Rust + Wasm 技术栈可以是 AI 推理中强大的 Python 替代方案。
与 Python 相比,Rust+ Wasm 应用程序的大小可以是 Python 的 1/100,速度可以提高 100 倍,最重要的是,可以在完全硬件加速的情况下安全地在任何地方运行,而无需对二进制代码进行任何更改。 Rust 是 AGI 的语言。
我们创建了一个非常简单的 Rust 程序(40 行代码),以本机速度使用 llama2 模型进行推理。当编译为 Wasm 时,二进制应用程序(仅 2MB)可以在有着异构硬件加速器的设备之间完全移植。 Wasm 运行时( WasmEdge )还为云环境提供了安全可靠的执行环境。事实上,WasmEdge Runtime 还可以与容器工具无缝协作,可以跨许多不同的设备编排和执行可移植应用程序。
[点此查看 dmeo 视频:如何在 MacBook 上与 llama2 模型聊天](【用 2MB 应用运行大型语言模型?WebAssembly带你飞!】 https://www.bilibili.com/video/BV1BF411m73B/?share_source=copy_web&vd_source=71527f8e252ebbaa141625dd2b623396 "点此查看 dmeo 视频:如何在 MacBook 上与 llama2 模型聊天")
这项工作基于 Georgi Gerganov创建的 llama.cpp 项目。我们采用了原始的 C++ 程序在 Wasm 上运行。它适用于 GGUF 格式的模型文件。
在你的电脑上运行 Llama 2 模型
步骤 1. 安装 WasmEdge 以及 GGML 插件
在 Linux 或 Mac (M1/M2) 计算机上使用以下命令来安装所有内容。请参阅此处了解更多详细信息。
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install.sh | bash -s -- --plugin wasi_nn-ggml
步骤 2. 下载预构建的 Wasm 应用程序和模型
curl -LO https://github.com/second-state/WasmEdge-WASINN-examples/raw/master/wasmedge-ggml-llama-interactive/wasmedge-ggml-llama-interactive.wasm
你还需要下载 GGUF 格式的 llama2 模型。下面的示例下载了一个量化为 5 位权重、针对对话特别优化的 llama2 7B 模型(请在此处查看更多信息)。
curl -LO https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/resolve/main/llama-2-7b-chat.Q5_K_M.gguf
步骤 3. 运行试试!
使用 WasmEdge 运行 Wasm 推理应用程序,并将 GGUF 模型传递给它。你现在可以输入问题与模型聊天。
wasmedge --dir .:. --nn-preload default:GGML:CPU:llama-2-7b-chat.Q5_K_M.gguf wasmedge-ggml-llama-interactive.wasm default
Question:
这是一个完整的对话示例。
wasmedge --dir .:. --nn-preload default:GGML:CPU:llama-2-7b-chat.Q5_K_M.gguf wasmedge-ggml-llama-interactive.wasm default
Question:
Who is the "father of the atomic bomb"?
Answer:
The "father of the atomic bomb" is a term commonly associated with physicist J. Robert Oppenheimer. Oppenheimer was a leading figure in the development of the atomic bomb during World War II, serving as the director of the Manhattan Project, which was responsible for the development and deployment of the first nuclear weapons. He is often referred to as the "father of the atomic bomb" due to his significant contributions to the field of nuclear physics and his leadership in the development of the bomb.
Question:
Was he a communist?
Answer:
J. Robert Oppenheimer was not a communist. While he was associated with the Manhattan Project, which was a secret government project, and was involved in the development of the atomic bomb, he was not a member of the Communist Party or had any known political affiliations with communism. Oppenheimer was a physicist and a scientist, and his primary focus was on the development of nuclear weapons during World War II.
可选:配置模型
你可以使用环境变量来配置模型执行。
例如,以下命令指定了上下文长度为 4千 token,这是 llama2 的标准,并且每个响应中的最大 token 数为 1k。 它还告诉 WasmEdge 在 runtime 层面打印模型的日志和统计数据。
LLAMA_LOG=1 wasmedge --dir .:. --nn-preload default:GGML:CPU:llama-2-7b-chat.Q5_K_M.gguf wasmedge-ggml-llama-interactive.wasm default
llama_model_loader: loaded meta data with 19 key-value pairs and 291 tensors from llama-2-7b-chat.Q5_K_M.gguf (version GGUF V2 (latest))
llama_model_loader: - tensor 0: token_embd.weight q5_K [ 4096, 32000, 1, 1 ]
... ...
llm_load_tensors: mem required = 4560.96 MB (+ 256.00 MB per state)
...................................................................................................
Question:
Who is the "father of the atomic bomb"?
llama_new_context_with_model: kv self size = 256.00 MB
... ...
llama_print_timings: sample time = 3.35 ms / 104 runs ( 0.03 ms per token, 31054.05 tokens per second)
llama_print_timings: prompt eval time = 4593.10 ms / 54 tokens ( 85.06 ms per token, 11.76 tokens per second)
llama_print_timings: eval time = 3710.33 ms / 103 runs ( 36.02 ms per token, 27.76 tokens per second)
Answer:
The "father of the atomic bomb" is a term commonly associated with physicist J. Robert Oppenheimer. Oppenheimer was a leading figure in the development of the atomic bomb during World War II, serving as the director of the Manhattan Project, which was responsible for the development and deployment of the first nuclear weapons. He is often referred to as the "father of the atomic bomb" due to his significant contributions to the field of nuclear physics and his leadership in the development of the bomb.
![]() 边缘上的 llama。图片由 Midjourney 生成。
边缘上的 llama。图片由 Midjourney 生成。
为什么不选Python?
像 llama2 这样的大语言模型通常使用 Python 进行训练(例如PyTorch 、 Tensorflow和 JAX)。但使用 Python 进行推理应用(AI 中约 95% 的计算)将是一个严重的错误。
- Python 包具有复杂的依赖关系。它们很难搭建和使用。
- Python 的依赖非常大。 Python 或 PyTorch的 Docker 镜像通常为数 GB 甚至数十 GB。这对于边缘服务器或设备上的 AI 推理来说尤其成问题。
- Python 是一种非常慢的语言。比 C、C++ 和 Rust 等编译语言慢达 35,000 倍。
- 由于 Python 速度很慢,因此大部分实际工作负载须委托给 Python wrapper 之下的本机共享库。这使得 Python 推理应用程序非常适合演示,但很难在幕后修改以满足特定于业务的需求。
- 对本机库的笨重依赖以及复杂的依赖管理,使得在利用设备独特的硬件功能的同时跨设备移植 Python AI 程序变得非常困难。
![]() LLM 工具链中常用的 Python 包直接相互冲突。
LLM 工具链中常用的 Python 包直接相互冲突。
因 LLVM、 Tensorflow和 Swift 语言而闻名的 Chris Lattner 在最近一期创业播客中接受了精彩的采访。他讨论了为什么 Python 非常适合模型训练,但对于推理应用来说却是错误的选择。
Rust+ Wasm 的优点
Rust + Wasm 堆栈提供了统一的云计算基础设施,涵盖设备到边缘云、本地服务器和公共云。对于 AI 推理应用程序来说,它是 Python 堆栈的强大替代方案。难怪埃隆·马斯克说 Rust 是 AGI 的语言。
- **超轻量。**包含所有依赖项的推理应用程序只有 2MB。它的大小不到典型 PyTorch 容器大小的 1%。
- **非常快。**原生 C/Rust 速度可以贯穿推理应用程序的所有部分:预处理、张量计算和后处理。
- **可移植。**相同的 Wasm 字节码应用程序可以在所有主要计算平台上运行,并支持异构硬件加速。
- **易于设置、开发和部署。**没有更复杂的依赖。使用笔记本电脑上的标准工具构建单个 Wasm 文件并将其部署到任何地方!
- **安全且云就绪。 **Wasm 运行时旨在隔离不受信任的用户代码。 Wasm 运行时可以通过容器工具进行管理,并轻松部署在云原生平台上。
Rust 推理程序
我们的演示推理程序是用 Rust 编写的并且编译成了 Wasm。Rust 源代码非常简单。它只有 40 行代码。 Rust 程序管理用户输入,跟踪对话历史记录,将文本转换为 llama2 的聊天模板,并使用 WASI NN 标准 API 运行推理操作。
fn main() {
let args: Vec<String> = env::args().collect();
let model_name: &str = &args[1];
let graph =
wasi_nn::GraphBuilder::new(wasi_nn::GraphEncoding::Ggml, wasi_nn::ExecutionTarget::AUTO)
.build_from_cache(model_name)
.unwrap();
let mut context = graph.init_execution_context().unwrap();
let system_prompt = String::from("<<SYS>>You are a helpful, respectful and honest assistant. Always answer as short as possible, while being safe. <</SYS>>");
let mut saved_prompt = String::new();
loop {
println!("Question:");
let input = read_input();
if saved_prompt == "" {
saved_prompt = format!("[INST] {} {} [/INST]", system_prompt, input.trim());
} else {
saved_prompt = format!("{} [INST] {} [/INST]", saved_prompt, input.trim());
}
// Set prompt to the input tensor.
let tensor_data = saved_prompt.as_bytes().to_vec();
context
.set_input(0, wasi_nn::TensorType::U8, &[1], &tensor_data)
.unwrap();
// Execute the inference.
context.compute().unwrap();
// Retrieve the output.
let mut output_buffer = vec![0u8; 1000];
let output_size = context.get_output(0, &mut output_buffer).unwrap();
let output = String::from_utf8_lossy(&output_buffer[..output_size]).to_string();
println!("Answer:\n{}", output.trim());
saved_prompt = format!("{} {} ", saved_prompt, output.trim());
}
}
要自行构建应用程序,只需安装 Rust 编译器及添加 wasm32-wasi 编译器目标。
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
rustup target add wasm32-wasi
然后,查看源项目,并运行 Cargo 命令以从 Rust 源项目构建 Wasm 文件。
# Clone 源代码
git clone https://github.com/second-state/WasmEdge-WASINN-examples/
cd WasmEdge-WASINN-examples/wasmedge-ggml-llama-interactive/
# 构建 Rust 程序
cargo build --target wasm32-wasi --release
# 输出的 Wasm 结果文件
cp target/wasm32-wasi/release/wasmedge-ggml-llama-interactive.wasm .
在云端或边缘运行
一旦获得 Wasm 字节码文件,你可以将其部署在任何支持 WasmEdge Runtime 的设备上。你的设备上只需安装带有 GGML 插件的 WasmEdge。我们目前有适用于通用 Linux、Ubuntu Linux 和 Mac M1/M2 的 GGML 插件。
基于 Llama.cpp,WasmEdge GGML 插件将自动利用设备上的一切硬件加速来运行你的 Llama2 模型。例如,GGML 插件的 Mac OS 版本使用 Metal API 在 M1/M2 的内置神经处理引擎上运行推理工作负载。GGML 插件的 Linux CPU 版本使用 OpenBLAS 库来自动检测和利用现代 CPU(如 AVX 和 SIMD)上的高级计算特性。
这就是我们在不牺牲性能的情况下实现跨异构 AI 硬件和平台的可移植性的方法。
下一步是什么
虽然 WasmEdge GGML 工具目前可用(并且确实得到我们的云原生客户使用),但它仍处于早期阶段。如果你有兴趣为开源项目做出贡献并塑造未来大语言模型推理基础设施的方向,那么不妨为以下一些唾手可得的成果进行贡献!
- 为更多硬件和操作系统平台添加 GGML 插件。 Nvidia CUDA 显然是一个重要目标,我们很快就会实现。但我们也对 Linux 和 Windows 上的 TPU、ARM NPU 以及其他专用 AI 芯片感兴趣。
- 支持更多 llama.cpp 配置。我们目前支持将一些配置选项从 Wasm 传递到 GGML 插件。但我们希望支持 GGML 提供的所有选项!
- 支持其他 Wasm 兼容语言的 WASI NN API。我们对 Go、Zig、Kotlin、JavaScript、C 和 C++ 特别感兴趣。
- 支持模型结果中的文本流。可以看到,当前的 WASI NN 标准 API 一次性返回全部推理结果。我们希望创建一个替代方案,可以通过模拟打字机体验,逐个返回字符。
其它 AI 模型
作为轻量级、快速、可移植且安全的 Python 替代品,WasmEdge 和 WASI NN 能够围绕大语言模型以外的流行 AI 模型构建推理应用程序。例如,
边缘轻量级 AI 推理才刚刚开始!
 边缘上的 llama。图片由 Midjourney 生成。
边缘上的 llama。图片由 Midjourney 生成。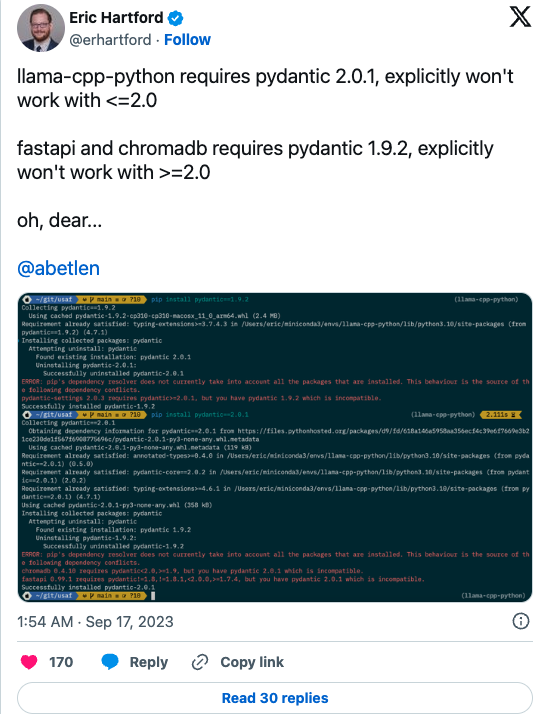 LLM 工具链中常用的 Python 包直接相互冲突。
LLM 工具链中常用的 Python 包直接相互冲突。