作者: pepezzzz 原文来源:https://tidb.net/blog/086d700a
引言
Oracle 的聚簇因子:
表中建立了索引的数据排序优良度的一个度量值;向优化器表明了具有同样索引值的数据行是不是存放在同一个或连续的一系列数据块中,或者数据行是否被分散存放在表的多个数据块中。简单地说,Oracle 数据库的聚簇因子信息,能反映出索引范围扫的回表成本。# 从案例看 cop task## 案例1下图是一个 SQL 的执行计划,选中行是 IndexLookUp 算子回表后过滤算子。![image.png]() 从右侧 Operator Info 栏中的可见,416 行的索引回表过滤需要使用 26 的 cop task,可以简单地认为 416 行表数据处于 26 个 region 中。经过数据 “按序” 的导出和导入:a. dumpling --sql “select * from a order by cus_id” -F 100MiB --output-filename-template …b. tidb-lightning下图是 SQL 的新执行计划,执行计划完全一样,效率有较大的提升。
从右侧 Operator Info 栏中的可见,416 行的索引回表过滤需要使用 26 的 cop task,可以简单地认为 416 行表数据处于 26 个 region 中。经过数据 “按序” 的导出和导入:a. dumpling --sql “select * from a order by cus_id” -F 100MiB --output-filename-template …b. tidb-lightning下图是 SQL 的新执行计划,执行计划完全一样,效率有较大的提升。![]() 从右侧 Operator Info 栏中的可见,416 行的索引回表过滤仅需要使用 4 的 cop task,可以简单地认为 416 行表数据仅处于 4 个 不同 region 中,相关的数据“聚集”后,回表的开销降低了,网络的请求变快了,高并发情况下尤为明显。## 案例2单表 500 万的数据删除主键后进行“翻数”,重复插入 200 次,得到一个 10 亿记录的表。查询 SQL:select * from t where col1='1' ,col1 列上有二级索引。进行压测时,报:Coprocessor task terminated due to exceeding the deadline。可以认为,由于 10 亿记录的表通过以上的翻数操作得到,数据处于非常 “均匀” 的分散,单条语句的二级索引回表的 cop task 固定为 200,在高并发情况下,极容易触发以上的报错信息。通过相同的“数据整理”步骤,单语句 SQL 效率提升较大。## Region 与 cop taskRegion 是 TiDB 中计算、存储、调度的单元。计算单元的含义,大致可以理解为,cop 请求也会以 region 为单位进行分发。上述案例中,由于数据较为分散,即相同索引值的数据分布在较多的 region 中,会导致单条 SQL 语句的 cop task 变多,影响语句的执行效率,乃至于触发 tikv 的报错。在目前 TiDB 的统计信息设计中,没有类似于 Oracle 的聚簇因子的概念,但是实际上仍受数据 “聚簇” 效果的影响。之前常见于 Oracle 的数据维护操作,对 TiDB 也有相同效果。压测和生产中的高频语句,需要注意相关数据写入分布的行为和影响。# shard_row_id_bitsTiDB v6.5 之前,默认情况下,非整数主键、没有主键的表或者建表时显式指定 nonclustered 非聚簇的表,TiDB 会使用一个隐式的自增 rowid。大量执行 INSERT 插入语句时,由于 rowid 自增分配,会把数据集中写入单个 Region,造成写入热点。通过设置 SHARD_ROW_ID_BITS,可以把 rowid 打散写入多个不同的 Region,缓解写入热点问题。它的使用效果如下图:
从右侧 Operator Info 栏中的可见,416 行的索引回表过滤仅需要使用 4 的 cop task,可以简单地认为 416 行表数据仅处于 4 个 不同 region 中,相关的数据“聚集”后,回表的开销降低了,网络的请求变快了,高并发情况下尤为明显。## 案例2单表 500 万的数据删除主键后进行“翻数”,重复插入 200 次,得到一个 10 亿记录的表。查询 SQL:select * from t where col1='1' ,col1 列上有二级索引。进行压测时,报:Coprocessor task terminated due to exceeding the deadline。可以认为,由于 10 亿记录的表通过以上的翻数操作得到,数据处于非常 “均匀” 的分散,单条语句的二级索引回表的 cop task 固定为 200,在高并发情况下,极容易触发以上的报错信息。通过相同的“数据整理”步骤,单语句 SQL 效率提升较大。## Region 与 cop taskRegion 是 TiDB 中计算、存储、调度的单元。计算单元的含义,大致可以理解为,cop 请求也会以 region 为单位进行分发。上述案例中,由于数据较为分散,即相同索引值的数据分布在较多的 region 中,会导致单条 SQL 语句的 cop task 变多,影响语句的执行效率,乃至于触发 tikv 的报错。在目前 TiDB 的统计信息设计中,没有类似于 Oracle 的聚簇因子的概念,但是实际上仍受数据 “聚簇” 效果的影响。之前常见于 Oracle 的数据维护操作,对 TiDB 也有相同效果。压测和生产中的高频语句,需要注意相关数据写入分布的行为和影响。# shard_row_id_bitsTiDB v6.5 之前,默认情况下,非整数主键、没有主键的表或者建表时显式指定 nonclustered 非聚簇的表,TiDB 会使用一个隐式的自增 rowid。大量执行 INSERT 插入语句时,由于 rowid 自增分配,会把数据集中写入单个 Region,造成写入热点。通过设置 SHARD_ROW_ID_BITS,可以把 rowid 打散写入多个不同的 Region,缓解写入热点问题。它的使用效果如下图:![image.png]() 隐式的自增 rowid 会因为左侧 shard bits 的翻转,会连续生成 “跳跃” 的 rowid,如 0000...0000,0001...0001,0010...0010,0011...0011,0000...0100,0001...0101,0010...0110 等,得到连续插入数据时,rowid 不连续的效果,规避了写入单个 Region 热点的问题。从上图中,可见 SHARD_ROW_ID_BITS 代表的是 “翻转位数”,2 的幂代表实际 kv map 中的 rowid 写入点数量,即
隐式的自增 rowid 会因为左侧 shard bits 的翻转,会连续生成 “跳跃” 的 rowid,如 0000...0000,0001...0001,0010...0010,0011...0011,0000...0100,0001...0101,0010...0110 等,得到连续插入数据时,rowid 不连续的效果,规避了写入单个 Region 热点的问题。从上图中,可见 SHARD_ROW_ID_BITS 代表的是 “翻转位数”,2 的幂代表实际 kv map 中的 rowid 写入点数量,即 SHARD_ROW_ID_BITS = 4 表示 16 个分片/ Region。但是,SHARD_ROW_ID_BITS 配置同时会带来写入数据不聚集的问题,从下图中可以看出,同一时间写入的数据,由于 SHARD_ROW_ID_BITS = 2,分布在四个不同的 Region 上。如果语句条件是根据时间进行范围扫,TableRowidScan 算子的 cop task 会增加 3 倍。![image.png]() 在生产实践中,关于 SHARD_ROW_ID_BITS 个人的建议是:通常配置为 2写入压力大的情况可以配置为 3不要超过 4另外,如果 tikv 实例的数量较小,不需要配置太大的 SHARD_ROW_ID_BITS。# 结论实际上,TiDB 的“聚簇因子”存在并影响索引读取的效率。在压测和生产实践过程中,需要关注回表数据和 cop task 的大概比例关系。## 题外话 merge_option=deny表属性是 TiDB 从 5.3.0 版本开始引入的新特性。如果建表时指定 shard_row_id_bits 时,希望建表时就均匀切分 Region,可以考虑配合 PRE_SPLIT_REGIONS 一起使用,用来在建表成功后就开始预均匀切分 2^(PRE_SPLIT_REGIONS) 个 Region。但由于新建表或分区的分裂操作实际产生的是空 Region,如果分裂打散操作距离写入存在一定时间间隔,则 Region 可能会被合并,从而导致无法真正规避写入热点问题。此时可以为表或分区添加
在生产实践中,关于 SHARD_ROW_ID_BITS 个人的建议是:通常配置为 2写入压力大的情况可以配置为 3不要超过 4另外,如果 tikv 实例的数量较小,不需要配置太大的 SHARD_ROW_ID_BITS。# 结论实际上,TiDB 的“聚簇因子”存在并影响索引读取的效率。在压测和生产实践过程中,需要关注回表数据和 cop task 的大概比例关系。## 题外话 merge_option=deny表属性是 TiDB 从 5.3.0 版本开始引入的新特性。如果建表时指定 shard_row_id_bits 时,希望建表时就均匀切分 Region,可以考虑配合 PRE_SPLIT_REGIONS 一起使用,用来在建表成功后就开始预均匀切分 2^(PRE_SPLIT_REGIONS) 个 Region。但由于新建表或分区的分裂操作实际产生的是空 Region,如果分裂打散操作距离写入存在一定时间间隔,则 Region 可能会被合并,从而导致无法真正规避写入热点问题。此时可以为表或分区添加 merge_option 属性,设置为 deny 来解决问题。- 禁止属于某个表的 Region 被合并
ALTER TABLE t ATTRIBUTES 'merge_option=deny';
```#
 从右侧 Operator Info 栏中的可见,416 行的索引回表过滤需要使用 26 的 cop task,可以简单地认为 416 行表数据处于 26 个 region 中。经过数据 “按序” 的导出和导入:a. dumpling --sql “select * from a order by cus_id” -F 100MiB --output-filename-template …b. tidb-lightning下图是 SQL 的新执行计划,执行计划完全一样,效率有较大的提升。
从右侧 Operator Info 栏中的可见,416 行的索引回表过滤需要使用 26 的 cop task,可以简单地认为 416 行表数据处于 26 个 region 中。经过数据 “按序” 的导出和导入:a. dumpling --sql “select * from a order by cus_id” -F 100MiB --output-filename-template …b. tidb-lightning下图是 SQL 的新执行计划,执行计划完全一样,效率有较大的提升。 从右侧 Operator Info 栏中的可见,416 行的索引回表过滤仅需要使用 4 的 cop task,可以简单地认为 416 行表数据仅处于 4 个 不同 region 中,相关的数据“聚集”后,回表的开销降低了,网络的请求变快了,高并发情况下尤为明显。## 案例2单表 500 万的数据删除主键后进行“翻数”,重复插入 200 次,得到一个 10 亿记录的表。查询 SQL:select * from t where col1='1' ,col1 列上有二级索引。进行压测时,报:Coprocessor task terminated due to exceeding the deadline。可以认为,由于 10 亿记录的表通过以上的翻数操作得到,数据处于非常 “均匀” 的分散,单条语句的二级索引回表的 cop task 固定为 200,在高并发情况下,极容易触发以上的报错信息。通过相同的“数据整理”步骤,单语句 SQL 效率提升较大。## Region 与 cop taskRegion 是 TiDB 中计算、存储、调度的单元。计算单元的含义,大致可以理解为,cop 请求也会以 region 为单位进行分发。上述案例中,由于数据较为分散,即相同索引值的数据分布在较多的 region 中,会导致单条 SQL 语句的 cop task 变多,影响语句的执行效率,乃至于触发 tikv 的报错。在目前 TiDB 的统计信息设计中,没有类似于 Oracle 的聚簇因子的概念,但是实际上仍受数据 “聚簇” 效果的影响。之前常见于 Oracle 的数据维护操作,对 TiDB 也有相同效果。压测和生产中的高频语句,需要注意相关数据写入分布的行为和影响。# shard_row_id_bitsTiDB v6.5 之前,默认情况下,非整数主键、没有主键的表或者建表时显式指定 nonclustered 非聚簇的表,TiDB 会使用一个隐式的自增 rowid。大量执行 INSERT 插入语句时,由于 rowid 自增分配,会把数据集中写入单个 Region,造成写入热点。通过设置 SHARD_ROW_ID_BITS,可以把 rowid 打散写入多个不同的 Region,缓解写入热点问题。它的使用效果如下图:
从右侧 Operator Info 栏中的可见,416 行的索引回表过滤仅需要使用 4 的 cop task,可以简单地认为 416 行表数据仅处于 4 个 不同 region 中,相关的数据“聚集”后,回表的开销降低了,网络的请求变快了,高并发情况下尤为明显。## 案例2单表 500 万的数据删除主键后进行“翻数”,重复插入 200 次,得到一个 10 亿记录的表。查询 SQL:select * from t where col1='1' ,col1 列上有二级索引。进行压测时,报:Coprocessor task terminated due to exceeding the deadline。可以认为,由于 10 亿记录的表通过以上的翻数操作得到,数据处于非常 “均匀” 的分散,单条语句的二级索引回表的 cop task 固定为 200,在高并发情况下,极容易触发以上的报错信息。通过相同的“数据整理”步骤,单语句 SQL 效率提升较大。## Region 与 cop taskRegion 是 TiDB 中计算、存储、调度的单元。计算单元的含义,大致可以理解为,cop 请求也会以 region 为单位进行分发。上述案例中,由于数据较为分散,即相同索引值的数据分布在较多的 region 中,会导致单条 SQL 语句的 cop task 变多,影响语句的执行效率,乃至于触发 tikv 的报错。在目前 TiDB 的统计信息设计中,没有类似于 Oracle 的聚簇因子的概念,但是实际上仍受数据 “聚簇” 效果的影响。之前常见于 Oracle 的数据维护操作,对 TiDB 也有相同效果。压测和生产中的高频语句,需要注意相关数据写入分布的行为和影响。# shard_row_id_bitsTiDB v6.5 之前,默认情况下,非整数主键、没有主键的表或者建表时显式指定 nonclustered 非聚簇的表,TiDB 会使用一个隐式的自增 rowid。大量执行 INSERT 插入语句时,由于 rowid 自增分配,会把数据集中写入单个 Region,造成写入热点。通过设置 SHARD_ROW_ID_BITS,可以把 rowid 打散写入多个不同的 Region,缓解写入热点问题。它的使用效果如下图: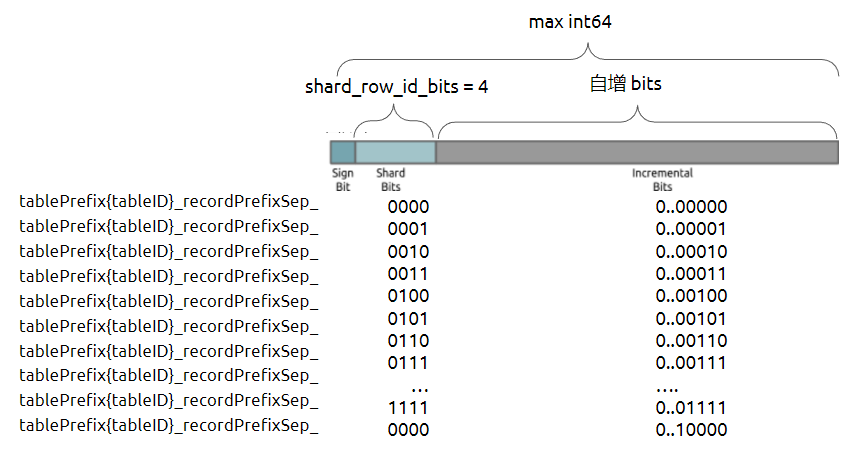 隐式的自增 rowid 会因为左侧 shard bits 的翻转,会连续生成 “跳跃” 的 rowid,如 0000...0000,0001...0001,0010...0010,0011...0011,0000...0100,0001...0101,0010...0110 等,得到连续插入数据时,rowid 不连续的效果,规避了写入单个 Region 热点的问题。从上图中,可见 SHARD_ROW_ID_BITS 代表的是 “翻转位数”,2 的幂代表实际 kv map 中的 rowid 写入点数量,即
隐式的自增 rowid 会因为左侧 shard bits 的翻转,会连续生成 “跳跃” 的 rowid,如 0000...0000,0001...0001,0010...0010,0011...0011,0000...0100,0001...0101,0010...0110 等,得到连续插入数据时,rowid 不连续的效果,规避了写入单个 Region 热点的问题。从上图中,可见 SHARD_ROW_ID_BITS 代表的是 “翻转位数”,2 的幂代表实际 kv map 中的 rowid 写入点数量,即 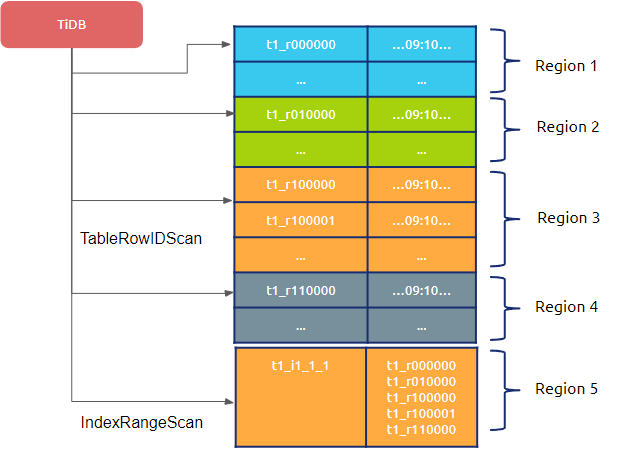 在生产实践中,关于 SHARD_ROW_ID_BITS 个人的建议是:通常配置为 2写入压力大的情况可以配置为 3不要超过 4另外,如果 tikv 实例的数量较小,不需要配置太大的 SHARD_ROW_ID_BITS。# 结论实际上,TiDB 的“聚簇因子”存在并影响索引读取的效率。在压测和生产实践过程中,需要关注回表数据和 cop task 的大概比例关系。## 题外话 merge_option=deny表属性是 TiDB 从 5.3.0 版本开始引入的新特性。如果建表时指定 shard_row_id_bits 时,希望建表时就均匀切分 Region,可以考虑配合 PRE_SPLIT_REGIONS 一起使用,用来在建表成功后就开始预均匀切分 2^(PRE_SPLIT_REGIONS) 个 Region。但由于新建表或分区的分裂操作实际产生的是空 Region,如果分裂打散操作距离写入存在一定时间间隔,则 Region 可能会被合并,从而导致无法真正规避写入热点问题。此时可以为表或分区添加
在生产实践中,关于 SHARD_ROW_ID_BITS 个人的建议是:通常配置为 2写入压力大的情况可以配置为 3不要超过 4另外,如果 tikv 实例的数量较小,不需要配置太大的 SHARD_ROW_ID_BITS。# 结论实际上,TiDB 的“聚簇因子”存在并影响索引读取的效率。在压测和生产实践过程中,需要关注回表数据和 cop task 的大概比例关系。## 题外话 merge_option=deny表属性是 TiDB 从 5.3.0 版本开始引入的新特性。如果建表时指定 shard_row_id_bits 时,希望建表时就均匀切分 Region,可以考虑配合 PRE_SPLIT_REGIONS 一起使用,用来在建表成功后就开始预均匀切分 2^(PRE_SPLIT_REGIONS) 个 Region。但由于新建表或分区的分裂操作实际产生的是空 Region,如果分裂打散操作距离写入存在一定时间间隔,则 Region 可能会被合并,从而导致无法真正规避写入热点问题。此时可以为表或分区添加 