作者:栾小凡 Zilliz 合伙人、技术总监
近期, OpenAI 在首届开发者大会上公布了系列最新进展,引发各大媒体和从业人员的广泛关注。
其中最引人注目的是全新推出的 GPT-4 Turbo ——一个更经济、更高效的服务版本,可以显著提升用户体验。不止如此,多模态技术的融合也开辟了前所未有的可能性,使得开发者能够在一个统一的平台上同时处理文本、图像以及其他多种类型的数据。GPT Store 的推出更是一个重要的里程碑,它为用户提供了定制化 GPT 模型的能力,这也意味着,无论是大型企业还是个人开发者,都能够享受到这项创新带来的个性化 AI 解决方案。
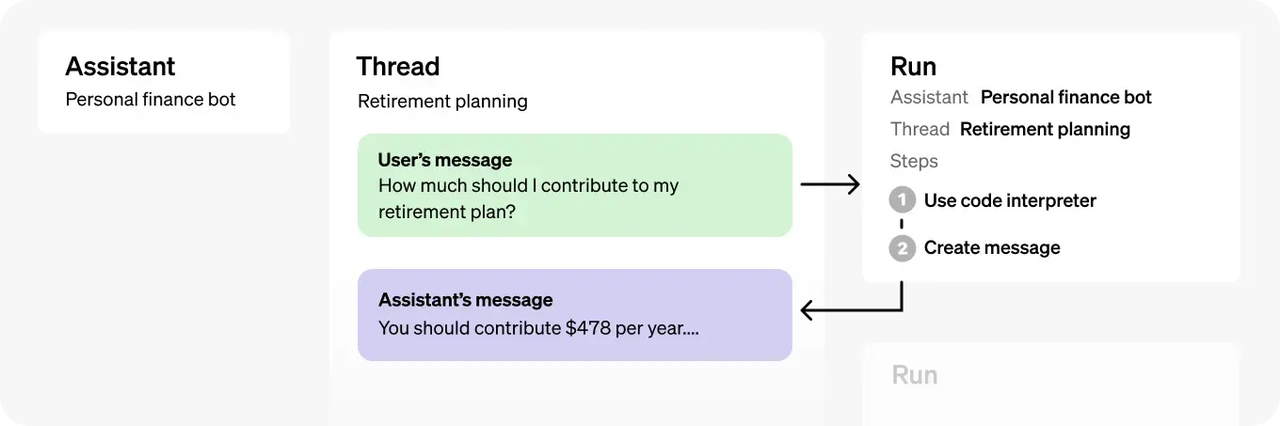
不过,最令人惊讶的还是 OpenAI 推出了全新的 Assistant 功能。它直接介入应用开发领域,这一变化不仅象征着 OpenAI 作为工具和平台的提供者的角色转变,还体现了它在推动技术应用方面的积极参与。新推出的 Assistants API 是一个量身定制的 AI 工具,它能够利用额外的工具来协助开发者创建更智能的 AI 助手。这个 API 不仅支持代码解释执行、函数调用和数据检索等基本功能,还提供了强大的持久化和无限长线程功能,极大地增强了开发者在应用开发中对复杂数据的处理和记忆管理能力。
![]() |OpenAI Assistant 接口架构
|OpenAI Assistant 接口架构
毫无疑问,Assistant 接口的推出为 GPT 技术 开辟了新的可能性。ReAct 范式下 Agent,包含了任务拆解、Memory管理、工具调用等能力,这和 Assistant API 的定义是非常接近的。
然而,这种创新同时也给 OpenAI 生态圈内的开发者带来了不小的挑战,尤其对那些专注于中间件框架和向量数据库的供应商来说更是如此。市场上有声音称,OpenAI 的这些动作可能对小型创业公司构成严峻挑战,一些唱衰向量数据库的言论也此起彼伏。
对此,作为一名向量数据库行业的从业者,我也收到了许多关于向量数据库未来和 OpenAI Assistant 的 Knowledge Retrieval 能力的疑问和质疑。接下来,我就和各位分享自己的思考:Assistant 功能是否真的有能力取代传统的向量数据库。
![]() |开发者绝望的Twitter
|开发者绝望的Twitter
从定价和限制讲起
想要逆向分析 OpenAI 究竟如何实现 RAG,可以先从探究其计费策略开始。目前,Assistants API 仍处于初期阶段,关于它的信息相对有限,可以参考 OpenAI 官网关于计费的部分和一些说明:
![]() |Assistants API 计费信息
|Assistants API 计费信息
我们通过对可用资料的分析,得出以下几点关键结论:
- 首先,Assistants API 仍旧依赖于向量数据库索引机制,暗示着其背后并非神秘的黑科技。
- 其次,它采取的是按每个Assistant计费,表明 OpenAI 目前还未涉足多租户模式等更复杂的服务结构。
- 最后,从计费模式来看,OpenAI 似乎没有将检索和文件上传的成本计入考虑,这可能意味着公司认为这些操作所需的计算资源成本相对较低。或许 OpenAI 认为向量数据的算力成本很低,因此只需要计算文档 Embdedding 和生成就可以覆盖计算成本。
那么 0.2💲/GB/assistant/day 到底是什么概念呢?我们与常见的存储 AWS S3(0.023元/GB/月)对比,前者大概是后者的 260 倍。这样看来,OpenAI 的定价并不便宜,然而,如果从向量索引的角度计算,我们得出了完全不同的结论:
以一个 3M 左右的文件为例,数据集来自于 MS_marco 的, 使用 ChatGPT 的文本处理功能统计得出的单词个数为共544,355 个。
由此,我们可以做一些简单的数学推断:
- Token 计算:
- 在 OpenAI 的环境中,通常情况下 75 个单词对应 100 个 OpenAI token。
- 一个 3M 大小的文件,假设其包含约 544,355 个单词,那么该文件大约包含 750,000 个 token(根据 75字/100 token 的比例换算)。
- 向量数目计算:
- 按照一般的 RAG(Retrieval-Augmented Generation)模式,每 500 个 token 构成一个数据块,即一个向量。
- 因此,对于大约 750,000 个 token 的文件,它大约对应 1,500 个向量(750,000 token / 500 token/向量)。
- 向量大小计算:
- 按照 OpenAI 的向量计算标准,1500 个向量的总大小是 9M(计算方式:1500 向量 × 1536 维 × 4 字节/维)。
- 这意味着即使不考虑索引结构,一个 3M 大小的原始文档在向量形式下至少需要 9M 的内存。
- 内存需求推算:
- 根据以上计算,可以推算出 1 GB 大小的文件在向量数据库中可能需要至少 3 GB 的索引内存。
- 成本计算:
- 参考 AWS 的 r6id.large机型,16 GB 内存的单月价格为 108.864 美金。
- 因此,每 GB 内存的月均成本约为 6.8 美金(108.864 美金 / 16GB)。
OpenAI 的售价为 6 美金 1GB,而实际的内存开销高达 6.8 * 3 大约 20 美金,考虑水位、额外内存占用等因素,这不由得让人怀疑,OpenAI 是不是藏着什么黑科技,能大幅削减这些看似天价的索引成本?
算到这里,我瞬间觉得头皮发麻。对于我们这些向量数据库厂商来说,OpenAI 似乎把生存的空间压缩得越来越小。真的是这样吗?好奇心驱使我开始测试 OpenAI 的 Assistant API,想看看它到底有多厉害。但很快我就发现,事情没那么简单。
说说上传文件的问题吧:
![]() |OpenAI Assistants 文件限制
|OpenAI Assistants 文件限制
- 文档中文件数量的限制:看来 OpenAI 对文件数量有着严格的规定。每个用户只能上传 20 个文件,而且每个文件最大也就 512 MB。就算是一个组织,上传的总量也不能超过 100 GB。听起来 100 GB也够用,但这对那些需要处理海量数据的人来说,可能就有点力不从心了。
- 上传尝试和意外发现:我还尝试上传了一个 80 MB的文件,遗憾的是,这次尝试失败了。我意外发现,除了文件大小的限制,还有一个隐藏的规则——每个文件的 token 数量不能超过 2M。这意味着单个文件里的向量数量大约在 1 万以下,20 个文件加起来也就是 20 万向量,这只能打到 Zilliz Cloud 免费实例提供的范围。
逆向一下OpenAI的思路
让我们换个角度来看看 OpenAI 【可能是如何构建 Retreive 】服务的,主要从架构、成本优化、性能和查询效果几个方向考虑。
架构
- 对于个人用户(ToC),OpenAI 通过限制每个人能上传的文档数量来控制数据量。这样做的目的是让每个用户的数据保持在百万级别以下,这样一个物理服务器就能服务几十个用户。这样猜测的主要原因是租户数目过多,因为如果每个用户都分配独立的 1c2g 资源,成本可能会超过他们的收费。
- 对于企业用户(ToB),每个组织的数据限额被设定在 100 GB。这可能是因为 OpenAI 目前主要依赖单机方案,所以需要确保每个用户的数据量不超出千万级别。
- 弹性架构设计:OpenAI 可能是在 Kubernetes(K8s)上部署了多个这样的单机向量数据库。这样一来,就可以根据需求弹性地扩展或缩减资源。部署在 K8s 的一个好处是,它可以根据用户的实际使用量来自动调整资源,这对于那些数据使用量不大的用户来说,可以进一步降低成本。
![]() |OpenAI Retrieve架构
|OpenAI Retrieve架构
成本
现在,我们来讨论讨论成本问题。OpenAI在成本控制方面也有不少可行的方案:
- 使用磁盘索引方案:为了降低数据存储成本,OpenAI可能采用了特殊的磁盘索引技术。这种方法可能把成本降低了大概5到10倍。值得注意的是磁盘索引方案可能会大幅降低性能,目前绝大部份向量数据库并没有高性能的磁盘索引方案。
- 降低召回要求来节约成本:如果对数据召回的精确度要求不是特别高,OpenAI可能使用了一种叫做产品量化(Product Quantization)的技术。这种技术可以使相同内存装载大约4到8倍的向量数据,并且可能带来一定的查询性能提升。
- 其他成本考虑:还有其他一些因素可能影响成本。比如说,如果文档中包含很多图片,这些图片的原始向量数据可能会被压缩得更小。另外,计费策略中没有明确说明,如果文档小于1GB是否还是按照1GB来收费。这意味着对于数据量不大的用户,OpenAI可能在实际上卖出了比实际使用更多的资源,这也是一种减少成本的策略。
性能
根据我们的测试,一次查询的调用时间大概在5秒左右,这远远超出了一般向量数据库的响应时间,可以认为的性能瓶颈仍然在大模型侧。但是值得注意的是,如果向量达到千万级或者亿级,向量检索的速度也可能到达百ms甚至秒级,此时性能就会变得至关重要。 效果
![]() |OpenAI RAG 优化路线
|OpenAI RAG 优化路线
除了性能之外,大家可能还很好奇 OpenAI 在召回效果上有没有什么特别的秘诀。在最近的 OPENAI Devday上,我们看到了一些有趣的展示,其中显示了 OpenAI 在优化他们的 RAG 查询时使用了不少技巧,这包括 HyDE(生成假设性响应)、对模型的微调、调整数据块大小、结果的重新排序、查询的扩展甚至是工具的特殊使用等等。
从目前的测试结果来看,OpenAI Assistant 的表现确实不错,但它并没有完全解决 RAG 系统中存在的一些问题。在我的测试中,有两个方面的结果并不尽如人意:
- 长文本摘要:当对长文本进行摘要时,Assistant只提供了一些零散的信息,而没有像我预期的那样,利用新版本GPT的长上下文能力来处理整段文章。
- 特定关键词查询:例如,当我询问某个文档ID中提到了什么内容时,Assistant并没有提供有用的信息。这种基于特定关键词的查询,如果使用了倒排索引技术,应该是比较容易处理的。
另外,LLamaIndex框架也推出了类似的测试。结果显示,就正确性和相似性而言,LLamaIndex 的 QueryEngine 比当前的 Retrieval Assistant 表现得更好。"
OpenAI,请重新思考 Retrieval Assistant 的方案
根据我们的上述分析,OpenAI 的召回实现其实并不完美,仍然存在一些问题:
- 扩展性问题:目前的单租户模式似乎不支持处理超过百GB的大型文档集。
- 缺少灵活性:从现有实现来看,系统似乎难以从处理几个文档有效扩展到处理数万个文档。
- 多租户支持不足:随着用户数量的增加,即使每个用户每月只支付 6 美元,当用户数达到几万时,总成本还是非常高。
- 性能与成本挑战:一旦处理的数据量大幅增加,就会面临更大的成本和性能挑战。根据我们的测试,Retrieval Assistant 在延迟和并发处理方面似乎难以满足实际生产环境的需求。
- 搜索效果欠佳:目前缺乏在标量和向量之间进行混合检索的能力。
- RAG 实现一般:与业界最先进的技术相比,其实现似乎稍显逊色,尤其是在特定的应用场景中,定制化的解决方案可能会有更好的效果。
- 产品体验问题:API 相对复杂(相比之下,LlamaIndex 封装的 API 更为简洁明了),而且计费逻辑也不够清晰。例如,目前用户无法判断一次 Assistant 调用会消耗多少 token。
看起来,Assistant API 已经给出了解决它目前问题的线索,也就是所谓的'函数调用'(Functional calling)。这有点像传统业务中使用 SQL 语言从关系型数据库获取数据那样,通过 Retrieval API 从向量数据库获取数据似乎是一个更好的方法。
- 向量数据库的优势:首先,像 Milvus 和 Pinecone 这样的向量数据库通常具有出色的扩展性,能够支持从十亿到百亿规模的向量,而且还能够实现多租户功能,一台服务器就能支持百万级别的用户,通过外置向量数据库,Assistant API 的扩展性会更好。
- Serverless 向量数据库的前景:Serverless 向量数据库肯定会成为一个重要的领域。通过降低费用、提供更好的隔离性和提升系统弹性,向量数据库将持续改进,这也是数据库赛道大家持续优化迭代的目标。OpenAI 应该更多地关注模型层面的优化,因为这才是推动 AIGC 革命的关键。
- RAG 数据需求的复杂性:RAG(Retrieval-Augmented Generation)并不仅仅是简单的向量召回工作。在不同业务场景下,向量数据库、关系型数据库、图数据库和搜索引擎都扮演着重要的角色。OpenAI Assistant 应该更关注如何有效地结合这些工具来完成任务,而不是自己部署维护一个存储产品。
- 复杂的业务逻辑和用户需求:随着 RAG 逻辑的日益复杂,用户需要更多的控制权和透明度。在实际的生产环境中,成本、稳定性、可观测性和数据安全性都非常重要,而 OpenAI 似乎低估了这些因素的复杂度。
最后,如果 OpenAI 决定自己维护向量数据库,我也会推荐 Zilliz 的产品——Linux 基金会支持的开源项目 Milvus。面对 OpenAI 庞大的用户规模和复杂的成本需求,Milvus 的高扩展性、高性能、磁盘索引能力和标量查询能力都是更好的选择。更不必说我们即将发布的 2.4 版本,它将包含许多专门针对 RAG 场景的优化,将帮助开发者更好地构建自己的 RAG 应用提高召回效果。也欢迎所有大模型行业的各位联系我们,大家一起探索更多大模型和向量数据库融合的可能性。
 |OpenAI Assistant 接口架构
|OpenAI Assistant 接口架构 |开发者绝望的Twitter
|开发者绝望的Twitter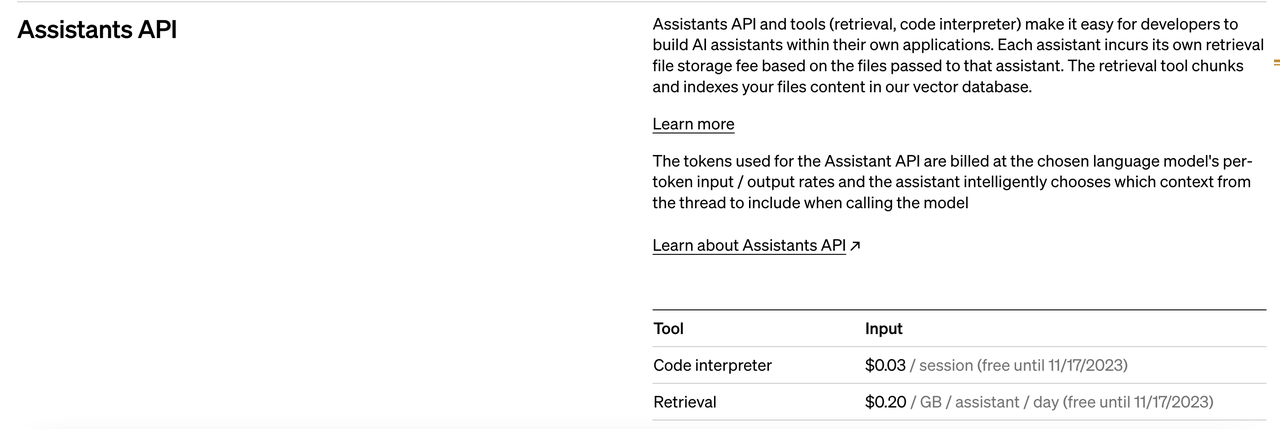 |Assistants API 计费信息
|Assistants API 计费信息 |OpenAI Assistants 文件限制
|OpenAI Assistants 文件限制 |OpenAI Retrieve架构
|OpenAI Retrieve架构 |OpenAI RAG 优化路线
|OpenAI RAG 优化路线