![]()
Apache Celeborn(Incubating)[1] [2] 是阿里云开源的大数据计算引擎通用 Remote Shuffle Service,旨在提升 Shuffle 的性能/稳定性/弹性,目前已广泛运行在包含阿里在内的多家企业,每天服务着生产环境数十P的 Shuffle 数据,可稳定支撑单 Shuffle 超 600T 的大作业。
Apache Celeborn(Incubating)是个开放、活跃、多元的社区(https://github.com/apache/incubator-celeborn),有着来自不同国家、不同公司和组织的开发者和用户,欢迎更多的开发者/用户加入~
本文介绍 Celeborn 新发布的 0.3.0 版本的重要 Feature,包括但不限于:支持 Flink,支持 Native Spark(Gluten),快速优雅升级,支持 HDFS 等。Celeborn 0.3.0 相比 0.2.1 新增了480+ Commits, Resolve 了 470 个 Jira Issue,在功能/稳定性/性能上都有较大提升。
Flink 支持
MapPartition
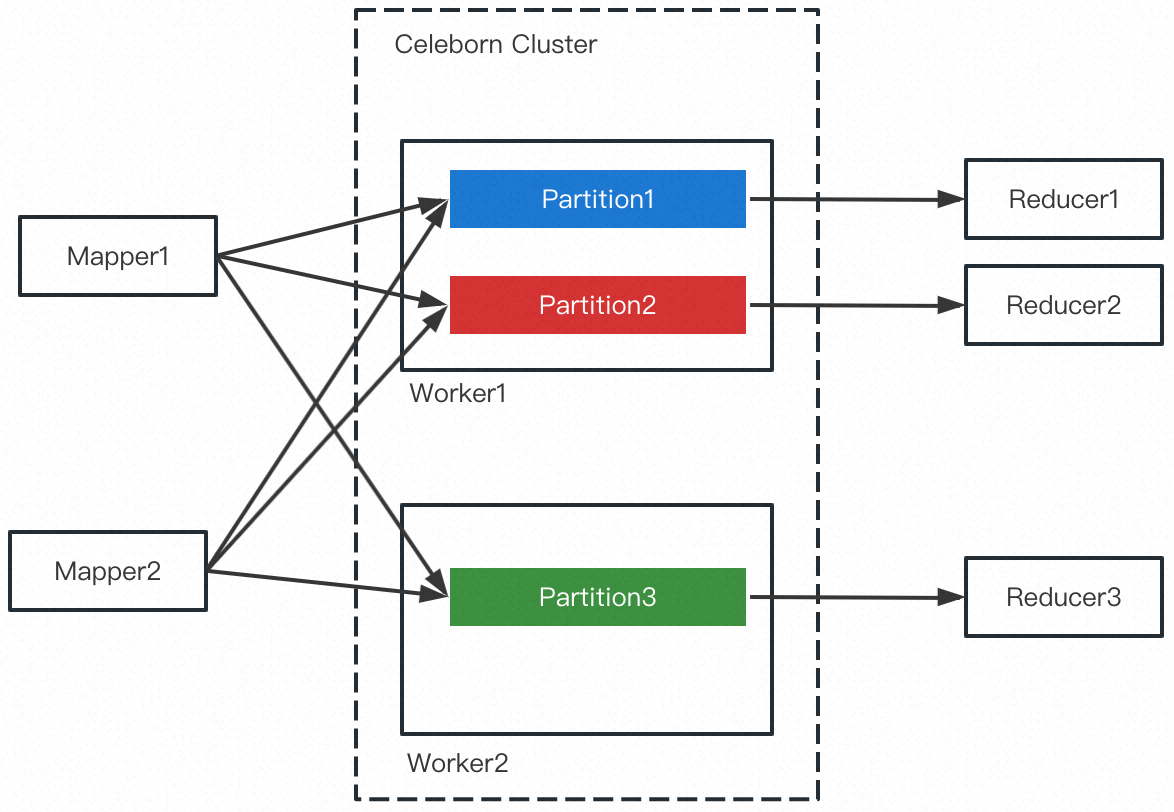
熟悉 RemoteShuffleService(简称 RSS)的同学知道,Push Shuffle + Reduce Partition 数据聚合是 RSS 的核心设计,如下图所示:
![1]()
RSS 把属于同一Reduce Partition 的数据聚合为一个(或多个)大粒度文件,因此 Reducer 在 Shuffle Read 时的网络效率和磁盘 IO 效率都能大幅度提高,这也是 RSS 提升作业的性能和稳定性的关键。此外,由于 Shuffle 数据推给 RSS,引擎的计算节点变得“无状态”,因此能更好的拥抱存算分离/弹性的云原生架构。
如大多数设计一样,Reduce Partition 的设计也有其 TradeOff:
- 重算代价高。通常情况下,上游所有 Mapper 都会往某个 Reduce Partition 文件推送数据,当文件丢失时需要重算上游所有的 Task。尽管 Celeborn 的多副本机制可以降低数据丢失的概率,但可能性依然存在。
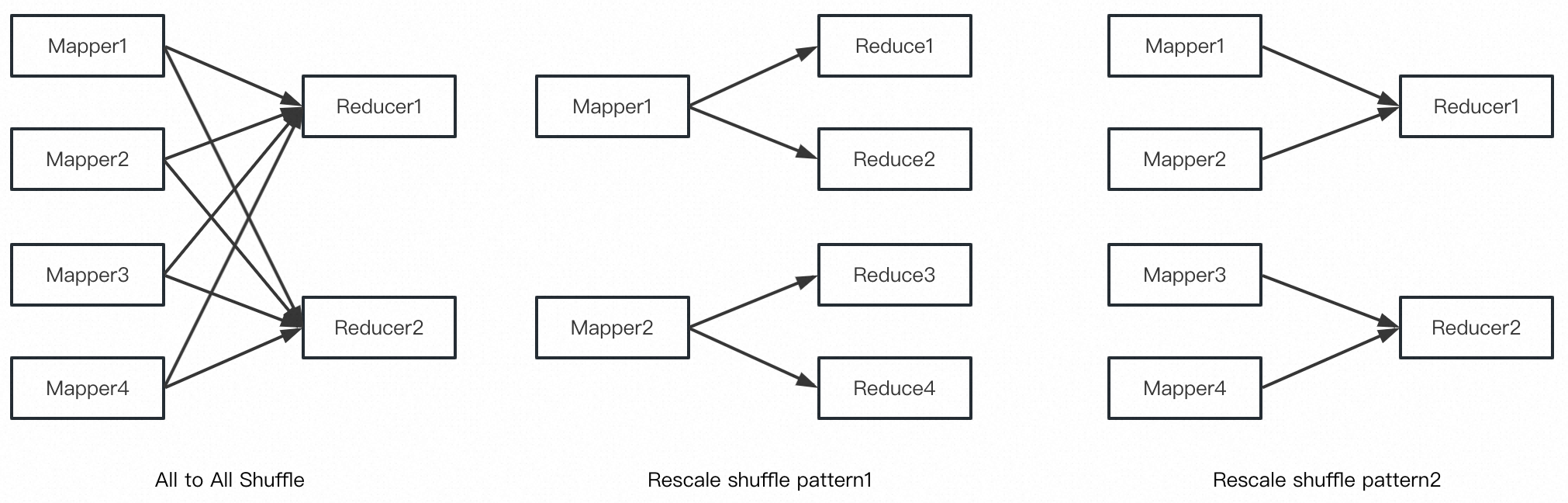
- 只支持 All-to-All 和 Forward 类型的 Shuffle,难以支持 Rescale 类型的 Shuffle。All-to-All 和 Rescale 的 Shuffle 类型如下图所示:
![2]()
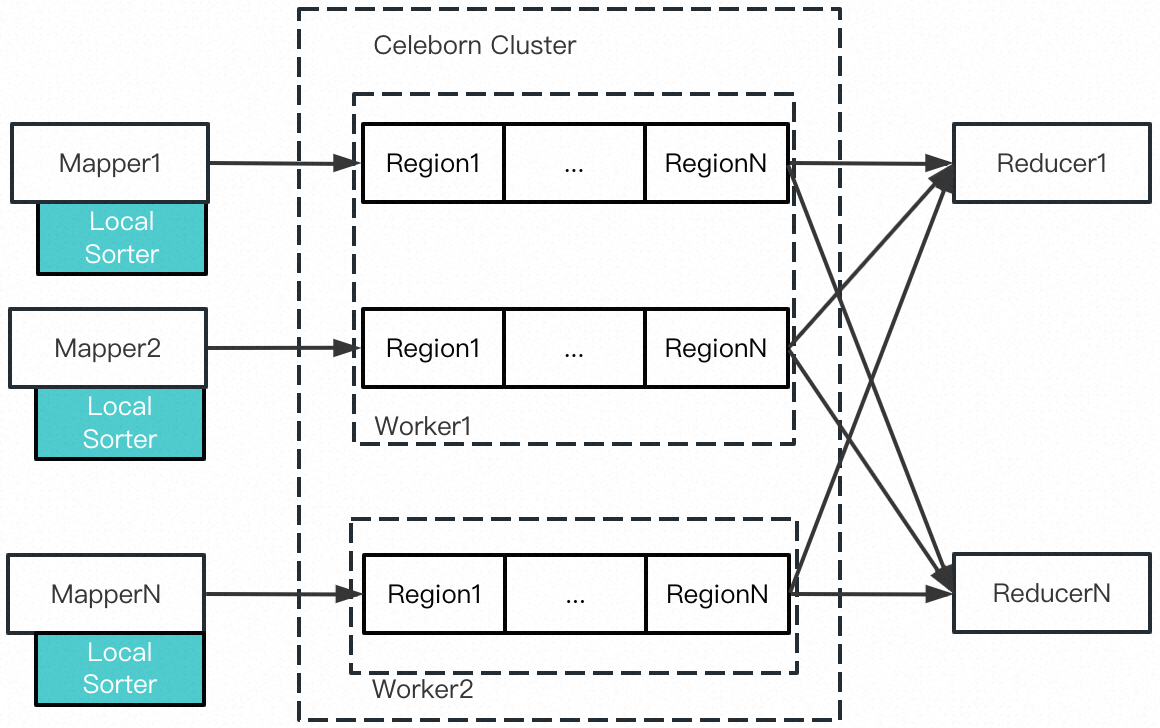
为了更好的支持 Flink(新引入 Rescale 和 Forward 两种 Shuffle 类型),以及满足更小代价的重算代价,Celeborn0.3.0 支持了 MapPartition 的 Shuffle 类型。顾名思义,Map Partition 的文件保存的是来自 Map Task 的 Shuffle 数据,但不同于传统的本地 Shuffle,Celeborn 的 MapPartition 引入了 Sorted Region 和 IO Scheduling 来提升 IO 效率。MapPartition 的整体设计如下图所示:
![3]()
Mapper 本地的 LocalSorter 在内存缓存特定大小的 Shuffle 数据(称为 Region,默认64M),达到阈值后对该 Region 的数据根据 Reducer PartitionId 做排序,然后推送给预先分配的 Celeborn Worker,Worker 接收/持久化/索引数据。MapPartition 的某个 Region 的数据布局如下所示:
![4]()
尽管 Region 内数据按照 Reduce PartitionId 做了排序,但由于来自不同 Reducer 的 Shuffle Read 的请求是随机的,依然无法做到顺序读盘。为了缓解随机 IO,Celeborn 引入了 IO Scheduling 的机制,对当前 IO 请求按照访问文件的 Offset 做排序,尽量把随机读转变为顺序读,如下图所示:
![5]()
IO Scheduling 的优化只能做到尽力而为,假如当前的请求大部分不连续则无法生效。根据生产经验,Flink Batch 的并发通常不大(<2000),在资源充裕的情况下下游的 Reduce Task 能同时调度起来,那么就有较大概率可以合并 IO 请求。
目前 Flink/Spark 分别只支持 MapPartition/ReducePartition,社区后续会对 Flink 引入 ReducePartition,并根据需求判断是否对 Spark 引入 MapPartition。
Credit-Based Shuffle Read
由于有了 MapPartition,Celeborn0.3.0 很自然的支持了 Flink。此外,为了让 Shuffle Read 的数据也由 Flink 的 Memory Manager 来管理,Celeborn0.3.0 支持了 Credit-Based Shuffle Read。简单来说,首先 Celeborn Worker 通知 Client 当前可读取的数据片数量(Backlog),Flink TaskManager 一旦有空余的内存 Buffer 便发送给 Worker 对应的 Credit,Worker 消耗一个 Credit 并发送一个数据片。流程如下图所示:
![6]()
生产案例
Celeborn 支持 Flink 已经得到生产作业的验证。在阿里内部,Celeborn 承接的最大 Flink Batch 作业单 Shuffle 超过 600T。
Apache Celeborn 对 Flink 的支持得到了 flink-remote-shuffle 社区 [3] 的大力支持,很多设计也源于 flink-remote-shuffle 项目。
Native Spark 支持
Gluten Columnar Shuffle
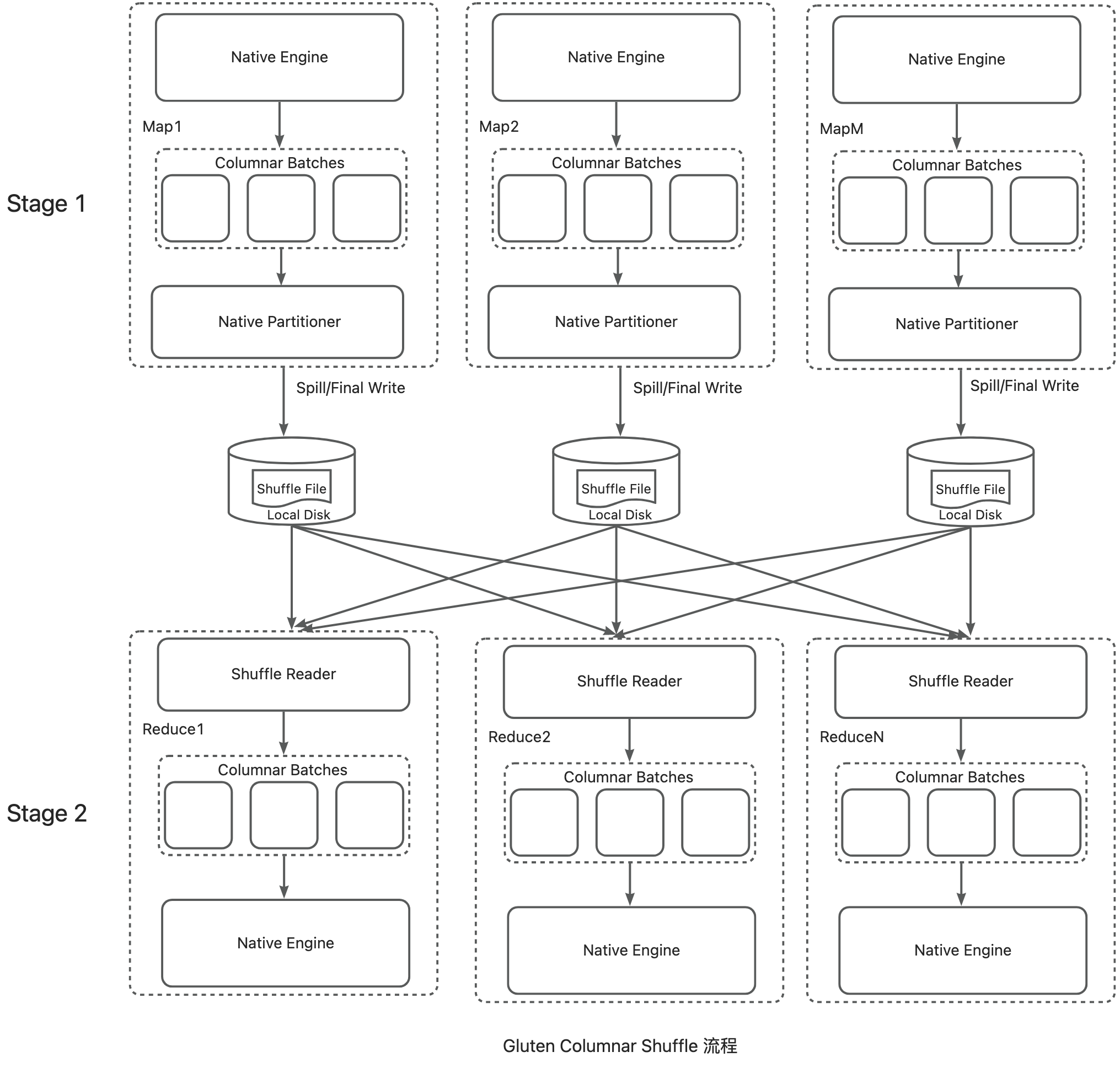
Gluten [4] 是 Intel 开源的引擎加速项目,旨在通过把 Spark Java Engine 替换为 Native Engine(Velox, ClickHouse, DataFusion等)来加速 Spark 引擎。Gluten 的核心能力包括 Plan 转换,统一内存管理,Columnar Shuffle 等。Gluten 的 Columnar Shuffle 通过 Hash-based Shuffle/Native Partitioner/零拷贝等设计获得相比于原生 Row-Based Shuffle 12%的性能提升,其主要流程如下图所示:
![7]()
Gluten Columnar Shuffle 做了诸多优化,但由于其沿用了 Spark 的本地 Shuffle 框架,故存在以下主要限制。
- 依赖大容量本地盘存储 Shuffle 数据,一方面无法应用存算分离架构,另一方面计算节点“有状态”无法及时缩容,从而导致资源利用率低。
- Shuffle Write 内存紧张时 Spill 到磁盘,增加额外的磁盘 I/O。
- Shuffle Read 有大量的网络连接和大量磁盘随机读,导致较差的稳定性和性能。
Gluten 集成 Celeborn
过去一段时间,Gluten 社区和 Celeborn 社区相互合作,成功把 Celeborn 集成进 Gluten。Gluten 集成 Celeborn 的设计目标是同时保留 Gluten Columnar Shuffle 和 Celeborn Remote Shuffle 的核心设计,让两者的优势叠加,如下图所示:
![8]()
整体来说,Shuffle Writer 复用 Native Partitioner,拦截本地 IO 并改为推向 Celeborn 集群;Celeborn 集群做数据重组(聚合相同 Partition的数据)和多备份;Shuffle Reader 从特定 Celeborn Worker 上顺序读取数据并反序列化为 Column Batch。这个设计不仅保留了 Gluten Columnar Shuffle 的高性能设计,又充分利用了 Celeborn 远端存储、数据重组和多副本的能力。
性能测试
Celeborn 在磁盘资源受限时有最好的性能表现。针对 Gluten + Celeborn 我们测试了三组硬件环境:SSD 环境,充分 HDD 环境,有限 HDD 环境。整体结论是:在 SSD 环境,Gluten + Celeborn Columnar Shuffle 性能跟 Gluten 本地 Columnar Shuffle 持平;在充分 HDD 和有限 HDD 环境,Gluten + Celeborn Columnar Shuffle 性能比 Gluten 本地 Columnar Shuffle 分别提升 8%和 12%。
快速优雅升级
快速优雅升级是 Celeborn 的重要目标,包含两层需求:
-
升级不影响正在运行的作业;
-
升级的过程要快,不受长尾作业的影响。
大部分系统可以实现 1,常见的策略是给一个优雅下线的时间窗口,超时强制重启;但 2 比较难以实现。Celeborn 通过独有的 Hard Split 机制可以很顺畅的实现 2,测试中当前 Worker 有正在运行的作业的情况下升级 Worker 的耗时小于 1 分钟。
Partition Split 机制
为了更好的容错,Celeborn 从一开始就引入了 Partition Split 机制。概括的说,作业运行的过程中,在某些特定情况下,Partition 的数据可以“分裂”为多个 Partition Split,以实现更高的稳定性和灵活性。特定情况包括:
- Partition 文件超过预设阈值;
- Worker 磁盘容量即将不足;
- Worker 处于优雅下线状态;
- 推送数据失败;
Partition Split 触发 Partition Split 的流程如下图所示(推送数据失败的流程略有不同):
![9]()
Partition Split 支持 Soft 和 Hard 两种模式,Soft 表示旧的 Split 依然可以接收数据直到所有的 Mapper 都收到新的 Partition Location 信息;Hard 表示旧的 Split 不再接收新的数据。快速优雅升级依赖的是 Hard Split。
快速优雅升级
依托 Hard Split 机制,Celeborn 可以很顺畅的实现快速优雅升级。在触发优雅下线之后, Worker 立即通知 Master 并把自己置为 Graceful Shutdown 状态,Master 不再向该 Worker 分配新的负载。此后发给 Worker 的 PushData 的 Response 都会带上 Hard_Split 的标记,促使 Client 终止向该 Worker 继续推送数据。接下来 Client 将发送 CommitFiles 给该 Worker,触发内存数据刷盘。在内存数据完成刷盘之后,Worker 把本地的 Partition 信息存入 leveldb,此时该 Worker 达到了干净的状态:
- 不会有新的 Partition 分配到该 Worker;
- 本地所有 Partition 数据都已写文件;
- 本地所有 Partition 信息都已存入 leveldb;
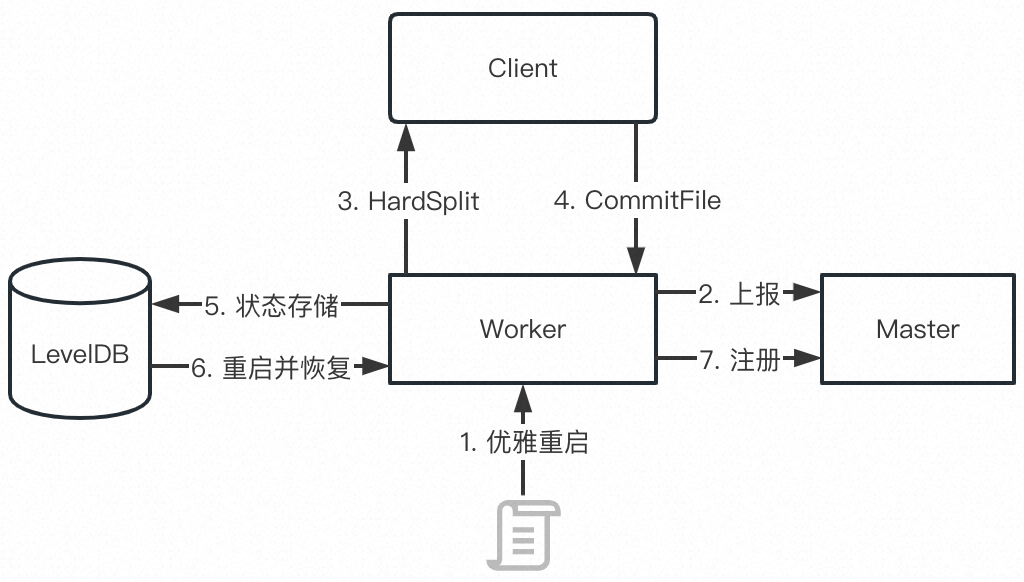
此时 Worker 退出进程并等待重启。重启之后,Worker 从 leveldb 中恢复状态,可以正常服务本地 Shuffle 数据的读取请求,以及接收新的 Shuffle Write。整体流程如下图所示:
![10]()
注意:优雅升级需要 Worker 节点绑定固定的地址和端口,否则重启后的 Worker 将会被视作新加入的节点,而无法提供停机前的数据。在 Kubernetes 上,Celeborn 默认使用 StatefulSet 部署,重启后 Pod IP 会发生变化,如要达成该要求,需要 Worker 绑定 FQDN 而非 IP,更多详情请参考 CELEBORN-713。
生产案例
Celeborn 的某位用户分 10 批升级集群,每批升级 100 个 Worker,在不影响作业运行的情况下,每批升级耗时 2 分钟。
多层存储: HDFS
![11]()
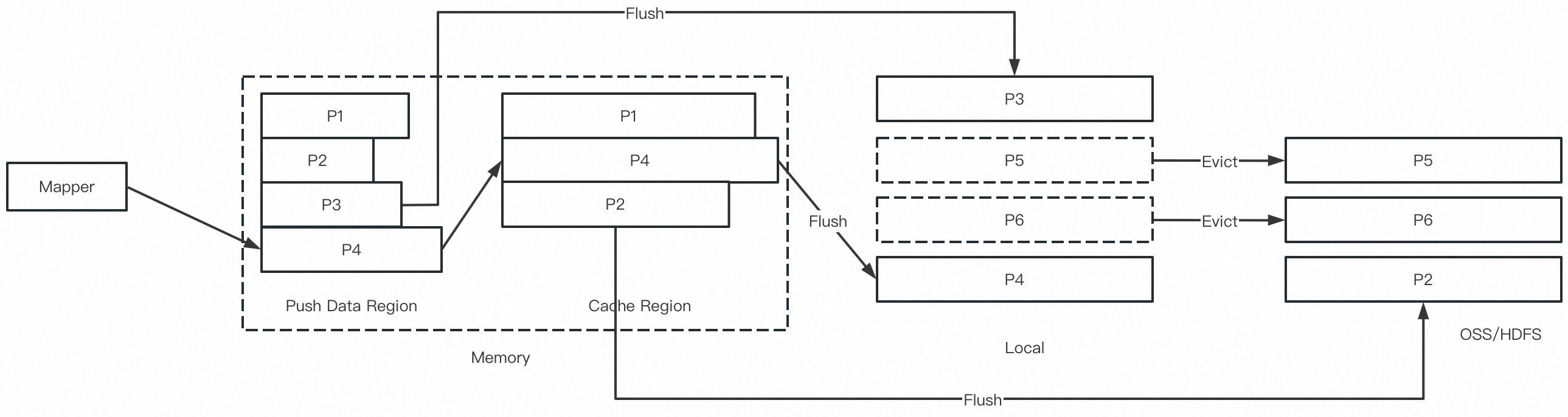
Celeborn Worker 多层存储的设计目标是支持内存/本地盘/分布式存储三层灵活配置(任选 1-3 层),尽量让数据存放在更快的设备中,从而适配不同的硬件环境,并对小作业更加友好。0.3.0 正式支持了本地盘 + HDFS,用户可以选择只用本地盘/只用 HDFS/同时使用本地盘+HDFS 三种组合。在本地盘和 HDFS 同时存在时,优先使用本地盘。
Celeborn Worker 在初始化 Partition 时,若发现无可用本地盘,则创建 HDFS 文件,后续该 Partition 的数据将写入该文件。若 Partition 发生分裂,则下一个 Split 存在哪层介质由其所分配的 Worker 的状态决定。因此,同一个 Partition 的不同 Split 可能存储在不同介质中,同一个 Partition Split 的主从副本也可能存储在不同介质中。Celeborn 的 HDFS 介质默认使用两副本,当 Partition Split 的主从都存在 HDFS 时,为了避免空间冗余,其中一副本会被删除。
HDFS 介质的多副本并不能代替 Celeborn 的主从副本,因为一旦 HDFS 的某次写入崩溃,则整个文件都将不可用,而 Celeborn 的主从副本只要有一个 Commit 成功,则意味着至少有一份数据可用。
多级黑名单
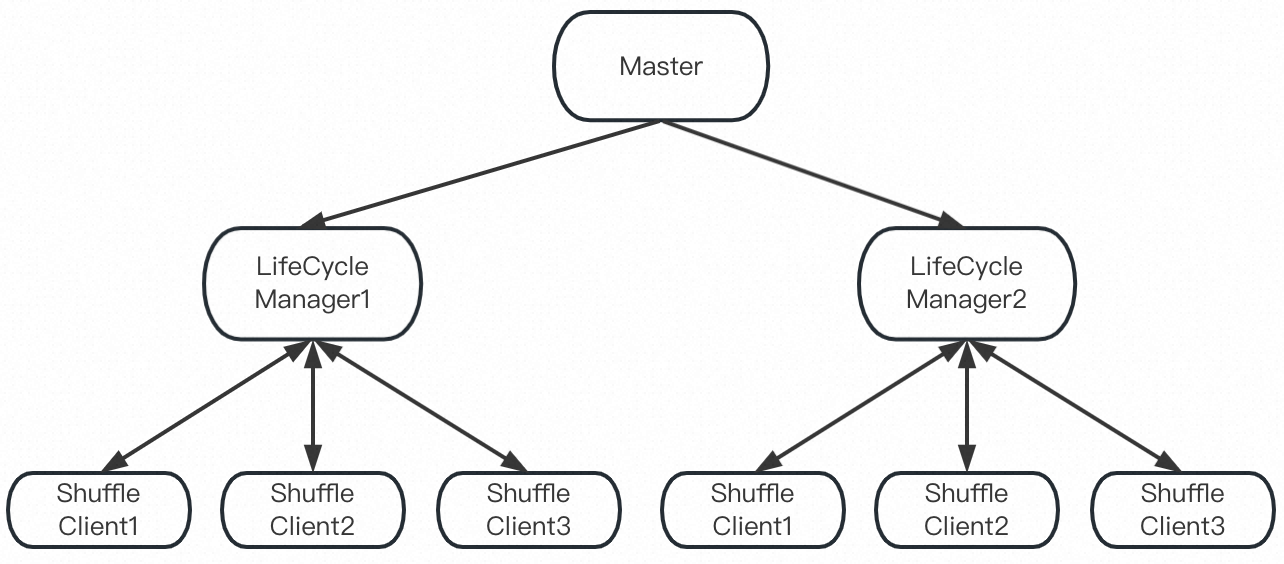
在大规模部署的环境中,Worker(暂时)不可用是常见现象,让 Celeborn 的所有组件(Master, LifecycleManager, ShuffleClient)及时准确知道 Worker 状态对作业的稳定性和性能至关重要。为了实现这一目标,Celeborn 设计了多级黑名单的机制。
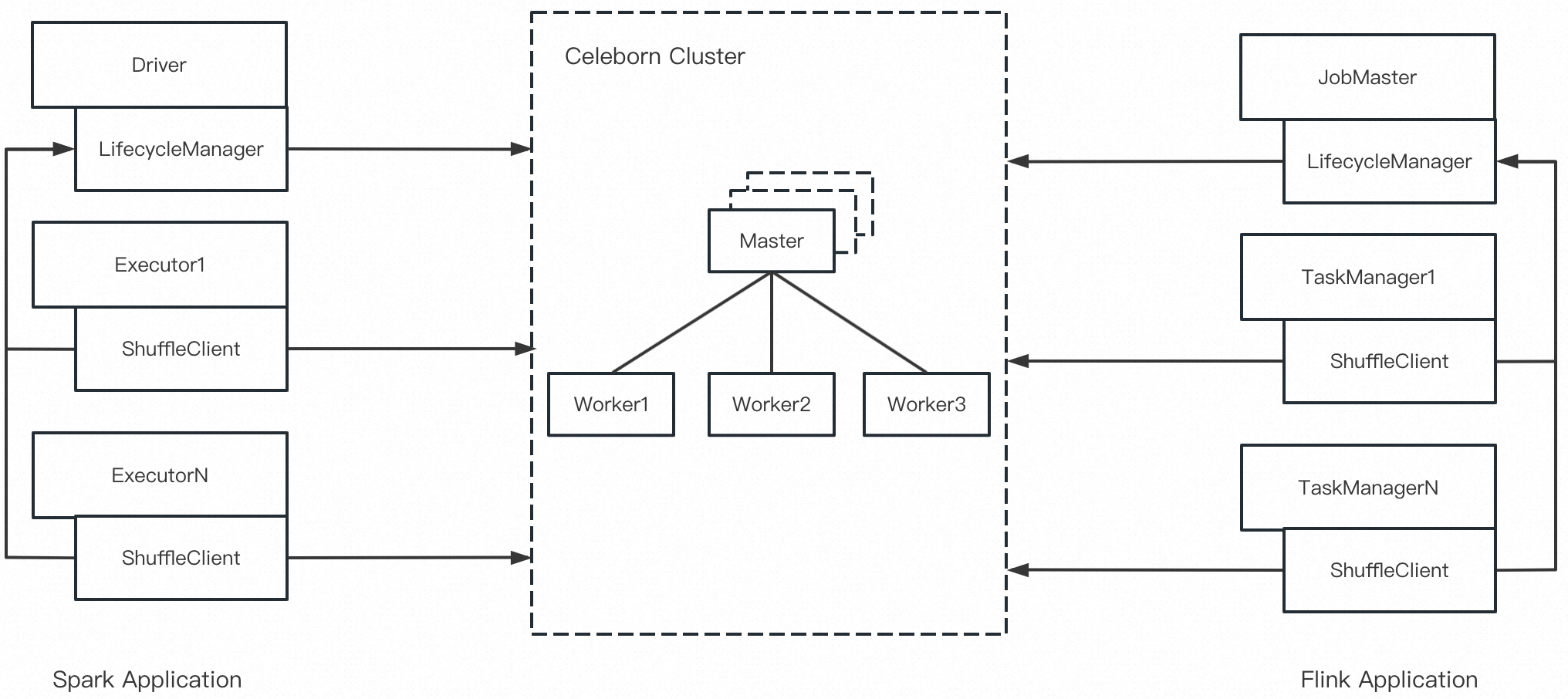
在 Celeborn 的架构里,Master 负责管理 Celeborn 集群的状态,整个集群只有一个 Active 实例;LifecycleManager 负责管理 Application 的 Shuffle 状态,每个 Application 有一个实例;ShuffleClient 存在于计算引擎的调度单元里(i.e. Spark 的 Executor,Flink 的TaskManager),每个容器进程有一个实例。示意图如下:
![12]()
ShuffleClient 跟 Worker 的交互最为高频,因此最早感知 Worker 是否可用,但其感知不一定准确,因为网络抖动/CPU 高负载都可能导致 PushData 失败;而 Master 的感知最晚(Worker 心跳汇报状态),但其信息最为准确;LifecycleManager 的延迟和准确性介于两者之间。基于这个观察,Celeborn 设计了多级黑名单,如下图所示:
![13]()
具体而言,一旦发生跟 Worker 的交互失败,ShuffleClient/LifecycleManager 会加入本地黑名单,同时 ShuffleClient 会汇报给 LifecycleManager;LifecycleManager 跟 Master 的心跳返回会把 Master 的黑名单加入 LifecycleManager 的黑名单;LifecycleManager 的黑名单通过 RPC 成功以及黑名单超时删除;ShuffleClient 跟 LifecycleManager 的交互会刷新 ShuffleClient 的黑名单。
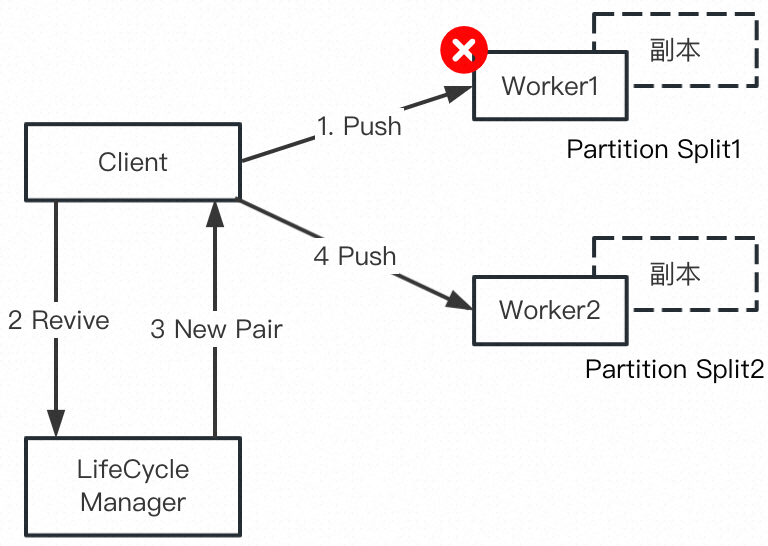
Batch Revive
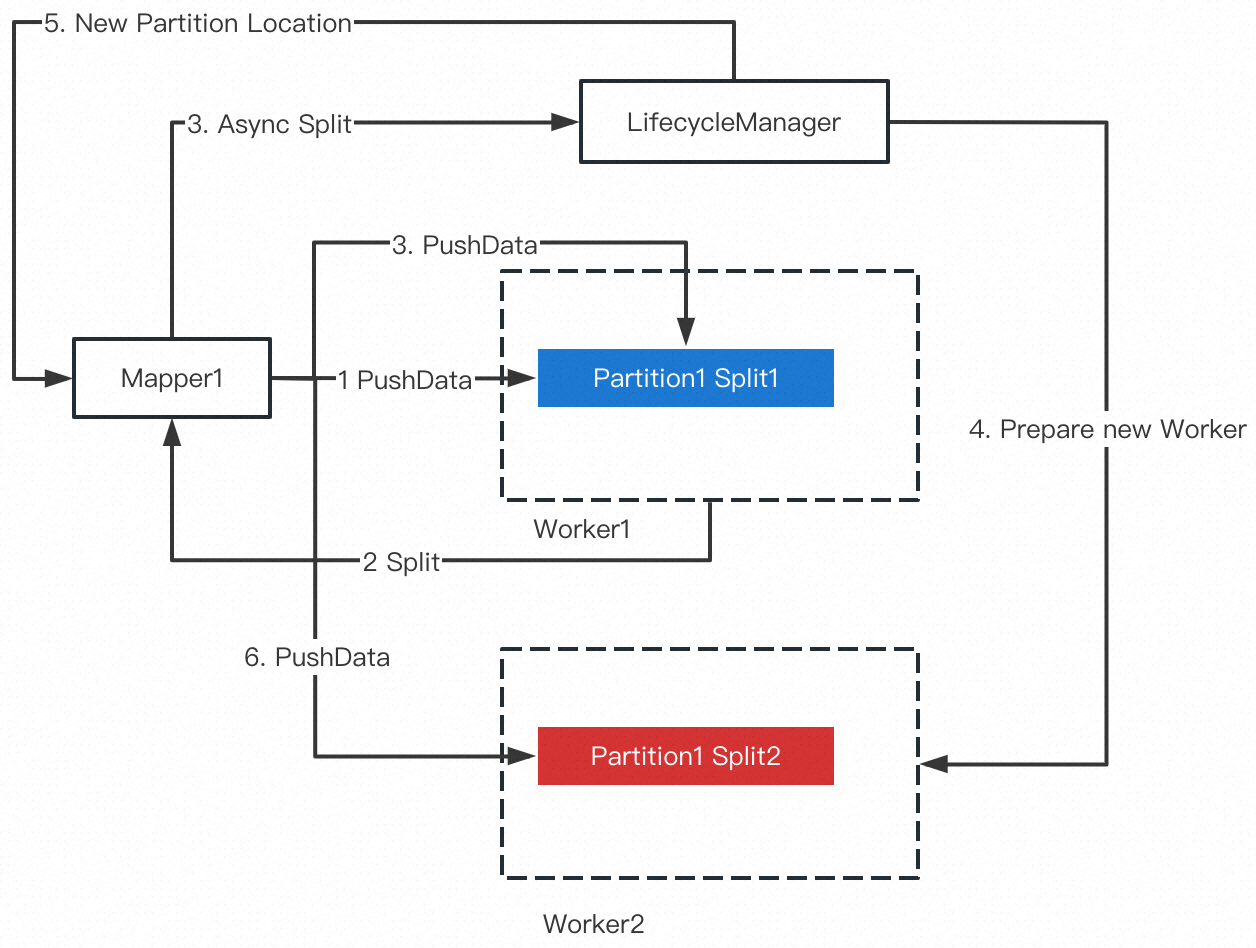
作为最重要的容错机制之一,Celeborn ShuffleClient 在发生 PushData 失败时会触发 Revive,LifecycleManager 重新选择一对 Worker,同时当前 Partition 发生一次分裂,如下图所示:
![14]()
Revive 机制可以很好的处理 Worker 状态不稳定的事件,不会因为少量 Worker 失败/网络抖动/CPU 短暂高负载导致 Task 失败。然而,当前的 Revive机制会对 LifecycleManager产生大量的 RPC 请求,极端情况可能会导致 Driver OOM。为了缓解这个问题,Celeborn0.3.0 引入了 Batch Revive 优化,即 ShuffleClient 缓存若干 Revive 请求后一并发给 LifecycleManager,如下图所示:
![15]()
在 3T TPCDS Q23a 的测试中,Batch Revive 优化可以把发给 LifecycleManager 的 RPC 数量从 6.4w降到 2.6k。
And More
测试
我们针对 0.3.0 做了稳定性、兼容性、性能三方面的测试。
优雅重启
三台 Worker,开启 Graceful Shutdown,在作业运行的过程中依次重启三台 Worker,作业不受影响正常跑完,每台 Worker 的重启时间在 25s 左右。
Client 端开启异常节点拉黑:
spark.celeborn.client.push.excludeWorkerOnFailure.enabled=true
spark.celeborn.client.fetch.excludeWorkerOnFailure.enabled=true
Worker 端开启优雅重启:
celeborn.worker.graceful.shutdown.enabled=true
celeborn.worker.push.port=9092
celeborn.worker.fetch.port=9093
celeborn.worker.rpc.port=9094
celeborn.worker.replicate.port=9095
Worker1 在 19 分 44 秒收到 Shutdown 信号:
23/07/17 21:19:44,135 INFO [shutdown-hook-0] Worker: Shutdown hook called.
在 19 分 53s 完成优雅下线并退出进程:
23/07/17 21:19:53,225 INFO [shutdown-hook-0] Worker: Worker is stopped.
在 20 分 01s 完成重启和注册:
23/07/17 21:20:01,171 INFO [main] Worker: Register worker successfully.
Spark 作业无 task 失败,且总时间无显著变慢:
![16]()
兼容性测试
Celeborn 保持跨版本之间的兼容性,即相邻两个版本,新版本的服务端兼容老版本的客户端,从而大幅简化升级过程。
在本次测试中使用 0.2.1 版本的 Client 和 0.3.0 的服务端,作业可正常运行:
![17]()
性能测试
硬件环境
Celeborn 部署在 Yarn 集群上,每个 Worker 最大使用 20g 内存,不额外引入机器资源。硬件环境如下:
Spark 版本 3.3.1
Celeborn Worker 端配置
# celeborn-env.sh
export CELEBORN_MASTER_MEMORY=4g
export CELEBORN_WORKER_MEMORY=4g
export CELEBORN_WORKER_OFFHEAP_MEMORY=12g
# celeborn-defaults.conf
celeborn.metrics.enabled=false
celeborn.replicate.io.numConnectionsPerPeer=24
celeborn.application.heartbeat.timeout=120s
celeborn.worker.storage.dirs=/mnt/disk1,/mnt/disk2,/mnt/disk3,/mnt/disk4,/mnt/disk5,/mnt/disk6,/mnt/disk7,/mnt/disk8
celeborn.network.timeout=2000s
celeborn.ha.enabled=false
celeborn.worker.closeIdleConnections=true
celeborn.worker.monitor.disk.enabled=false
celeborn.worker.flusher.threads=1
MicroBenchmark
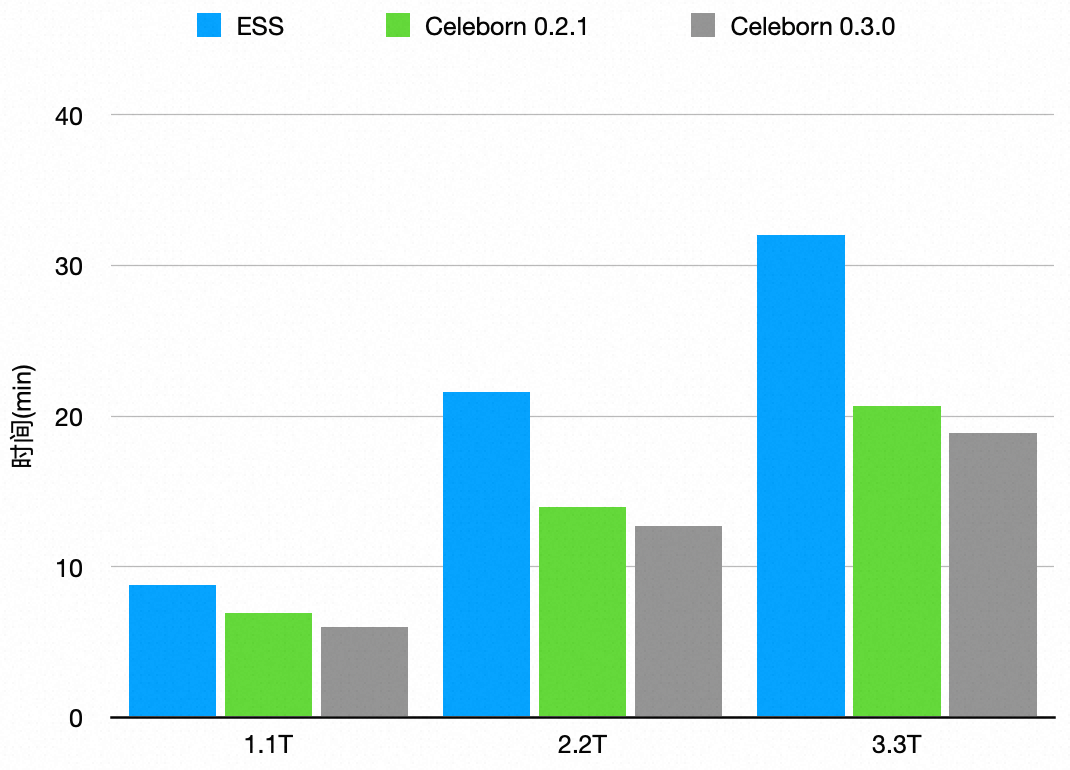
在这个测试场景中,我们测了 1.1T/2.2T/3.3T 的纯 Shuffle 场景,并对比 ESS, Celeborn 0.2.1, Celeborn 0.3.0 的总时间。
MicroBenchmark 代码如下:
spark.sparkContext.parallelize(1 to 8000, 8000).flatMap( _ => (1 to 15000000).iterator.map(num => num)).repartition(8000).count
spark.sparkContext.parallelize(1 to 8000, 8000).flatMap( _ => (1 to 30000000).iterator.map(num => num)).repartition(8000).count
spark.sparkContext.parallelize(1 to 8000, 8000).flatMap( _ => (1 to 45000000).iterator.map(num => num)).repartition(8000).count
测试结果
![18]()
Shuffle Write/Read Stages 具体时间如下表:
| |
1.1T |
2.2T |
3.3T |
| ESS |
8.3min (3.5/4.8) |
21.6min (8.6/13) |
32min (13/19) |
| Celeborn 0.2.1 sort |
6.9min (4.4/2.5) |
14min (8.8/5.2) |
20.7min (13/7.7) |
| Celeborn 0.3.0 sort |
6min (3.7/2.3) |
12.7min (7.5/5.2) |
18.9min (11/7.9) |
可以看出,Celeborn 相比 ESS 有明显性能优势,随着 Shuffle Size 变大优势愈加明显。0.3.0 相比 0.2.1 也有进一步性能提升。
3T TPCDS
测试方法
控制 Celeborn Worker 可使用的磁盘数量,并对比 ESS 和 Celeborn 0.3.0 的性能。
测试结果
| |
ESS 执行时间 |
0.3.0 执行时间 |
| 每个Worker 1块盘 |
4998s |
4386s |
| 每个Worker 2块盘 |
3843s |
3614s |
| 每个Worker 4块盘 |
3609s |
3305s |
| 每个Worker 8块盘 |
3323s |
3209s |
可以看到,Celeborn 相比 ESS 有明显性能优势,磁盘资源越有限优势越明显。
最后,感谢 Celeborn 的用户和开发者,并欢迎更多的用户和开发者加入!
Reference
[1] https://github.com/apache/incubator-celeborn
[2] https://celeborn.apache.org/
[3] https://github.com/flink-extended/flink-remote-shuffle
[4] https://github.com/oap-project/gluten