行业背景
近年来,随着能源行业数字化的不断推进,智能电网、可再生能源发电、分布式发电、微电网等技术蓬勃发展。越来越多的能源企业意识到数据管理与价值挖掘对储能及能源利用有着重大意义,并开始探索一套有效的数据库解决方案以应对分布式储能的需求。如何实现分布式储能在电网中的规模化聚合,提升电网的运行安全性,同时增强电网对大规模及分布式可再生能源的有效消纳能力,是各大企业关注的重点。
痛点与挑战
1. 数据库管理方案无效
现有数据服务方案不仅难以实现分布式储能的聚合调控,且对大规模、跨区域多点布局的储能系统支持难度大。如何统一纳管能源消纳、储能设备、电池模组状况等关键数据,进而提高数据管理效率和准确性显得尤为重要。
2. 能源数据采集和分析成本高昂
复杂能源场景下,测点多且数据量庞大,随之而来的数据实时采集和存储等高昂成本不可避免;加之,目前市面上构建储能大数据分析能力普遍存在组件繁多、运维困难以及高昂的硬件资源投入成本等问题。这些都在很大程度上影响了企业的方案落地与推进。
3. 函数支撑断层
分布式储能系统中的电池、风机、空调等设备监控缺乏有效的函数支持,导致系统无法准确预测和判断设备的状态与性能,问题难以及时排除、设备无法及时维修。这给系统的稳定性和可靠性带来了不可忽视的风险。
4. 统一可视化监控平台缺失
可视化监控平台缺失可能导致设备监测、数据分析和故障排除等工作开展不畅,进而给业务系统带来严重的管理负担。反之,多维数据看板平台可实现对分布式储能场景的透明化管理,减少对人力看护的需求,从而降低成本投入。
解决方案
![]()
1. 多类型数据管理
KaiwuDB 提供“时序引擎+关系引擎”双能力,分别对储能场景中的传感器数据(温度、湿度等)、电力数据(电池等)、器械控制状态值数据(空调等)等时序数据,以及设备信息、业务数据等关系数据进行统一汇聚与纳管。
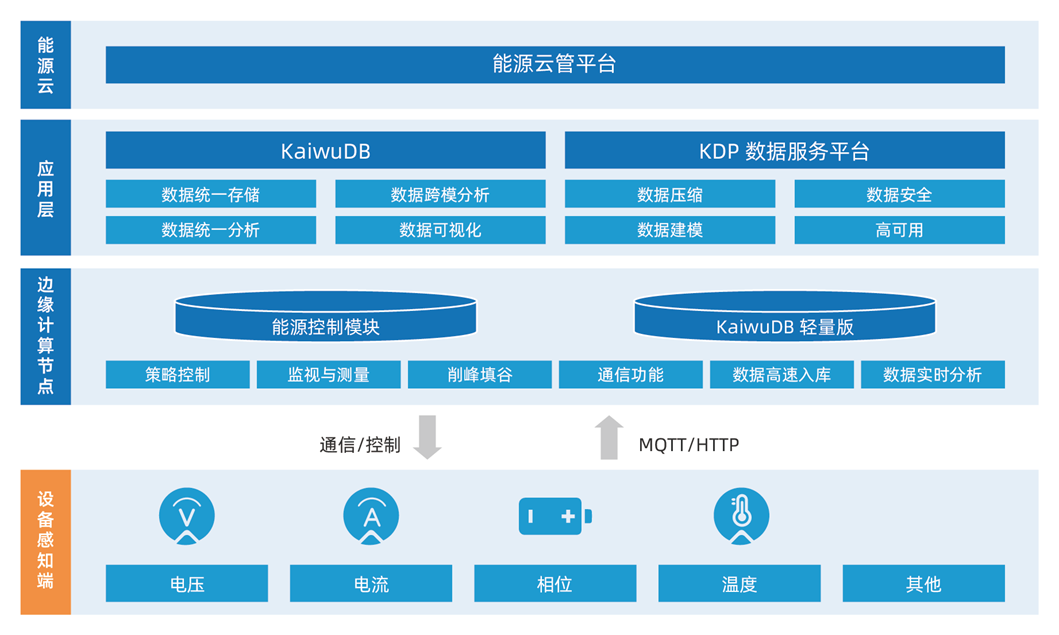
2. 云边端一体化架构模式
方案价值
1. 储能柜对电网的综合调节提升
毫秒级的数据实时查询与分析能力,可降低储能场景的决策时延,提升储能柜对电网的综合调节能力;并可进一步优化削峰填谷、平滑电荷、调频调峰、缓解配电阻塞等,大幅提高能源使用效率。
2. 设备利用率提升
KaiwuDB 跨模计算与分析能力可将生产、设备的时序类数据与设备信息、业务的关系数据进行跨模分析,得出设备的利用率、能效关系等情况,优化设备使用调度,提升设备利用率,延长设备服务寿命。
3. 数据的统一汇聚和纳管能力提升
KaiwuDB 云边端及集群的部署方案,灵活适配了储能系统架构;基于数据订阅发布能力,可实现边缘侧和中心汇聚层同步、全局存储与复杂分析;借助 API 支撑云端应用,完成了数据的统一汇聚和纳管。
4. 数据业务价值提升
通过多类函数,如时间切分类、数据切分类、窗口切分类等,帮助用户搭建业务分析模型,排查电池、空调、能耗等问题;通过流式计算功能,满足实时计算和连续查询的储能分析需求;结合数据发布订阅、API 和 BI 报表功能,实现数据可视化,助力实现全面的业务场景监控。