基于OceanBase 4.x 版本如何统计租户每日 clog 日志生成量的背景下,探究以及如何查看租户 clog 的使用情况。
作者:姜宇
爱可生 DBA 团队成员,擅长数据库故障排查和处理。对技术抱有热忱,实践是检验真理的唯一标准~
本文来源:原创投稿
- 爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
作者:姜宇,爱可生 DBA 团队成员,擅长数据库故障排查和处理。对技术抱有热忱,实践是检验真理的唯一标准~
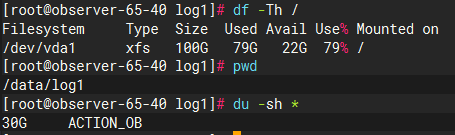
我们知道 clog 目录是存放 OceanBase 数据库记录修改操作的物理日志目录。目录具体的物理存放位置为 /data/log1/clustername/clog。比如,集群 ACTION_OB 的 clog 目录如下图所示:
![]()
OceanBase 4.1.0 版本采用了租户级别的日志流,将物理的变更记录聚合成了组织良好的若干日志流:一个系统日志流和多个用户日志流。系统的所有物理变更信息被记录在这些日志流中,故障恢复、日志归档、备库同步等均使用一套物理变更信息。在一个租户内,一个日志流允许有多个副本,多个副本之间基于 Paxos 协议同步数据。
OceanBase 4.1.0 版本 clog 目录下不再是 OBServer 的 clog 文件,而是新增了一层目录:log_pool 和 tenant_id 两类目录。下面我们分别介绍一下这两类目录的作用。
log_pool 目录
OceanBase 会为每一个 OBServer 节点初始化一个日志预分配池,即为该 OBServer 节点的日志盘总容量 LOG_DISK_CAPACITY,clog 文件默认 64M 一个,log_pool 会根据 log_disk_capacity/64M 预分配所有的 clog 日志文件;它受到集群配置项 log_disk_size 和 log_disk_percentage 共同影响。
- 如果
log_disk_size 的值为 0,且 log_disk_percentage 的值不为 0,则系统以 log_disk_percentage 配置项设置的值分配日志盘空间。
- 如果
log_disk_size 的值不为 0,则无论 log_disk_percentage 的值是否为 0,系统均以 log_disk_size 配置项设置的值分配日志盘空间。
- 如果
log_disk_size 和 log_disk_percentage 的值均为 0,则系统会根据日志和数据是否共用同一磁盘来自动计算 Redo 日志占用其所在磁盘总空间的百分比:
- 共用时,Redo 日志占用其所在磁盘总空间的百分比为 30%。
- 独占时,Redo 日志占用其所在磁盘总空间的百分比为 90%。
log_disk_size 和 log_disk_percentage 默认为 0,如果没有特殊配置的情况下,OBServer 的日志盘总容量使用根据上述第三种情况决定。本地测试环境 OceanBase 日志盘没有划分磁盘,和 OceanBase 数据盘 data 目录共用一个磁盘。所以 OceanBase 日志盘占用其所在磁盘总空间的百分比为 30%,即 30G。
![]()
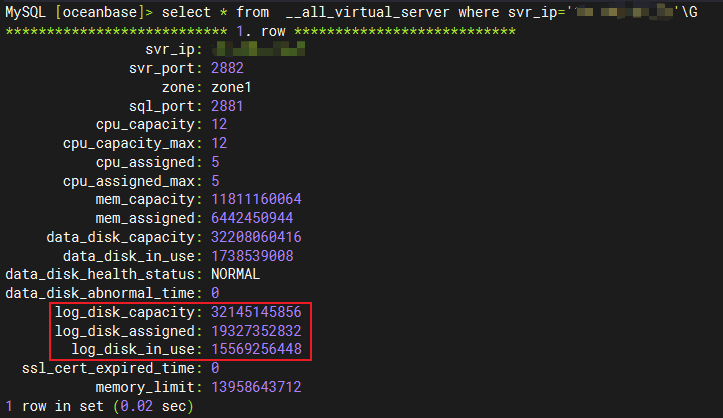
我们可以通过系统表 __all_virtual_server 来查看具体使用情况。其中 log_disk_capacity 即为当前 OBServer 节点的日志盘总容量,大约为 30G 左右。
![]()
那 log_disk_assigened 日志盘分配 和 log_disk_in_use 日志盘使用 又代表了什么意思呢?我们继续向下看。
tenant_id 目录
租户在一个 OBServer 的表现为一个 unit 资源单元,v4 新增 unit_config 属性 LOG_DISK_SIZE(注意和系统参数 log_disk_size 区分),为创建的租户初始化 log_disk_size 大小的 clog 目录空间。具体存放位置就是上边说的 /data/log1/clustername/clog/tenant_id 目录了。根据不同租户的 tenant_id 创建不同租户所属的日志目录。
需要注意的是这部分空间并不是一开始就分配到租户的所属目录下的,而是预占,在租户未使用 clog 文件时,会保留在 log_pool 中,表现为 all_virtual_server 表的 log_disk_assigned 字段。当租户需要写入新的 clog 文件时,OceanBase 才会将 log_pool 中的 clog 文件分配到所属的租户目录下,表现为 all_virtual_server 表的 log_disk_in_use 字段。
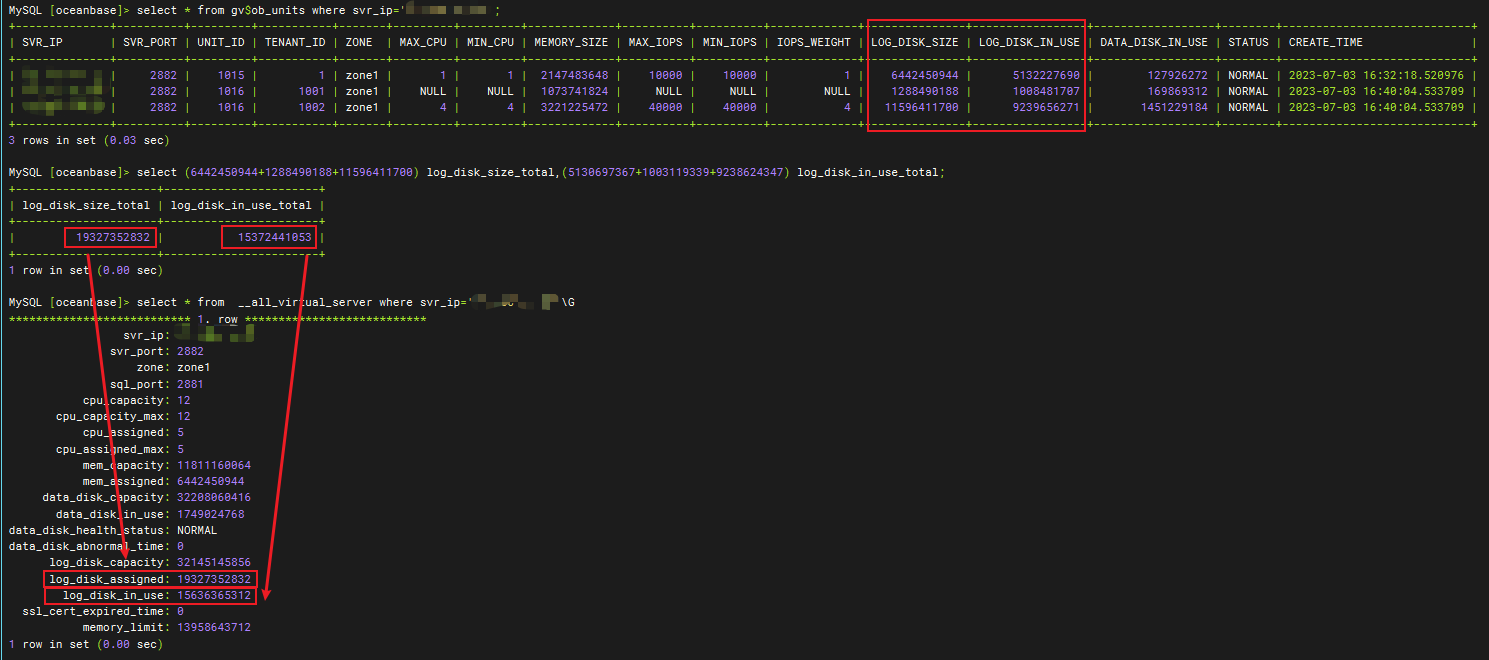
我们可以通过视图 gv$ob_units 查看具体 OBServer 节点的 unit 配置情况:
- log_disk_size:表示某一租户 unit 资源单元的日志磁盘可用的最大容量。
- log_disk_in_use:表示某一租户 unit 资源单元的日志磁盘使用容量。
可以看到下图中,all_virtual_server 的 log_disk_assinged 列对应 gv$ob_units 的 log_disk_size 列值之和,即 OBServer 节点的日志盘是根据租户的unit规格配置来预分配每个租户的日志盘容量的。all_virtual_server 的 log_disk_in_use 列对应 gv$ob_units 的 log_disk_in_use 列值之和,即当租户需要申请新的 clog 文件时,log_pool 才会将 clog 文件分配到租户的日志目录下。
![]()
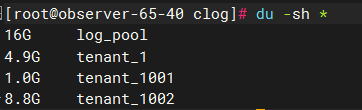
我们也可以通过磁盘目录使用来观察到 log_pool+tenant_id 的目录之和大约是 30G 左右,即 LOG_DISK_CAPACITY=30G;而 tenant_id 目录大小与 gv$ob_units 的 log_disk_in_use 对应;
![]()
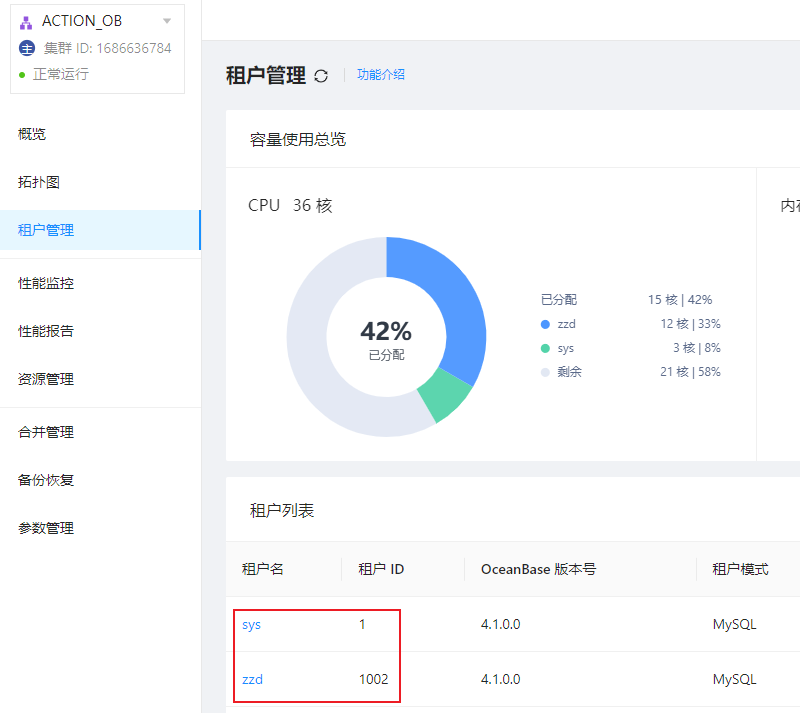
目录空间使用的问题明白后,当我在看 OCP 的集群租户信息时发现,日志盘目录下为什么会多了一个 tenant_1001 的目录呢,这个租户我没有创建过呀,为什么会多了一个租户呢?
![]()
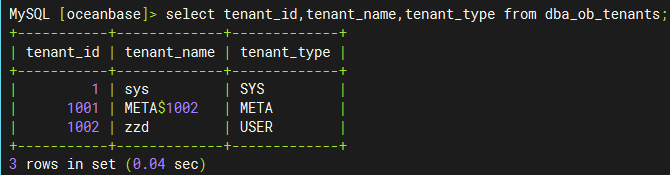
其实 tenant_1001 是 1002 租户的 Meta 租户,从 4.0.0 版本开始,引入了 Meta 租户概念。Meta 租户是 OceanBase 数据库内部自管理的租户,每创建一个用户租户系统就会自动创建一个对应的 Meta 租户,其生命周期与用户租户保持一致。Meta 租户用于存储和管理用户租户的集群私有数据,这部分数据不需要进行跨库物理同步以及物理备份恢复,这些数据包括:配置项、位置信息、副本信息、日志流状态、备份恢复相关信息、合并信息等。Meta 租户不能直接登录。我们可以通过 DBA_OB_TENANTS 视图查看具体的租户信息:
![]()
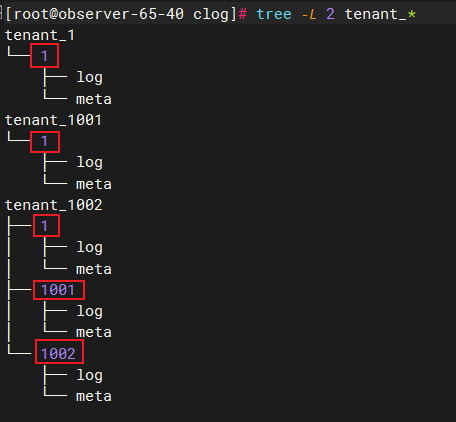
下图中,我们看到tenant_id目录下并不是具体的clog文件,而是又有一层数字id目录,数字id目录下的log目录才是具体存放clog文件的地方,那这些数字id有代表的是什么意思呢,我们继续向下看。
![]()
3、日志流目录
OcenaBase 4.x 版本引入了日志流 和分片的概念。每个分区都有其对应的数据存储对象,称之为分片(Tablet),它具备存储数据的能力,支持在机器之间迁移(transfer),是数据均衡的最小单位。日志流是由 OceanBase 数据库自动创建和管理的实体,它代表了一批数据的集合,包括若干 Tablet 和有序的 Redo 日志流。它通过 Paxos 协议实现了多副本日志同步,保证副本间数据的一致性,实现了数据的高可用。
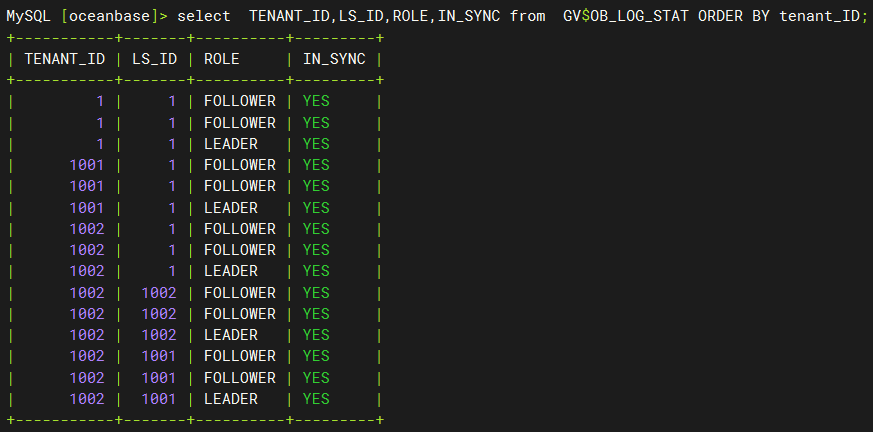
上图中的数字 id 其实就是对应了这里的日志流 id,即 LS_ID。我们可以通过 gv$ob_log_stat 查看租户的日志流 ID。通过下图我们可以看到 tenant_id=1 的租户对应的日志流 id 为 1;tenant_id=1001 的租户对应的日志流 id 为 1;tenant_id=1002 的租户对应的日志流 id 为 1、1001、1002 与上图目录结构一致。
![]()
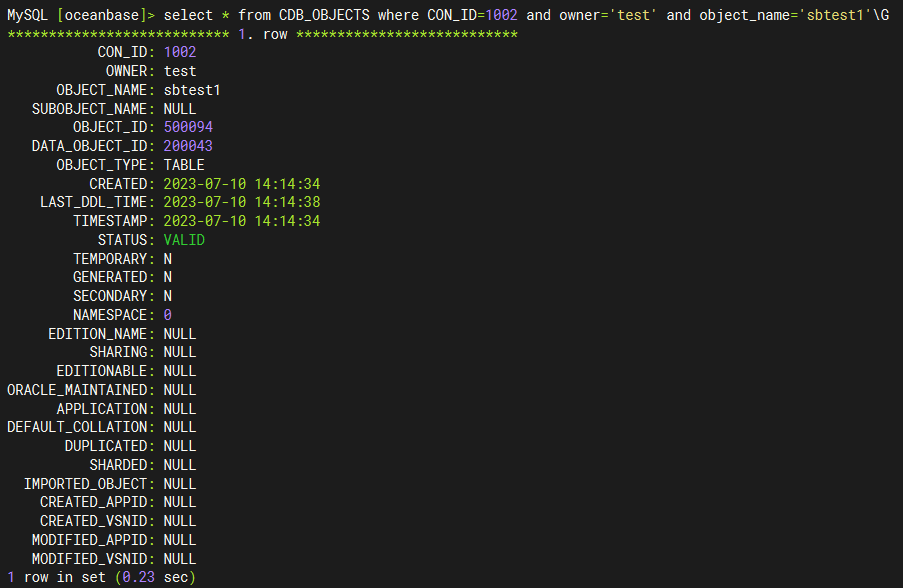
我们也可以通过视图 CDB_OBJECTS 和 CDB_OB_TABLET_TO_LS 查看表分区对应的分片、分片与日志流的映射关系,以及日志流副本的位置信息。比如我们想看 tenant_id=1002 租户的 test 库的 sbtest1 表所在的日志流信息:
- 通过
CDB_OBJECTS 我们可以查询对指定表对应的分片 ID:tablet_id(DATA_OBJECT_ID)
![]()
- 通过
CDB_OB_TABLET_TO_LS 我们可以查询到指定分片的日志流 ID:LS_ID。
![]()
clog 磁盘使用控制
租户可使用的 clog 磁盘容量是有限度的,当租户 unit 的 clog 日志容量使用比例(log_disk_in_use/log_disk_size*100%)达到指定阈值(log_disk_utilization_threshold,默认为 80%,不可修改)后,不会再向 log_pool 申请 clog 文件,而是直接复用最老的 clog 文件。
可以看到下图中租户的 clog 磁盘使用率也符合预期值。
![]()
clog 的使用量统计
在知道了 clog 目录结构之后,我们就可以通过计算租户目录下 clog 文件的生成量来统计租户每小时、每天的日志生成量,可以用于预估 OceanBase 备份盘的使用量。
#统计租户 clog 的生成量
--每小时
find $clog_dir/tenant_$tenant_id/ -type f -regex '.*/[0-9]+' -exec stat --format="%y" {} \; |cut -d ':' -f 1|sort|uniq -c|awk -F ' ' '{print $2" | "$3" | "$1" | "$1*64/1024 "G"}'
--每天
find tenant_1001/ -type f -regex '.*/[0-9]+' -exec stat --format="%y" {} \; |cut -d ' ' -f 1|sort|uniq -c|awk -F ' ' '{print $2" | "$3" | "$1" | "$1*64/1024 "G"}'
# 统计租户 data 数据大小
select tenant_id,svr_ip,sum(required_size/1024/1024/1024) from CDB_OB_TABLET_REPLICAS group by tenant_id,svr_ip,svr_port;
#!/usr/bin/bash
clog_dir=/data/log1/ACTION_OB/clog
echo "-- 检查时间:`date "+%Y-%m-%d %H:%M:%S"` --"
echo "+++++++++++++++++++++++++++++++++++++++++++++++++++"
echo "log_pool剩余clog文件数量: `ls -l $clog_dir/log_pool/|grep -v meta|wc -l`"
echo "log_pool剩余空间: $(echo "scale=2;`ls -l $clog_dir/log_pool/|grep -v meta|wc -l` * 64 / 1024 "|bc) G"
for tenant_id in `ls $clog_dir|grep "tenant_*"|awk -F '_' '{print $2}'`
do
echo "+++++++++++++++++++++++++++++++++++++++++++++++++++"
echo "$tenant_id 租户当前clog文件数量: `find $clog_dir/tenant_$tenant_id/* -regex '.*/[0-9]+' -type f |wc -l`"
echo "$tenant_id 租户当前clog文件总大小: $(echo "scale=2;`find $clog_dir/tenant_$tenant_id/* -regex '.*/[0-9]+' -type f |wc -l` * 64 / 1024 "|bc) G"
echo -e "$tenant_id 租户clog按照天统计:(YYYY-mm-dd|file_num|count_size)\n`find $clog_dir/tenant_$tenant_id/ -type f -regex '.*/[0-9]+' -exec stat --format="%y" {} \; |cut -d ' ' -f 1|sort|uniq -c|awk -F ' ' '{print $2" | "$1" | "$1*64/1024 "G"}'`"
done
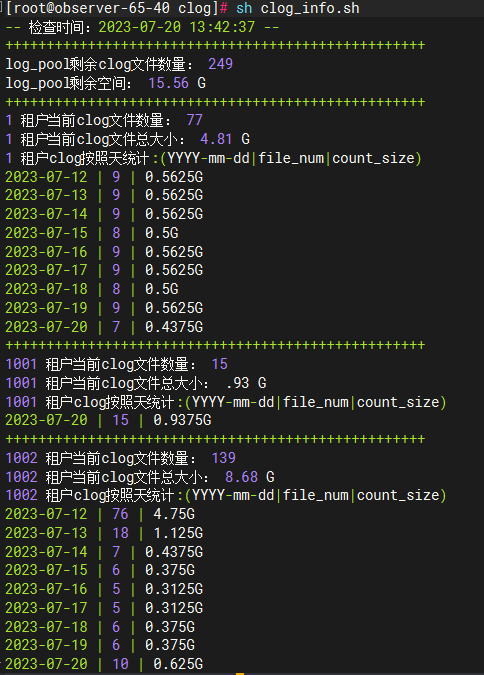
脚本执行结果如下图所示:
![]()
更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
爱可生开源社区的 SQLE 是一款面向数据库使用者和管理者,支持多场景审核,支持标准化上线流程,原生支持 MySQL 审核且数据库类型可扩展的 SQL 审核工具。
SQLE 获取