建好了(除非指定了在推理模型,此时没有反向建图的过程),当placeholder输入真实的Tensor数据时(也就是feed_list),在指定了输出节点的情况下(也就是fetch_list),执行器会解析整个计算图,得到每个节点的计算顺序,并对Tensor进行相对应的处理。如以下代码所示,通过tf.gradients(Y, X)可以显式拿到梯度节点,在执行器运行过程中sess.run(),只需要指定需要的输出节点(比如是前向输出output或者是梯度输出grad)和喂入数据feed_list,即可在计算图上计算得到结果。
import tensorflow as tf
X1 = tf.placeholder(tf.float32, shape=(1,), name="X1")
X2 = tf.placeholder(tf.float32, shape=(1,), name="X2")
h1 = tf.multiply(X1, X2)
h2 = tf.add(h1, X1)
output = tf.div(h2, X2)
grad = tf.gradients(output, [X1, X2])
feed_dict = {
"X1": 0.6, "X2": 0.2
}
sess = tf.Session()
output_v = sess.run(output, feed_dict)
grad_v = sess.run(grad, feed_dict)
![图片]()
△Fig 3.2 静态图的正向建图和反向建图都在建图阶段一并完成了
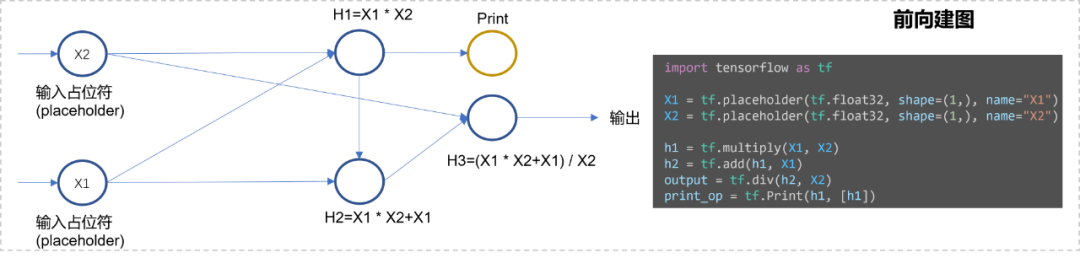
由此我们发现了静态图和动态图自动求导机制的不同点,静态图在执行计算过程中,其实并不区分前向计算和反向计算。对于执行器而言,无论是前向过程建的图,亦或是反向过程建的图都是等价的,执行器不需要区分,因此只需要一套执行器即可,将自动求导机制的实现嵌入到了建图过程中。而由于动态图的建图和计算同时进行,导致其执行器也必须区分前向和反向的过程。从静态图的实现机制上看,我们也不难发现,由于静态图提前已经对整个计算图的拓扑结构有所感知,就能对其中不合理的内存使用进行优化,并且可以对节点进行融合优化,也可以静态分析得到更合理的节点执行顺序,从而实现更大的并行度。静态图的这些性质决定了其更适合于模型部署,计算效率和内存使用效率都比动态图更高。但是静态图也有一个最大麻烦,就是模型调试麻烦。首先由于对整个图都建好了后才能执行,因此并不能动态往里面添加原生python的print操作——此时Tensor都还没计算出来呢,你打印出来的只是该计算节点本身而已,并没有输入任何数值信息。为了print其中的节点以进行模型调试,可以往里面插入TensorFlow的tf.Print操作节点,如Fig 3.3所示。当然,你也可以单纯在执行器运行时,通过指定fetch_list=[h2]进行中间变量的获取。但是不管是哪种方法,都显然比动态图的调试更为麻烦。
![图片]()
△Fig 3.3 在计算图中插入Print节点,以进行模型调试
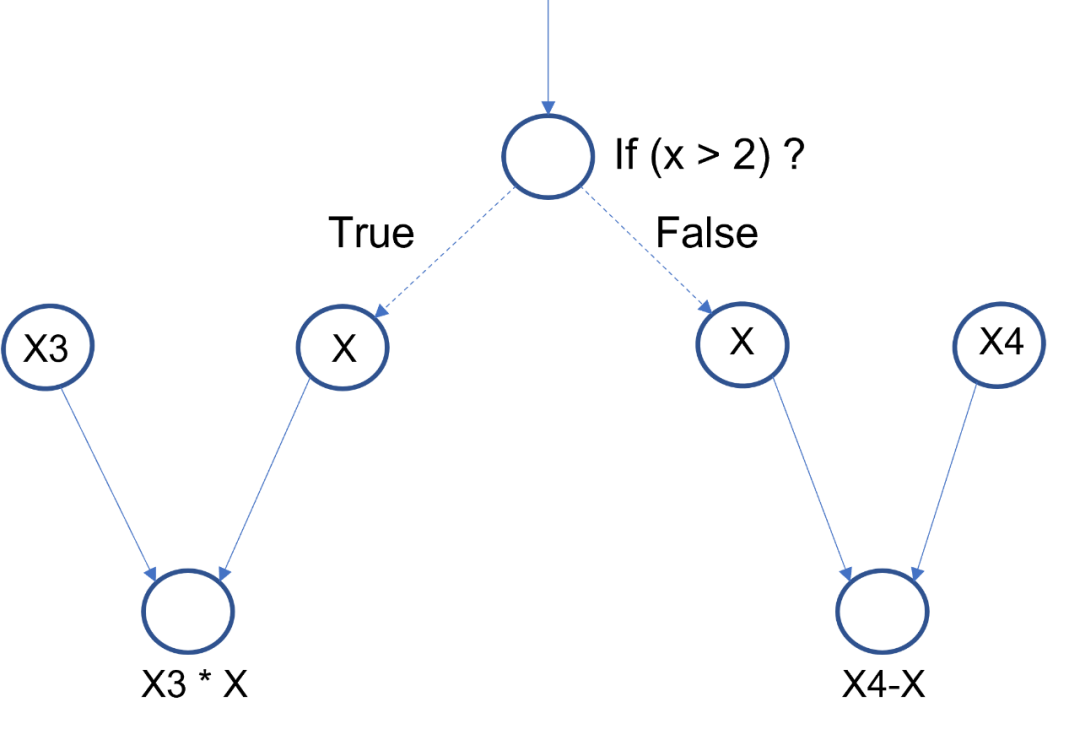
静态图对于数据流控制的操作,也远比动态图麻烦。以条件判断为例子,在动态图中只需要实时计算判断条件,实时建图计算即可,一切都是那么地顺滑。但是静态图是必须得提前建图的,这意味着无法实时进行分支判断,因此所有可能的分支都需要进行建图,如Fig 3.4所示,实现了以下的条件判断逻辑。
if (X > 2) {
return X * X3
} else {
return X4 - X
}
![图片]()
△Fig 3.4 静态图中对于所有可能的条件判断分支,都需要提前建图
03 静态图自动求导的实现示例
3.1 前向建图和反向建图
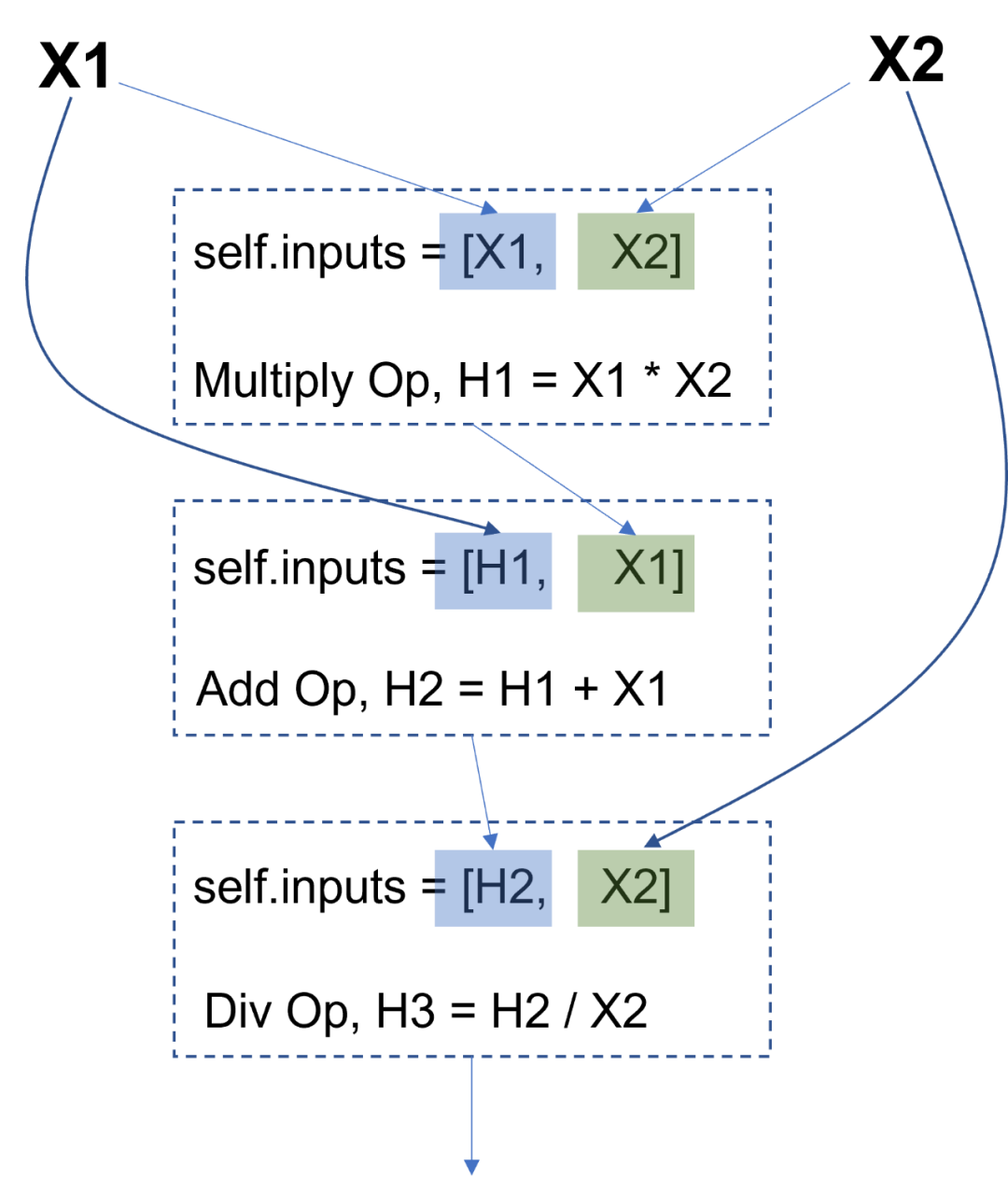
以上讲了那么多动态图和静态图的差别,看似有些跑题了,我们说好的自动求导实现呢?嗯嗯,本章在读者对静态图和动态图有了充分的认知之后,将会讨论如何实现静态图的自动求导机制。笔者已经将代码开源_( https://github.com/FesianXu/ToyAutoDiff )_,有兴趣的读者可以自行尝试。在这个代码库中,主要有两种数据结构类,Node和Op。Node是节点类,如下所示,其主要定义了输入列表self.inputs,这个输入列表用于储存当前节点的所有输入信息,而其本身则是作为输出存在,通过这种方式可以建立一个前向图,如Fig 3.5所示,通过维护Node类中的inputs列表,就足以维护前向图的拓扑关系,其是一个有向无环图(Directed Acyclic Cycle, DAG)。同时,Node类中还具有一个const_attr用于描述Tensor与常数的一些操作,如果想要引入类型推断系统,那么还需要加入self.shape,但是本文中并没有引入这个机制。
class Node(object):
def __init__(self):
self.inputs = []
self.op = None
self.const_attr = None
self.name = ""
def __add__(self, other):
if isinstance(other, Node):
new_node = add_op(self, other)
else:
new_node = add_byconst_op(self, other)
return new_node
def __mul__(self, other):
if isinstance(other, Node):
new_node = mul_op(self, other)
else:
new_node = mul_byconst_op(self, other)
return new_node
def __truediv__(self, other):
raise ValueError('No implement div')
# Allow left-hand-side add and multiply.
__radd__ = __add__
__rmul__ = __mul__
def __str__(self):
return self.name
__repr__ = __str__
![图片]()
△Fig 3.5 通过组织Node里面的inputs列表,既可以维护一个前向图关系的描述
通过实现一个抽象类Op,我们把所有算子的基类需要的共有接口给定义了,第一个是计算方法(Compute),注意到该操作并不区分前向或者反向,在执行器调用这个compute的时候,只是对输入的实际Tensor进行指定计算而已,因此这个方法其实就是在图计算中实现惰性计算(Lazy Compute)的实际计算方法。第二个是反向建图方法(gradient),该方法对当前输入节点和输出节点(也即是自身)进行反向求导建图。同时注意到在__call__方法中,Op将输出节点new_node = Node()进行定义,并且将其纳入自己类中new_node.op = self。
class Op(object):
def __call__(self):
new_node = Node()
new_node.op = self
return new_node
def compute(self, node, input_vals):
raise NotImplementedError
def gradient(self, node, output_grad):
raise NotImplementedError
该Op类是一个抽象类,需要集成它实现其他具体的算子,比如矩阵乘法算子MatMulOp。该矩阵乘法算子的输入是两个Op,分别是node_A和node_B。其在compute方法中,传入的Tensor是基于numpy array的,因此直接采用np.dot()进行计算即可,当然也可以加入类型断言,形状断言用以判断传入的Tensor符合计算图的要求。在gradient方法中,我们知道对于矩阵乘法而言,其微分如(3-1)所示,将每个输入节点的对应微分写到gradient中,此时的\(\partial \mathbf{Y}\)就是前继节点的求导累积结果,在代码中记为output_grad。
\(\begin{align} \mathbf{Y} &= \mathbf{A} \mathbf{B} \ \partial \mathbf{A} &= \partial \mathbf{Y} \cdot \mathbf{B}^{\mathrm{T}} \ \partial \mathbf{B} &= \mathbf{A}^{\mathrm{T}} \cdot \partial \mathbf{Y} \end{align} \tag{3-1}\)
class MatMulOp(Op):
"""Op to matrix multiply two nodes."""
def __call__(self, node_A, node_B, trans_A=False, trans_B=False):
new_node = Op.__call__(self)
new_node.matmul_attr_trans_A = trans_A
new_node.matmul_attr_trans_B = trans_B
new_node.inputs = [node_A, node_B]
new_node.name = "MatMul(%s,%s,%s,%s)" % (node_A.name, node_B.name, str(trans_A), str(trans_B))
return new_node
def compute(self, node, input_vals):
assert len(input_vals) == 2
assert type(input_vals[0]) == np.ndarray and type(input_vals[1]) == np.ndarray
return np.dot(input_vals[0], input_vals[1])
def gradient(self, node, output_grad):
"""
if Y=AB, then dA=dY B^T, dB=A^T dY
"""
return [matmul_op(output_grad, transpose_op(node.inputs[1])), matmul_op(transpose_op(node.inputs[0]), output_grad)]
通过类似的方法还可以实现其他很多算子操作,比如加减乘除等等。前向建图很容易完成,我们讨论下如何进行反向建图。在该试验代码中,实现了一个gradients函数,如下所示,该函数对输出节点output_node和指定的节点列表(node_list)中的每个节点进行求导操作。在实现这个的过程中,我们调用了一个叫做find_topo_sort的函数,对以这个输出节点output_node为起始点进行深度优先搜寻(Depth First Search),然后进行逆序就得到了反拓扑结构。还是以Fig 3.2的拓扑结构为例子,对其输出H3进行DFS,得到的拓扑序为X2 -> X1 -> H1 -> H2 -> H3,进行翻转后得到H3 -> H2 -> H1 -> X1 -> X2。我们发现翻转后的序,和Fig 3.2的反向建图的序是一致的。因此以此为序,遍历的过程中不断地调用当前遍历节点的op.gradient方法,实现层次反向建图。
def gradients(output_node, node_list):
"""Take gradient of output node with respect to each node in node_list.
Parameters
----------
output_node: output node that we are taking derivative of.
node_list: list of nodes that we are taking derivative wrt.
Returns
-------
A list of gradient values, one for each node in node_list respectively.
Something wrong, should be the backward graph of the gradients
"""
node_to_output_grads_list = {}
node_to_output_grads_list[output_node] = [oneslike_op(output_node)]
reverse_topo_order = reversed(find_topo_sort([output_node]))
for ind, each in enumerate(reverse_topo_order):
if ind == 0:
gg = each.op.gradient(each, oneslike_op(output_node))
else:
gg = each.op.gradient(each, node_to_output_grads_list[each])
if gg is None:
continue
for indv, eachv in enumerate(gg):
if each.inputs[indv] in node_to_output_grads_list.keys():
node_to_output_grads_list[each.inputs[indv]] += gg[indv]
else:
node_to_output_grads_list[each.inputs[indv]] = gg[indv]
node_to_output_grad[each] = each
grad_node_list = [node_to_output_grads_list[node] for node in node_list]
return grad_node_list
def find_topo_sort(node_list):
"""Given a list of nodes, return a topological sort list of nodes ending in them.
A simple algorithm is to do a post-order DFS traversal on the given nodes,
going backwards based on input edges. Since a node is added to the ordering
after all its predecessors are traversed due to post-order DFS, we get a topological
sort.
"""
visited = set()
topo_order = []
for node in node_list:
topo_sort_dfs(node, visited, topo_order)
return topo_order
def topo_sort_dfs(node, visited, topo_order):
"""Post-order DFS"""
if node in visited:
return
visited.add(node)
for n in node.inputs:
topo_sort_dfs(n, visited, topo_order)
topo_order.append(node)
建图完后我们就需要进行计算了,而计算是有执行器(Executor)进行的。执行器中最主要的方法是run,这个相当于TensorFlow中的sess.run(),不同的在于,这里的执行器是在构造器中指定fetch_list,在run()中指定喂入的Tensor数据。在run方法中,我们同样需要采用DFS对计算图进行遍历(不区分前向还是反向,再强调一遍),得到了计算序后,依次喂入tensor数据,调用op.compute()进行tensor计算即可。
class Executor:
"""Executor computes values for a given subset of nodes in a computation graph."""
def __init__(self, eval_node_list):
self.eval_node_list = eval_node_list
def run(self, feed_dict):
node_to_val_map = dict(feed_dict)
# Traverse graph in topological sort order and compute values for all nodes.
topo_order = find_topo_sort(self.eval_node_list)
for each in topo_order:
if each.inputs:
input_vals = []
for each_input in each.inputs:
input_vals += [node_to_val_map[each_input]]
node_to_val_map[each] = each.op.compute(node=each, input_vals=input_vals)
node_val_results = [node_to_val_map[node] for node in self.eval_node_list]
return node_val_results
至此,我们就实现了一个简单的静态图autodiff机制得到试验,后续可以加入形状推断机制,抽象出Layer神经网络层,参数初始化器Initiator,优化器Optimizer,损失Loss,模型层Model,那么我们就可以构建出一个玩具版本的TensorFlow啦,嘿嘿嘿~~
————END————
参考资料:
[1]. https://blog.csdn.net/LoseInVain/article/details/88557173, 《AutoDiff理解》 之第一篇, 自动求导技术在深度学习中的应用
[2]. https://openmlsys.github.io/chapter_preface/index.html, OPEN MLSYS
[3]. https://github.com/FesianXu/ToyAutoDiff
推荐阅读:
千万级高性能长连接Go服务架构实践
百度搜索Push个性化:新的突破
数据交付变革:研发到产运自助化的转型之路
百度搜索exgraph图执行引擎设计与实践
百度搜索&金融:构建高时效、高可用的分布式数据传输系统