![file]()
作者 | 李晨
编辑 | Debra Chen
数据准备对于推动有效的自助式分析和数据科学实践至关重要。如今,企业大都知道基于数据的决策是成功数字化转型的关键,但要做出有效的决策,只有可信的数据才能提供帮助,随着数据量和数据源的多样性继续呈指数级增长,要实现这一点愈加困难。
如今,很多公司投入了大量时间和金钱来整合他们的数据。他们使用数据仓库 或数据湖来发现、访问和使用数据,并利用AI推动分析用例。但他们很快意识到,在湖仓中处理大数据仍然具有挑战性。数据准备工具是缺失的组成部分。
什么是数据准备,挑战是什么
数据准备是清理、标准化和丰富原始数据的过程。这使数据准备好应用于高级分析和数据科学用例。准备数据需要执行多项耗时的任务,以便将数据移动到数据仓库或数据湖,包括:
- 数据提取
- 数据清洗
- 数据标准化
- 数据对外服务
- 大规模编排数据同步工作流
除了耗时的数据准备步骤外,数据工程师还需要清理和规范化基础数据,否则,他们将无法理解要分析的数据的上下文,因此通常使用小批量的Excel数据来实现此目的。但这些数据工具有其局限性,首先,Excel无法容纳大型数据集,也不允许您操作数据,更无法为企业流提供可靠的元数据。准备数据集的过程可能需要数周到数月才能完成。调查发现,大量企业花费多达80%的时间准备数据,用来分析数据并提取价值的时间只有区区20%。
翻转 80/20 规则
随着非结构化数据的增长,数据工具在删除、清理和组织数据上花费的时间比以往任何时候都多。数据工程师经常会忽略关键错误、数据不一致和处理结果异常,与此同时,业务用户要求得到数据的时间越来越短,对用于分析的高质量数据的需求却比以往任何时候都大,目前的数据准备方法根本无法满足需求。数据工程师和数据分析师往往花费超过80%的时间查找和准备所需的数据。这样一来,他们只有 20% 的时间用于分析数据并获得业务价值,这种不平衡被称为80/20规则。
那么如何有效扭转80/20规则?对于复杂的数据准备,需要一种敏捷、迭代、协作和自助服务的数据管理方法-DataOps,来帮助企业大幅提升数据准备的效率,将80/20的浪费转变为公司的优势。DataOps平台使IT部门能够为其数据资产提供自助服务功能,并使数据分析师能够更有效的发现合适的数据,同时应用数据质量规则和与他人更好地协作,在更短的时间内交付业务价值。
在正确的时间为数据分析师提供正确的数据意味着可以准备复杂的数据,可以应用数据质量规则,并可以在更短的时间内交付业务价值。有了这些企业级数据准备工具,数据团队和业务团队将会:
- 减少在数据发现和准备上花费的时间,并加速数据分析和AI项目
- 处理存储在数据湖中的大量结构化和非结构化数据集
- 加快模型开发并推动业务价值
- 通过预测性和迭代式分析发现复杂数据中隐藏的价值
白鲸开源如何提供帮助
白鲸开源DataOps平台WhaleStudio提供无代码、敏捷的数据准备和数据协作平台,这样,企业可以更专注于数据科学分析、人工智能(AI)和机器学习(ML)用例。 ![file]()
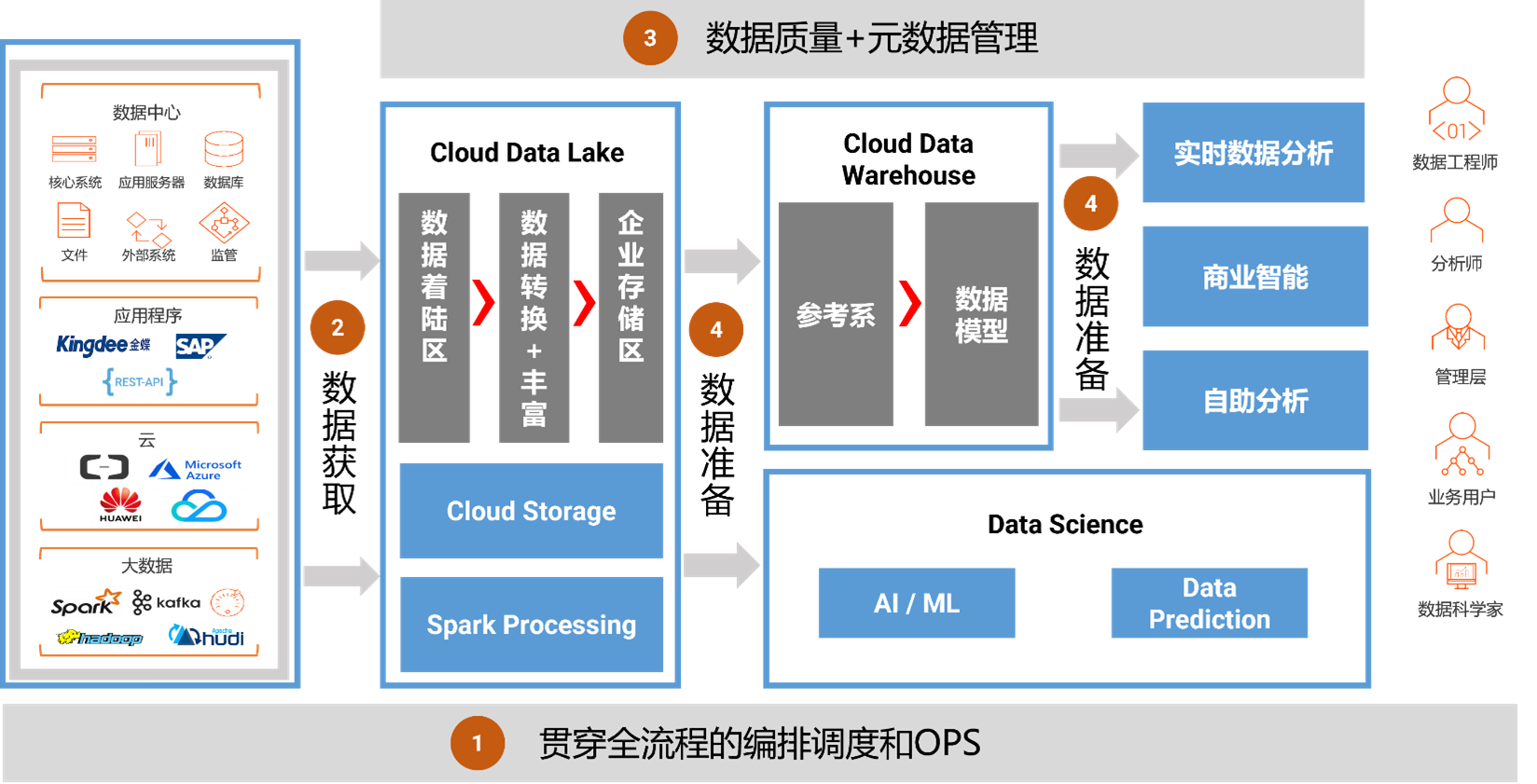
覆盖全流程的编排调度和OPS能力
智能和自动化对于速度、规模、敏捷性至关重要,数据开发的每个步骤都受益于强大的编排和调度能力,这些功能将提高企业处理数据的速度和规模,还能够跨云平台和处理引擎管理各类数据任务。白鲸开源WhaleStudio中的统一调度系统——白鲸调度系统(WhaleScheduler)会帮助您建立数据采集、加工、运维、服务一站式、体系化、规范化的流水线管理模式,通过统一数据编排调度,为数据消费流水线提供服务,让数据能力服务运营过程更加安全、敏捷和智能化。
同时,WhaleStudio基于DataOps最佳实践,为您的环境带来敏捷性、生产力和效率,可以帮助您通过更频繁、更快、更少错误地发布来获取即时反馈。WhaleStudio中的IDE和协同平台为您提供开箱即用的 CI/CD 功能,这些使您能够打破开发、运营和安全方面的孤岛,在整个数据开发生命周期中提供一致的体验。 图片
引入数据
确定处理流程后,需要将数据引入数据湖,通常会先进行数据初始化,将基础数据全量引入湖中,随后从数据源捕获变更数据 (CDC)进行增量加载,以实现实时的数据捕获。
借助白鲸开源WhaleStudio中的数据同步工具WhaleTunnel,开发人员可以自动加载文件、数据库和 CDC 记录,云原生解决方案允许您以任何延迟(批量、增量、准实时、实时),快速引入任何数据。它使用简单,是向导驱动的低代码操作,方便任何人员开箱即用。
确保数据可信和可用
将数据摄取到数据湖后,需要确保数据干净、可信且随时可供使用。白鲸开源的数据集成和数据质量解决方案,使开发人员可以在简单的可视化界面中使用拖拽方式来快速构建、测试和部署数据管道。
构建在白鲸调度系统(WhaleScheduler)中的数据质量模块,提供全方位的数据质量功能,包括数据分析、清理、重复数据删除和数据验证,帮助用户避免“垃圾进垃圾出”的问题,确保数据干净、可信且可用。而白鲸调度系统(WhaleScheduler)中的元数据模块,提供了血缘分析功能,帮助企业快速针对各种数据源和目标的情况进行分析,加快开发人员之间的交接和代码审核效率,进一步确保数据的准确性。
创建高性能数据处理管道
一旦数据进入数据仓库或者数据湖中,数据使用者可能希望进一步对数据集进行切片和分析,则可以继续使用白鲸调度系统(WhaleScheduler)的可视化设计器来构建DAG逻辑。而构建在WhaleTunnel中的数据集成功能,能够使用无代码接口快速构建高性能的端到端数据管道,使开发人员可以轻松地在任何云或本地系统之间移动和同步数据。批流一体的数据同步方式可以完美兼容离线同步、实时同步、全量同步、增量同步等多种场景,这在极大程度上降低了数据集成任务管理的困难。
综上所述,白鲸开源WhaleStudio套件可以帮助企业解决内部多数据源、多数据系统复杂的数据集成,持续开发、持续部署、数据捕获、数据打通等一些列问题,加速数据准备过程,全面提升数据分析和大模型构建的能力。
本文由 白鲸开源科技 提供发布支持!