1.首页推荐非内积召回现状
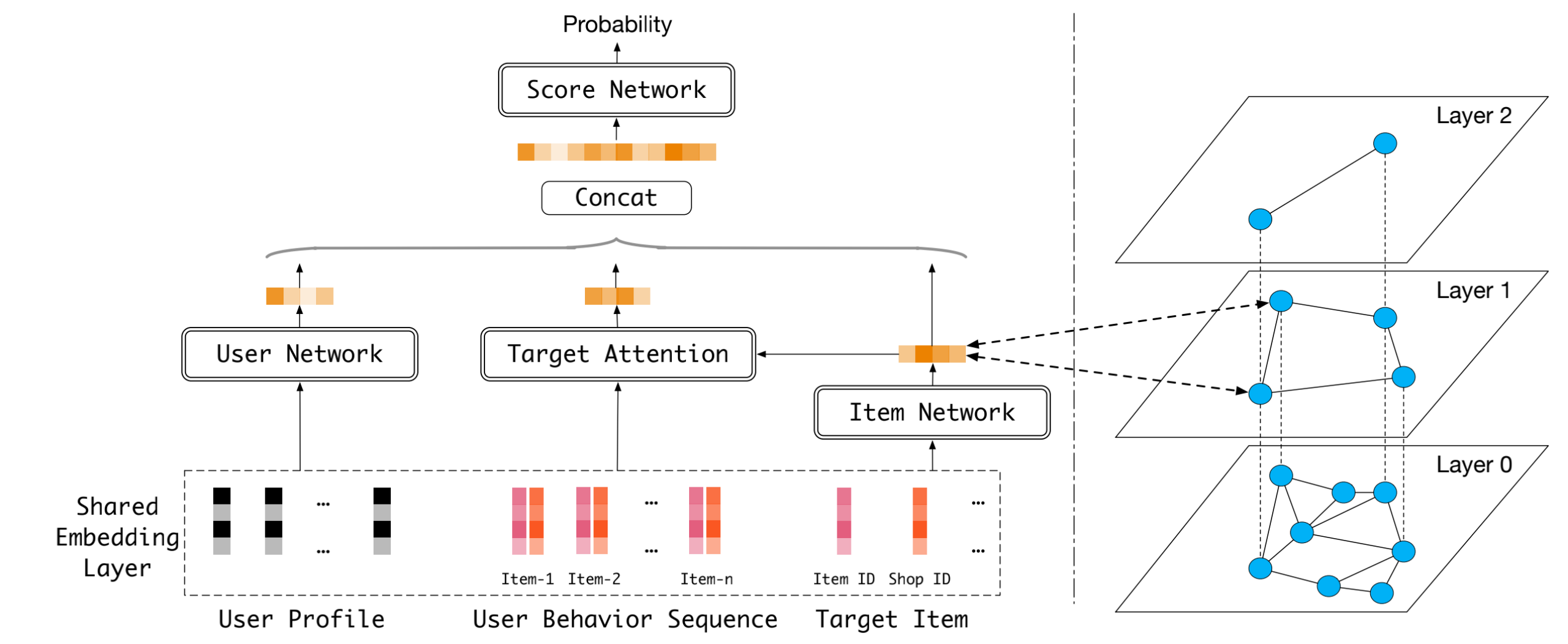
非内积召回源是目前首页推荐最重要的召回源之一。同时非内积相比于向量化召回最终仅将user和item匹配程度表征为embeding内积,非内积召回仅保留item embedding,不构造user显式表征,而是通过一个打分网络计算用户-商品匹配程度,极大的提升了模型精准度的上限,有很大优化空间。
• 模型:采用dot-product attention对用户行为和目标商品进行交互,结合用户画像、原始商品表征生成打分
• 索引与检索:
◦ 索引:离线模型训练完成后,对 item embedding 基于l2距离构造hnsw索引
◦ 检索:线上召回时,实时根据用户请求,在hnsw索引中逐层向下进行beam-search寻找最优结果
▪ 多样性保证:在最后一层检索过程中,进行类目维度多样性剪枝
• 样本
◦ 正样本:首页点击和订单作为正样本,
◦ 负样本:全站点击随机负采样 + 底池均匀负采样
• 特征:用户点击序列、用户画像特征、商品侧特征等
• 学习目标: 对正负样本采用sampled softmax loss建模为多分类问题
2.非内积召回优化-级联学习与负样本扩充
非内积召回模型整体有更好的拟合能力,但目前方案中原有训练样本相对较为简单,并且负样本量级较少,阻碍了非内积召回能力的发挥。为提升召回与后续链路一致性,现加入曝光未点击、精排top打分样本进行级联学习。学习目标从原有的点击正样本和随机负采样多分类问题从升级为包含点击、曝光未点击、精排序样本、随机负采样之间的精细化序关系融合;同时扩充负样本量级,提升模型打分精准性。
2.1 相关工作
2.1.1 级联学习相关工作
级联学习旨在引入多种推荐系统链路中样本,采用排序学习方式拟合真实系统分布。京东搜索多目标实践引入订单、点击、曝光样本之间的级联[1],有效提升大盘效果。list-MLE[2]是广泛应用的学习排序方法,将list内样本给出预测分数,优化预测分数分布和真实排序一致。plist_MLE[3]解决了连续多目标优化问题,使用线性标量化策略将其转换为一个单目标优化问题。
2.1.2 负样本扩充相关工作
batch内负样本扩充主要分为inbatch、crossbatch两种方式。CBNS[4]采用crossbatch,既维护一个队列,存储之前batch的embedding,在每次迭代后,把当前batch的embedding和采样概率存入队列中,并将最早的embedding出队,在计算sampled softmax的时候可以用到batch内的和队列中的负样本。SBC[5]采用inbatch方式,随机采样同一个batchsize中的样本作为负样本。MNS[6]在采样时,使用了混合负采样,应用多种采样生产负样本。
2.2 级联学习与负样本扩充优化点
加入曝光未点击、精排top打分样本进行级联学习;同时扩充负样本量级,提升模型打分精准性。
2.2.1 级联学习
• 样本优化:
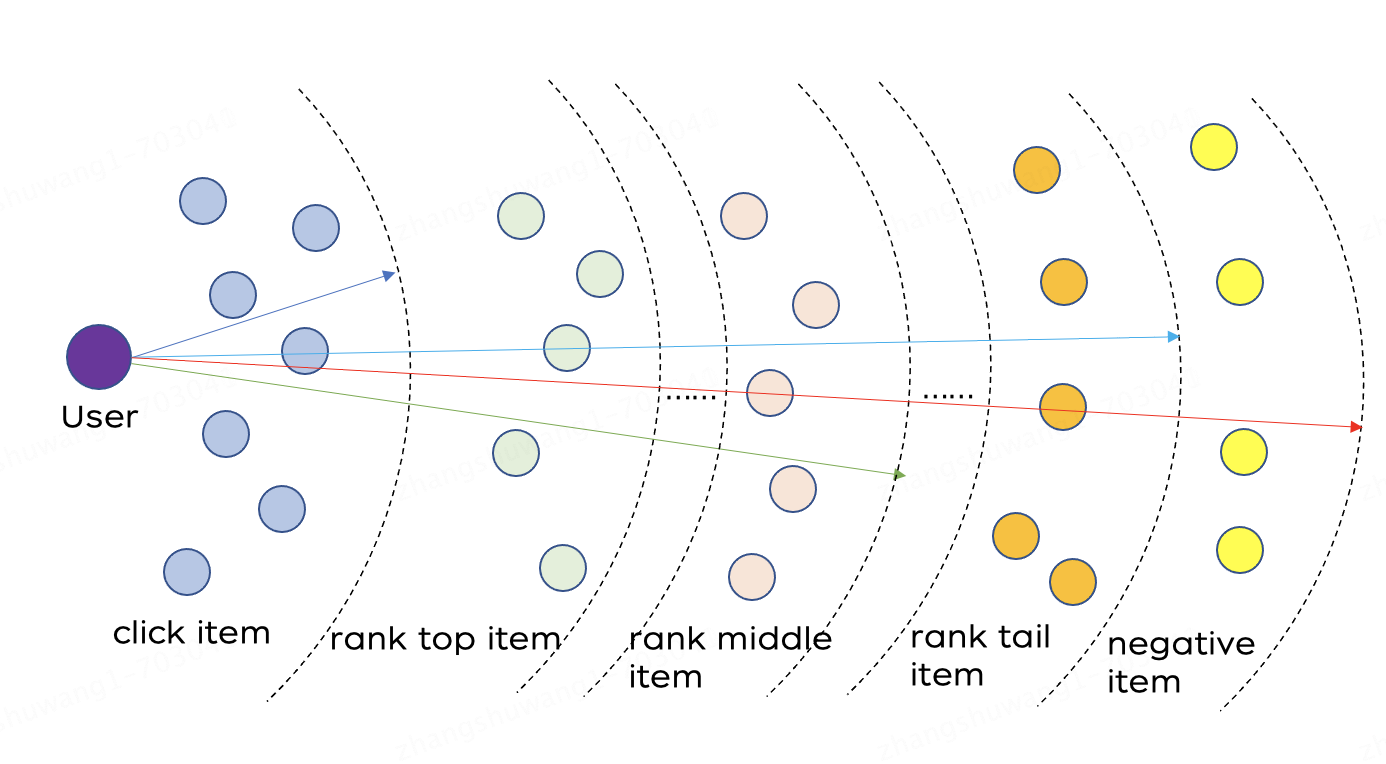
◦ 加入曝光未点击样本、精排序样本。点击正样本:曝光未点击=1:4;将每个正样本对应的请求精排序分段采样,分段为精排打分序1-10、11-50、51-100、101-200、201-400、401-900,每个分段采样4条。
• 学习目标优化:
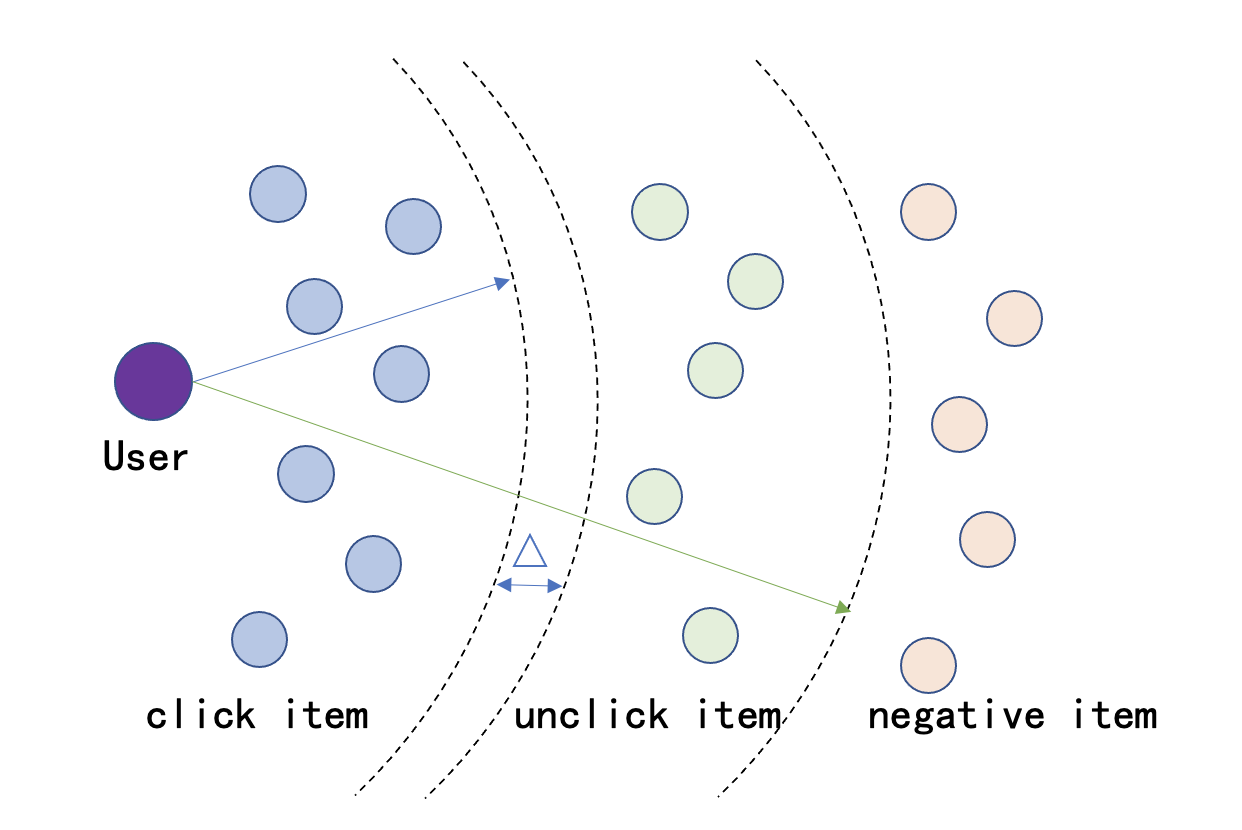
1. 原始学习目标: 正样本和负采样多分类问题
2. 升级后学习目标:点击正样本、曝光未点击、精排序样本、随机负采样之间的精细化序关系融合:
1. 点击正样本>曝光未点击>随机负采样
2. 点击正样本>精排序top>精排序middle>精排序tail>随机负采样
| 新增曝光未点击精细化学习 |
新增精排序关系精细化学习 |
|
参考工作:京东搜索多目标召回模型实践 [1] |
参考工作:Position-Aware ListMLE: A Sequential Learning Process for Ranking [3] |
|
|
2.2.2 负样本扩充
之前的非内积优化实验及参考工作[4,5,6]验证扩充负样本可提升模型精准性。模型训练过程中,随机采样同一个batch中的样本作为负样本[6]可大幅扩充负样本个数。
优化点:负样本个数由百级别扩充至千级别。
3.离线&线上实验
通过离线消融实验验证各优化点对模型打分精准性提升。
3.1 离线实验
| 实验 vs base |
点击hitrate@50 |
点击hitrate@100 |
点击hitrate@1200 |
订单hitrate@50 |
订单hitrate@100 |
订单hitrate@1200 |
| 消融实验-仅扩充负样本 |
+18.2% |
+27.1% |
+9.2% |
+9.1% |
+13.9% |
+1.1% |
| 扩充负样本+只加曝光未点击 |
+20.3% |
+30.0% |
+12.5% |
+16.8% |
+18.6% |
+18.2% |
| 扩充负样本+完整级联学习 |
+65.7% |
+56.6% |
+12.1% |
+67.3% |
+54.9% |
+26.7% |
离线实验结论:
1. 多组消融实验验证了加入曝光未点击、精排样本的完整级联学习引入能带来离线明显受益,尤其在订单维度。
3.2 线上实验
大盘指标:外页uctr +0.02%(0.8),引商点击 +0.53%, uctr含内页 +0.14%,外页ucvr+4.93%(0.00),含内页ucvr+4.17%(0.00),外页推荐用户转化率 +4.64%(0.00),含内页推荐用户转化率 +3.67%(0.00)
召回源指标:非内积召回线上召回源曝光相对+25%,ctr持平、cvr相对+4%
4.总结与思考
1. 精排top打分样本、曝光未点击样本引入+级联学习 可大幅提升离线hitrate指标,线上召回源曝光大幅增长(+25%),ctr持平、cvr显著提升。
2. 负样本扩充实验中,随着负样本扩充hitrate增长。后续将继续摸底负采样扩量上限。
5.参考文献
[1] 京东搜索多目标召回模型实践
[2] Listwise approach to learning to rank: theory and algorithm
[3] Position-Aware ListMLE: A Sequential Learning Process for Ranking
[4] Cross-Batch Negative Sampling for Training Two-Tower Recommenders
[5] Sampling-bias-corrected neural modeling for large corpus item recommendations
[6] Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations
作者:京东零售 张树旺
来源:京东云开发者社区 转载请注明来源