本文分享自华为云社区《DataArts Studio 通过Rest Client 接口读取RESTful接口数据的能力,通过Hive-SQL存储》,作者: 张浩奇 。
Rest Client 提供了读取RESTful接口数据的能力。Rest Client从RESTful地址中获取数据,转换为数据集成支持的数据类型,然后传递给下游的hive-sql节点存储。本文POST接口典型场景为例,为您示例如何使用Rest Client,从RESTful地址中读取数据并同步到hive表中。
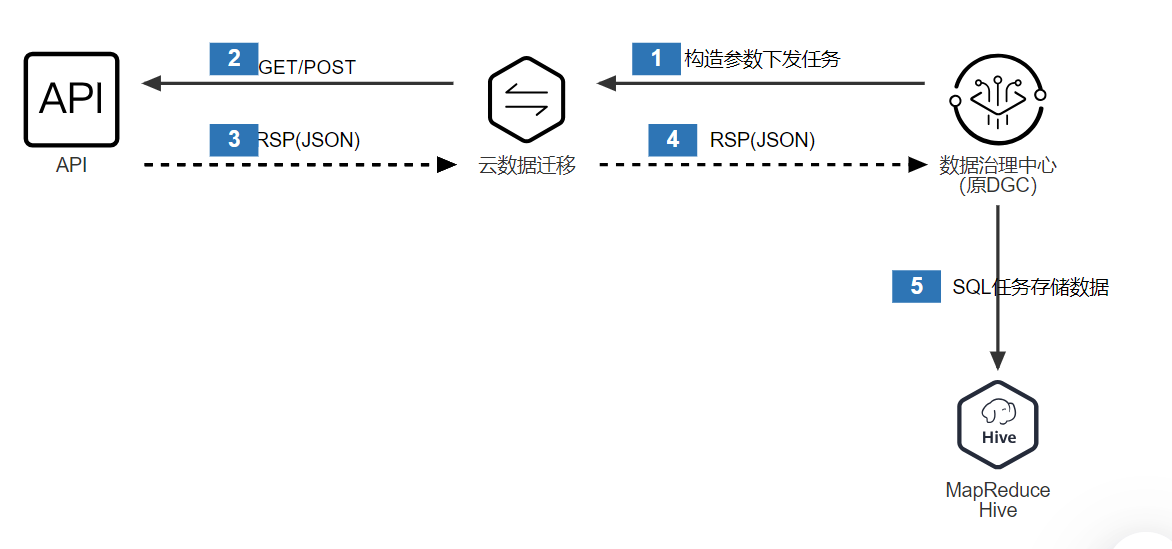
本文指导从RESTful地址中读取数据并同步到MRS-Hive表中。大致方案,DataArtStudio 管理配置采集任务,通过CDM服务进行代理下发和第三方API服务器进行对接,响应消息通过节点间参数传递给MSR-Hive-SQL解析入库,
集成流程如下:
![cke_138.png]()
方案开发流程如下:
步骤1:DataArtsStudio 创建Rest Client任务
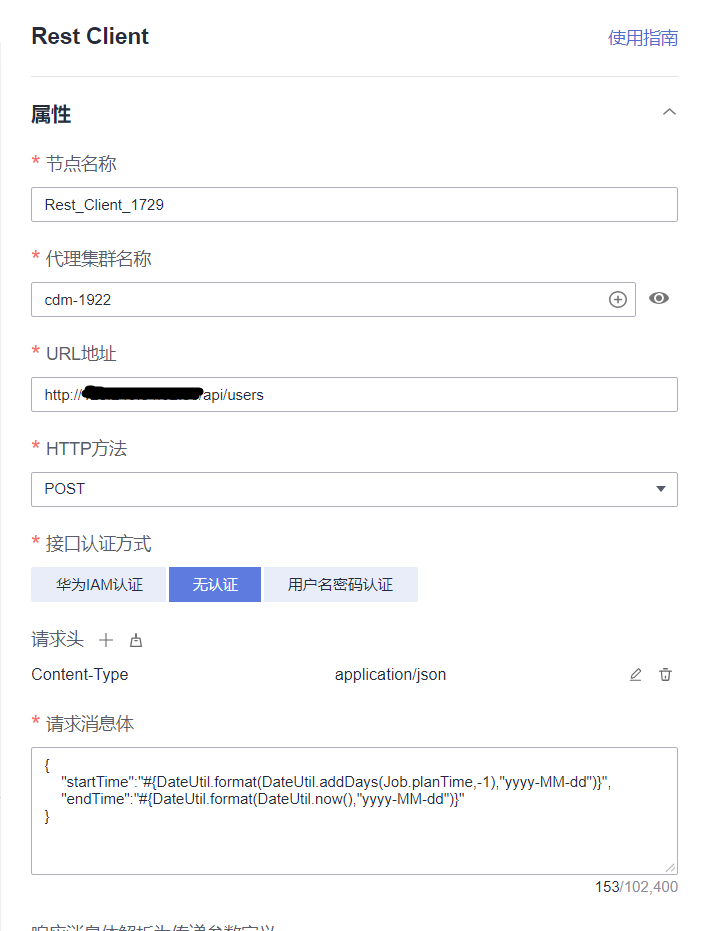
数据开发模块,创建Rest Client节点,输入GET/POST参数,包括认证方式,头域、请求参数/消息体
![cke_139.png]()
其中请求消息体中json可以使用EL表达式,比如携带时间过滤参数
JSON Body体
{
"startTime":"#{DateUtil.format(DateUtil.addDays(Job.planTime,-1),"yyyy-MM-dd")}",
"endTime":"#{DateUtil.format(DateUtil.now(),"yyyy-MM-dd")}"
}
系统转换后参数如下:
{
"startTime":"2023-07-11",
"endTime":"2023-07-12"
}
EL表达式的详细参考如下:
https://support.huaweicloud.com/usermanual-dataartsstudio/dataartsstudio_01_0494.html
响应消息的JSON中返回的消息如下数组格式:
Response body:
{"data":
[
{
"id":99467,
"proportionProjectId":"0405",
"proportionProjectName":"外勤津贴",
"proportionAfterTax":40800,
"proportionDepartmentId":289,
"proportionDepartmentName":"总所税务部",
"voucherStatusTime":1600758794000,
"billsNumber":"2020092299467"
},
{
"id":102000,
"proportionProjectId":"040102",
"proportionProjectName":"040102 _ 职能部门员工年薪",
"proportionAfterTax":20000,
"proportionDepartmentId":296,
"proportionDepartmentName":"总所创客部",
"voucherStatusTime":1606209149000,
"billsNumber":"2020112402000"
}
]
}
步骤2:MSR-Hive创建表
CREATE TABLE IF NOT EXISTS mrs_hive_rest
(
`billsNumber` STRING
,`proportionDepartmentId` BIGINT
,`voucherStatusTime` BIGINT
,`proportionProjectId` STRING
,`proportionAfterTax` BIGINT
,`id` BIGINT
,`proportionProjectName` BIGINT
,`proportionDepartmentName` STRING
);
步骤3:DataArtsStudio 创建hive-sql脚本用于存储POST接口的响应消息
数据开发模块创建hive-sql脚本,例如:
-- HIVE sql
-- ******************************************************************** --
-- author: zhanghaoqi
-- create time: 2023/07/12 15:50:41 GMT+08:00
-- ******************************************************************** --
SELECT * FROM mrs_hive_rest;
INSERT INTO mrs_hive_rest SELECT json_tuple(json, 'billsNumber', 'proportionDepartmentId', 'voucherStatusTime', 'proportionProjectId', 'proportionAfterTax', 'id', 'proportionProjectName', 'proportionDepartmentName') FROM (
SELECT explode(split(regexp_replace(regexp_replace('${jsonStr}', '\\[|\\]',''),'\\}\\,\\{','\\}\\;\\{'),'\\;'))
as json) t;
SELECT * FROM mrs_hive_rest;
SQL脚本关键点说明,在脚本中引用**${jsonStr}** 作为响应的消息的JSON字符串进行解析(在步骤4中定义改参数内容)
由于响应消息是JSON数组,使用了内置的json和字符串方法进行解析。
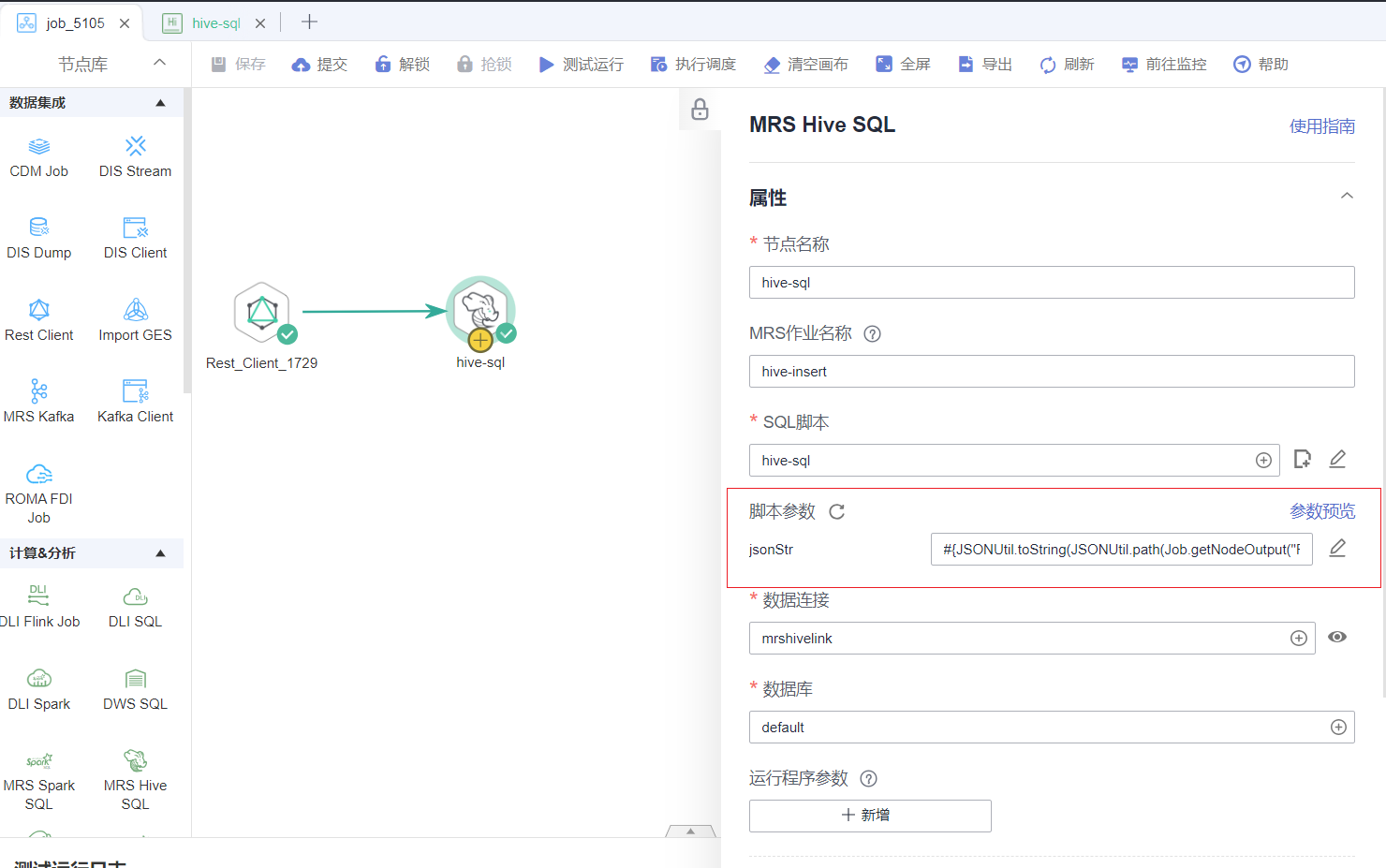
步骤4:DataArtsStudio 创建hive-sql节点执行脚本
创建hive-sql节点,执行步骤3脚本
![cke_140.png]()
参数关键点:脚本参数会自动提取SQL脚本中引用的参数,此处需要配置参数的内容,参数使用EL表达式获取前一个Rest_Client节点的返回值 #{JSONUtil.toString(JSONUtil.path(Job.getNodeOutput("Rest_Client_1729"),"data"))} 其中Rest_Client_1729为前一个节点的任务名,data为前一个节点的数据路径。
步骤5:配置完成后执行测试运行验证脚本
配置完成后,测试运行脚本,通过查看日志确认内容是否符合预期,SQL入库是否成功。
[2023/07/12 20:13:24 GMT+0800] [INFO] Connect to server successfully
[2023/07/12 20:13:24 GMT+0800] [INFO] Executing SQL:SELECT * FROM mrs_hive_rest;
[2023/07/12 20:13:24 GMT+0800] [INFO] Execute SQL successfully
[2023/07/12 20:13:24 GMT+0800] [INFO] Reading SQL execution result
[2023/07/12 20:13:24 GMT+0800] [INFO] The first 0 rows:
[2023/07/12 20:13:24 GMT+0800] [INFO] Read SQL execution result successfully
[2023/07/12 20:13:24 GMT+0800] [INFO]
[2023/07/12 20:13:24 GMT+0800] [INFO] Executing SQL:INSERT INTO mrs_hive_rest SELECT json_tuple(json, ‘billsNumber’, ‘proportionDepartmentId’, ‘voucherStatusTime’, ‘proportionProjectId’, ‘proportionAfterTax’, ‘id’, ‘proportionProjectName’, ‘proportionDepartmentName’) FROM (
SELECT explode(split(regexp_replace(regexp_replace(’[{“billsNumber”:“2020092299467”,“proportionDepartmentId”:289,“voucherStatusTime”:1600758794000,“proportionProjectId”:“0405”,“proportionAfterTax”:40800,“id”:99467,“proportionProjectName”:“外勤津贴”,“proportionDepartmentName”:“总所税务部”},{“billsNumber”:“2020112402000”,“proportionDepartmentId”:296,“voucherStatusTime”:1606209149000,“proportionProjectId”:“040102”,“proportionAfterTax”:20000,“id”:102000,“proportionProjectName”:“040102 _ 职能部门员工年薪”,“proportionDepartmentName”:“总所创客部”}]’, ‘\[|\]’,’’),’\}\,\{’,’\}\;\{’),’\;’))
as json) t;
[2023/07/12 20:13:38 GMT+0800] [INFO] Execute SQL successfully
[2023/07/12 20:13:38 GMT+0800] [INFO] Reading SQL execution result
[2023/07/12 20:13:38 GMT+0800] [INFO] Read SQL execution result successfully
[2023/07/12 20:13:38 GMT+0800] [INFO]
[2023/07/12 20:13:38 GMT+0800] [INFO] Executing SQL:SELECT * FROM mrs_hive_rest;
[2023/07/12 20:13:38 GMT+0800] [INFO] Execute SQL successfully
[2023/07/12 20:13:38 GMT+0800] [INFO] Reading SQL execution result
[2023/07/12 20:13:38 GMT+0800] [INFO] The first 2 rows:
2020092299467,289,1600758794000,0405,40800,99467,null,总所税务部
2020112402000,296,1606209149000,040102,20000,102000,null,总所创客部
[2023/07/12 20:13:38 GMT+0800] [INFO] Read SQL execution result successfully
[2023/07/12 20:13:38 GMT+0800] [INFO]
确认脚本执行成功,入库成功。
【云咖问答】第2期 华为云大咖架构师坐阵,与你共话应用创新,提问互动赢开发者定制礼品~https://bbs.huaweicloud.com/forum/thread-0234124103999807029-1-1.html
点击关注,第一时间了解华为云新鲜技术~