作者: 代城
万全网络高级工程师,负责万全网络数据平台整体架构研发工作,拥有超过 7 年的大数据相关技术研发经验,一直关注着开源和云技术的发展。
![]()
万全网络科技有限公司是一家专注于 B 端电商物流供应链的公司。致力于为客户提供全面的供应链解决方案,涵盖从产品采购到最终配送的全程服务。
公司的服务包括但不限于:供应链管理,仓储与配送,信息技术支持。
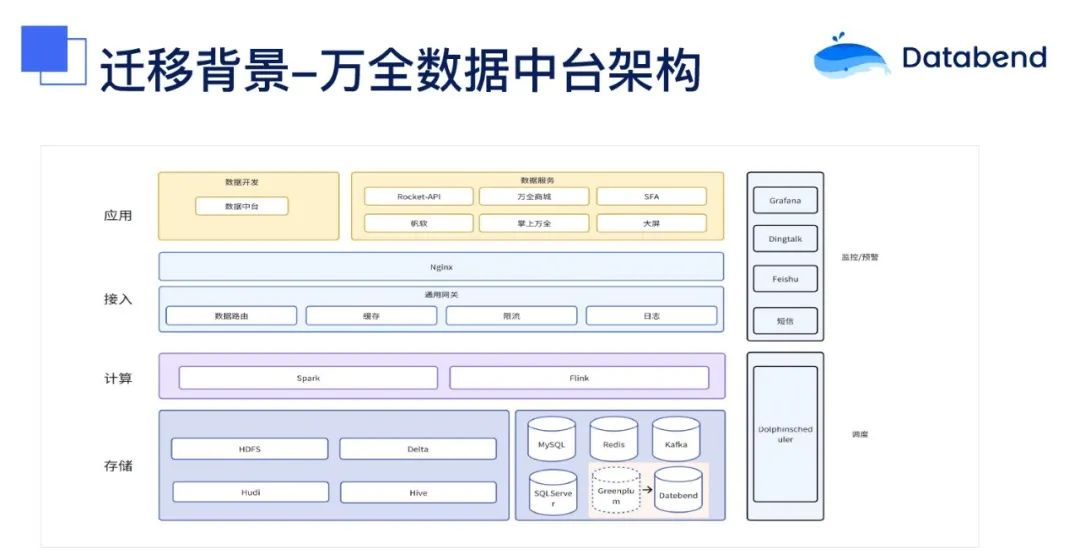
迁移背景
在不断发展的科技环境中,企业往往需要不断调整和优化其技术基础设施以适应变化的业务需求。
![]()
万全数据中台架构从 2020 年开始构建,历经 3 年多的时间打磨,已经实现了数仓开发的大部分基础功能,包括数据源管理、数据离线同步、数据实时同步、数据资源目录、数据开发、任务依赖管理以及数据服务接口。
此平台不仅支持数据的采集、清洗、加工,还涵盖了数据对外提供服务的完整链路。数据计算同步和计算引擎都是基于 Spark 构建的,确保了平台的稳定性和高效性。
在过去的几年中,它主要使用 Greenplum 作为大数据应用层数据库,该数据库主要用于支撑万全的业务线报表、大屏展示、帆软报表、SFA 运营报表等应用。然而,随着业务的不断发展和平台的逐步完善,我们发现 Greenplum 在一些方面已经不能满足我们的需求,因此决定进行数据库迁移,寻找更适合我们业务的解决方案。
Greenplum 使用中的挑战:
- 响应时间 延长:用户反馈高峰时期报表响应时间过长。
- 存储与性能局限:CRUD 操作限制我们选择行存储堆表,尽管其事务吞吐能力可与 MySQL 媲美,但在存储效率低、不适合 OLAP 场景、高 IO 开销等方面存在缺陷。
- 物化视图 导致的 IO 压力: 物化视图 1-5 分钟一次的高频刷新导致大量磁盘 IO 操作,使得服务器的 iowait 指标常年高达 60%,导致查询延迟。
- 资源分配挑战: 尽管通过资源队列减少了用户间资源竞争,但存算混部的特性限制了对磁盘资源的精确控制,导致整体性能提升有限。
- MVCC 机制的存储成本: 频繁更新的行由于 MVCC 机制而存储多个副本,增加存储空间需求,提高存储成本,影响查询性能。
为了保持数据库的查询性能稳定,需要定期运行维护任务,通常是根据更新频率间隔几个小时执行一次 VACUUM 操作,但是通常 VACUUM 只会对增量部分数据进行快照合并,无法完全释放表空间膨胀,还需要在每个月选择一天进行分批对表执行 full VACUUM 操作,以维持表查询性能稳定。
在当前硬件资源有限的条件下,即便是进行节点扩容,也并不会带来更多的收益,而且还需要对数据进行重新分布,从收益和成本上都不是最佳选择。
我们期望一个既有数据湖特性、又能够高效查询的数据库,而 Databend 刚好契合我们的需求。在这次迁移中,我们选择了 Databend 数据库,经过一系列的规划、准备、兼容性评估等工作,成功将我们的业务从 Greenplum 迁移到 Databend。这次迁移不仅减少了资源占用,提升了性能,也为我们未来的业务发展提供了更强大的支持。
规划和准备
原则
在迁移的起始阶段,我们制定了一系列核心原则,它们为我们的工作指明了方向。
首先,我们坚持“复用现有资源”的原则。通过最大化利用现有基础设施和资源,不仅降低了成本,还实现了现有数据与服务的有效整合。这种策略极大地提高了迁移过程中资源的效率利用。
其次,我们重点关注优化现有数据架构中的问题。深入分析了过去架构中的性能瓶颈和灵活性不足的问题,并针对性地进行优化。我们期望能够在新架构中实现更高的性能和更优的效果。
同时,降低维护成本成为我们的另一关键目标,这涵盖了服务维护和数据维护两个方面。通过优化架构设计并采用更高效的维护策略,我们旨在减轻运维负担,提升系统的稳定性和可维护性。
最后,我们特别强调架构的伸缩性,确保新系统能够轻松适应未来业务增长和数据规模的扩展。这意味着我们的系统设计具备优秀的扩展能力,能够灵活适应业务和技术需求的演变。
![]()
准备工作
一开始,我们对采用 Databend 持有谨慎的期待,抱着“试一试”的态度。但在经过实际测试和应用后,Databend 的表现远超预期,其性能并不逊色于传统的存算混合架构。这不仅证实了我们的选择的正确性,而且凸显了 Databend 在大数据存储领域的出色性能。
特别值得一提的是,Databend 的读写分离机制,这一机制与云原生概念紧密相连,同时符合当前数据湖发展的趋势。通过实现读写分离,我们成功提高了读取性能的同时降低了写入的压力。
在使用 Greenplum 时,尽管我们实施了资源分组和队列限制策略,但这些措施并未能有效解决资源争抢问题。为了更有效地应对此挑战,我们决定充分发挥 Databend 的多租户特性,将不同业务线的流量进行分割,确保每个业务线都能享有更优越的性能体验。此外,多租户机制还为我们提供了更为灵活的权限管理方式。
![]()
增效
将 Databend 数据库部署在 Kubernetes(k8s)上,采用云原生的部署方式。这一战略选择为我们的系统带来了显著优势,特别是在动态扩缩容方面。利用 Kubernetes 的高级特性,我们有效缓解了流量高峰期的压力,同时降低了系统维护成本。
在数据仓库开发方面,我们通过降低表间依赖,显著提高了数据维护的效率。此外,我们还实现了数据载入层的平滑迁移,优化了离线 T+1 数据的导入流程。值得注意的是,在实时数据处理上,我们从实时数据导入切换为微批次导入,虽然牺牲了部分时效性,但导入性能却得到了数倍的提升,极大地增强了开发团队的工作效率。
![]()
优化
在数据库迁移过程中,我们不仅迁移了数据库,还对原有数据架构进行了深入优化。一个关键的优化是解决了之前在Greenplum 中使用大量视图和物化视图构建准实时报表所带来的问题。
在 Greenplum 系统中,我们依赖视图和物化视图来构建准实时报表,这在表结构变化时导致了维护的复杂性和服务中断。而在 Databend 迁移后,我们利用其作为数据湖的能力,保存多个数据版本,采用 insert overwrite 方法配合调度平台,实现了数据的高可用性和稳定访问。这一策略不仅打破了物化视图间的依赖关系,还使我们能够灵活应对表结构变更,最小化对用户的影响。
这种优化策略极大提高了我们对外服务的稳定性和连续性,同时降低了维护的复杂性。新架构的灵活性使我们能够更有效地应对数据变更,进一步增强了系统的可维护性和可扩展性。
![]()
迁移过程
在当前快速发展的数据管理领域,有效的数据库迁移策略对保持技术先进性和业务竞争力至关重要。
在迁移的初期,我们明确了四项核心原则:复用现有资源、优化现有数据架构、降低维护成本,以及提升架构伸缩性。这些原则确保我们的迁移策略既高效又可控。
经过详细的需求分析和目标设定,我们对 Databend 进行了深入评估,包括性能测试和压力测试,以确保其适应性和稳定性。这一阶段的成功为我们后续的迁移提供了坚实的基础。
数据库架构优化
新一代云原生数仓 Databend 采用了存算分离的设计理念,提高了系统的灵活性、扩展性,并优化了多租户环境下的读写分离策略,大大提升了性能、安全性和稳定性。
迁移过程的集成与优化
在数据同步方面,我们采用了 Flink 和 Spark 处理引擎,以应对实时与离线数据同步的需求。我们优化了数据同步的流程和稳定性,并调整了任务调度策略,提高了数据同步的效率和稳定性。
查询优化和性能提升
我们重点优化了查询条件,采用了计算落地策略和 query cache 功能,以应对大量数据查询和数据倾斜问题。这些措施显著提升了查询性能和响应时间。
测试与回退策略
在测试阶段,我们采用了分流策略,重点关注性能回归排查和优化,确保系统的稳定性和可靠性。我们还制定了灵活的回退策略,以应对可能出现的系统性能问题。
迁移中的挑战与解决方案
在迁移过程中,我们面临并克服了多个技术挑战,包括系统表查询优化、查询节点内存问题、存储错误和 nginx 代理问题等。
迁移成果与指标
迁移完成后,我们在多个方面取得了显著成果:
- 查询性能: 提升显著,用户可以更快速地获取数据。
- 数据导入/导出速度: 显著提高,支持更高效的数据更新。
- 存储效率: 优化后的系统在存储资源利用上更加高效。
- 用户体验: 由于性能的提升,用户体验得到了显著改善。
- 成本效益: 维护时间成本降低,系统资源利用率提升。
![]()
总结和展望
在过去的 4 个月中,我们团队成功完成了整个业务系统的迁移工作,涵盖了 4 个业务线,共计近 500 张表和 600 个任务的迁移任务。
这次迁移不仅提升了技术,也加强了团队协作。我们计划继续优化系统,并保持对 Databend 新进展的关注,积极回馈社区。Databend 的卓越性能和稳定性在整个迁移过程中发挥了关键作用,为我们的业务发展提供了强有力的支持。
在成功完成业务系统的迁移之后,我们并没有止步于此,而是立志继续向前迈进,展望着更为辉煌的未来。
首先,我们计划逐步迁移数仓的 ODS 层,采用多集群方式进行部署。通过逐步迁移的方式,我们能够更好地掌握整个迁移过程,确保在迁移过程中系统的稳定性和可靠性。同时,使用多集群方式进行部署能够更好地分散资源,提高系统的整体性能和吞吐量。
其次,我们计划将 HDFS 存储进行独立部署,以减少资源竞争,进一步提升性能。通过独立部署存储,我们可以更灵活地调整存储资源的配置,以满足不同业务需求。这一举措有望进一步优化系统架构,提高数据存储和读取的效率。
我们还将持续跟进 Databend 版本的发布,以获取最新的功能和性能优化。通过不断学习和应用新的技术,我们可以更好地解锁 Databend 的更多使用技巧,从而更好地助力公司业务的发展。
致谢
感谢团队的辛勤工作和 Databend 社区的支持。数据库迁移是一项复杂而又重要的任务,我们通过逐步的规划、精心的准备和团队的共同努力,成功地将业务系统迁移到了新的数据库平台,实现了性能的提升、成本的控制以及更好的用户体验。
Databend 数据库不仅解决了我们许多的技术难题,而且在使用过程中展现出卓越的性能和稳定性。正是在 Databend的帮助下,我们成功地克服了诸多挑战,为业务提供了可靠的数据支持。
同时,我想借此机会表达对 Databend 社区的敬意。社区的力量是不可忽视的,正是有了这样一个充满活力和热情的社区,Databend 得以不断优化和升级。感谢每一位社区成员的付出。