在上篇文章中,我们向大家解释了为什么实时湖仓是当前企业数字化转型过程中的解决之道,介绍了实时计算和数据湖结合的应用场景。(“数据驱动”时代,企业为什么需要实时湖仓?)
在这篇文章中,我们将详细介绍在数栈实时开发平台内,实时湖仓的功能架构设计和具体实操案例。
功能架构介绍
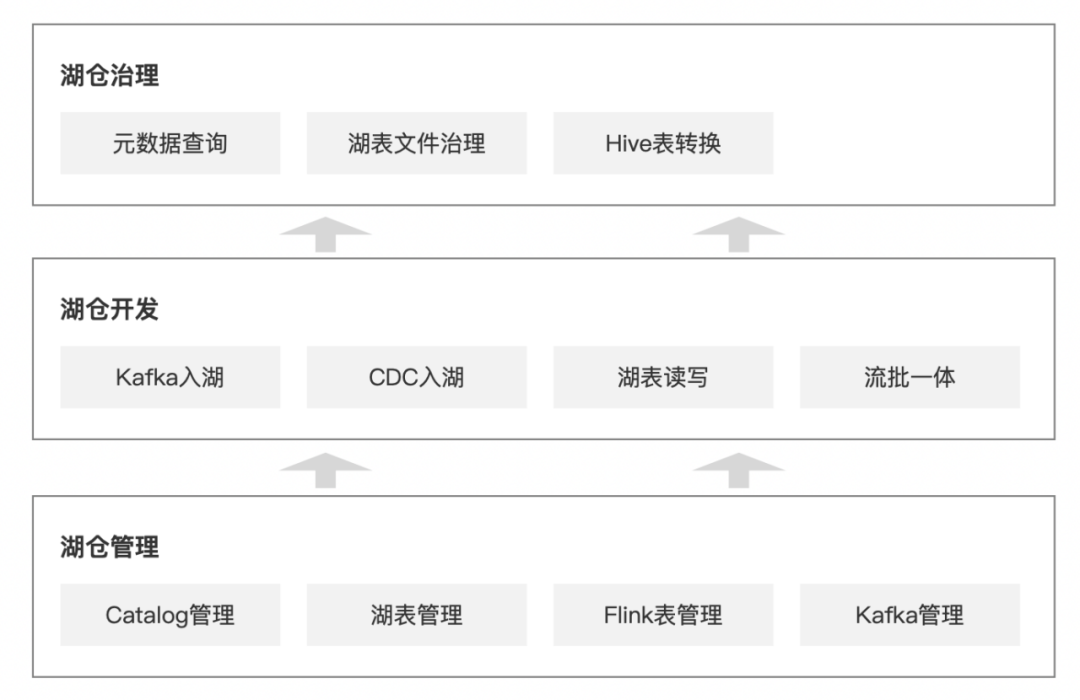
实时湖仓并不是一个独立的产品模块,它的完整实践是基于数栈实时开发平台进行的。为了更直观地介绍我们建设实时湖仓的完整思路,我们单独拆出了架构图供大家参考。
![file]()
湖仓管理
湖仓管理是建设实时湖仓的基础,通过这一层的建设,你可以:
· 借助 Flink Catalog 管理,构建一套虚拟湖仓分层架构,类似传统离线数仓中的主题域、DW 分层设计
· 可视化创建湖表,平台支持 Paimon、Hudi、Iceberg 三种湖表创建,并分别提供对应的 DDL DEMO
· 通过 Flink 表管理,持久化存储基于 RDB、Kafka 创建的 Flink 映射表,和湖表一起,为实时计算提供表管理能力
· 作为实时计算领域最常用的数据介质,平台同时也支持对 Kafka Topic 进行基础的增删改查、数据统计分析等功能
湖仓开发
湖仓开发是建设实时湖仓的核心能力,按应用场景主要分为:
· 数据入湖:通过实时消费 Kafka,或者读取 RDB 的 CDC 数据,将业务数据实时打入数据湖,构建实时湖仓的 ODS 层,为后续的流/批读写提供统一的数据基础
· 湖仓加工:借助湖表格式的事务特性、快照特性等能力,通过 FlinkSQL 任务读写湖表,构建湖仓中间层
· 流批一体:在湖仓加工过程中,根据不同的业务场景,可以选择流读或批读。在流批一体的设计上,你可以选择先批读存量数据,无缝衔接流读增量数据;也可以选择流读增量数据,批读进行数据订正
湖仓治理
在湖仓开发过程中,我们可以通过湖仓治理能力,不断优化完善实时湖仓:
· 湖表文件治理:在湖仓开发过程中,会产生大量小文件、过期快照、孤儿文件等数据,严重影响湖表的读写性能。通过文件治理功能,可以定期合并小文件、清理过期快照/孤儿文件,提高开发效率
· 元数据查询:在提供 Catalog/Database/Table 基础信息查询的同时,会对湖表的存储、行数、任务依赖等信息进行统计,方便全局判断湖表价值
· Hive 表转换:对于历史 Hive 表,平台支持在不影响历史数据的前提下,一键转换表类型
实操案例分享
下面通过一个数开案例,详细介绍如何在平台实现数据入湖、湖仓开发、湖仓治理。
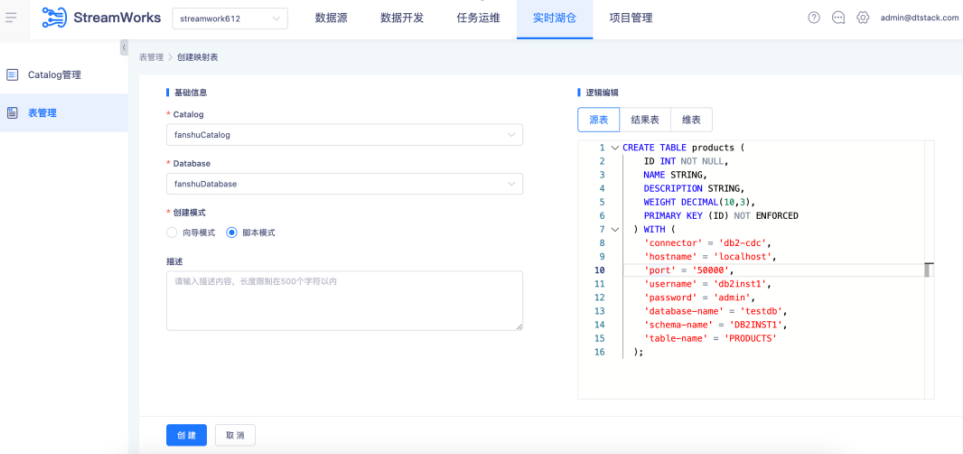
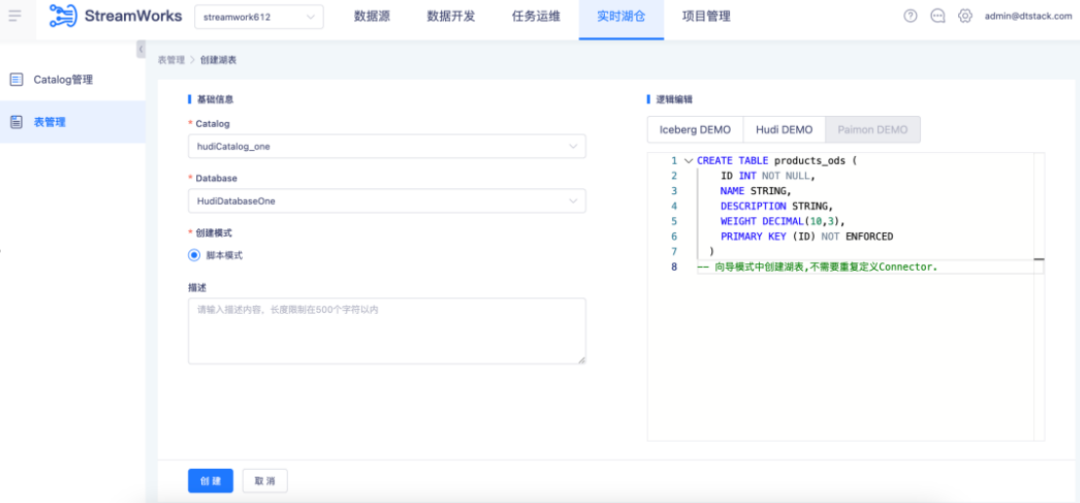
数据入湖(实时采集 DB2 数据,写入 PaimonA 湖表)
● 先创建 DB2-CDC 的 Flink 映射表和 Paimon 湖表
![file]()
![file]()
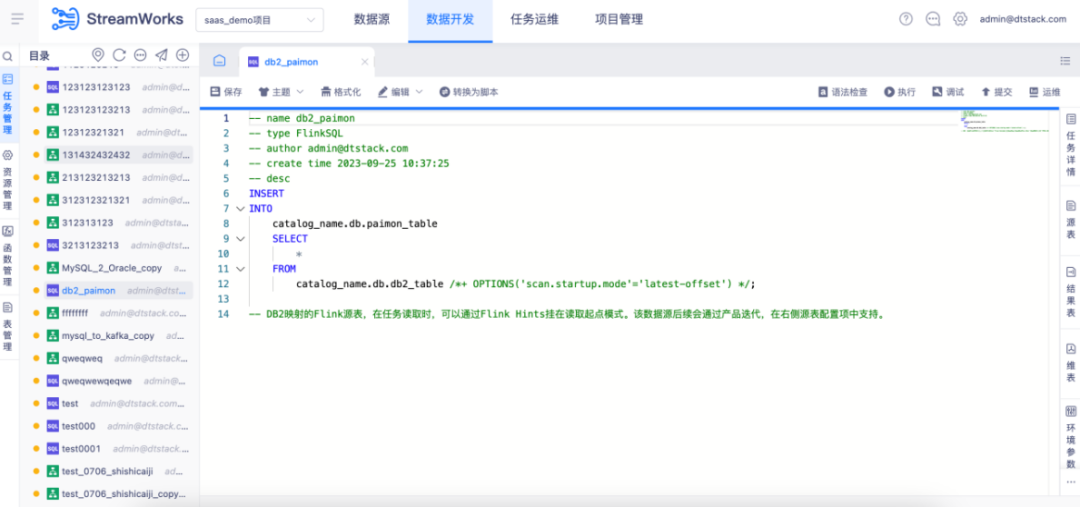
● 开发入湖任务
![file]()
湖仓开发(流式读取 PaimonA,流式写入 PaimonB)
● 创建 PaimonB
方式同上,此处不再重复演示。
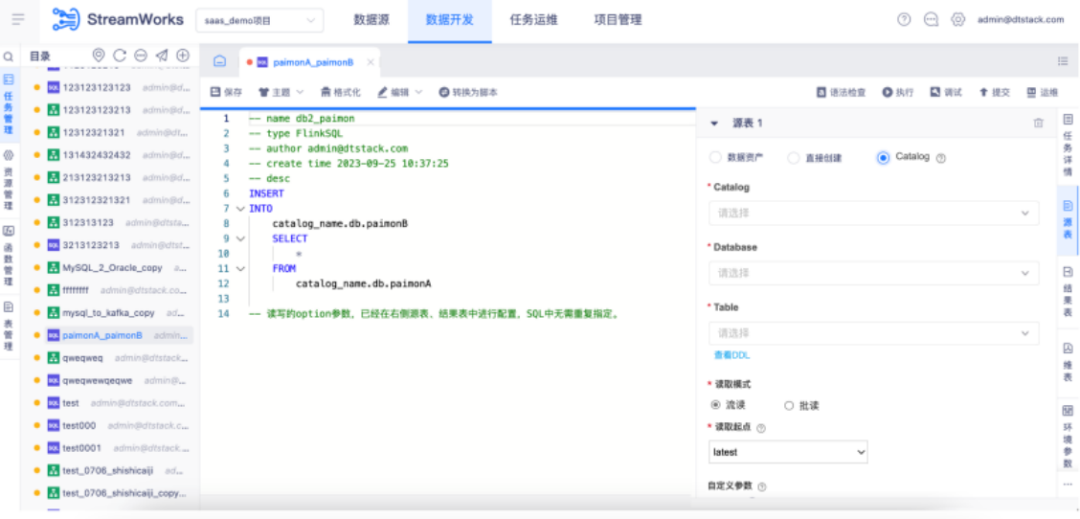
● 开发读写湖表任务
平台支持读写参数的配置化开发,无需在 SQL 代码中定义,从而极大地提高了开发效率。例如,在湖表读取时选择时间戳,如果使用 SQL 开发,需要先在后台查询快照数据,并进行时间戳转换才能理解。而通过配置化方式,可以直接选择或输入日期时间,在提交任务时自动进行时间戳转换。
![file]()
湖仓治理
● 元数据查询
提供 Catalog、Database、湖表(Paimon/Hudi/Iceberg)、Flink 映射表的元数据查询。
![file]()
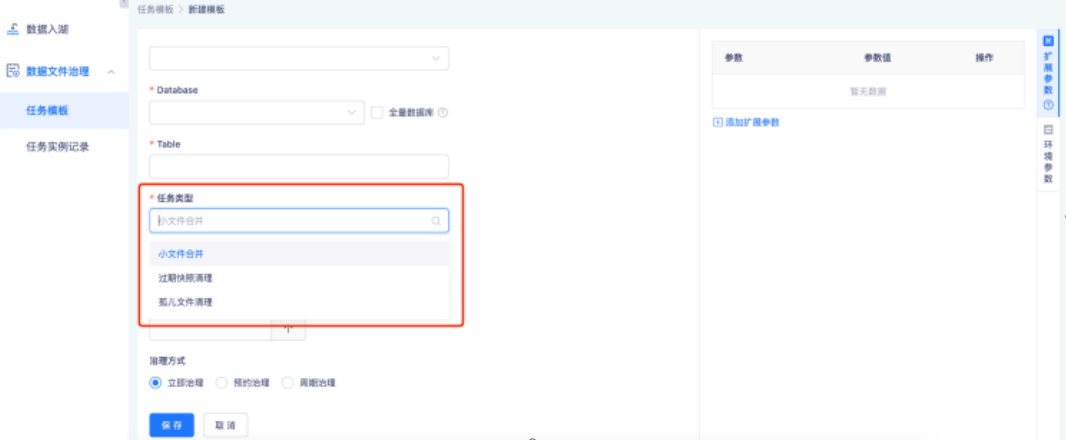
● 数据文件治理
湖表的读写,特别是实时场景下的读写,会产生大量的小文件,小文件过多又会影响读取性能。因此对于湖表文件的治理功能,是建设实时湖仓必不可缺的一部分。
![file]()
总结
实时湖仓是「实时计算」和「数据湖」的一种结合应用场景,并不是具体指一个产品模块。平台通过相关功能的设计,让数据开发可以更简单更直观地了解 Flink Catalog、数据湖、流批一体等概念,并在实际业务场景中更方便地去落地实践。
本文根据《实时湖仓实践五讲第二期》直播内容总结而来,感兴趣的朋友们可点击链接观看直播回放视频及免费获取直播课件。
直播课件:
https://www.dtstack.com/resources/1053?src=szgzh
直播回放视频:
https://www.bilibili.com/video/BV1Uw411k7iS/?spm_id_from=333.999.0.0
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm 想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack