![]()
作者 | 浮生若梦的石头
导读
随着实时计算技术在大数据中的广泛应用,数据的时效性得到大幅度,但是实际应用场景中,除了时效性,还面临着更高的技术要求。
本文结合实时计算的水位技术在流批一体数据仓库中的探索和实践,重点阐述了水位技术的概念和相关理论实践,尤其就水位在实时计算系统中的特性、边界定义和应用,最后重点描述了一种改进的精准水位的设计和实现。该技术架构目前在百度实际业务场景下表现成熟和稳定,借此分享给大家,希望对大家有参考价值。
全文7118字,预计阅读时间18分钟。
01 业务背景
为了提升产品研发、策略迭代、数据分析以及运营决策的效率,业务对数据的时效性要求越来越高。
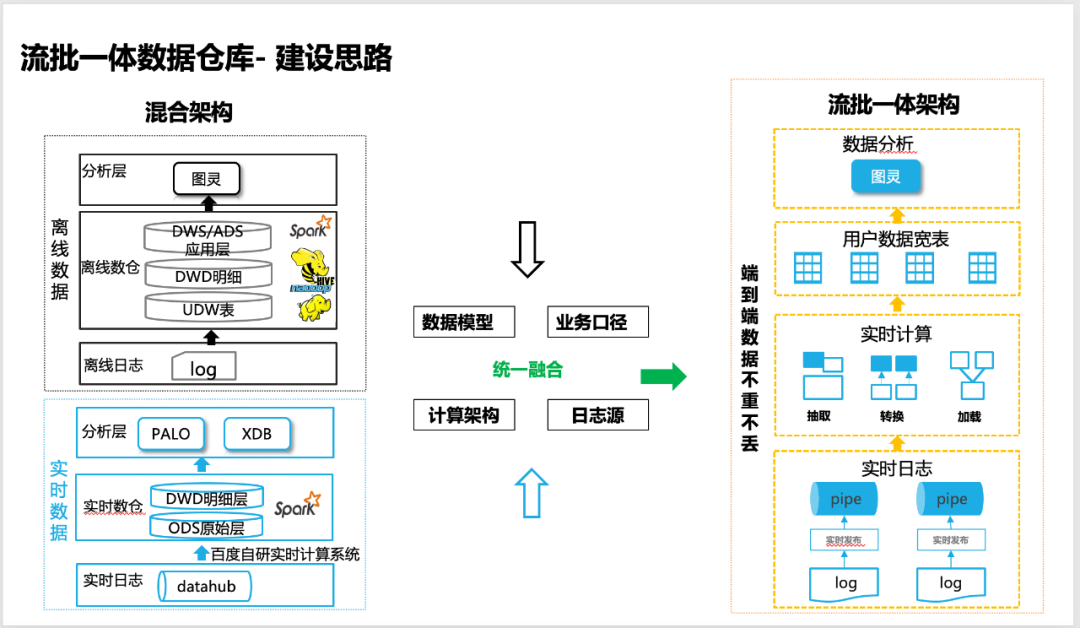
虽然我们很早就基于实时计算实现了实时数据仓库的建设,但是还是无法取代离线数据仓库,实时和离线数据仓库各自一套开发和维护的成本高,最重要的是业务的口径还不能100%对齐。所以我们一直在致力于建设一套流批一体数据仓库,在实现整体数据加工效率提速的同时,还能保证数据如离线数据那样可靠,能支持100%业务场景,从而实现整体降本提效。
![图片]()
△流批一体数据仓库建设思路
02 流批一体数据仓库的技术难点
要想端到端实现流批一体数据仓库,作为底层技术架构的实时计算系统,面临着很多技术难点和挑战:
1、端到端数据的严格不重不丢,以保证数据的完整性;
2、实时数据的窗口和离线数据的窗口,包含数据是对齐的(99.9% ~ 99.99%);
3、实时计算需要支持精准的窗口计算,以保证实时反作弊策略的准招效果;
4、实时计算系统和百度内部大数据生态打通,并有实际大规模线上稳定运行实践。
以上2和3点,都需要高可靠的水位机制来确保实时数据的进度感知和精准切分。
于是本篇文章就精准水位在流批一体数据仓库中的探索和实践的经验,分享给大家。
03 水位概念和通用实现的现状
3.1 水位的必要性
在介绍水位(Watermark)的概念之前,需要先插入2个概念:
Event time, 事件发生时间。我们一般理解为用户真实行为发生的时间,具体对应是日志中记录用户行为发生的时间戳。
Processing time, 数据处理时间。我们一般理解为系统处理数据的时间。
那水位(watermark)具体有什么用处?
在实际实时数据处理过程中,数据是无边界的(Unbounded), 那么基于Window这种窗口计算或其他类似场景就面临一个实际的问题:
怎么知道某个窗口的数据是完整的?什么时候才能触发窗口计算()?
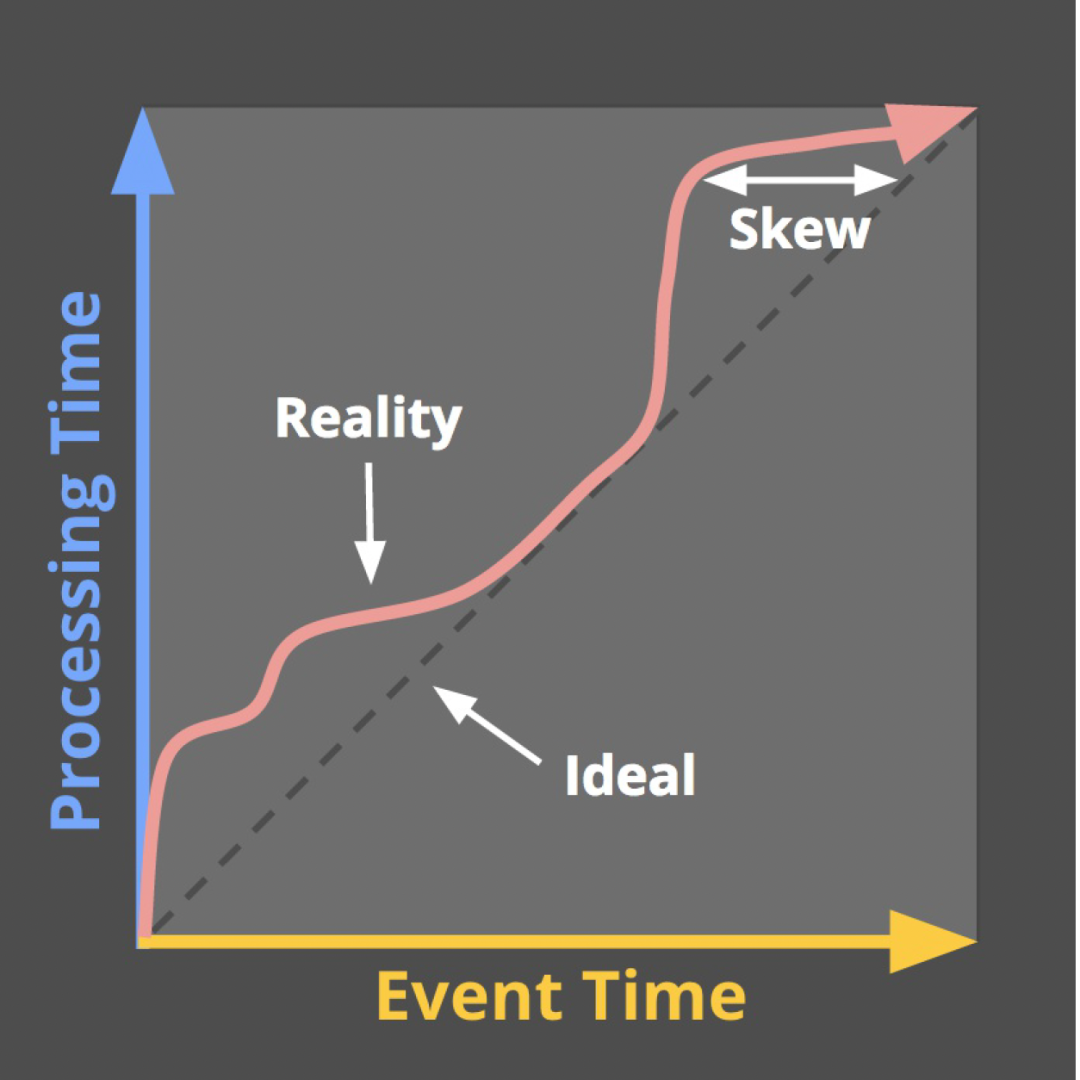
大多数情况下,我们使用Event Time来触发窗口计算(或者数据分区切分,对标离线)。然而实际的情况是实时日志总有不同程度的延迟(在日志采集、日志传输和日志处理等阶段),即如下图所示,实际上会发生水印的倾斜(即数据会出现乱序)。在这种情况下 , Watermark机制就很有必要存在,来确保数据的完整性。
![图片]() △水位倾斜现象
△水位倾斜现象
3.2 水位的定义和特点
水位(watermark)的定义目前业界没有统一的说法,结合**Streaming Systems**一书(作者是Google Dataflow 研发团队)中定义,个人以为比较确切:
The watermark is a monotonically increasing timestamp of the oldest work not yet completed.
从定义我们可以概括出水位的2大基本特性:
然而在实际生产系统中,水位如何去计算,以及实际的效果是什么样子?结合目前业界不同的实时计算系统,对于水位的支持还是不一样的。
3.3 目前水位现状和面临的挑战
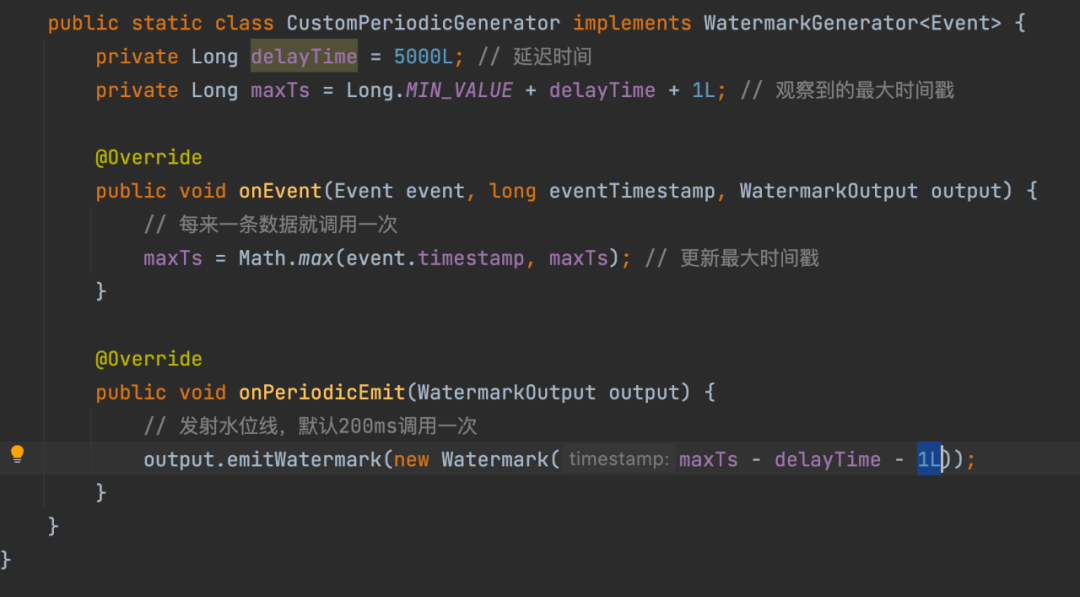
在目前业界的实时计算系统中,比如Apache Flink(Google Dataflow的开源实现)、Apache Spark(仅局限Structured Streaming框架)中,都是支持水位的,下面就以社区最火爆的Apache Flink列举一下水位的实现机制:
![]()
但是以上水位的实现机制和效果,在日志源端出现大面积日志延迟传输的情况下,水位还依旧会更新(新旧数据乱序传输)推进,会导致对应的窗口数据不完整,窗口计算不准确。因此,在百度内部,我们基于日志采集和传输系统、实时计算系统探索了一种改进的、相对精准的水位机制,以确保实时数据在窗口计算、数据落地(sink 到AFS/Hive)等应用场景下,窗口数据的完整性问题,以满足实现流批一体数据仓库的要求。
![图片]()
△Flink中水位生成策略
GEEK TALK
04 全局水位的设计和应用
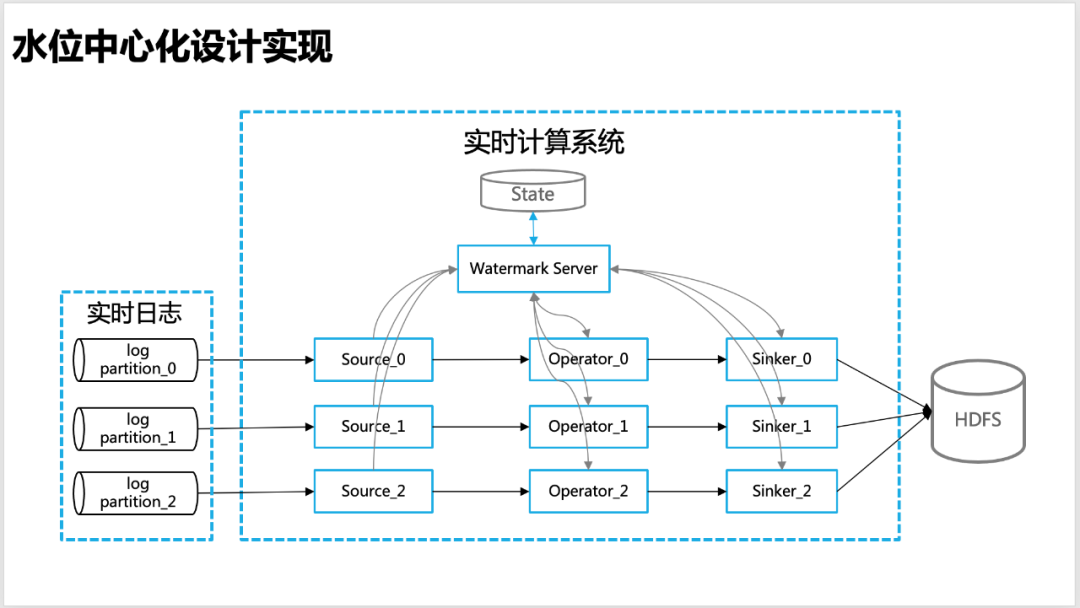
4.1 水位中心化管理的设计
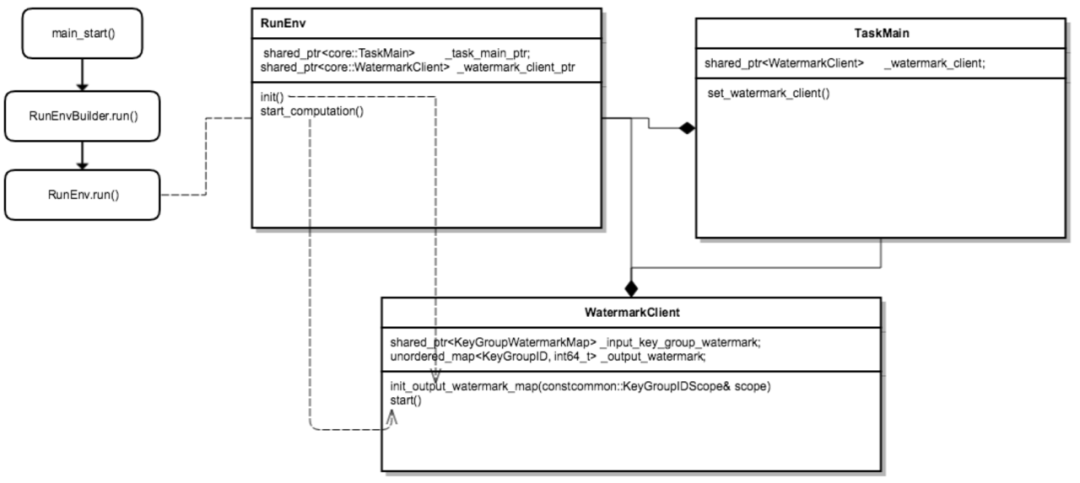
为了使得水位在实时计算中更精准,我们设计出一种中心化的水位管理思路,即实时计算的各个节点,包含source、operator、sinker等都会把自己计算的水位信息,统一上报给全局的Watermark Server,由Watermark Server 来进行水位信息的统一管理。
![图片]()
△中心化水位设计
Watermark Server :维护一个水位的信息表(hash_table),包含实时计算程序(APP)整体拓扑信息(Source、Operator 和Sinker等)各个层级对应的水位信息,以便于进行全局水位(比如low watermark)的计算,Watermark Server 定期和state做交互,以保证水位信息的不丢失。
Watermark Client:水位更新客户端,在source、worker和sinker等实时算子中,负责向Watermark Server 上报和请求水位信息(比如上游或者全局水位),通过baidu-rpc服务请求回调。
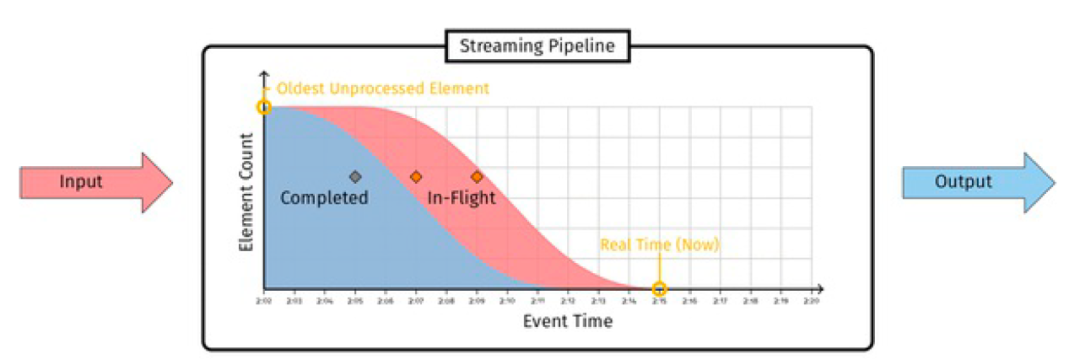
Low watermark(低水位):Low watermark是一个时间戳,用来标记实时数据处理过程中最早(oldest)的没有处理的数据的时间(Low watermark, which pessimistically attempt to capture the event time of the oldest unprocessed record the system is aware of.)。它承诺未来不会有早于该时间戳的数据到达。这里的时间计算一般基于eventtime,即事件发生时间,例如日志中用户行为发生的时间,而较少使用数据处理时间(processing time,某些场景也可以用),watermark计算的公式为(来自Google MillWheel 论文):
Low Watermark of A = min(oldest work of A, low watermark of C : C outputs to A)
![图片]()
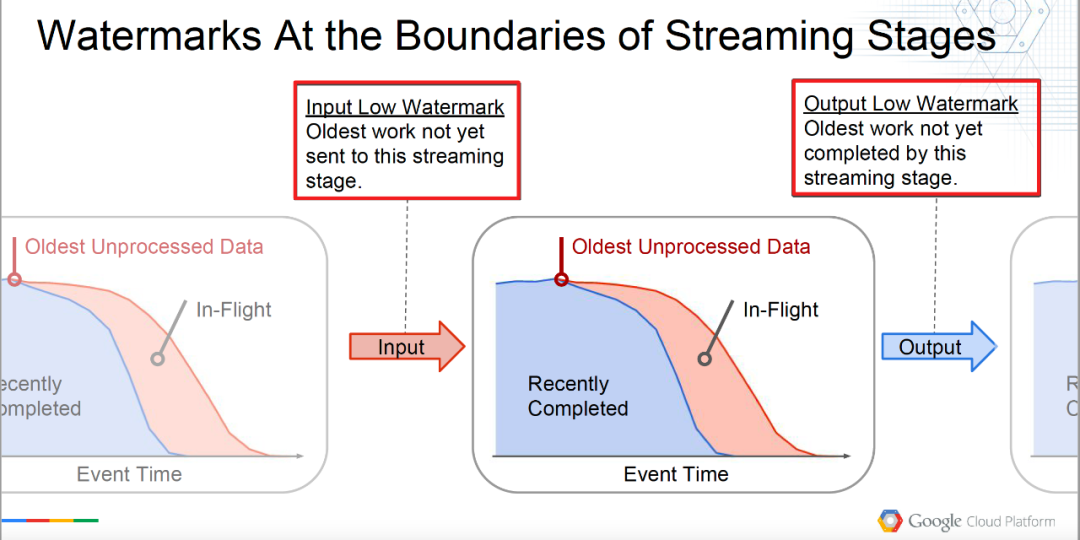
但是在实际系统设计中,low watermark又可以按照算子处理的边界区分如下:
Input Low Watermark: Oldest work not yet sent to this streaming stage.
InputLowWatermark(Stage) = min { OutputLowWatermark(Stage’) | Stage’ is upstream of Stage}
输入最低水位,可以理解为将要输入当前算子,即上游算子处理过的数据的watermark。
Output Low Watermark: Oldest work not yet completed by this streaming stage.
OutputLowWatermark(Stage) = min { InputLowWatermark(Stage), OldestWork(Stage) }
输出最低水位,可以理解为当前算子未处理过数据的最早的(oldest)水位,即处理过数据的水位。
具体如下图所示,理解会更形象些。
![图片]() △Low watermark的边界定义
△Low watermark的边界定义
4.2 如何实现精准水位
4.2.1、精准水位的前提条件
目前实时计算系统在实时数据仓库的应用场景,我们都是使用low watermak来触发窗口计算(因为这样更可靠),从3.1中low watermark的定义我们可知:low watermark是层级迭代计算的,水位是否精准,取决于最上游(即source)水位的精准度。于是为了提升源头水位计算的精准度,我们需要前提条件:
![图片]()
△日志打包信息
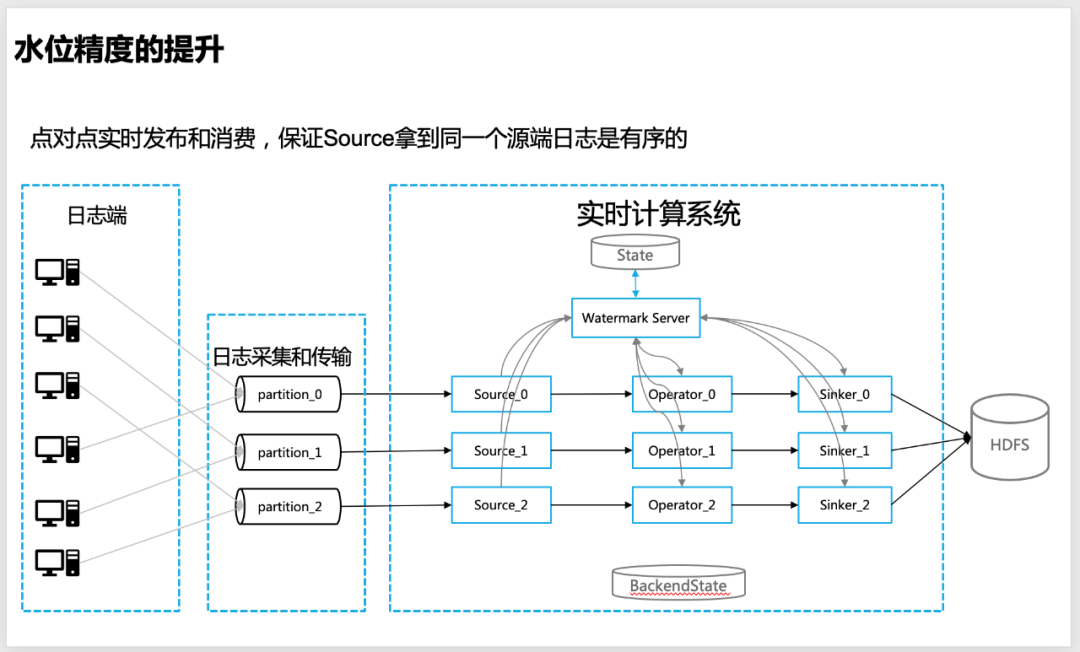
日志是实时点对点发布到消息队列,以保证消息队列单个分区(partition)内,单个服务器的日志是严格有序的
![图片]()
△源端日志点对点发布到消息队列,保证单分区日志是有序的
4.2.2、水位的计算方式
1、Watermark server
初始化:
首先作为独立的线程(thread)启动。根据配置的日志传输任务的BNS(Baidu Naming Service,百度名字服务,提供服务名称到服务端所有运行实例的映射)来解析日志源的服务器列表(hostname list);根据配置的APP拓扑关系,初始化watermark信息表,并持久化写入Table(百度分布式kv存储引擎)。
普通水位信息更新:接收到Client到水位信息并更新对应粒度(Processor粒度或者keygroup粒度)的水位,对局部水位进行更新
精准水位计算:
现实中,如果要求源端的日志100%都精确的到达,会造成频繁的延迟或者延迟太久(如果下发采用全局Low watermark逻辑)。原因是:在日志端服务器实例太多的情况下(比如实际上我们有的日志有实例6000 - 10000个),总有线上服务的实例会出现日志实时上传的延迟的情况,那么这就需要在数据的完整性和时效性之间做一个折中,比如以百分比的形式来精准控制允许延迟的实例个数(比如配置99.9% 或者99.99%来设置允许源端日志出现延迟的比例),来精准控制最源端水位的精确度。
精准水位需要特殊配置,根据Source端实时上报的服务器和日志进度的映射关系,以及配置的允许延迟实例的比例,来计算Source端的output low watermark。
计算全局low Watermark:会计算一个全局最小的水位,返回给Client端的请求
状态持久化:定期把全局水位信息持久化写入外部存储,以便于状态恢复
2、Watermark Client
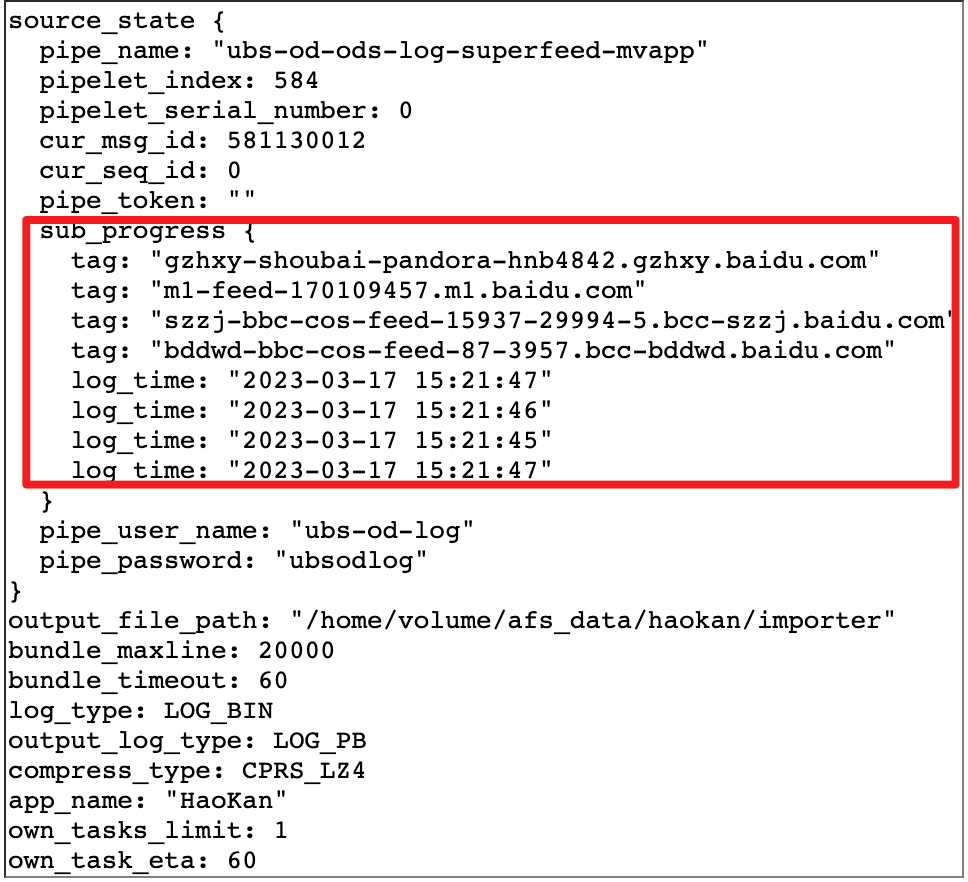
Source 端:解析日志包,并获日志包里面的机器名等信息和原始的日志。原始日志经过ETL处理后,并根据原始的日志获取最新时间戳(event_timestamps),Source通过Watermark Client API 把解析到hostname和最新时间戳(event_timestamps)的映射关系表定期上报(目前配置的1000ms)到Watermark Server。
![图片]()
△Source通过解析日志获取的服务器和日志进度映射关系
Operator端:
Input low Watermark计算 : 获取上游(Upstream)的output low watermark,作为input low watermark来决定是否触发窗口计算等操作;
output low Watermark计算:根据日志、状态(state)等处理进度(oldest work)来计算自己的output low watermark,并上报到Watermark Server,以便于下游算子(Download Processor)使用。
![图片]()
△Watermark Client 工作流程
Sinker端:
Sinker端和上面的普通实时算子(Operator)一样,会计算Input Low Watermark和 Output Low Watermark来更新自己的水位,
额外需要请求一个全局的Low Watermark 来决定数据的输出窗口是否关闭。
4.3 精准水位在系统间的传递
水位传递的必要性
很多时候,实时系统并不是孤立的,多个实时计算系统之间存在着数据的交互,最为常见的方式是两个实时数据处理系统是上下游的关系。
具体表现为:两个实时数据处理系统之间通过消息队列(比如社区的Apache Kafka)来实现数据的传递,那么在这种情况下,如何实现精准水位的传递呢?
具体实现步骤如下:
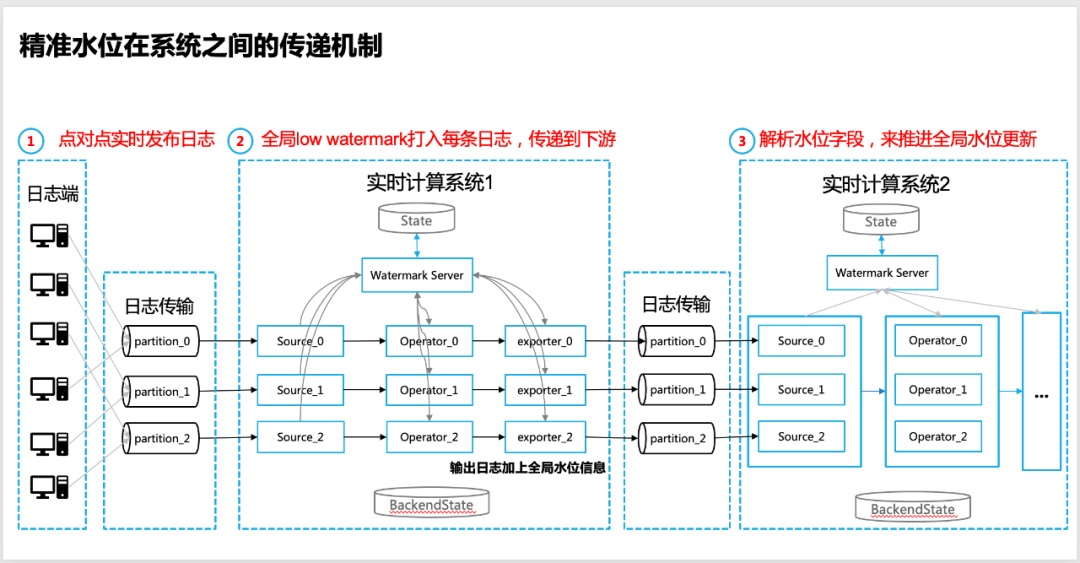
1、上游实时计算系统的日志源,保证日志是点对点发布的,这样可以保证全局水位的精准度(具体比例是可调的);
2、在上游实时计算系统的输出端(sinker/exporter 到消息队列端),需要保证使用全局low watermark的下发,目前我们采用把全局水位信息打印到每条日志上面来实现传递;
3、在下游实时数据计算系统的Source端,需要解析日志携带的水位信息字段(来自上游实时计算系统),并开始作为水位的输入(Input Low Watermark),开启层层水位的迭代计算和全局水位的计算;
4、在下游实时数据计算系统的Operator/Sinker端,可仍旧可以用日志的Event Time来实现具体数据切分,来作为窗口计算的输入,但是触发窗口计算的机制,仍旧以Watermark Server 返回的全局Low Watermark为准,以保证数据数据的完整性。
![图片]()
△精准水位在实时计算系统之间的传递机制
05 实际效果和后续展望
5.1 实际线上效果
5.1.1 落地数据的实测效果(完整性)
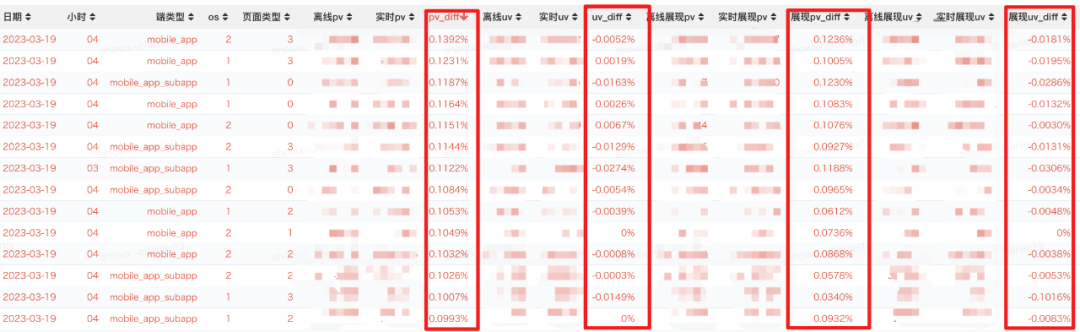
实际线上测试,采用精准水位(配置水位精度99.9%,即只允许千分之一的源端实例延迟),在日志没有延迟的情况下,实时落地的数据和离线数据,在同一个时间窗口(Event Time)下效果对比如下(基本都是十万分以下):
![图片]()
△源端日志没有延迟的情况下数据完整性效果
在源端日志出现延迟的情况下(<=0.1%源端日志实例延迟的情况下,水位还会持续更新),数据diff效果整体基本在千分之1 左右(受到日志源端点对点日志本身可能存在数据不均情况的影响):
![图片]()
在源端日志出现大面积延迟的情况下(>0.1%源端日志实例延迟的情况下),由于使用了精准的水位机制(水位精度99.9%),全局水位不会更新,实时数据写AFS的窗口不会关闭,一直等待延迟数据的到来和全局水位得更新才会关闭窗口,以保证数据的完整性,实际测试结果如下(在千分之1.1-千分之1.2之间,受到日志源端实例本身存在不均情况的影响):
![图片]()
5.2 总结和展现
经过实际精准水位的研究和实际线上的应用,基于精准水位的实时数据仓库,在具备时效性提升的同时,具备了更高、灵活数据的精度机制,在稳定性优化后,实际上完全已经替代之前的离线和实时两套数据仓库系统,实现了真正意义上的流批一体数据仓库。
同时基于中心化的水位机制,也后续面临着性能优化、高可用(故障恢复机制的完善)和更精细粒度精准水位的挑战(在窗口计算触发机制下)。
——END——
参考文献:
[1] T. Akidau, A. Balikov, K. Bekiroğlu, S. Chernyak, J. Haberman, R. Lax, S. McVeety, D. Mills, P. Nordstrom, and S. Whittle. Millwheel: Fault-tolerant stream processing at internet scale. Proc. VLDB Endow., 6(11):1033–1044, Aug. 2013.
[2] T. Akidau, R. Bradshaw, C. Chambers, S. Chernyak, R. J. Fernández-Moctezuma, R. Lax, S. McVeety, D. Mills, F. Perry, E. Schmidt, et al. The dataflow model: a practical approach to balancing correctness, latency, and cost in massive-scale, unbounded, out-of-order data processing. Proceedings of the VLDB Endowment, 8(12):1792–1803, 2015.
[3] T. Akidau, S. Chernyak, and R. Lax. Streaming Systems. O’Reilly Media, Inc., 1st edition, 2018.
[4] "Watermarks - Measuring Time and Progress in Streaming Pipelines", Slava Chernyak , Google Inc
[5] P. Carbone, A. Katsifodimos, S. Ewen, V. Markl, S. Haridi, and K. Tzoumas. Apache flink: Stream and batch processing in a single engine. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 36(4), 2015.
推荐阅读:
视频编辑场景下的文字模版技术方案
浅谈活动场景下的图算法在反作弊应用
Serverless:基于个性化服务画像的弹性伸缩实践
图片动画化应用中的动作分解方法
性能平台数据提速之路
采编式AIGC视频生产流程编排实践

 △水位倾斜现象
△水位倾斜现象
 △Low watermark的边界定义
△Low watermark的边界定义