1背景
公司存在多种物料种类、不同类型的库存和价值管理不一,存货系统目前主要接入包装耗材、商品数据。目的是为了:
- 管理出入库价格、数量、库龄等业务数据,便于管理部门追溯及财务管控,协助仓库提升存货和物料的管理能力。
- 管理仓库物料及商品的费用价值,提升核算及业务的效率,实现业务信息一体化及凭证自动化。
- 辅助计划或采购部门查看库存,为采购计划提供数据支撑。
存货系统先接入了包耗材数据,这类数据的特性是行数据不多,但每行数量很大。后接入了商品的库存,由于行数据量增长N倍以上 ,并且随着业务不断增长数据量越来越大,考虑到原有底层设计不能很好的支撑这么大的数据量,故有了这次系统的模型升级。
2面对的问题
2.1 数据承接点问题
原业务流程在数据承接上跨越了核心P0链路后才把数据落地到库存应用(造成了一定的技术风险,历史上也确实发生过一次技术故障 ,消费上游消息代码有bug,导致P0清结算链路数据下发出现阻塞,影响了部分结算单据的处理时效):
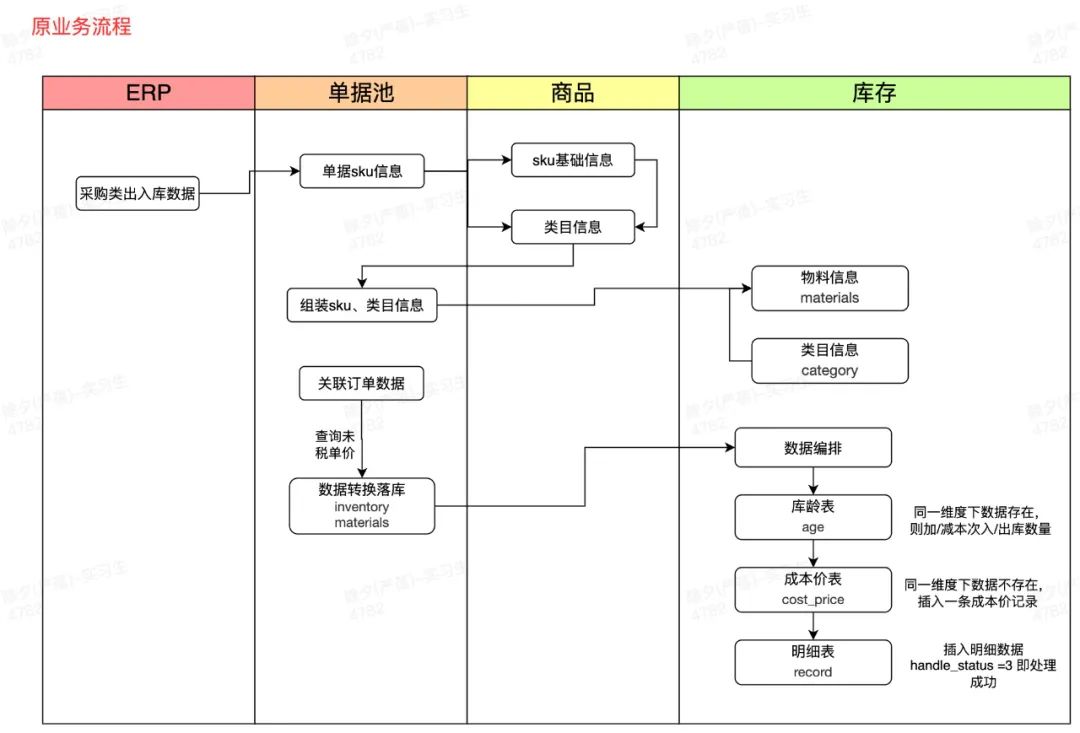
(1)数据落库在单据系统 (2)关联订单数据 (3)查询出未税单价 (4)组装后下发库存 ![640.jpg]()
重构前的设计,成本表存储逻辑:不管每天成本价有没有变化,都会维护一条记录;台账表存储逻辑:每天如果有出入库数据按照业务类型汇总+2条期初期末数据,如果没有出入库数据,只保存2条期初期末数据。从存储逻辑不难看出存储了很多冗余数据,且台账表期初期末数据以行的形式存储也是不合理的。
如下是例子数据
2.2.1 明细表(record)
每天出入库、调价单的数据
![image.png]()
2.2.2 成本表(cost_price)
所有物料每天都需要计算一个成本价 ![image.png]()
2.2.3 台账表(ledger)
日台账:汇总当天明细数据、以及期初、期末价格和数量 月台账:汇总当月明细数据、以及期初、期末价格和数量
![image.png]()
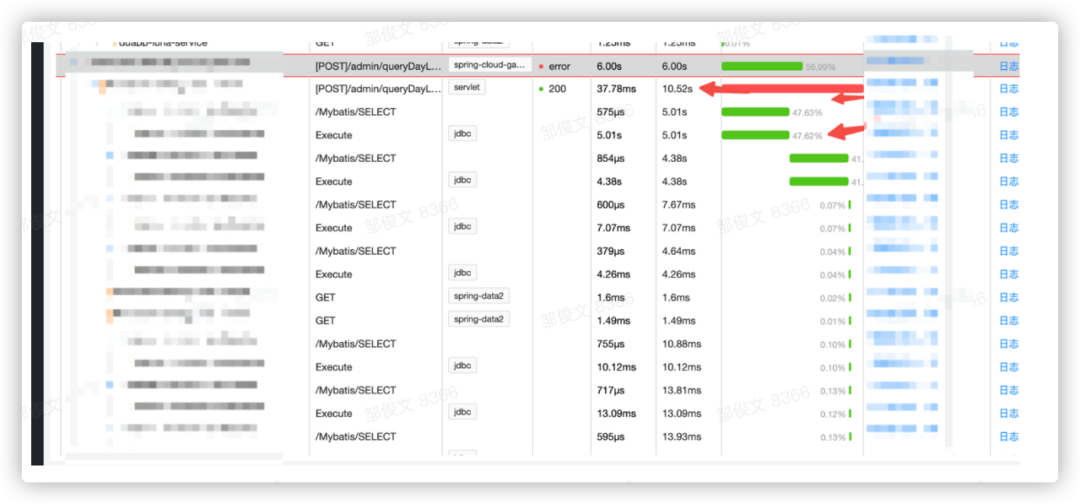
2.3 页面数据查询性能瓶颈
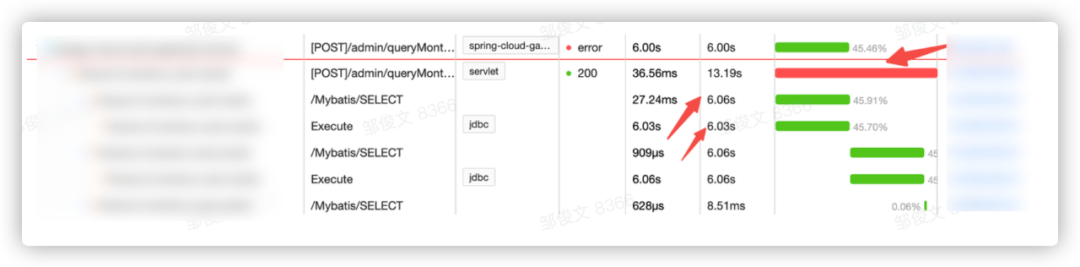
2.3.1 大盘&台账表分析:
通过大盘和台账表分析,在接入仓库商品数据后,页面查询接口耗时很高,接口性能存在问题
![640.png]()
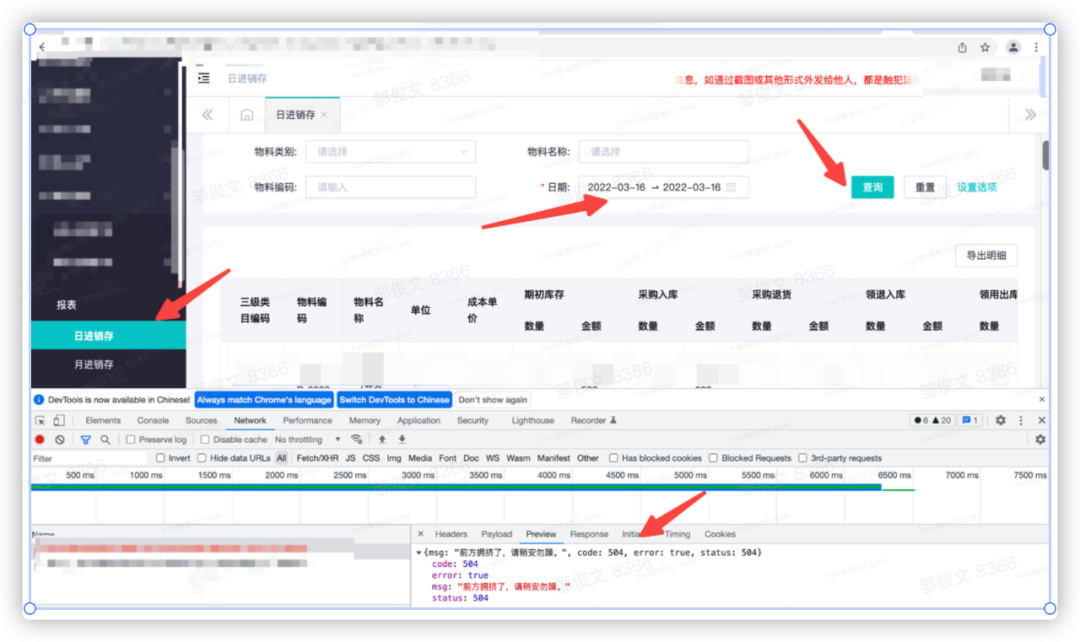
2.3.2 日/月进销存也面临同样的问题
![6401.png]()
![6402.png]()
3解决方案
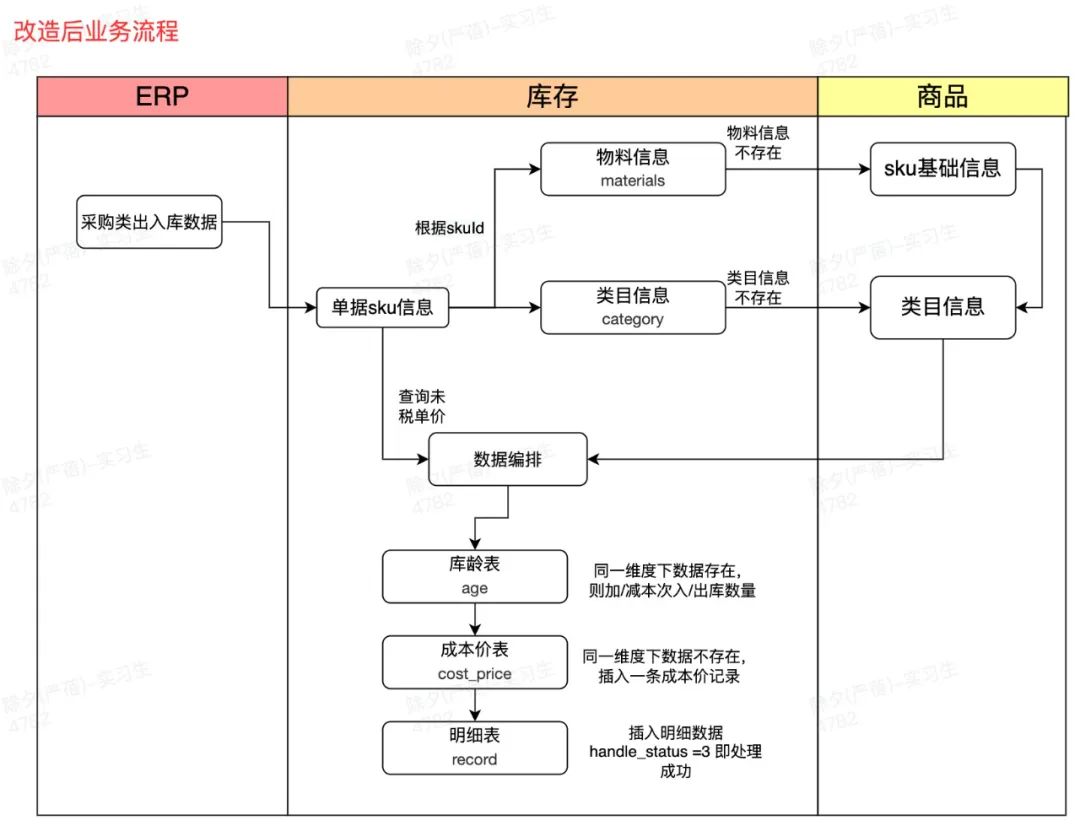
3.1 数据承接优化
3.1.1 库存应用直接承接单据池落地信息表
![6401.jpg]()
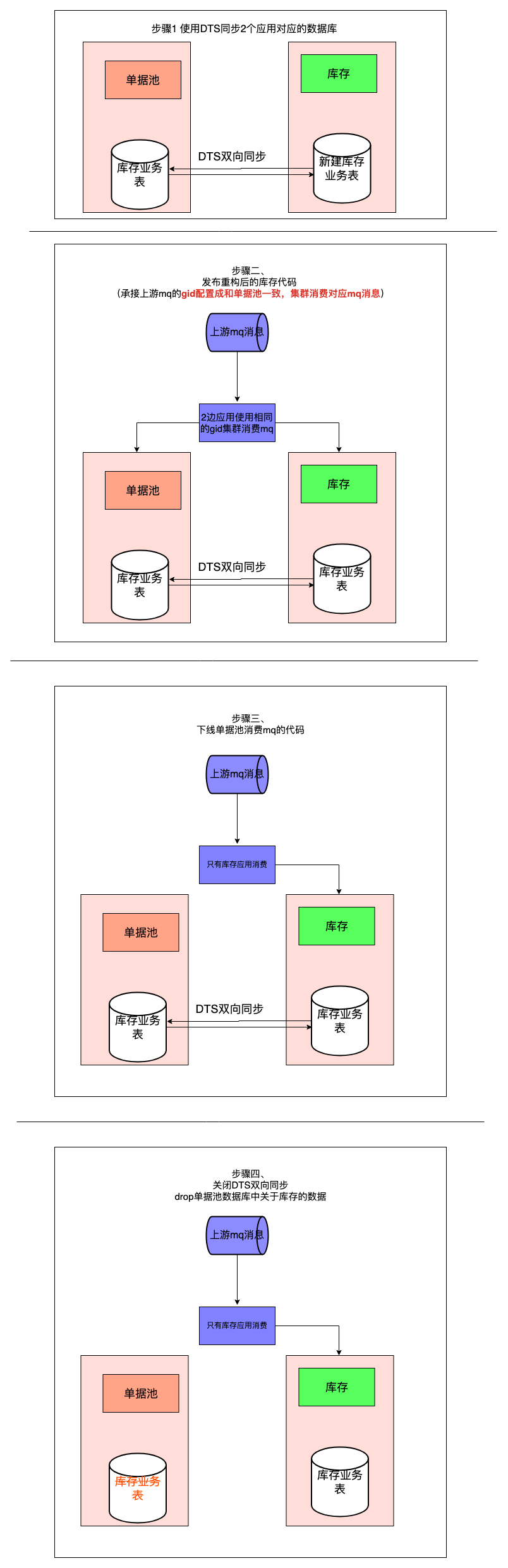
3.1.2 具体实现过程
![6403.png]()
3.2 数据存储设计问题优化
3.2.1 简单示例
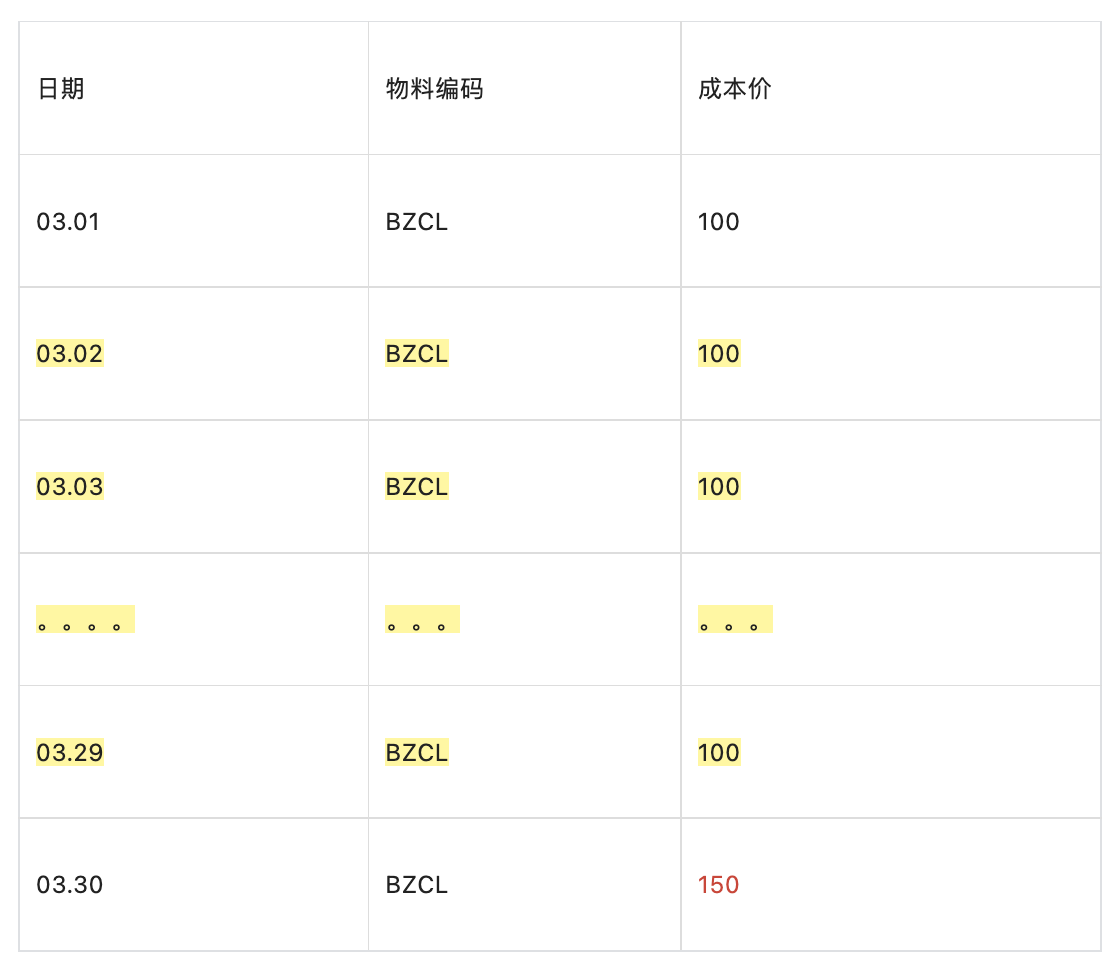
比如一个物料,3月1日的成本价为100元,后在3月30日又进一件成本价200元的相同物料,则我们库里的记录信息如下, 2条数据即可 , 【无须每日更新数据,只有当前物料当日有出入库、调价数据时,才需要插入当日最新数据】,
实际场景,当业务代码查询3月10日的成本价时,往前查询到03.01的数据即可
3.2.2 期望的数据存储样式
![image.png]()
而不是30条数据 ( 03.02 至 03.29,这28条数据都是冗余的数据) ![image.png]()
3.2.3 页面数据查询性能瓶颈解决方案
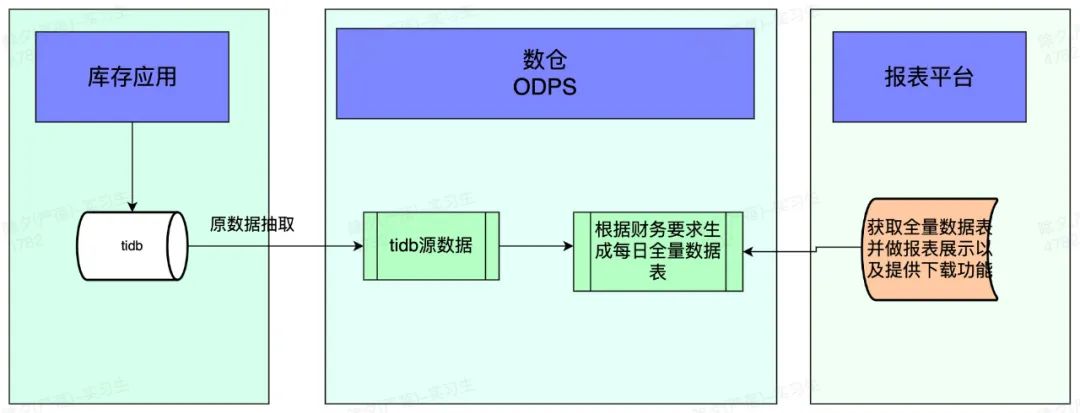
由于数据存储逻辑变更,只会存储有变动的数据,而进销存报表是每天都需要产出的不管数据有没有变化。结合当前业务逻辑以及数据量最后决定把数据同步到数仓,在数仓进行数据补全后,通过报表平台拉取报表信息。
弃用当前后管平台查询报表 转为使用报表平台拉取库存报表信息
数据同步流程如下: ![6402.jpg]()
报表平台具备生成类似于Excel的数据展示,以及任意维度查询信息的能力,同时也具备Excel导出的功能
![6404.png]()
4重构后的价值
4.1 量化业务价值:
每月节省核算以及审核时间约30小时,占核算组总月结时间比例为30%。
4.2 不可量化业务价值
将仓库业务纳入存货系统,庞大数据量通过系统自动核算,输出表格,节约手工核算的时间,以及提升核算数据的准确性,解决无法通过表格实现的困境;
提升核算质量的同时,可以完成更多库存、销售数据分析,如周转率分析,出入库渠道分析,减值计提等等。分析结果提升公司退货商品的管理以及库存管理。
功能重构从基础数据、入库模型、调价单、成本计算、出库模型、重算、报表都做了升级,在数据接收、成本计算等过程中增加了校验逻辑和修复数据的功能。
4.3 技术价值
(1)技术价值:首次尝试了在线TIDB切换流程(包括数据复制、数据同步、数据比对、数据切流),积累了TIDB切换经验,给后续的TIDB迁移专项提供了经验沉淀。
(2)技术价值:把P0级的清结算应用里的部分功能迁移到库存应用中,解决了大流量的仓库数据下传至清结算应用的风险,实现了交易和非交易在应用级别的解耦和隔离。
(3) 团队价值:以赛代练,通过该项目培养了组内成员对于数仓平台和报表平台的实践和使用,拓宽了团队整体的技术栈,并积累了数据开发的对应经验,也落地了数仓平台和报表平台的操作使用文档(节省了后续团队成员的数据开发熟悉接入的成本)。
作者:得物技术
链接:https://juejin.cn/post/7208817904559833149
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。