本文整理自火山引擎基础架构研发工程师陶克路、王正在 ApacheCon Asia 2022 上的演讲。文章主要介绍了 Apache Zeppelin 支持 Flink 和 Spark 云原生实践。
作者 | 火山引擎云原生 计算研发工程师-陶克路、火山引擎云原生 计算研发工程师-王正
Apache Zeppelin 介绍
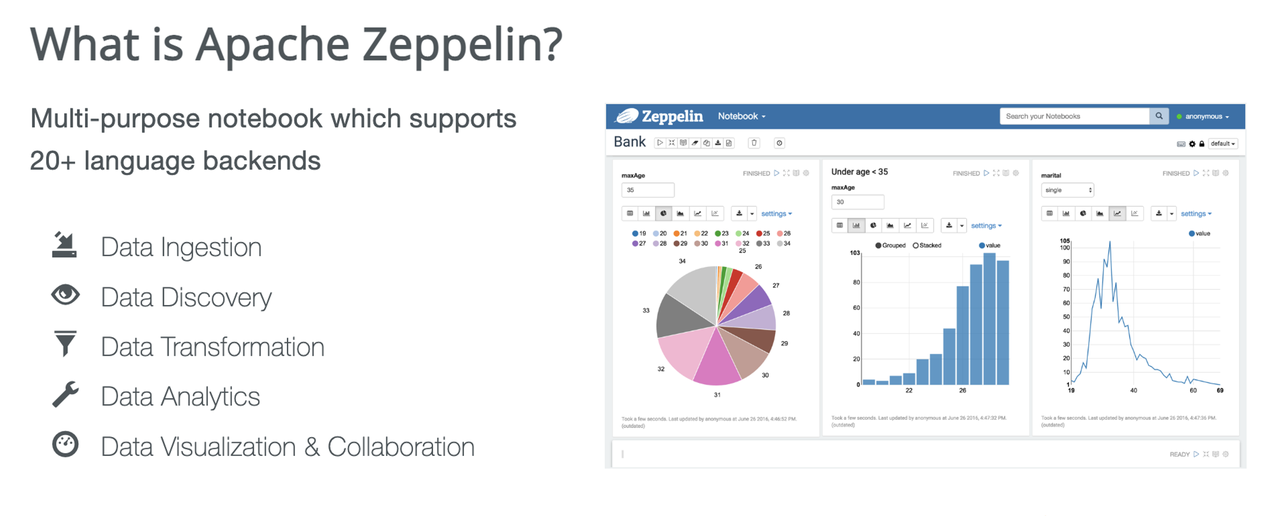
Apache Zeppelin 是一个支持 20 多种语言 Notebook 的后端,可以用于数据摄入、发现、转换及分析,也能够实现数据的可视化,如饼图、柱状图、折线图等。
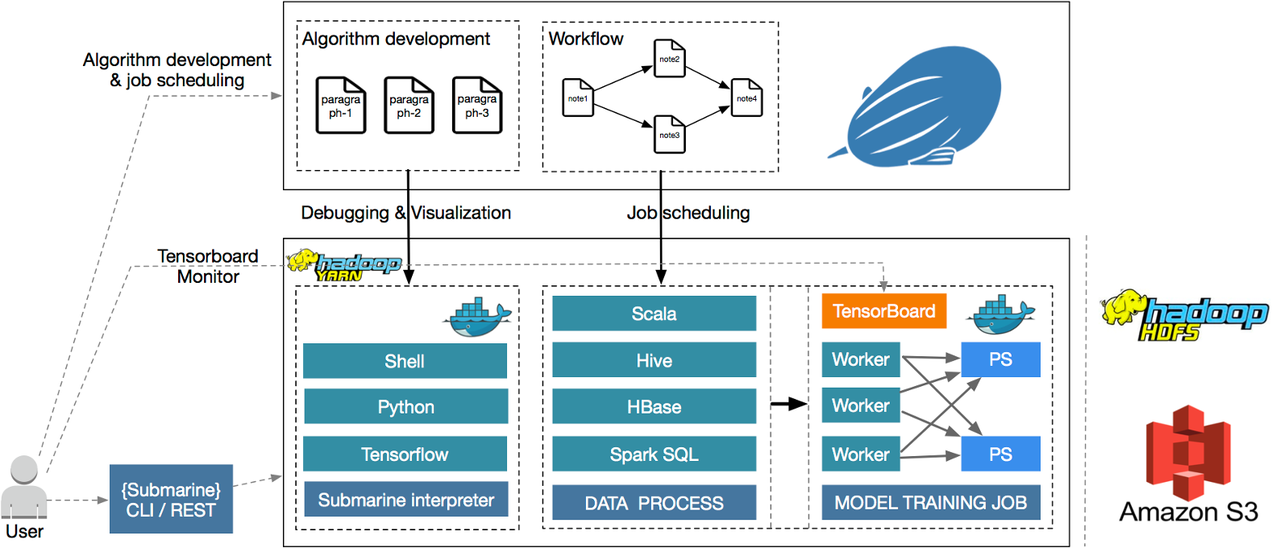
典型使用场景是通过开发 Zeppelin 的代码片段或者 SQL,通过提交到后端实现实时交互,并通过编写 Notebook 的 Paragraph 集合,借助调度系统实现定时调度任务。
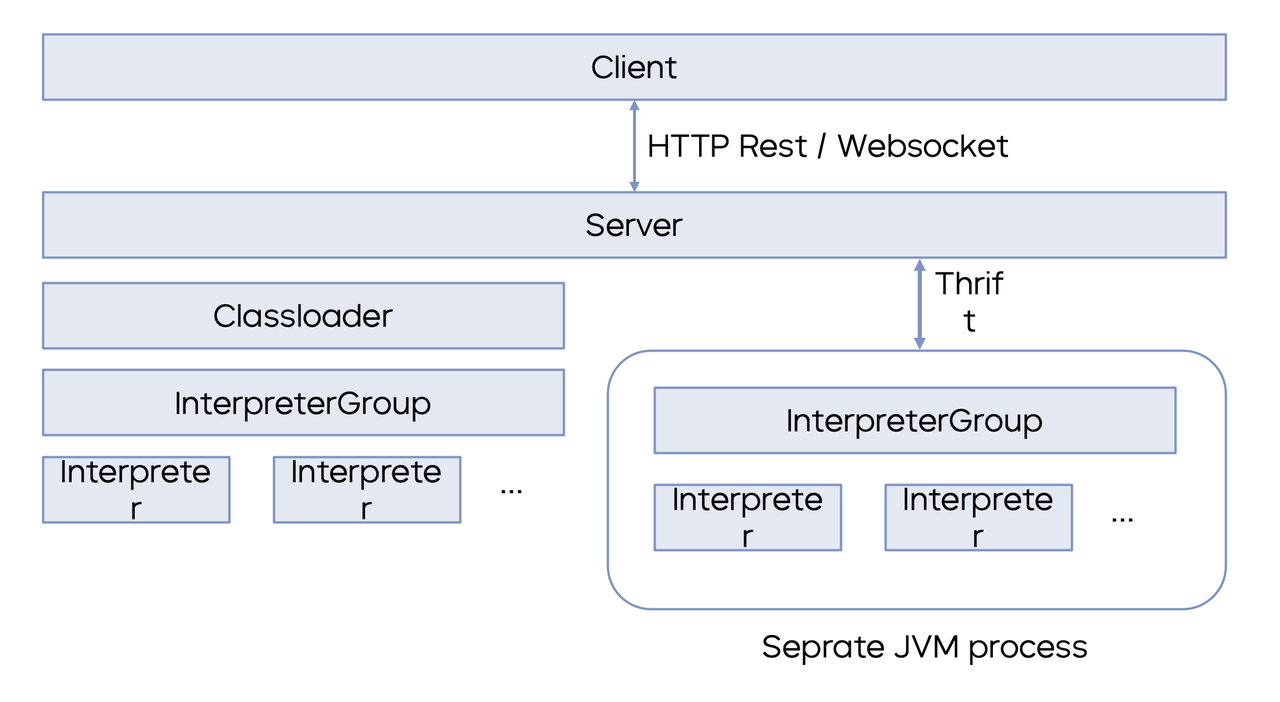
Zeppelin 的技术架构包含三个部分:Client、Server 和 Interpreter。Client 和 Server 通过 Restful 接口或 WebSocket 接口进行交互,Interpreter 解释器则是一个独立于 Zeppelin Server 的进程,在 K8s 环境上面拥有独立的 POD 和环境信息。
Apache Zeppelin 的云原生实践
Apache Zeppelin 的云原生实践包含五个部分:
Namespace 内部
跨 Namespace
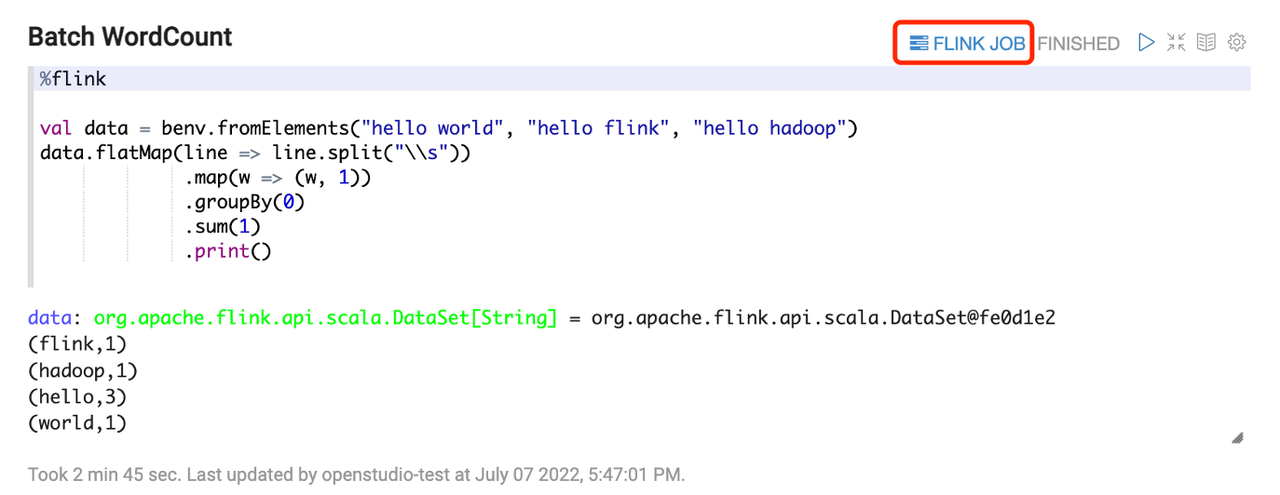
基于 Zeppelin 的 Flink 云原生实践
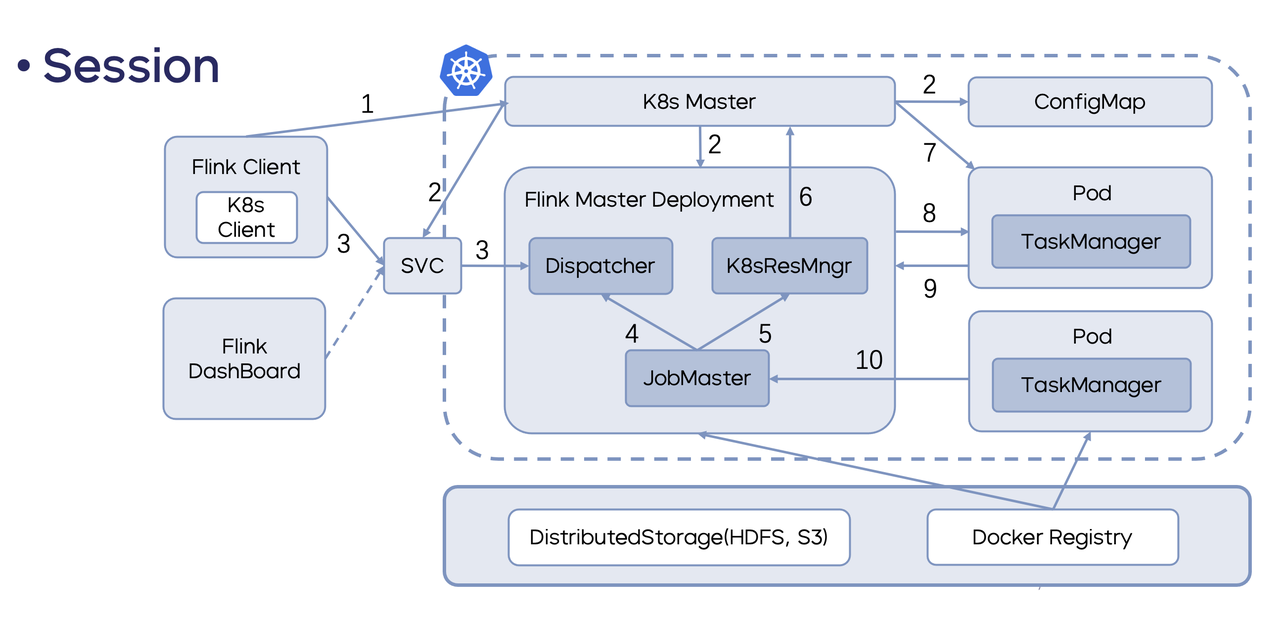
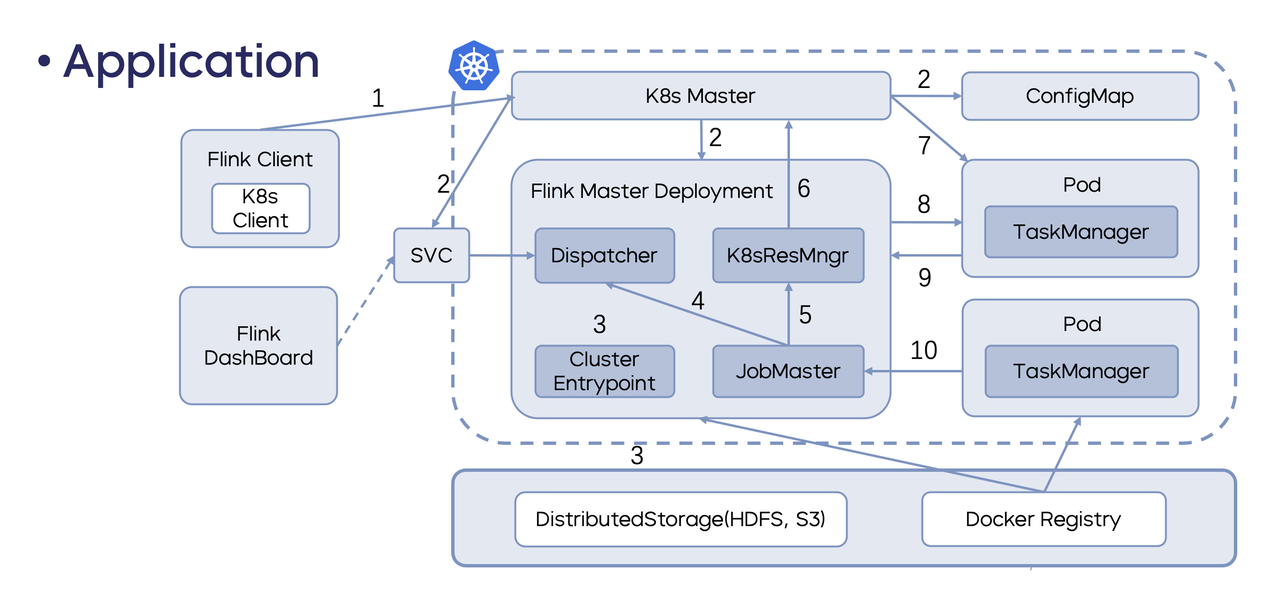
Flink on K8s 的工作原理
目前 Flink on K8s 主要有两种工作方式:
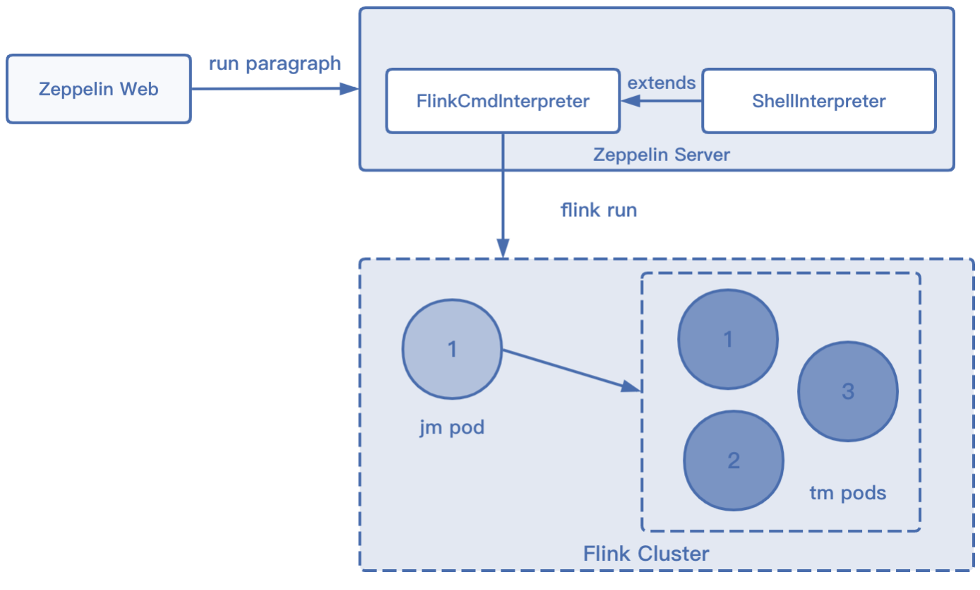
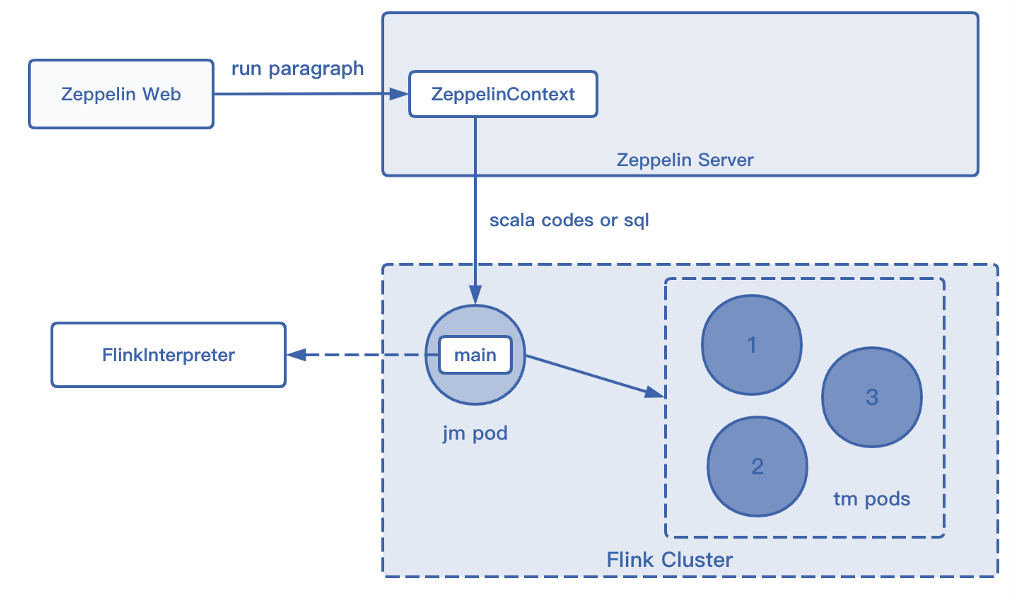
Flink on Zeppelin 的工作原理
Flink on Zeppelin 的工作基本都是用解释器实现的,Flink 的解释器大体上可分为两种,FlinkCmd 解释器和其他 Flink 解释器。
Flink on Zeppelin 的功能增强
火山引擎对 Flink on Zeppelin 进行了功能增强,主要有以下几个方面:
基于 Zeppelin 的 Spark 云原生实践
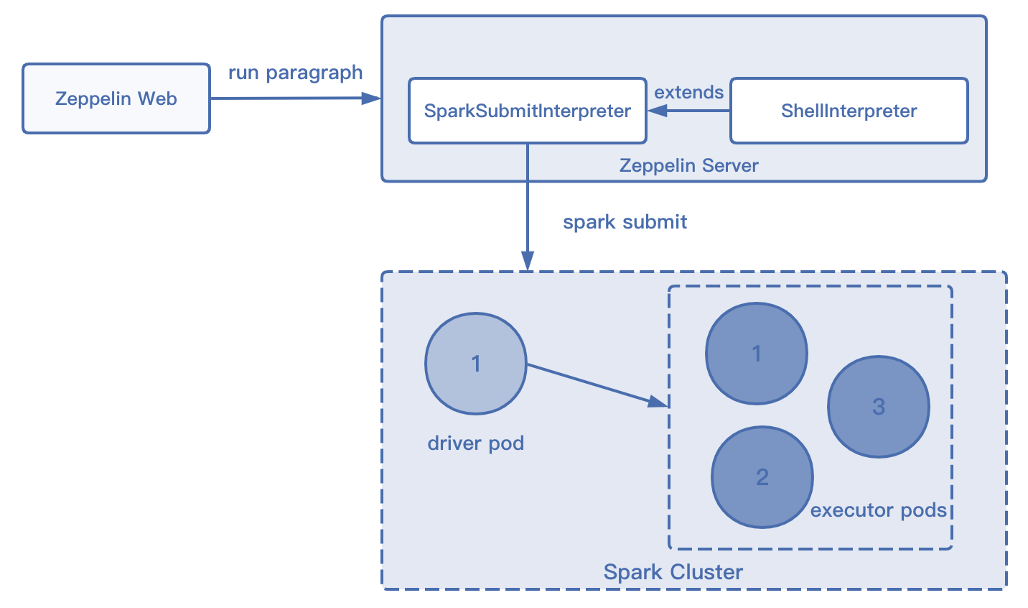
Spark on K8s 工作原理
Spark 在 K8s 上的工作原理和 Flink 的 Application 模式类似,用户提交指令给 K8s APIServer 后,创建对应的 Driver Pod 和 ConfigMap。 Driver Pod 运行相应的程序,根据代码需求向 K8s Master 发送请求申请Executor Pod资源。 Executor Pod创建完毕后开始执行任务,执行完毕后最终销毁。
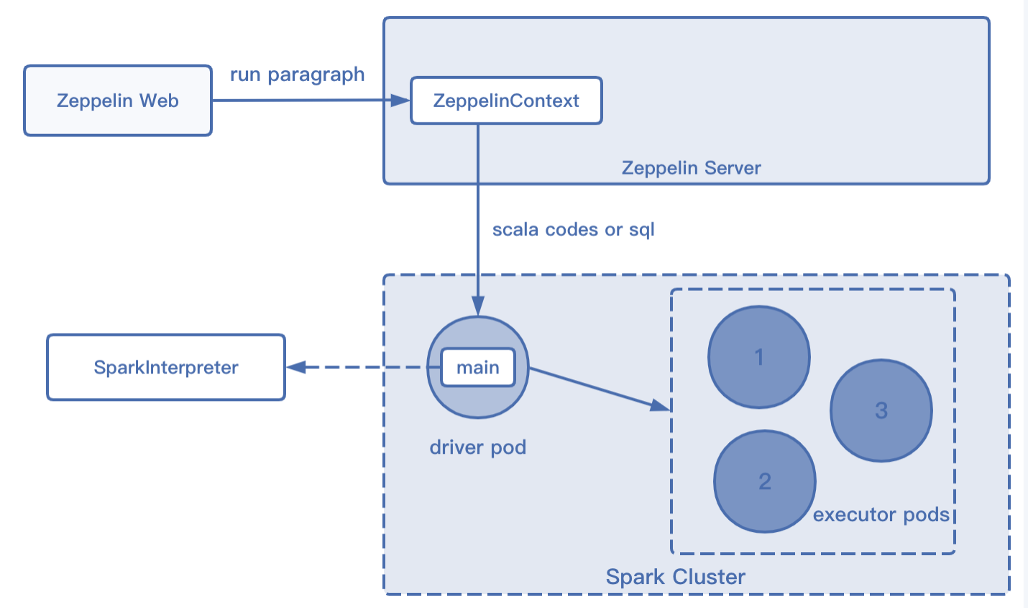
同样 Spark on Zeppelin 的工作也都是基于解释器实现的。
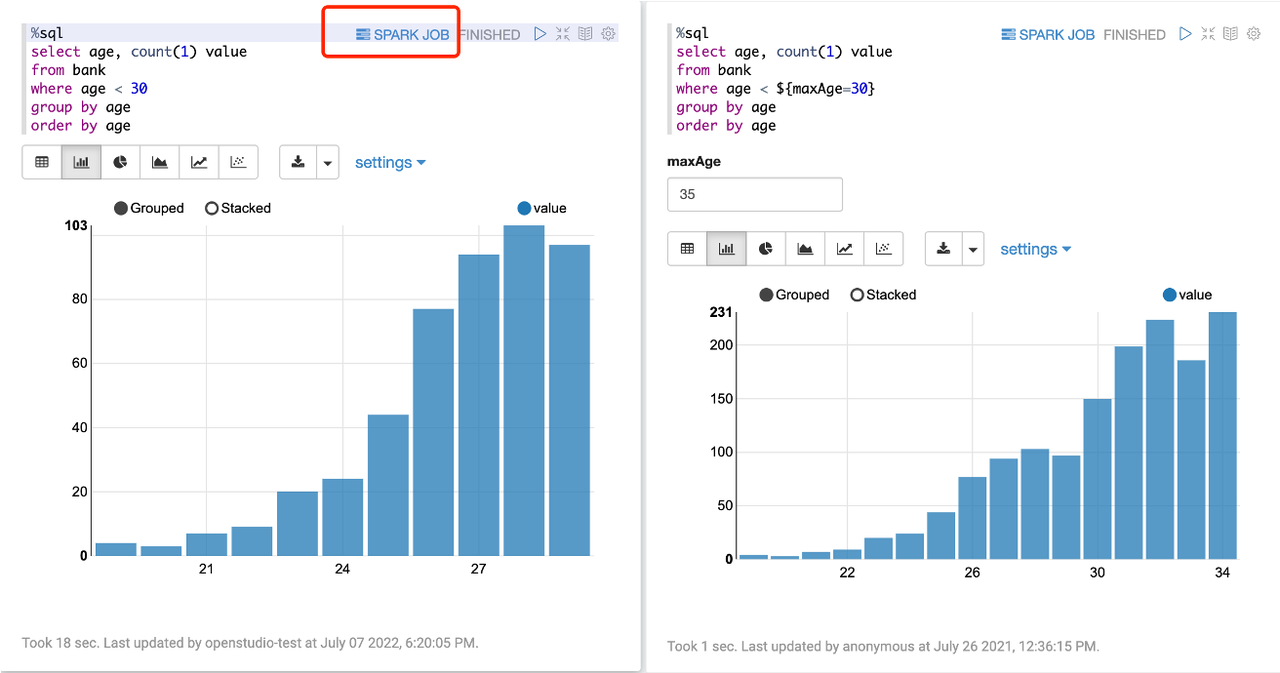
Spark on Zeppelin 的功能增强
火山引擎同样对 Spark on Zeppelin 进行了功能增强,主要有以下几个方面: