一、前言 SQL是用于访问和处理数据库的标准计算机语言。GaussDB支持SQL标准(默认支持SQL2、SQL3和SQL4的主要特性)。
本系列将以《云数据库GaussDB—SQL参考》在线文档为主线进行介绍。
二、GaussDB数据库中的常量和变量的基本概述及语法定义 数据库中的变量和常量是两种重要的数据使用类型。变量是可以变化和被修改的,而常量则是固定不变,不能被修改的。
1、变量定义 在GaussDB中,变量是用于存储可变值的数据类型。变量通常在程序中定义,并在执行期间可以更改其值。在GaussDB中,可以使用以下语法来定义变量:
DECLARE variable_name data_type;
其中,variable_name 是变量的名称,data_type 是变量的数据类型。例如,要定义一个名为 my_variable 的整数变量,可以使用以下语句:
DECLARE my_variable INT;
2、常量定义 在GaussDB中,常量用于存储固定值的数据类型。常量在程序中定义后,其值不能被修改。在GaussDB中,可以使用以下语法来定义常量:
DECLARE constant_name data_type = constant_value;
其中,constant_name 是常量的名称,data_type 是常量的数据类型,constant_value 是常量的值。例如,要定义一个名为 my_constant 的整数常量,可以使用以下语句:
DECLARE my_constant INT = 10;
这将定义一个名为 my_constant 的整数常量,其值为 10。
请注意,这只是GaussDB中定义变量和常量的基本语法。具体建议参考GaussDB的官方文档或相关资料以获取更详细信息。
3、其他(%TYPE、%ROWTYPE属性) 变量类型除了支持基本类型,还可使用%TYPE和%ROWTYPE去声明一些与其他表字段或表结构本身相关的变量。
%TYPE属性:
%TYPE主要用于声明某个与其他变量类型(例如,表中某列的类型)相同的变量。假如我们想定义一个my_name变量,它的变量类型与employee的firstname类型相同,我们可以通过如下定义:
`--使用某列的属性声明
DECLARE my_name employee.firstname%TYPE
--使用其他变量的属性声明
DECLARE
name VARCHAR(10) NOT NULL := 'ZhangSan';
surname name%TYPE := 'LiSi';`
这样定义可以带来两个好处,首先,我们不用预先知道employee 表的firstname类型具体是什么。其次,即使之后firstname类型有了变化,我们也不需要再次修改my_name的类型。
%ROWTYPE属性:
%ROWTYPE属性主要用于对一组数据的类型声明,用于存储表中的一行数据,或从游标匹配的结果。假如,我们需要一组数据,该组数据的字段名称与字段类型都与employee表相同。我们可以通过如下定义:
--根据表employee表结构定义变量类型
DECLARE my_employee employee%ROWTYPE
三、在GaussDB数据库中如何使用变量&常量(示例) 变量&常量一般在数据库中不能直接应用到简单的SQL语句中,而是常常用于自定义的函数、存储过程中。下文简单举一列子(可参考前面FUNCTION/PROCEDURE等相关文章):
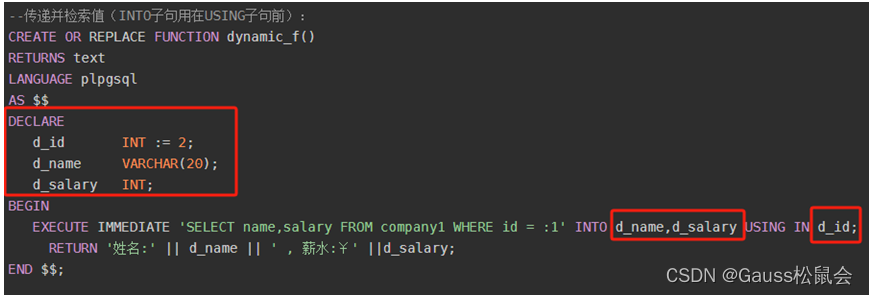
示例一,定义常量&变量(创建动态语句) ![]()
常量作为WHERE 条件之一;变量存储查询的结果值。
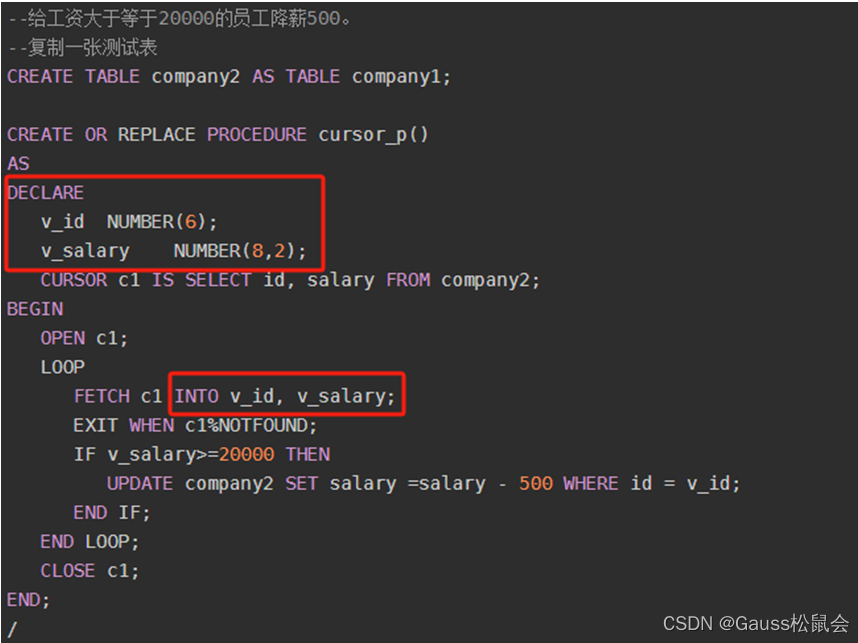
示例二,定义变量(创建游标) ![]()
定义变量,存储游标结果值
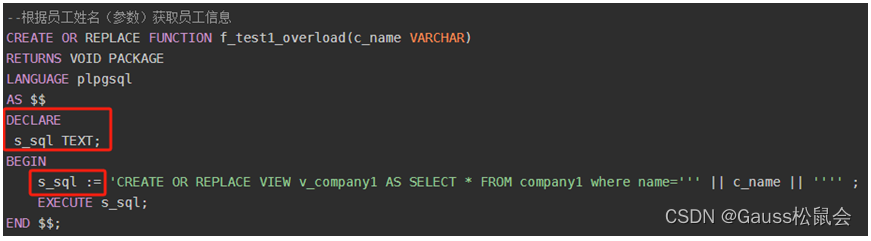
示例三,定义变量(创建package属性重载函数) ![]()
定义TEXT类型变量、赋值SQL语句
四、小结 在GaussDB数据库中,变量和常量是两种不同的数据存储方式。变量是用于存储可变值的数据类型,可以在程序执行期间更改其值。而常量则是用于存储固定值的数据类型,其值在定义后不能被修改。 在GaussDB中,可以使用DECLARE语句来定义变量和常量,并通过使用“:=”运算符来为它们赋值。正确地定义和使用变量和常量可以提高程序的灵活性和可维护性,并确保数据的准确性和完整性。
——结束