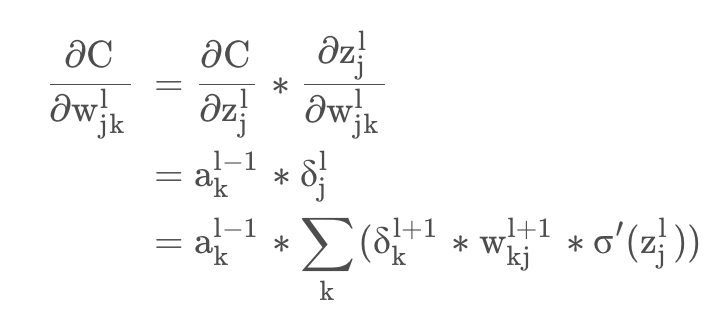![]()
作者 | FesianXu
导读
我们在进行对比学习训练时候,经常需要设置大的batch size,而显卡的显存大小是限制batch size大小的最主要因素,在实践过程中我们经常采用recompute机制,通过用计算换空间的方式,减少模型的内存消耗。然,在动态图训练时候,recompute机制需要进行手动的停止同步和梯度融合,本文纪录下这个问题。
全文7095字,预计阅读时间18分钟。
在对比学习场景,或者其他需要大batch size的场景中,由于显卡显存的限制,经常会受限batch size的进一步增大,此时可以采用“以计算换空间”的方式减少模型的显存占用,得而进一步增大batch size。目前主流框架都对这个机制提供了支持,一般称之为recompute或者checkpoint机制,比如pytorch提供在[1],paddle(动态图)提供在[2],tensorflow(动态图)提供在[3];而在静态图框架中,比如tensorflow(静态图)提供在[4],而paddle(静态图)的这个能力由fleet-x提供[5]。为了理解recompute机制在分布式场景会导致的问题和解决方案,我们首先需要了解recompute机制,我们先简单介绍下。
一般来说深度学习网络的一次训练由三部分构成:
前向计算(forward):在该阶段会对模型的算子进行前向计算,对算子的输入计算得到输出,并传给下一层作为输入,直至计算得到最后一层的结果位置(通常是损失)。
反向计算(backward):在该阶段,会通过反向求导和链式法则对每一层的参数的梯度进行计算。
梯度更新(优化,optimization):在该阶段,通过反向计算得到的梯度对参数进行更新,也称之为学习,参数优化。
在之前反向求导公式的推导过程中[6],我们知道进行反向求导链式传递的时候,需要前一层的激活输出\( \sigma^{\prime}(z_{j}^{l}) \) 作为输入参与本层的梯度计算,如式子(1-1)所示(既是[6]中的公式(4.1)):
![图片]()
△(1-1)
公式看起来让人头大,我们以代码为例子。在一般深度学习框架中,提供对自定义层的梯度定义,如博文[7]中介绍的。一般这类型的自定义都会提供两种输入,op和grad,如下代码:
#使用修饰器,建立梯度反向传播函数。其中op.input包含输入值、输出值,grad包含上层传来的梯度
@tf.RegisterGradient("QuantizeGrad")
def sign_grad(op, grad):
input = op.inputs[0] # 取出当前的输入
cond = (input>=-1)&(input<=1) # 大于1或者小于-1的值的位置
zeros = tf.zeros_like(grad) # 定义出0矩阵用于掩膜
return tf.where(cond, grad, zeros)
# 将大于1或者小于-1的上一层的梯度置为0
其中的op表示当前的算子操作符,而op.inputs即是该算子的输入列表,当然如果该算子是中间层算子,那么其输入就是上一层的输出了,而grad就是累积的梯度,一般我们都会对op和grad进行操作,以计算当前层的梯度。相对应的一些代码例子,读者有兴趣可移步到[8],笔者实现了一个很简单的自动梯度求导试验例子。
好像有点跑题了,但是笔者以这个例子主要是想告诉诸位读者,在模型的训练过程中为了反向梯度计算的方便会储存很多中间变量,比如前向计算过程中的激活输出值,梯度值等等。有些中间值会被框架自动回收,比如非叶子节点的梯度值是会被自动回收的,见[9],但是有些中间变量不会,比如此时的中间层的输出值,这些中间变量占据了整个训练过程的大量内存。对于这些中间变量,如果希望采用更大的batch size进行训练,那么就需要减少这些中间变量以换取更大的内存中间,recompute就是根据这个思路设计的。
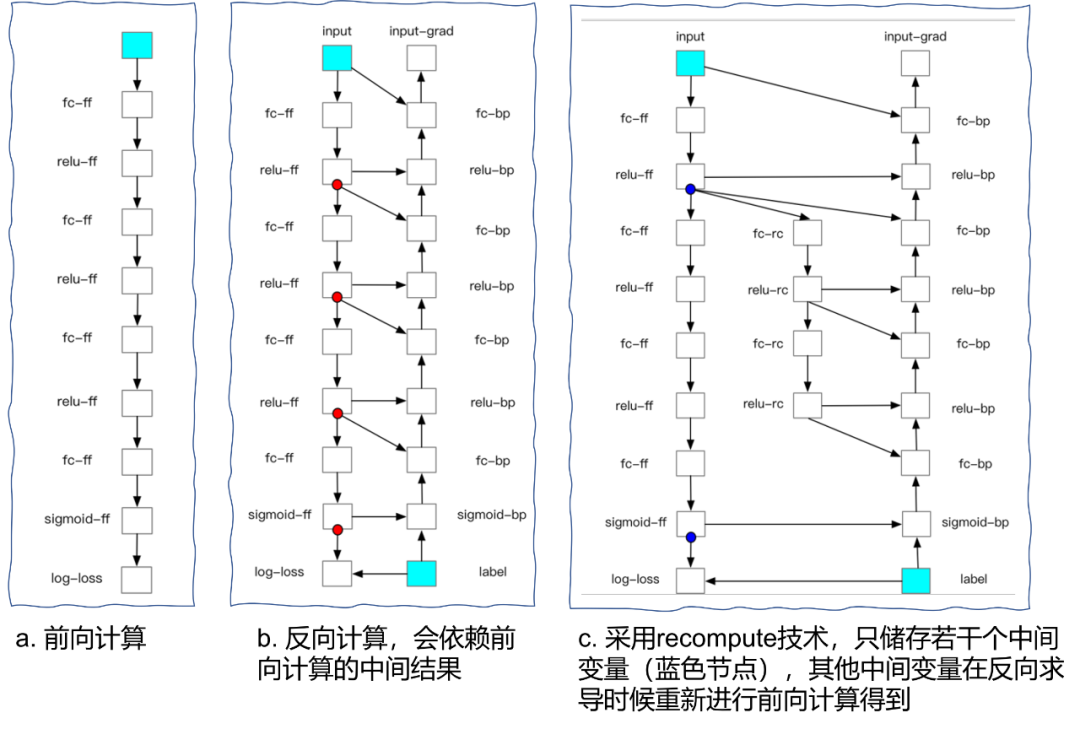
recompute将深度网络切分为若干个部分(segment),对于每个部分而言,前向计算的时候,除了小部分必须储存的变量外,其他中间变量都将被删除;在反向计算的时候,首先重新计算一遍前向算子,以获得需要的中间结果,再正常地运行反向算子。因此,recompute对比常规的网络迭代而言,多计算了一遍前向计算,是典型的以计算换空间的“妥协”技术。整个过程如Fig 1.所示。
![图片]()
△Fig 1. 前向计算,反向计算和重计算的图示,其中重计算会将除了checkpoints之外的非必要中间变量删除,在进行反向梯度计算时候再重新进行前向计算得到。
通常会把切分网络的变量称之为checkpoints,有大量学者在研究如何选择合适的checkpoints才能更好地均衡计算性能和内存,通常以ERNIE,BERT等为例子,在其每个Transformer模块的中间变量作为切分就比较合适。注意到无论在动态图还是在静态图中,都需要对checkpoints进行定义,比如paddle fleet中的recompute使用如下所示:
dist_strategy = fleet.DistributedStrategy()
# 使用Recompute,并设置checkpoints
dist_strategy.recompute = True
dist_strategy.recompute_configs = {"checkpoints": model.checkpoints}
# 定义checkpoints作为切分点
optimizer = fluid.optimizer.Adam(learning_rate=configs.lr)
optimizer = fleet.distributed_optimizer(optimizer, dist_strategy) # 设置分布式优化器
optimizer.minimize(model.loss)
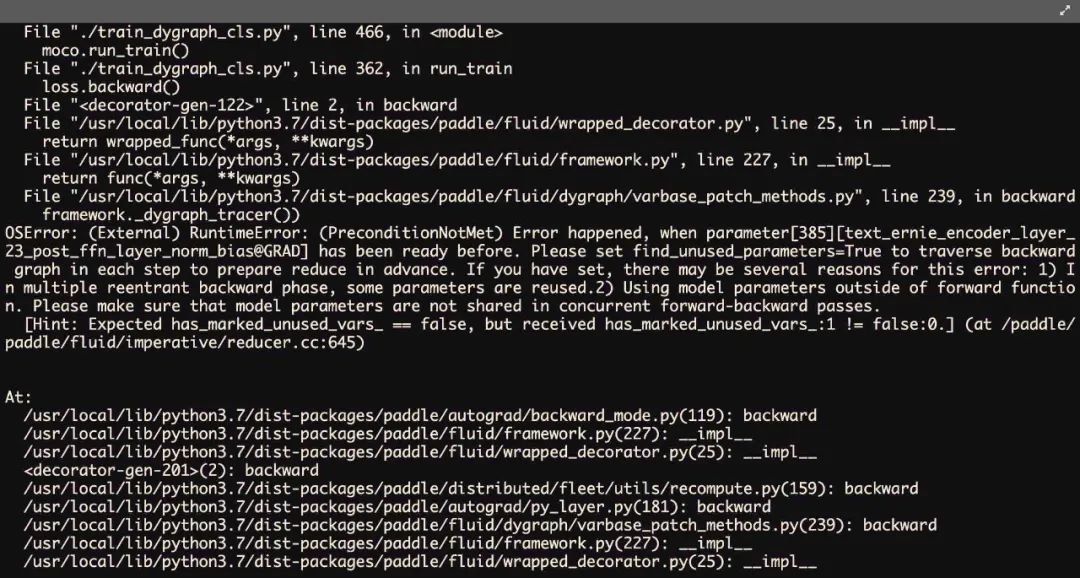
然而,问题来了。在静态图中使用分布式的recompute机制可能并不会有问题,因为静态图的分布式使用隐藏了一些细节,但是在动态图中使用recompute机制时候(以paddle为例子),则会产生报错如Fig 2.所示,相似的报错信息同样在pytorch上也会遇到,见[10]。
![图片]()
△Fig 2. 在paddle动态图分布式场景中,采用recompute机制将会产生这个报错。
在理解这个报错之前,我们需要理解数据分布式并行(Data Distributed Parallel,DDP)的逻辑。数据并行指的是将数据水平划分,并给不同的节点(不同的进程或者卡,甚至是分布式节点)进行计算,然后将各个节点的梯度更新结果进行汇总后更新(这个步骤称之为规约,reduce),使得最终每个节点的梯度更新结果是保持一致的。一般来说DDP可以分为几个步骤[12]:
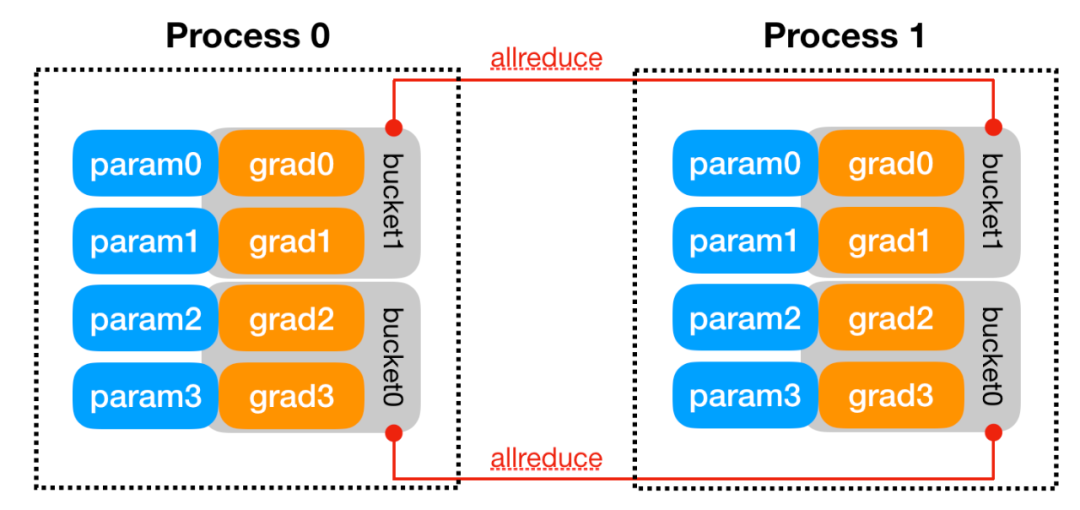
1、构建:DDP会将rank 0节点上的本地模型参数state_dict()广播到其他节点上,以确保每个节点都是有着同样的模型副本进行初始化的。然后,每个节点上的DDP进程将会创建一个本地规约器(reducer),这个规约器用于负责后续反向传播过程中的多节点梯度同步。为了提高通信效率,通常会将多个梯度打包到一个“桶(bucket)”中,并且对整个桶进行规约,由此减少通信成本,如Fig 3.所示。如果某个桶的某些梯度由于某些原因还没有准备好,那么就需要等待这个梯度准备就绪才能同步,这通常都会影响训练效率。除了装桶外,规约器还需要在构建过程中对每个参数进行自动求导钩子函数(hook)的注册。在反向求导阶段,这些钩子函数在梯度就绪的时候将会被触发。
![图片]()
△Fig 3. 梯度同步以桶为单位进行。
2、前向传播:DDP拿到输入后就传递给本地模型,如果find_unused_parameters 设置为True,那么就会继续分析模型的输出。这个模式允许对模型的子图进行反向计算,DDP会遍历模型的自动求导图,从中找出参与反向计算的参数,并且将所有未使用的参数(也即是不需要参加规约的参数)标识为ready状态。在反向过程中,规约器只会等待unready状态的参数进行同步,但是规约器同样会规约所有参数,而仅是不会等待这些未使用的参数而已。
3、反向传播:反向的backward()函数直接包含在损失Tensor中,而这脱离了DDP的控制,因此DDP利用在构建阶段注册好的自动梯度钩子进行梯度同步的触发。当一个梯度ready后,其对应的DDP钩子函数会被触发,DDP因此会将其参数的梯度标识为ready状态,意味着已经准备好被规约了。当一个桶中所有梯度都已经就绪后,规约器就对该桶触发allreduce操作,对所有节点该桶的值进行汇总求平均。
4、优化阶段:对于优化器而言,它优化的是本地的模型。由于每个节点的初始状态和参数更新都是一致的,因此最后的多节点的模型参数也是一致的。
让我们回到原来的问题上,了解了DDP的运行逻辑后,我们就能读懂这个报错信息了。
Error happened, when parameter[385] [xxxxx@GRAD] has been ready before. Please set fine_unused_parameters=True to traverse backward graph in each step to prepare reduce in advance. If you have set , xxxx
当采用了recompute机制后,将会有K个Transformer模块的checkpoints堆叠在一起,在进行loss.backward()的时候,将会对同样的模型触发产生K个前向-反向过程,这意味着对于同一个参数将会有K个自动求导钩子函数进行绑定,一旦某一个钩子函数将参数设置为ready后,其他钩子函数就会导致这个报错。因此报错中会显示某个GRAD梯度参数已经被标识为ready了,让你打开fine_unused_parameters = True以遍历反向图进行提前规约,但是你即便设置了同样也会报这个错的,因为本质原因在于recompute导致了参数被多个钩子函数所绑定了。[11]
那么怎么解决这个问题呢?一个简单的方法就是将DDP的前向-反向过程用no_sync()上下文进行包裹,此时可以防止DDP进行多节点的梯度规约,并且在本地汇集所有的本地模型梯度。在退出了no_sync()上下文后,手动触发DDP的前向-反向,进行梯度规约。这个no_sync上下文已经在pytorch和paddle中实现了,我们以paddle为例子(pytorch也是一样的,和paddle差别极其小,注意需要paddle 2.2以上才支持no_sync上下文):
# required: distributed
import numpy
import paddle
import paddle.distributed as dist
from paddle.autograd import PyLayer
from paddle.distributed.fleet.utils.hybrid_parallel_util import fused_allreduce_gradients
class cus_tanh(PyLayer):
@staticmethod
def forward(ctx, x):
y = paddle.tanh(x)
ctx.save_for_backward(y)
return y
@staticmethod
def backward(ctx, dy):
y, = ctx.saved_tensor()
grad = dy * (1 - paddle.square(y))
return grad
class SimpleNet(paddle.nn.Layer):
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(2, 2)
def forward(self, inputs):
inputs = cus_tanh.apply(inputs)
return self.linear(inputs)
if __name__ == '__main__':
dist.init_parallel_env()
model = SimpleNet()
model = paddle.DataParallel(model)
opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
for step in range(10):
x_data = numpy.random.randn(2, 2).astype(numpy.float32)
x = paddle.to_tensor(x_data)
x.stop_gradient = False
# step 1 : skip gradient synchronization by 'no_sync'
with model.no_sync():
y_pred = model(x)
loss = y_pred.mean()
loss.backward()
# step 2 : fuse + allreduce manually before optimization
fused_allreduce_gradients(list(model.parameters()), None)
opt.step()
opt.clear_grad()
代码中的model.no_sync()进入no_sync上下文,在进行本地梯度计算完后,采用fused_allreduce_gradients进行多节点的手动梯度规约。当然,将梯度规约全部放到了模型梯度计算完后,这样显然会比一边计算一边同时装桶进行多节点梯度规约来的慢,因为后者可以隐藏一些通信时间,而前者则完全是串行的过程。不过这也没办法,目前没有其他解决方法,姑且先凑合吧。
——END——
参考资料:
[1] https://pytorch.org/docs/stable/checkpoint.html, TORCH.UTILS.CHECKPOINT
[2]https://www.paddlepaddle.org.cn/documentation/docs/zh/2.2/api/paddle/distributed/fleet/utils/recompute_cn.html#recompute, paddle recompute
[3]https://www.tensorflow.org/api_docs/python/tf/recompute_grad, tf.recompute_grad
[4]https://www.tensorflow.org/versions/r1.15/api_docs/python/tf/contrib, Module: tf.contrib
[5]https://fleet-x.readthedocs.io/en/stable/paddle_fleet_rst/fleet_large_batch_training_techniques_cn.html#forward-recomputation-backpropagation, Forward Recomputation Backpropagation
[6]https://blog.csdn.net/LoseInVain/article/details/78092613, 《深度学习系列》反向传播算法的公式推导
[7]https://blog.csdn.net/LoseInVain/article/details/83108001, 在TensorFlow中自定义梯度的两种方法
[8]https://github.com/FesianXu/ToyAutoDiff, Toy Automatic Differentiation on computation graph
[9]https://blog.csdn.net/LoseInVain/article/details/99172594,在pytorch中对非叶节点的变量计算梯度
[10]https://github.com/pytorch/pytorch/issues/24005, Using torch.utils.checkpoint.checkpoint_sequential and torch.autograd.grad breaks when used in combination with DistributedDataParallel
[11]https://github.com/pytorch/pytorch/issues/24005#issuecomment-519719412
[12]https://pytorch.org/docs/stable/notes/ddp.html, DISTRIBUTED DATA PARALLEL
[13]https://www.paddlepaddle.org.cn/documentation/docs/zh/2.2/api/paddle/DataParallel_cn.html#dataparallel, paddle DataParallel
推荐阅读:
剖析多利熊业务如何基于分布式架构实践稳定性建设
百度工程师的软件质量与测试随笔
百度APP iOS端包体积50M优化实践(一)总览
基于FFmpeg和Wasm的Web端视频截帧方案
百度研发效能从度量到数字化蜕变之路
百度内容理解推理服务FaaS实战——Punica系统