编者按:传统以太网方案存在系统调用消耗大量时间、增加数据传输延时、对 CPU 造成很重的负担三个缺点,而 RDMA 技术可以解决以上三个缺点。那 RDMA 究竟是什么?它的方案的设计思路是什么?今天,浪潮信息驱动工程师刘伟带大家深入理解 RDMA 技术的基本原理,交流在工程上的设计思路。本文整理自龙蜥大讲堂 83 期,以下为本次分享内容:
01 RDMA技术的优点、基础知识和设计思路
传统以太网方案存在三个缺点:send/sendto 等系统调用导致 CPU 在用户态和内核态之间切换,消耗大量时间;发送过程中需要 CPU 把数据从用户空间复制到内核空间(接收时反向复制),增加了数据传输延时;需要 CPU 全程参与数据包的封装和解析,在数据量大时将对 CPU 将造成很重的负担。
RDMA 技术可以解决上述三个问题:首先,其在数据传输过程中没有系统调用;然后,在系统内存内部做到零拷贝,省掉了数据在用户空间和内核空间之间拷贝的步骤。最后,把数据包的封装和解析交由网卡硬件来做,降低了 CPU 负载。
RDMA 指的是一种远程直接内存访问技术。具体到协议层面,它主要包含了Infiniband(IB),RDMA over Converged Ethernet(RoCE)和Internet Wide Area RDMA Protocol(iWARP)三种协议。三种协议都符合RDMA标准,共享相同的上层用户接口(Verbs),只是在不同层次上有一些差别。
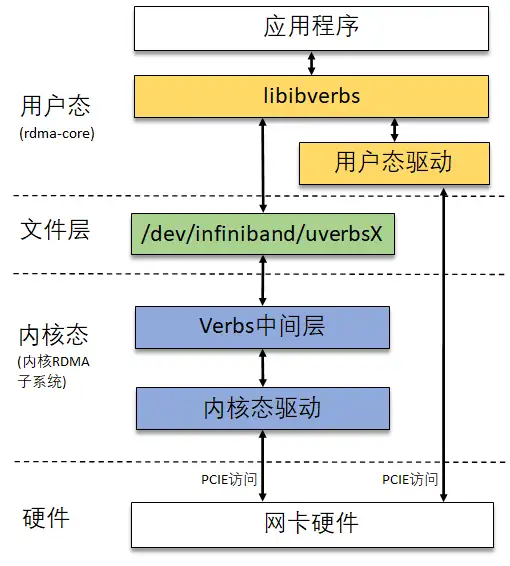
RDMA 的软件架构按层次可分成两部分,即 rdma-core 和内核 RDMA 子系统,分别运行在 Linux 系统中的用户态和内核态。整个软件架构适用于所有类型的 RDMA 网卡,不管网卡硬件执行了哪种 RDMA 协议(Infiniband/RoCE/iWARP)。
![]()
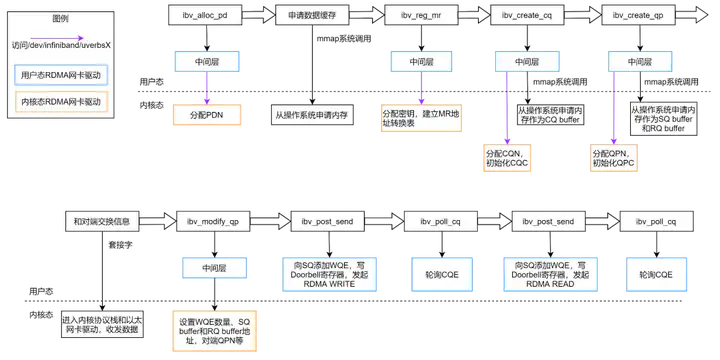
WQE(Work Queue Element,工作队列元素)的作用类似于以太网方案中收发队列里的描述符(Desc) 。其中包含了软件希望硬件去做的任务类型(远程读、远程写、发送还是接收等)以及任务的详细信息(数据所在的内存地址、数据长度和访问密钥等)。
WQ(Work Queue,工作队列)类似于以太网方案中的发送/接收队列,WQ 里面可以容纳很多 WQE,这些 WQE 在 WQ 中以先进先出(FIFO)队列的形式存在。左图展示了 WQ 和 WQE 的关系,以及它们和以太网方案中队列和描述符功能的比较。
QP 是一个发送工作队列和一个接受工作队列的组合,这两个队列分别称为 SQ(Send Queue)和 RQ(Receive Queue)。SQ 和 RQ 都是一种 WQ。SQ 专门用来存放发送任务,RQ 专门用来存放接收任务。在一次 SEND-RECV 流程中,发送端需要把表示一次发送任务的 WQE 放到 SQ 里面(这种操作称为 Post Send)。同样的,接收端需要把表示一次接收任务的 WQE 放到 RQ 里面(称为Post Receive),这样硬件才知道收到数据之后放到内存中的哪个位置。在RDMA技术中,通信的基本主体或对象是 QP,而不是节点。对于每个节点来说,每个进程都可以申请和使用若干个 QP,而每个本地 QP 可以“连接到”一个远端的 QP。每个节点的每个 QP 都有一个唯一的编号,称为 QPN(Query Pair Number),通过 QPN 可以唯一确定一个节点上的 QP。
CQ 意为完成队列(Completion Queue)。跟 WQ 中含有很多 WQE 类似,CQ 这个队列中也有很多元素,叫做 CQE(Completion Queue Element)。可以认为 CQE 跟 WQE 是相反的概念。如果 WQE 是软件下发给硬件的任务,CQE 就是硬件完成任务之后返回给软件的“完成报告”。每个 CQE 都包含某个 WQE 的完成信息。
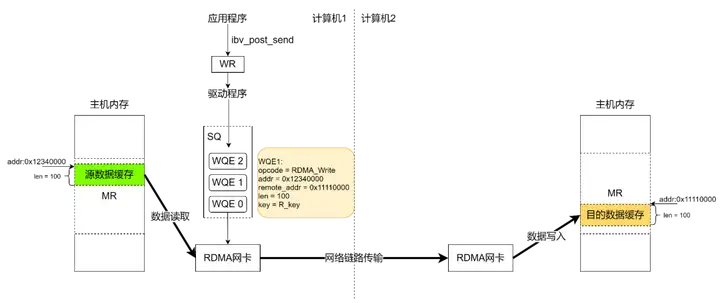
RDMA WRITE 操作是一端应用主动写入远端内存的行为,除了准备阶段,远端 CPU 不需要参与,也不感知何时有数据写入、数据在何时接收完毕。所以这是一种单端操作。需要注意的是,操作发起端的应用程序是通过虚拟地址来读写远端内存的,上层应用可以非常方便的对其进行操作。实际的虚拟地址—物理地址的转换是由 RDMA 网卡完成的。
![]()
下图中横向箭头表示的是某应用程序执行的步骤。每个步骤中下行的箭头和方框表示当前这个步骤的简要实现流程。
![]()
RDMA 实现方案的设计思路中比较重要的三点:初始化和配置等低频操作可以进入内核态执行;数据传输等高频操作旁路内核;独立的 QP、CQ 资源保证多线程并发。
![]()
02 浪潮 iRDMA 方案简介
iRDMA 是浪潮信息体系结构研究部利用自研 F10A FPGA 加速卡,基于 Linux 内核 IB 驱动架构和 rdma-core 开源协议栈,开发的一套 RDMA 网络加速平台,用户可在其基础上进行二次开发。
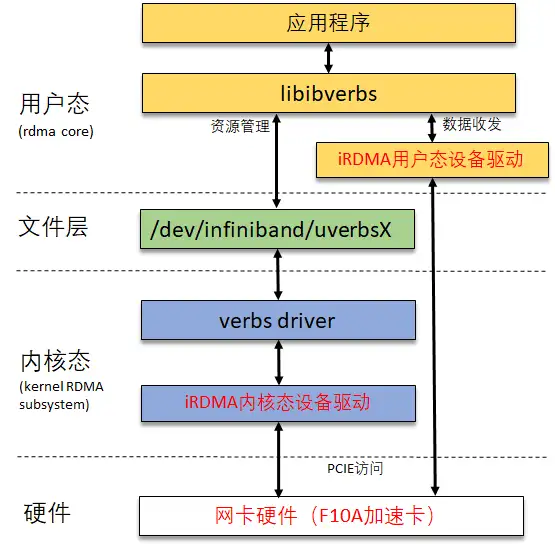
下面是它的软件模块框图:
![]()
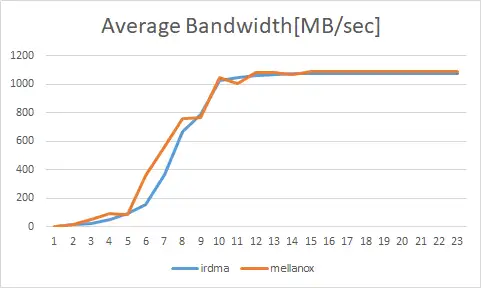
我们使用 perftest 工具测试 iRDMA,并和 Mellanox ConnectX-4 Lx 10G 网卡做比较,带宽测试结果见下图。
![]()
总体来说 Mellanox 网卡比 iRDMA 带宽大一点,按比例看小 size 时比较明显。
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载。