最近在排查一个sparkstreaming在操作kafka时,rebalance触发了一个异常引起任务失败,而组内小伙伴对消费者组的一些基本知识不是很了解,所以抽了些时间进行相关原理的整理。本文就来聊聊相关内容。
【消费者组的基本原理】
在kafka中,多个消费者可以组成一个消费者组(consumer group),但是一个消费者只能属于一个消费者组。消费者组保证其订阅的topic的每个分区只能分配给该消费者组中的某一个消费者进行处理,那么这里可能就会出现两种情况:
当消费者组中的消费者个数小于订阅的topic的分区数时,那么存在一个消费者到多个分区进行消费的情况;
而如果消费者组中的消费者个数大于订阅的topic的分区数时,那么就会有一部分消费者分配不到分区信息,出现消费者浪费的情况。
另外,如果不同的消费者组订阅了同一个topic,不同的消费者组彼此互不干扰。
【消费者组的原理深入】
1. group coordinator的概念
在早期版本中(0.9版本之前),kafka强依赖于zookeeper实现消费者组的管理,包括消费者组内的消费者通过在zk上抢占znode节点来决定消费哪些分区;注册消费者组和broker相关节点的监听,以感知环境的变化进而触发rebalance;另外就是offset也维护在zk中。
这种方式除了强依赖于zk,导致zk压力较大之外,还容易引发其他问题,例如:
一个被监听的zk节点发生变化,导致大量的通知消息推送给所有监听者(即消费者),另外就是脑裂引起的不一致问题,引发rebalance混乱。
基于以上原因,从0.9版本开始,kafka重新设计了名为group coordinator的协调者负责管理消费者的关系,以及消费者的offset。注意每个消费者组都有一个对应的group coordinator实例。
2. 消费者与broker的交互流程
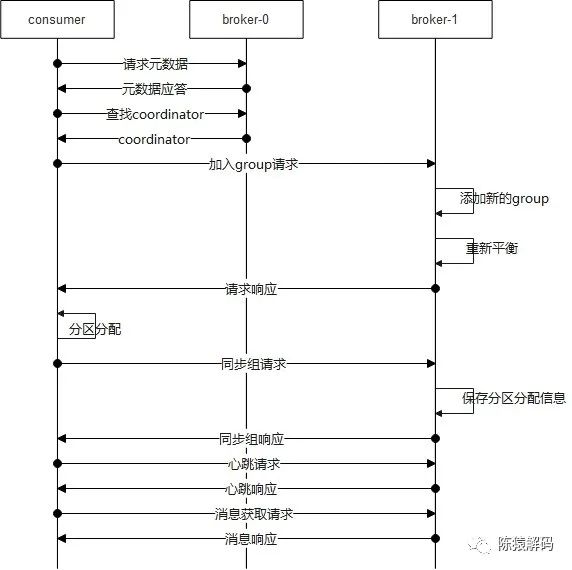
消费者组中消费者与broker之间的交互流程如下图所示:
![]()
1)首先,和所有客户端的逻辑一样,先向服务端请求元数据信息
2)接着向服务端请求消费者组的coordinator,得到coordinator所在的brokerid后,向对应broker建立连接并发送请求加入消费者组的请求,服务端收到请求后,判断消费者组是否存在,不存在则创建消费者组,并将该消费者加入到消费者组中,然后给予请求应答,对于第一个加入消费者组的消费者成为leader,在加入消费者组的应答中会告知成员信息,以及leader的信息。这样客户端可以知道自身是否成为leader。
3)此后,对于leader的消费者根据分区分配策略,进行分区分配,然后向broker发送同步消费者组(SyncGroup)的请求,请求中包含分区分配的信息。服务端,收到请求后,服务端保存分区分配信息,并进行请求应答响应。
这里需要注意的是:对于非leader的消费者同样会发送同步消费者组的请求,只是请求中没有分区分配的信息而已。
4)再然后,消费者与broker之间进行定时的心跳交互,服务端以此判断消费者的存活状态。
5)最后,消费者进入轮询阶段,向服务端发送消息获取(fetch)请求进行消息的消费。
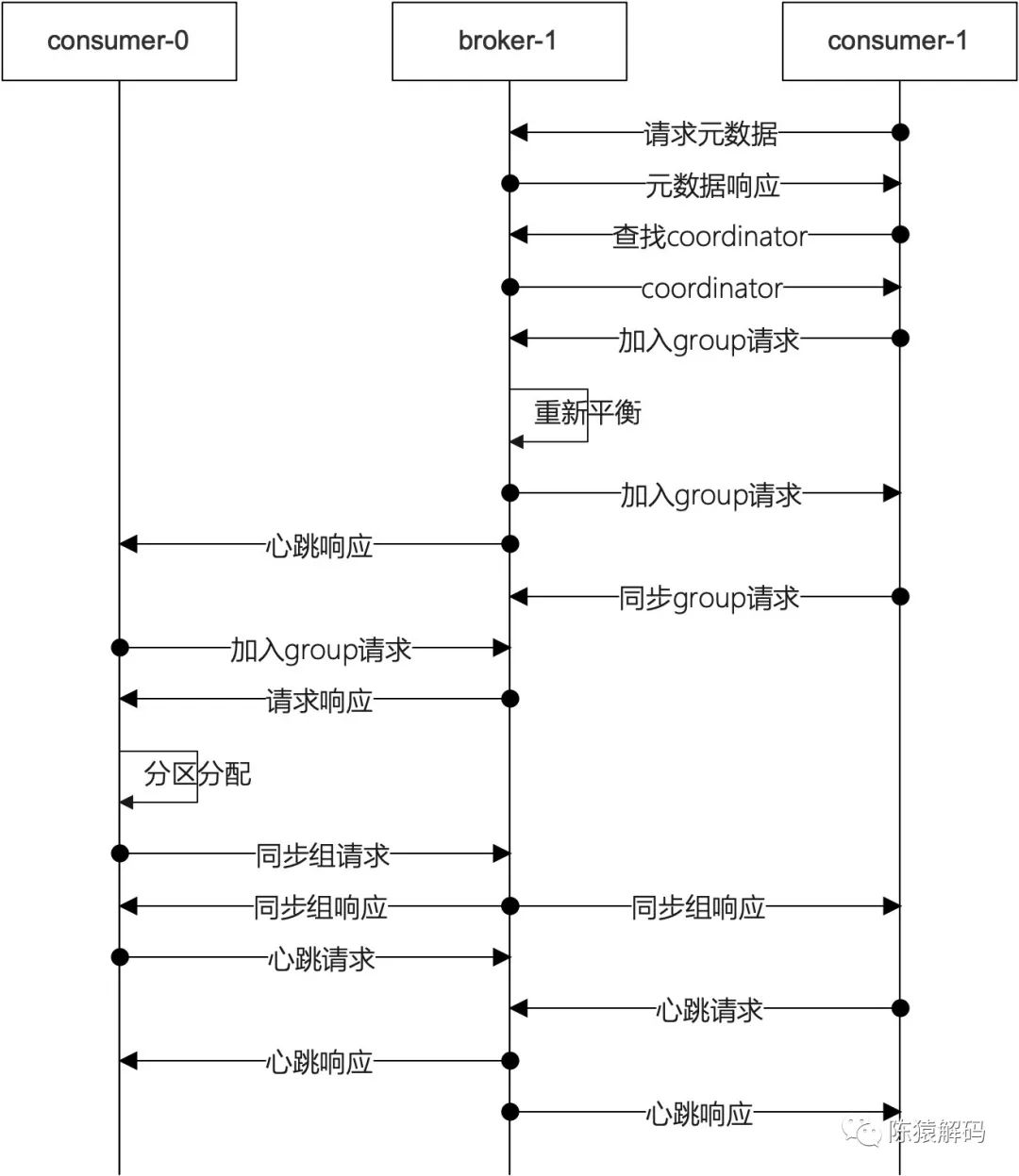
3. rebalance的流程
当消费者组有新成员加入或已有成员退出;或者topic分区(新增)发生变更时,服务端会触发重新分配分区的逻辑,这就是所谓的rebalance。
具体实现,服务端是通过在心跳中给leader对应的消费者一个错误信息,消费者在捕获该错误信息后,触发重新加入消费者组,之后复用之前的流程, 即在加入消费者组的请求响应中,告知消费者组中消费者的情况,leader的消费者重新进行分区分配,然后通过同步组请求告知服务端新的分区分配情况。
其大概流程如下图所示:
![]()
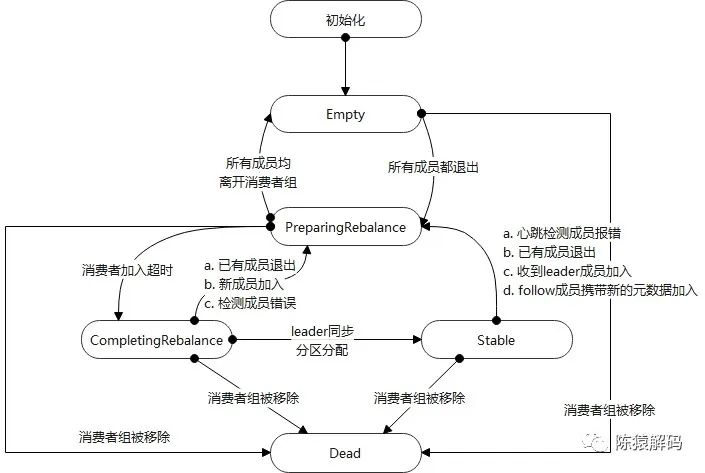
4. 服务端的相关逻辑
在服务端,coordinator分别维护了消费者组的信息,其中通过一个状态机来实现不同事件引起的各个不同处理操作,状态机的各个状态跳转,以及触发的事件如下图所示:
![]()
除此之外,还包括消费者组的成员信息、leader信息、generationId、以及偏移量的相关信息等。
5. 分区分配策略
首先,客户端可以通过"partition.assignment.strategy"参数进行分配策略的配置,当前可选的策略包括:
org.apache.kafka.clients.consumer.RangeAssignor
org.apache.kafka.clients.consumer.RoundRobinAssignor
org.apache.kafka.clients.consumer.StickyAssignor
org.apache.kafka.clients.consumer.CooperativeStickyAssignor(新版本增加)
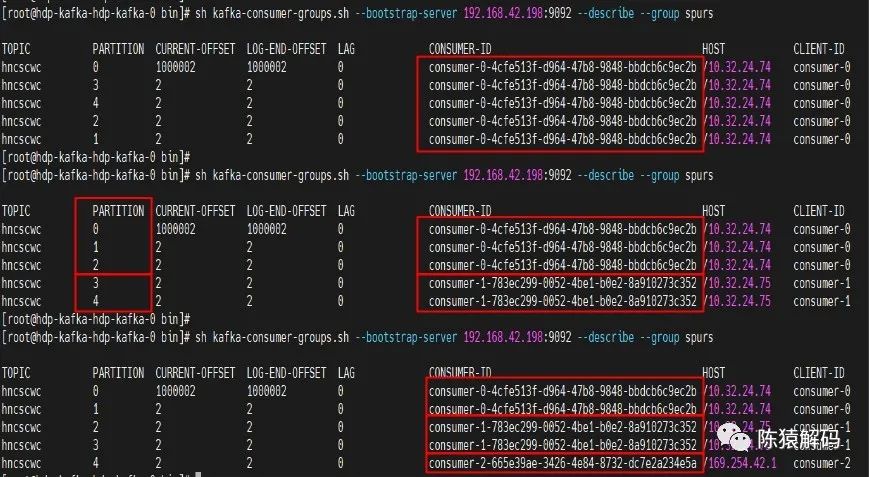
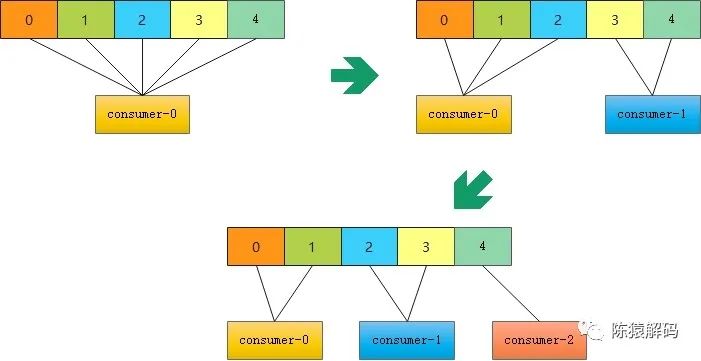
对于RangeAssignor,字面意思是按分区范围来进行分配的,具体分配逻辑是:针对每个topic,n=分区数/消费者个数,m=分区数%消费者个数,前m个消费者每个分配n+1个分区,后面的(消费者个数减去m)消费者每个分配n个分区。
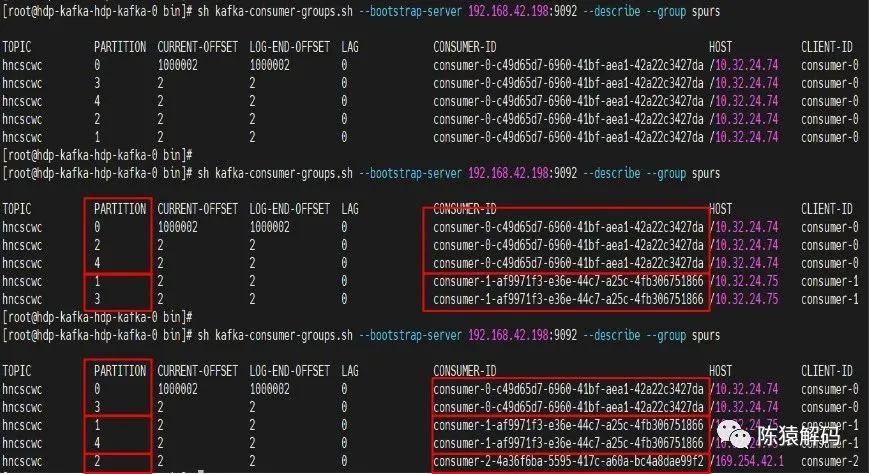
下面为实测三个消费者组依次加入同一个消费者组,并订阅一个具有5分区的topic的情况:
![]()
更直观一点的图如下所示:
![]()
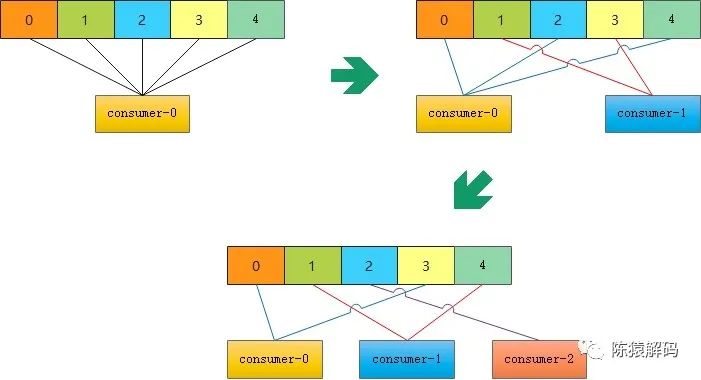
RoundRobinAssignor则是将所有消费者按照消费者ID字典序进行排序,同时将所有topic的所有分区也按字典序进行排序,再轮询进行分配。
同样实测情况与直观的图示如下:
![]()
![]()
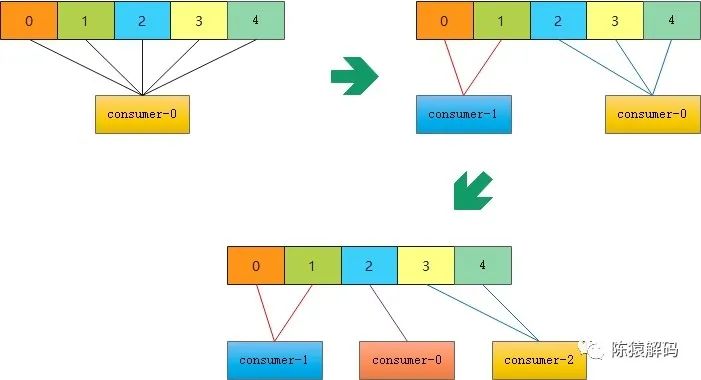
StickyAssignor是在kafka的0.11版本引入的,其设计目的主要有两个:
StickyAssignor的具体分配逻辑略复杂,本文不打算展开说明,来看下实际效果。
同样是三个消费者先后加入同一个消费者组后的分区情况:
![]()
![]()
从图中可以看出,与前面的RoundRobinAssignor相比,第三个消费者(consumer-2)加入后,前两个消费者的分区几乎没有变动。
【小结】
小结一下,本文主要讲述了kafka中,消费者组的基本概念与原理,在阅读源码过程中,其实发现还有很多内容可以再展开单独分析,例如服务端在处理加入消费者组请求时,采用了延时处理的方式,更准确的说,内部大量采用了时间轮加延时处理机制来响应客户端的请求;例如group coordinator所在节点异常后,迁移逻辑是怎样的保证其高可用等等。
另外一大块内容,消费者组中消费者的偏移量是如何保存的,其交互逻辑又是怎样的。这一部分内容作为(下)部分内容再单独介绍。
好了,这就是本文的全部内容,如果觉得本文对您有帮助,请点赞+转发,如果觉得有不正确的地方,也可以拍砖指点,最后,欢迎加我微信交流~