背景
在众多计算型软件的代码中,例如大数据,HPC以及AI,视频编解码软件,底层都会使用SIMD(单指令多数据流)指令对核心的逻辑进行优化。SIMD是一种计算机指令集,用于在不同的数据上执行相同的指令。它充分利用处理器的并行流水线,允许将多个数据一起处理来加速计算,从而提高程序的并行性,实现性能飞升。然而在当前服务器领域,由于X86生态占据主导地位,大量的软件针对X86平台利用X86的SIMD指令例如SSE/AVX/AVX2/AVX512进行了热点优化。由于ARM架构的服务器正在快速发展阶段,软件生态还远不如X86成熟,当一个X86软件需要移植到ARM服务器平台时,尤其是带有Intel SIMD的intrinsic指令时,需要将Intel的SIMD intrinsic指令(SSE/AVX/AVX2/AVX512)用ARM的SIMD intrinsic指令(NEON/SVE)重写,这将会给软件移植工作带来巨大的工作量,同时由于这些intrinsic指令和业务逻辑紧密耦合,这些移植的工作不具备可复制性,这也给软件移植带来了很重的负担。
X-SIMD简介
X-SIMD是平头哥基于开源SIMDe开发一个header-only C程序库,提供了一种简单易用的跨平台SIMD程序优化方案,旨在为不支持SIMD指令集的平台提供SIMD支持,它支持以下x86和arm指令集:
- x86 SSE,SSE2,SSE3,SSSE3,SSE4.1,SSE4.2, AVX, AVX2,AVX512
- aarch64 NEON, SVE
X-SIMD具有的优势:
- 良好的可移植性,X-SIMD为不同的硬件平台提供一个通用的API,它可以屏蔽不同平台之间的差异性,让开发者能够更加方便地使用SIMD指令,从而实现跨平台的应用开发;另一方面,对于已经包含许多intel intrinsic指令的软件来说,X-SIMD只需要通过头文件和编译选项修改,便可以轻松实现x86到arm平台的迁移。
- 高效的性能:X-SIMD充分利用不同硬件平台上的SIMD指令集,从而实现高效的数据并行计算;另外X-SIMD的API 内部实现有多种方式,或SVE,或NEON,或C语言,我们通过大量benchmark工作,按照最优实现方式,提供出去。测试对比,X-SIMD实现的接口对比华为Avx2Neon平均高出5~150%不等。
- 良好的兼容性:X-SIMD提供5000+ API,覆盖了intel 大多数指令集,并且每种接口至少包含一种以上实现方式,也就c语言实现,它保障了用户软件从x86迁移arm时,软件可以正常运行。
- 很好的可读性和可维护性,X-SIMD是由C语言编写的,代码结构清晰,开发者可以轻松地使用它来实现向量化计算,且易于扩展。
- 简单易用:如上所述,通过少量修改,X-SIMD帮助应用软件完成迁移,减少用户重新编写SIMD算法工作量,因此X-SIMD自推出就在HPC、大数据、数据库等场景得到应用。
在本文中,我们将主要介绍X-SIMD的架构和应用场景。
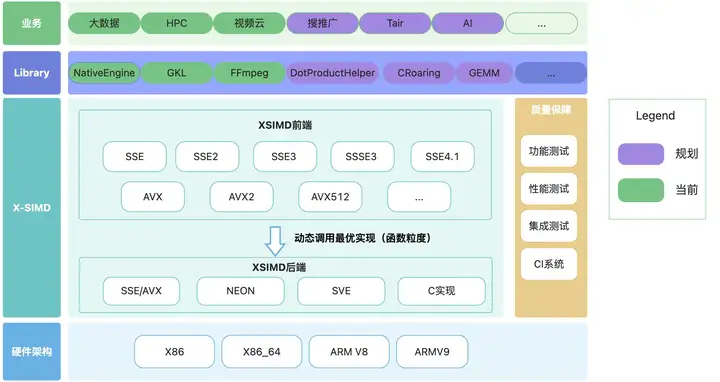
X-SIMD软件架构
![]()
X-SIMD软件架构图
如上图,X-SIMD是模块化的,在X-SIMD中x86和arm架构的接口实现分别有自己的头文件和命名空间,所有X-SIMD接口都以xsimd_为前缀。前端是x86指令集,后端是arm指令集和C语言实现,软件迁移时,无需更改x86的Native SIMD相关指令,经过X-SIMD重命名技术后会自动调用以xsimd_为前缀的API,X-SIMD按照最优实现将对应的x86指令翻译为SVE、NEON或C语言实现,举个例子,_mm512_add_ps函数实现如下:
XSIMD_FUNCTION_ATTRIBUTES
xsimd__m512
xsimd_mm512_add_ps (xsimd__m512 a, xsimd__m512 b) {
#if defined(XSIMD_X86_AVX512F_NATIVE)
// 如果当前平台是x86,支持AVX512F,则直接运行native API
return _mm512_add_ps(a, b);
#elif defined(XSIMD_ARM_SVE_NATIVE)
// 如果是arm 平台,则优先走SVE实现分支,(因为经我们测试比NEON实现性能更好点)
xsimd__m512 r;
xsimd_svbool_t pg = svptrue_b32();
r.sve_f32[XSIMD_SV_INDEX_0] = svadd_f32_z(pg, a.sve_f32[XSIMD_SV_INDEX_0], b.sve_f32[XSIMD_SV_INDEX_0]);
r.sve_f32[XSIMD_SV_INDEX_1] = svadd_f32_z(pg, a.sve_f32[XSIMD_SV_INDEX_1], b.sve_f32[XSIMD_SV_INDEX_1]);
r.sve_f32[XSIMD_SV_INDEX_2] = svadd_f32_z(pg, a.sve_f32[XSIMD_SV_INDEX_2], b.sve_f32[XSIMD_SV_INDEX_2]);
r.sve_f32[XSIMD_SV_INDEX_3] = svadd_f32_z(pg, a.sve_f32[XSIMD_SV_INDEX_3], b.sve_f32[XSIMD_SV_INDEX_3]);
return r;
#elif defined(XSIMD_ARM_NEON_A64V8_NATIVE)
// 否则优先走NEON实现分支
xsimd__m512 r;
r.m128[0].neon_f32 = vaddq_f32(a.m128[0].neon_f32, b.m128[0].neon_f32);
r.m128[1].neon_f32 = vaddq_f32(a.m128[1].neon_f32, b.m128[1].neon_f32);
r.m128[2].neon_f32 = vaddq_f32(a.m128[2].neon_f32, b.m128[2].neon_f32);
r.m128[3].neon_f32 = vaddq_f32(a.m128[3].neon_f32, b.m128[3].neon_f32);
return r;
#else
// 如果上述均未实现则走c语言实现分支。
xsimd__m512_private
r_,
a_ = xsimd__m512_to_private(a),
b_ = xsimd__m512_to_private(b);
XSIMD_VECTORIZE
for (size_t i = 0 ; i < (sizeof(r_.m256) / sizeof(r_.m256[0])) ; i++) {
r_.m256[i] = xsimd_mm256_add_ps(a_.m256[i], b_.m256[i]);
}
return xsimd__m512_from_private(r_);
#endif
}
// _mm512_add_ps 命名重定向
#if defined(XSIMD_X86_AVX512F_ENABLE_NATIVE_ALIASES)
#undef _mm512_add_ps
#define _mm512_add_ps(a, b) xsimd_mm512_add_ps(a, b)
#endif
X-SIMD目标是涵盖Intel AVX指令族,包括SSE、AVX,AVX2,AVX512,一共5588条指令,目前X-SIMD已完成常用接口API的开发约1000个,满足大数据,HPC,数据库等场景使用。
X-SIMD使用
使用X-SIMD开发非常简单,以下步骤既适用于跨平台开发,也适用于应用迁移场景:
- X-SIMD是header only,直接拷贝x-simd文件夹到/usr/local/include目录下
- 在代码中添加<xsimd/xsimd.h>头文件,或者将原来的x86 intrinsic头文件修改为 <xsimd/xsimd.h>
- 在构建脚本中添加以下编译选项以下编译
-DXSIMD_ENABLE_NATIVE_ALIASES (用于API重命名)
-march=armv8.5-a+crc+sve2+sha2+sha3+sve2-sha3 -msve-vector-bits=128 (适用于arm平台)
-I /usr/local/include/x-simd
如果应用适用的cmake进行构建,可以添加以下编译项
option(ENABLE_X_SIMD "Enable X-SIMD optimized" OFF)
if (ENABLE_X_SIMD)
MESSAGE( STATUS " ENABLE X_SIMD")
add_definitions(-DXSIMD_ENABLE_NATIVE_ALIASES)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -msve-vector-bits=128 -march=armv8.5-a+crc+sve2+sha2+sha3+sve2-sha3+sve2-aes")
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -msve-vector-bits=128 -march=armv8.5-a+crc+sve2+sha2+sha3+sve2-sha3+sve2-aes")
include_directories(/usr/local/include/x-simd)
endif()
以下是X-SIMD使用一个示例,例如下面的代码使用X-SIMD SSE2指令集来计算两个向量的和
#include <stdlib.h>
#include <xsimd/xsimd.h>
int main()
{
struct {
int32_t a[4];
int32_t b[4];
int32_t r[4];
} test_vec = {
{ INT32_C( 1587156417), INT32_C( 1768270179), -INT32_C( 1942404587), INT32_C( 346970517) },
{ INT32_C( 2141391970), INT32_C( 1584534422), INT32_C( 1144809083), -INT32_C( 446909148) },
{ -INT32_C( 566418909), -INT32_C( 942162695), -INT32_C( 797595504), -INT32_C( 99938631) }
};
__m128i a = _mm_loadu_epi32(test_vec.a);
__m128i b = _mm_loadu_epi32(test_vec.b);
__m128i r = _mm_loadu_epi32(test_vec.r);
__m128i sum = _mm_add_epi32(a, b);
if (memcmp(&sum, &r, sizeof(__m128i)) != 0) {
printf("Example test failed.\n");
} else {
printf("Example test OK.\n");
}
return 0;
}
用户可使用以下编译命令在aarch64上进行测试。
gcc -O2 -fPIC -Wall test.c -o test_xsimd -I. -DXSIMD_ENABLE_NATIVE_ALIASES -msve-vector-bi
另外我们提供了一个脚本可以快速扫描项目代码中有多少x86_64 intrinsic指令,方便用户在做迁移时统计接口,以评估迁移工作量:
#!/usr/bin/sh
set -e
DIR=$pwd
DATE=`date +%Y%m%d-%H%M%S`
SSE="_mm(?:[0-9]+)?_\w+"
AVX="_mm256(?:[0-9]+)?_\w+"
AVX512="_mm512(?:[0-9]+)?_\w+"
if [ -n $1 ];then
DIR=$1
echo $DIR
fi
grep -oPrn $SSE $DIR &> sse.log.$DATE
grep -oPrn $AVX $DIR &> avx.log.$DATE
grep -oPrn $AVX512 $DIR &> avx512.log.$DATE
X-SIMD应用场景
X-SIMD适用于各种应用程序,例如数字信号处理、图像和视频处理、机器学习、科学计算等,这些应用软件属于计算密集型,需要处理大量的数据计算,往往会使用到SIMD进行优化。以下是几个典型的应用场景说明:
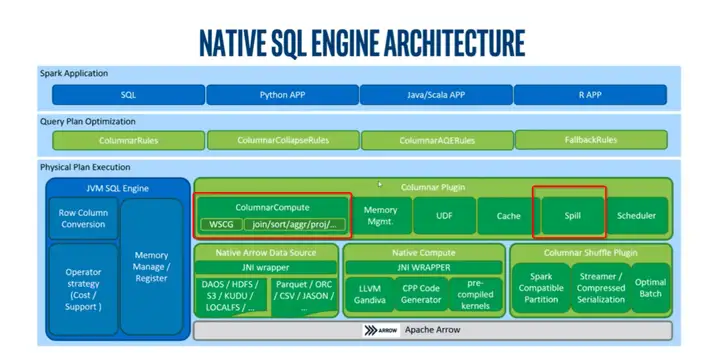
大数据场景OAP
优化分析包OAP(Optimized Analytics Package for Spark Platform )是英特尔和社区开发的开源项目,旨在提高 Spark 性能。它基于先进的英特尔硬件技术,提供了多种功能来改善 Spark 高速缓存、Shuffle、执行和机器学习性能。
其中Spark SQL 的 Native 引擎可以很好地处理基于行的结构化数据将 Spark 行数处理转为列式处理,Gazelle Plugin 基于 Apache Arrow 对 SIMD 友好的列式数据处理重新实现了 Spark SQL 执行层,并利用 Arrow 的 CPU 缓存友好的列式内存布局、SIMD 优化内核和基于 LLVM 的表达式引擎,为 Spark SQL 带来更好的性能。
![]()
Native Engine 架构图
内存数据库场景
云原生内存数据库Tair是阿里云国产自研的云原生内存数据库。在完全兼容Redis的基础上,提供了丰富的数据模型和企业级能力来帮助客户构建实时在线场景。Tair广泛应用于政务、金融、制造、医疗和泛互联网等各行业客户,满足客户的高速查询和计算场景。
TairRoaring是基于Tair引擎的Roaring Bitmap实现。Bitmap(又名Bitset)是一种常用的数据结构,使用少量的存储空间来实现海量数据的查询优化。尽管Bitmap相比常规基于Hash结构的实现节省了大量内存空间,但是常规Bitmap对于稀疏场景下的数据存储仍不够友好,因此有了各种压缩Bitmap的实现(Comprised bitmap),Roaring Bitmap就是业界公认的一种更高效和均衡的Bitmap压缩存储的实现。TairRoaring使用了包括SIMD instructions、Vectorization、PopCnt算法等多种工程优化,提升了计算效率,实现了高效的时空效率。通过X-SIMD指令转换,可以大幅度降低Tair在arm上重新通过SIMD实现Bitmap相关算法难度,降低迁移倚天的开发成本。
X-SIMD性能
对比华为Avx2Neon,X-SIMD在接口实现更丰富,接口性能更优。以下是摘取部分ffmpeg中使用的相关API,对比了两者的实现的性能差异,每个接口执行100000次统计其耗时时长,性能提升从5%~138%不等。
| 接口 |
avx2neon cycle(us) |
x-simd cycle(us) |
x-simd 实现指令 |
接口性能提升 |
| _mm256_mullo_epi32 |
576 |
458 |
NEON |
26% |
| _mm256_mullo_epi16 |
576 |
460 |
NEON |
25% |
| _mm256_storeu_si256 |
370 |
326 |
NEON |
13% |
| _mm256_cvtepi32_ps |
350 |
329 |
NEON |
6% |
| _mm256_cvtps_epi32 |
333 |
254 |
NEON |
31% |
| _mm256_avg_epu8 |
569 |
473 |
SVE |
20% |
| _mm256_mulhi_epi16 |
1044 |
442 |
SVE |
136% |
| _mm256_mulhi_epu16 |
1043 |
439 |
SVE |
138% |
| _mm256_permute4x64_epi64 |
1,027 |
710 |
SVE |
45% |
| _mm256_extracti128_si256 |
249 |
220 |
SVE |
13% |
| _mm256_inserti128_si256 |
620 |
616 |
SVE |
21% |
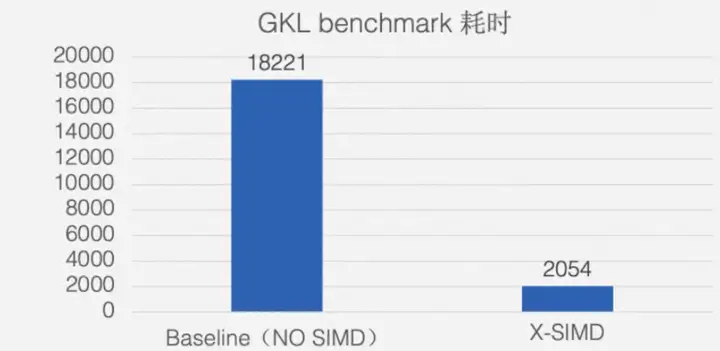
X-SIMD在HPC GKL benchmark中表现性能提升8倍,在GATK端到端测试性能提升20%。
![]()
GKL benchmark
在大数据Oap中,X-SIMD 完成了Arrow组件的适配,SparkSQL性能端到端提升2~5%。
| tpcds sql请求 |
baseline |
x-simd |
性能提升 |
| query1 |
17.23 |
18.537 |
7.1% |
| query2 |
23.937 |
28.595 |
16.3% |
| query3 |
14.112 |
15.269 |
7.6% |
| query4 |
107.661 |
105.457 |
-2.1% |
| query5 |
32.148 |
34.798 |
7.6% |
| query6 |
13.119 |
13.416 |
2.2% |
| query7 |
23.097 |
23.687 |
2.5% |
| query8 |
13.89 |
13.806 |
-0.6% |
| query9 |
52.583 |
50.993 |
-3.1% |
| query10 |
19.611 |
19.812 |
1.0% |
| |
|
average |
3.80% |
综述
X-SIMD是一个modern SIMD指令的开源C库,它提供了一系列丰富的跨平台兼容的函数,可以在aarch64 CPU架构上直接运行x86_64 intrinsic指令,并实现了高效的向量化处理操作,易于移植和扩展。如果你需要对大量数据进行引擎程序设计、数学运算、图像/音视频处理等高性能计算操作,而又希望代码简单易用、具有良好的可移植性和可维护性,并且正打算迁移到aarch64平台上,那么X-SIMD正是你所需要的。X-SIMD可以帮助你降低了向量化代码迁移的门槛,欢迎有需要的伙伴前来咨询。
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载。