NebulaGraph 内核所自带的数据结构其实已经很丰富了,比如 List、Set、Map、Duration、DataSet 等等,但是我们平时在建表和数据写入的时候,可以用到的数据结构其实比较有限,复杂结构目前仅支持以下几种:
enum PropertyType {
UNKNOWN = 0,
... // 基础类型
TIMESTAMP = 21,
DURATION = 23,
DATE = 24,
DATETIME = 25,
TIME = 26,
GEOGRAPHY = 31,
} (cpp.enum_strict)
所以,有时候因为业务需求,我们需要能存入一些定制化的数据类型,比如机器学习中经常用到的 Embedding 的数据类型,工程上经常会有直接存储二进制数据 Binary 的需求,这就需要开发者自己去添加一个数据类型来满足自己的业务开发需求。
本文将手把手教你如何在 NebulaGraph 中增加一种数据类型,直到可以建表使用并插入对应数据以及查询。
下面我们以一个简单的二进制类型 Binary 的添加步骤来讲解整个流程。
1.命令设计
在实现新增 Binary 类型之前我们先想好要用怎么样的命令去使用这个类型,我们可以参考 NebulaGraph 已有的数据类型的使用
1.1 schema 创建命令
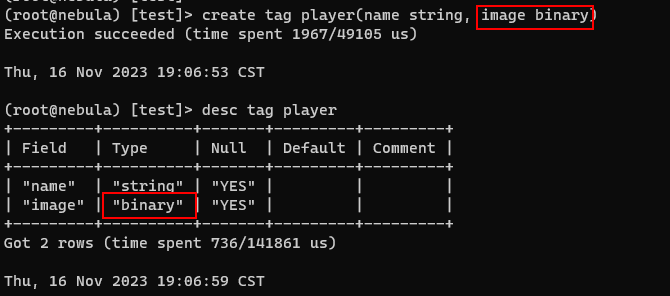
// 创建点表
create tag player(name string, image binary)
// 创建边表
create edge team(name string, logo binary)
上面我们设计新建 schema 时使用 binary 关键字来表示设置二进制类型的属性字段。
1.2 插入数据
这里有一个问题就是,命令只能以字符串形式传输,所以我们如果通过命令来插入二进制数据的话,就需要转码。这里我们以选用 Base64 编码为例。
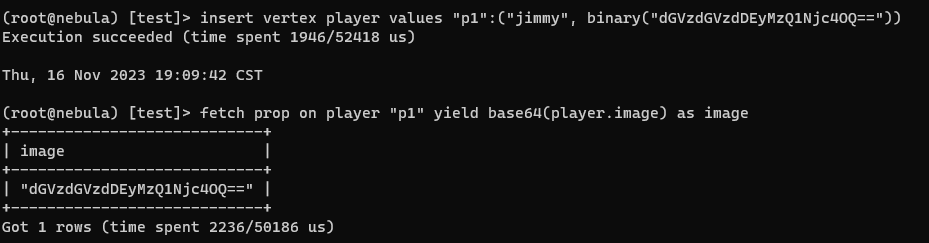
insert vertex player values "p1":("jimmy", binary("0s=W9d...."))
我们在插入命令里面同样以一个 binary 关键字来表示插入的是二进制数据的字符串而不是普通的字符串。
1.3 查询数据
其实正常的设计,或者现有的 NebulaGraph 代码上面来看,查询语句并不需要做改变,直接按照像读其他数据一样读取 Binary 字段就可以了,只是这里我们需要考虑一个问题,客户端没适配的话怎么办?像 nebula-console、nebula-java、nebula-cpp 这些客户端,我们暂时没法一一去适配新增的类型,所以为了测试的时候使用 nebula-console 能够正常读取到数据,我们需要提供转换函数,将新增的 Binary 类型转换为现有客户端能读取的数据格式。
fetch prop on player "p1" yield base64(player.image) as img_base64
这里我们定义了一个 base64() 的转换函数,将存储的二进制数据再以 Base64的格式输出。(兜兜转转回到原点了(:≡)
定义好命令之后,我们来看看怎么实现这些内容,首先我们需要实现这个 Binary 的数据结构。
2. 定义数据结构
在服务端 C++ 代码中,我们可以以一个 Bytes 数组来表示二进制的数据结构
struct Binary {
std::vector<std::byte> values;
Binary() = default;
Binary(const Binary &) = default;
Binary(Binary &&) noexcept = default;
explicit Binary(std::vector<std::byte> &&vals);
explicit Binary(const std::vector<std::byte> &l);
// 用于直接从命令行的字符串中解析出二进制
explicit Binary(const std::string &str);
... // 其他接口
};
一个简单的数据结构定义好之后,我们需要将这个结构添加到 Value 的 union 中
Value 这个数据结构在 Value.cpp 中定义,它是 nebula 中所有数据结构的一个基类表示,每个新增的数据结构想要和之前其他数据结构一起混用的话,需要在 Value.cpp 里面对各个接口做适配。
这个 Value 的数据结构里面有很多的接口定义,像赋值构造、符号重载、toString、toJson、hash 等接口,都需要去适配。
好在这不是什么难事,参考其他类型的实现就行。唯一要注意的是要细心!
2.1 定义 thrift 的数据结构
因为我们的数据结构还需要进行网络传输,所以我们还需要定义 thrift 文件里面的结构类型并实现序列化能力。
// 新增的数据类型
struct Binary {
1: list<byte> values;
} (cpp.type = "nebula::Binary")
// 在Value union中增加Binary类型
union Value {
1: NullType nVal;
2: bool bVal;
3: i64 iVal;
4: double fVal;
5: binary sVal;
6: Date dVal;
7: Time tVal;
8: DateTime dtVal;
9: Vertex (cpp.type = "nebula::Vertex") vVal (cpp.ref_type = "unique");
10: Edge (cpp.type = "nebula::Edge") eVal (cpp.ref_type = "unique");
11: Path (cpp.type = "nebula::Path") pVal (cpp.ref_type = "unique");
12: NList (cpp.type = "nebula::List") lVal (cpp.ref_type = "unique");
13: NMap (cpp.type = "nebula::Map") mVal (cpp.ref_type = "unique");
14: NSet (cpp.type = "nebula::Set") uVal (cpp.ref_type = "unique");
15: DataSet (cpp.type = "nebula::DataSet") gVal (cpp.ref_type = "unique");
16: Geography (cpp.type = "nebula::Geography") ggVal (cpp.ref_type = "unique");
17: Duration (cpp.type = "nebula::Duration") duVal (cpp.ref_type = "unique");
18: Binary (cpp.type = "nebula::Binary") btVal (cpp.ref_type = "unique");
} (cpp.type = "nebula::Value")
另外我们还需要在 common.thrift 文件中的 PropertyType 该枚举中增加一个 BINARY 类型。
enum PropertyType {
UNKNOWN = 0,
... // 基础类型
TIMESTAMP = 21,
DURATION = 23,
DATE = 24,
DATETIME = 25,
TIME = 26,
GEOGRAPHY = 31,
BINARY = 32,
} (cpp.enum_strict)
2.2 实现 Binary 的 thrift rpc 格式的序列化
这里的代码就不展示了,同样可以参考其他类型的实现。最相近的可以参考 src/common/datatypes/ListOps-inl.h 的实现
3. 命令行实现
数据结构定义好之后,我们可以开始命令行的实现,首先打开 src/parser/scanner.lex,我们需要新增一个关键字 Binary:
"BINARY" { return TokenType::KW_BINARY; }
接着打开 src/parser/parser.yy 文件,将关键字声明一下:
$token KW_BINARY
为了尽量减少命令行的影响,我们将 Binary 关键字添加到非保留关键字的集合中:
unreserved_keyword
...
| KW_BINARY { $$ = new std::string("binary"); }
接下来我们要将Binary关键字添加到建表命令的词法树中:
type_spec
...
| KW_BINARY {
$$ = new meta::cpp2::ColumnTypeDef();
$$->type_ref() = nebula::cpp2::PropertyType::BINARY;
}
最后我们实现插入命令:
constant_expression
...
| KW_BINARY L_PAREN STRING R_PAREN {
$$ = ConstantExpression::make(qctx->objPool(), Value(Binary(*$3)));
delete $3;
}
就这样,我们就简单实现了上面命令设计里面的创建 binary schema 和插入 binary 数据的命令。
4. storaged 服务的读写适配
上面我们搞定了数据结构定义和 rpc 序列化以及命令行适配,一个新增的数据结构通过命令创建后,由 grapd 服务接收到请求并传输给 storaged 服务端。然而 storaged 服务端存储实际的数据是经过编码之后的 string,我们需要为这个新增的数据结构写一个编解码的代码逻辑。
4.1 RowWriterV2 写适配
在代码文件 src/codec/RowWriterV2.cpp 中,有以下几个函数需要适配的。
RowWriterV2::RowWriterV2(RowReader& reader) // 构造函数中适配新增的类似
WriteResult RowWriterV2::write(ssize_t index, const Binary& v) // 新增一个Binary的编码写入函数
这里我直接将 Bytes 数组写入 String 中
WriteResult RowWriterV2::write(ssize_t index, const Binary& v) noexcept {
return write(index, folly::StringPiece(reinterpret_cast<const char*>(v.values.data()), v.values.size()));
}
4.2 RowReaderV2 读适配
在代码文件 src/codec/RowReaderV2.cpp 中,同样有以下函数需要适配
Value RowReaderV2::getValueByIndex(const int64_t index) const {
...
case PropertyType::VID: {
// This is to be compatible with V1, so we treat it as
// 8-byte long string
return std::string(&data_[offset], sizeof(int64_t));
}
case PropertyType::FLOAT: {
float val;
memcpy(reinterpret_cast<void*>(&val), &data_[offset], sizeof(float));
return val;
}
case PropertyType::DOUBLE: {
double val;
memcpy(reinterpret_cast<void*>(&val), &data_[offset], sizeof(double));
return val;
}
...
// code here
case PropertyType::BINARY: {
...
}
}
需要注意的是:读和写必须映射上,怎么写的就怎么读。
至此,在 NebulaGraph 里新增一个数据类型的流程就结束了。
看看效果
![]()
![]()
感谢你的阅读 (///▽///)
对图数据库 NebulaGraph 感兴趣?欢迎前往 GitHub ✨ 查看源码:https://github.com/vesoft-inc/nebula; 想和其他图技术爱好者一起交流心得?和 NebulaGraph 星云小姐姐 交个朋友再进个交流群;