近几年围绕业务中台化的场景,涌现出了许多低代码平台。面对多组件、多页面、跨平台的复杂场景,如何保证整体的用户体验一致性,减少用户认知和负担,提升用户使用效率,便成为业务迫切需要解决的问题。本文从组件化角度聊聊设计工程化是如何解决模块化与规模化的问题。
近几年围绕业务中台化的场景,涌现出了许多低代码平台。面对多组件、多页面、跨平台的复杂场景,如何保证整体的用户体验一致性,减少用户认知和负担,提升用户使用效率,便成为业务迫切需要解决的问题。从传统软件工程的思路出发,组件化是解决复杂模块的抽象、复用及统一的常用解决方案。那么对于中台设计来说,是否也能借鉴软件工程学的思路来解决设计遇到的模块化与规模化的问题呢?这便是近几年设计工程化所讨论并尝试解决的问题。
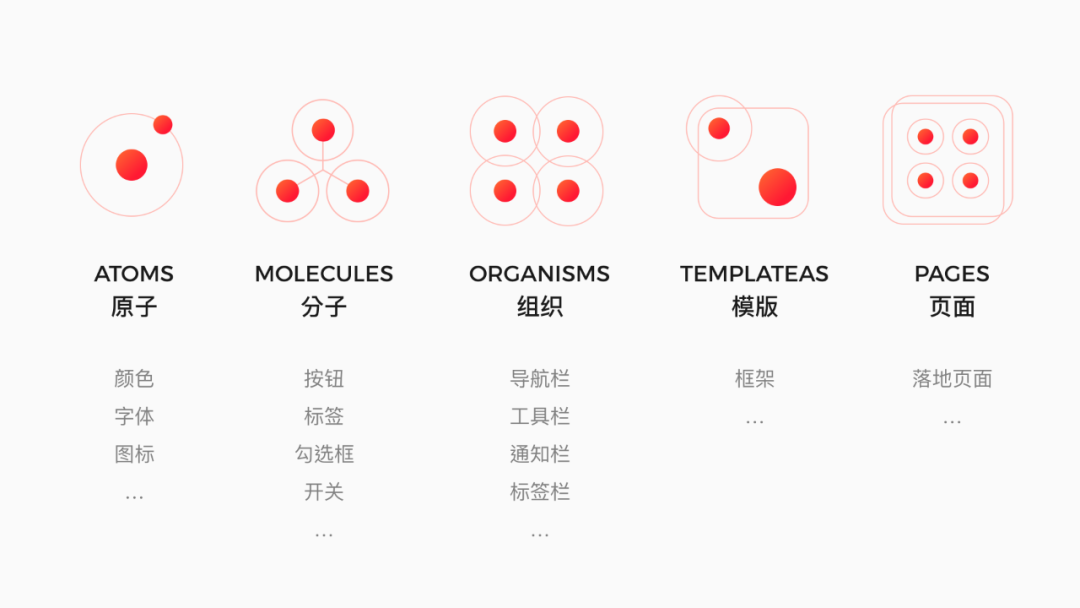
设计工程化源于 2013 年 Brad Forst 提出的原子设计理论(Atomic Design),理论使用一种有条理创建模式库的方法,结合软件开发的组件化思想,从最原始的原子出发,逐层构筑更高级别的组织,以解决设计模块化的问题,这就是设计系统的前身。
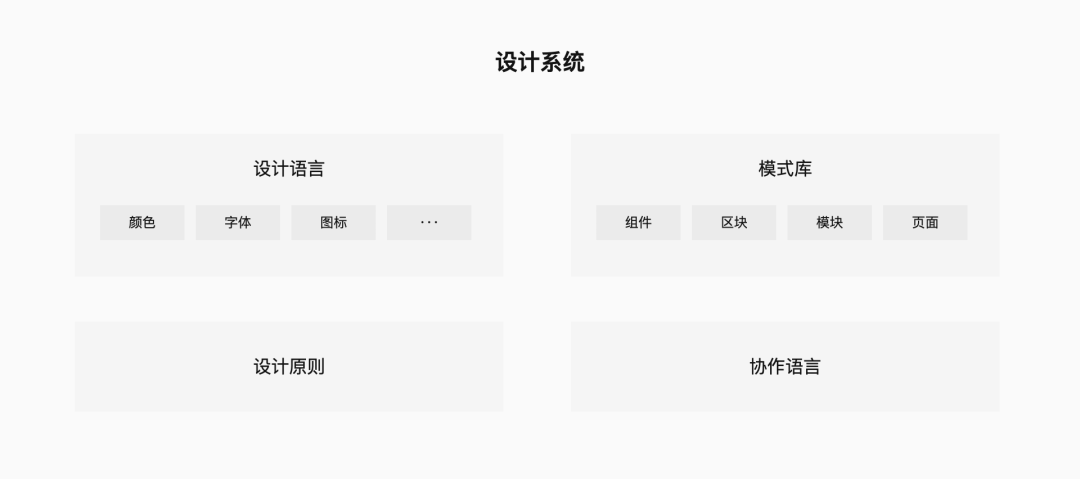
设计系统 — 设计系统的定义 设计系统是由设计语言和模式库构成,在设计原则的指导下,通过统一的协作语言和科学的管理方法组织起来,并创建体验一致的用户界面的系统。其目的是用于提高设计师和研发人员沟通效率,协作效率的实用工具,也能够更为客观地反映用户的需求。建立有效的设计系统,不仅能提高设计决策和协作的效率,也能减少系统出错的可能性。
设计系统的优势
沟通效率 :以往由于双方专业知识领域的差异而不好理解的概念,变得清晰了许多,例如在讨论组件的视觉呈现和交互逻辑时,往往需要不少的沟通和反复调整的成本,如今也因为规则的约定而顺畅了许多;
一致性 :产品在跨项目、跨平台的场景下,借助设计系统约定的规则,使用一致的设计语言来避免产品快速迭代中,可能遇到的视觉,交互,体验不一致问题;
文档化 :将设计语言、设计规则、模式库文档化,详细说明组件的外观,交互,适用场景等,可避免设计研发无根可循;
模块化 :组件化使用有限的规则来指导设计和研发,这样可实现设计研发关注点分离;并且利用原子化设计理论,逐层构筑模块、模板、页面等;
可维护性 :原子化的应用增强了模块的独立性,使得设计和研发的迭代更新变得高效,当一个模块需要更新时,使用这个模块的更高阶模块也能够同步更新;
协作效率 :设计系统的引入解决了设计和研发两种角色在产品迭代链路中,信息丢失和同步问题,大部分未遵循设计规则的组件模块,能够被及时发现并抛出;
设计系统存在的问题 自 Google 推出 Material Design 以来,各个大小公司的设计团队都花费了大量时间整理并发布自家产品的设计规范。用百家齐放来形容并不为过,并连续三年占据设计领域的热度榜。甚至有些规模不超过10人的小团队,也都投身到设计系统的整理中,似乎变成了每个设计团队的 KPI。
经过各个团队的验证,目前设计系统存在以下需要好好思考的问题:
整理耗时 :定义所有的设计规则和约束,以及基础和业务组件的整理,都需要经过大量的讨论,不仅仅涉及设计团队内部的沟通,也涉及各个业务线研发团队的外部沟通。
维护成本 :设计系统是需要不断维护并迭代的,并非一劳永逸;
缺乏创造力 :业务迭代受限于设计系统的规则和约束,创作的空间少了,但也带来了产品体验的一致性;
复杂度高 :模块化可降低系统的维护成本,但相反地会提高模块之间的耦合度,使得产品创新性难以提升;
如果从长远的角度看,一个好的设计系统不仅仅要能支持当前阶段的设计和研发工作,也要能支持一个团队的整体协同工作,更要能支持从规范本身出发,不断地进行演进和创新。
设计工程化 — 设计系统的流行推动了设计工程化的发展,下面对设计工程化的讨论主要分为两个部分:第一部分是以设计师视角出发的设计系统探索,第二部分是以工程师视角的设计系统落地实践。
设计系统探索 以产品生产链路来看,设计稿作为生产的上游输入源,资源的生产方式和管理方式,直接影响下游(如:研发生产)的交付效率。设计系统的引入,对于设计师来说,必然得主导系统的落地运行,以保证设计资产的质量与流通顺畅。
但设计系统的落地强依赖于生产工具的能力,传统的 Photoshop,AI 等设计工具,缺乏资源管理维度的能力。在现代设计工具(如 Sketch,Figma)出现以前,设计系统往往需要借助第三方平台提供的插件,并按插件规范命名图层,组织设计资源,才能生成设计系统文档。设计规则和约束依旧无法很好的融入设计工作流,于是在 UI 设计工具领域出现了 Figma, Sketch 等新宠,尝试将前端工程化的思想带入设计领域。
设计师在完成样式设计后,研发工程师需要按设备的尺寸,还原设计的排版布局意图。这造成了 UI/UX 和工程师之间的职能错配和重叠问题,工程师似乎承担了不少设计层面的实现任务。Figma 将组件化思想融入设计工具的同时,还引入了 Variants 等概念。让组件的响应式设计任务回归设计师,由设计师把控组件交互的各个形态。同时也因为颜色变量、文本样式、图层样式等运用复用思想的特地引入,设计系统的运行与维护,设计资产的流通,也顺利进入设计师的日常工作流中。
设计系统落地实践 作为「设计系统」执行方的设计师与前端工程师,日常工作分别是在两个差异化较大的工作流中进行的。常规流程是设计师在设计工具(Sketch、Figma)中完成页面设计后,前端再参照绘制好的原型稿和标注稿,在代码环境中还原视觉稿 UI/UX。
但在这个过程中时常会遇到以下问题:
视觉稿中可复用的设计系统原子,如果准确地传达给下游?
前端如何高效的获取上游设计的更新? 设想这么一个场景,在产研交付的过程中,设计师在视觉稿中做的每次修改,都希望能快速响应到最终的产品中,尽可能做到敏捷。而实际工作中,设计上游变更后会告知前端(存在少数变更不告知的情况),前端再打开包含标注信息的设计工具和代码编辑工具完成需求修改。在这个场景中,设计师会通过口头或文字罗列视觉变更点,存在一定的沟通成本和信息丢失问题。在最终产品交付上线前,还会经过一轮「设计走查」环节(敏捷开发中经常忽略的一环),可能又会产生新的设计上游变更,如此反复。
视觉稿中可复用的设计系统原子,如何传达给下游? 一个成熟的项目,往往会有自己的设计系统,设计原子作为系统中可复用程度较高的模块,已深度整合到设计工作流中。但由于设计和前端领域的概念不互通,导致可复用的信息不能有效传达。虽然设计师会整理包含字号层级,品牌色板,卡片阴影等信息的设计规范文件,但这些信息往往不能在视觉交付稿中很好的展现。要理解视觉稿中的设计原子,前端需要了解设计工具中的概念,如 Sketch 的图层样式、Symbols,Figma 的 Variants 等等。设计师是最了解页面样式复用逻辑的,但真正实现页面样式的却是前端工程师,这不可避免产生视觉还原误差。
视觉还原工作还能提效吗? 设计师在绘制好页面视觉稿后,前端需要将视觉稿还原成可交互的页面,按古早的分工,这里需要三种角色参与,分别是视觉设计师、页面重构工程师(负责 HTML + CSS 等 UI/UX 逻辑)和前端工程师(负责数据渲染等逻辑)。本质上,视觉还原就是将设计工具中的视觉稿描述转换为 Web 能理解的数据描述,即 HTML + CSS。而这一块的信息转换工作正是团队近一年来尝试攻克的点,团队立项的「Deco 智能代码项目」通过设计工具插件从视觉稿原始信息中提取结构化的数据描述(D2C Schema),然后结合规则系统、计算机视觉、智能布局、深度学习等技术对 D2C Schema 进行处理,转换为布局合理且语义化的 D2C Schema JSON 数据,最后再借助 DSL 解析器转换为多端代码。
智能代码解决了视觉还原工作整体的效能问题,但具体怎么让设计系统完美衔接研发工作流,降低设计研发协作成本,提升最终产出代码的可维护度,正是 DesignToken 可以发挥作用的地方。
Design Token —
Design tokens are the visual design atoms of the design system — specifically, they are named entities that store visual design attributes. We use them in place of hard-coded values (such as hex values for color or pixel values for spacing) in order to maintain a scalable and consistent visual system for UI development. -- Jina Anne
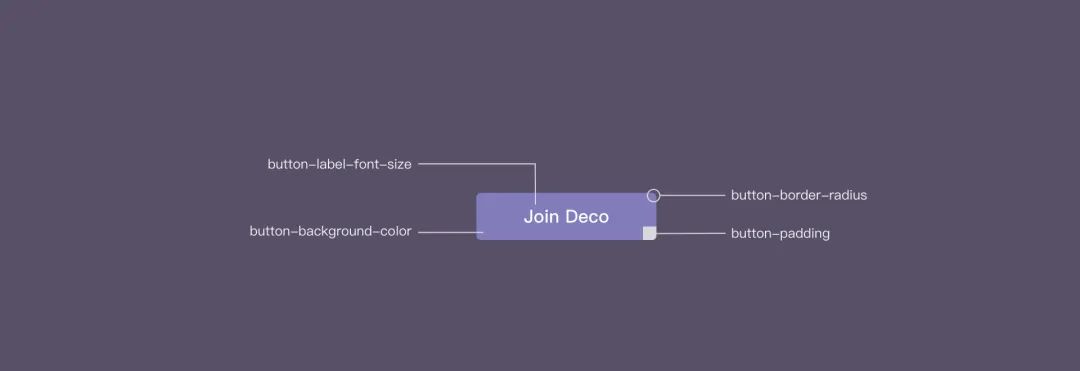
用上述 Design Token 之母的一段话,我们可以这么理解 Design Token。Design Token 是一种以平台无关的方式来表达设计决策的方法,以便在不同领域、工具和技术之间共享。在设计系统中的,Design Token 代表了构成视觉风格的,可复用的设计属性,例如颜色、间距、字体大小等等。Token 被赋予一个特定的名称(color.brand),该名称对应于某个设计决策定义的值(#3271FE)。
但有别于设计变量(Design Variables),Design Token 是一个具有平台无关性的抽象层,该抽象层的命名约定为设计属性创建了一种通用语言,可支持跨应用,跨平台,跨框架使用。
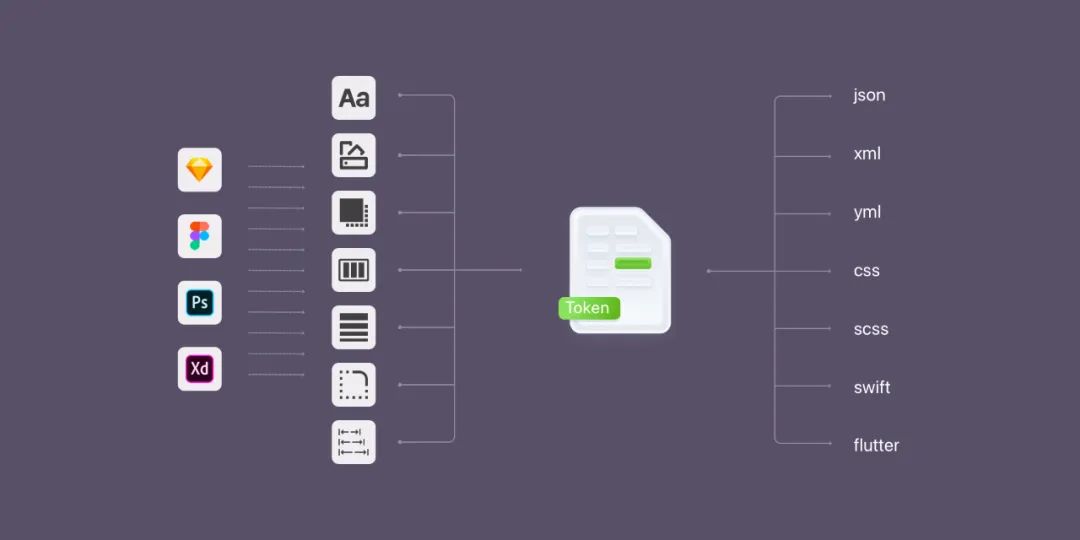
Design Token 的工作流程如下:
按照 W3C Design Token 兴趣组最新拟定的草案,Design Token 主要涉及三个部分:
令牌(Token)
设计工具如 Figma、Sketch、AdobeXD 等,负责生产并维护设计系统中的 Tokens。
翻译工具是将 Design Token 从一种格式转换为另外一种格式的工具,如 JSON to CSS。
Design Token 实践 在「Deco 智能代码」项目中,研发可以给项目关联特定的设计系统(DSM),如「京东 APP 设计系统」,其中包含文本样式,图层样式,调色板等设计原子。Deco 在做布局样式还原时,会优先使用设计系统中已有的 Design Tokens 并进行替换,并会标记设计系统中暂未录入的设计变量,例如不在设计规范中的色值,字体大小等。
Design Token 的引入除了可以给布局还原的代码做样式精简外,还能为视觉走查提供便利。因为 D2C(DesignToCode)的技术方案中,产出的代码视觉还原度可以达到将近 100%,设计师可以更多地关注自身视觉稿的设计系统覆盖度,借助上述流程中被标记的「设计变量」列表,可以十分方便的确认设计误差,例如设计规范中规定的背景色为
,
但
代
码
还
原
后
的
背
景
色
未
被
替
换
为
设计工程化理想方案构想 — 设计工程化解决的是规模化,效率化的问题。首先从角色分工上,按职责划分任务,涉及视觉呈现层面(元素边距,字体颜色大小等)的工作交由设计师负责,研发只负责业务逻辑的功能开发。而设计稿到产品的视觉还原功能,可结合 D2C(Design To Code)和 Design Tokens 来实现。D2C 负责页面视觉和响应式设计的自动化还原工作,Design Tokens 负责把设计决策产生的设计因子整合到开发工作流,从而完成设计系统在设计和研发产研链路中的落地串联。
通过上述方案,我们可以初步实现设计稿静态页面还原 + 响应式设计的工程化。即解决了 UI 到研发的链路打通问题。那对于设计系统中的交互逻辑的部分(即 UX),该如何实现工程化呢?
以往的组件交互逻辑,如按钮的点击交互,下拉菜单的展开动画,大多是由设计师口头或简单地画组件的分镜状态来跟研发进行协作的。缺乏交互规范,即使设计系统文档中有明确的交互设计规则,研发之间也会存在实现方案的差异,无法保持交互统一性和可维护性。
Figma 给出的解决方案是在视觉稿中直接绘制组件交互原型,再借助 A2C (Animation To Code)插件转换为动画描述文件(Animation JSON Schema),最终通过动画解释器(Animation Parser)完成 UX 链路的转换工作。
以上便是现阶段设计工程化落地的解决方案。
展望 — 设计工程化探讨的不仅是产品设计系统的搭建过程,也是设计和研发两种角色的分工转变,及协作效率提升的过程。设计系统是一个具有包容性且充满生命力的东西,包含从组件库到设计语言的结构化体系以及应对不断变化的创新迭代过程。Design Token 恰好是打通设计研发工作链路的一把钥匙,但不应该只有一把。
好的设计系统可以在产品的一致性和品牌的创造性表达之间取得平衡,好的组件化思路也应该能最大化运用设计系统的价值。在未来,随着技术的推陈出新,比如 AI 画图尝试通过机器学习的方式生产艺术画,设计工程化也会有更多可探索的方向。
参考文献 —
https://juejin.cn/post/7122711998839652389#heading-13
https://zhuanlan.zhihu.com/p/344336425
提效神器 Design Token 的探索与应用:
https://juejin.cn/post/7120150297808207909