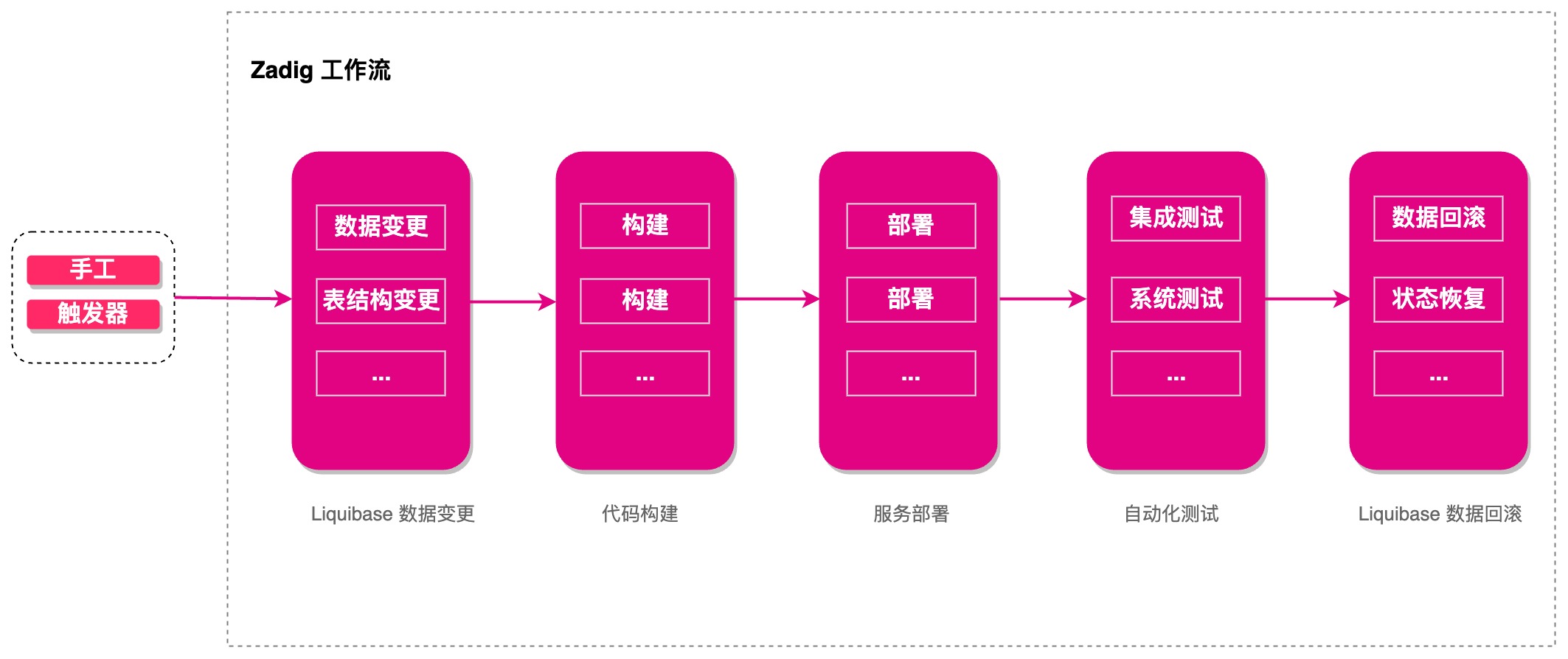
 下面主要介绍研发流程中涉及的工作流
下面主要介绍研发流程中涉及的工作流 
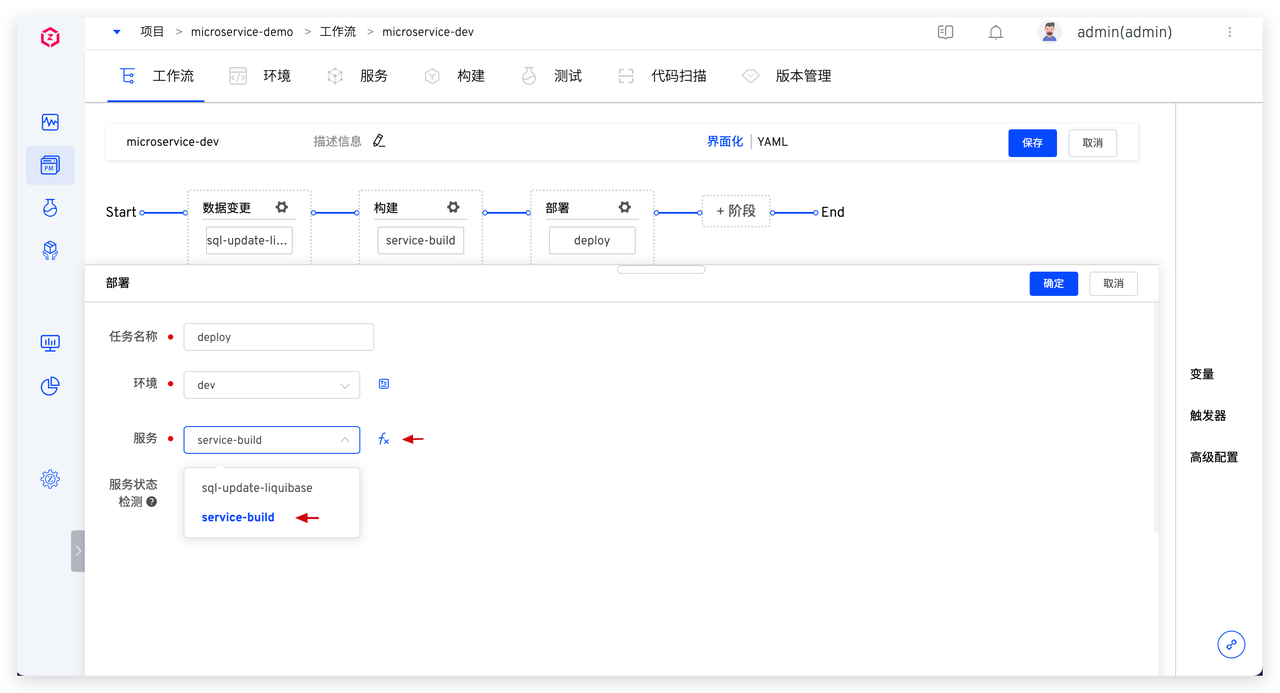
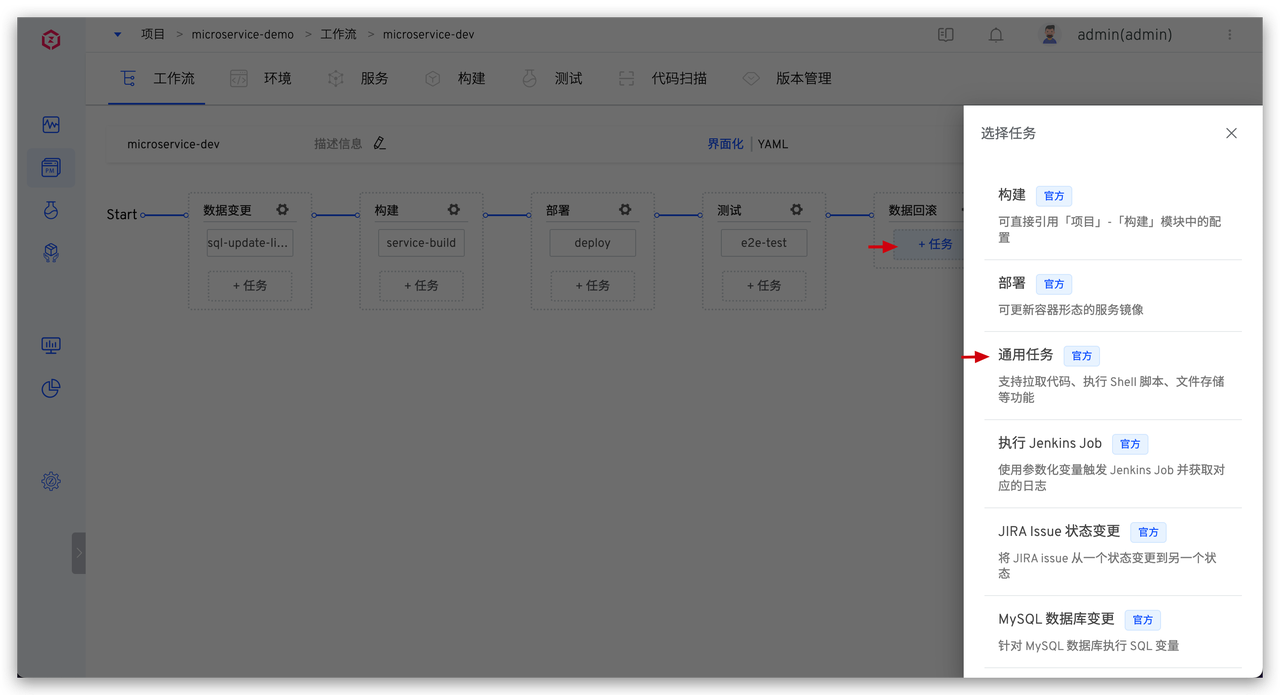
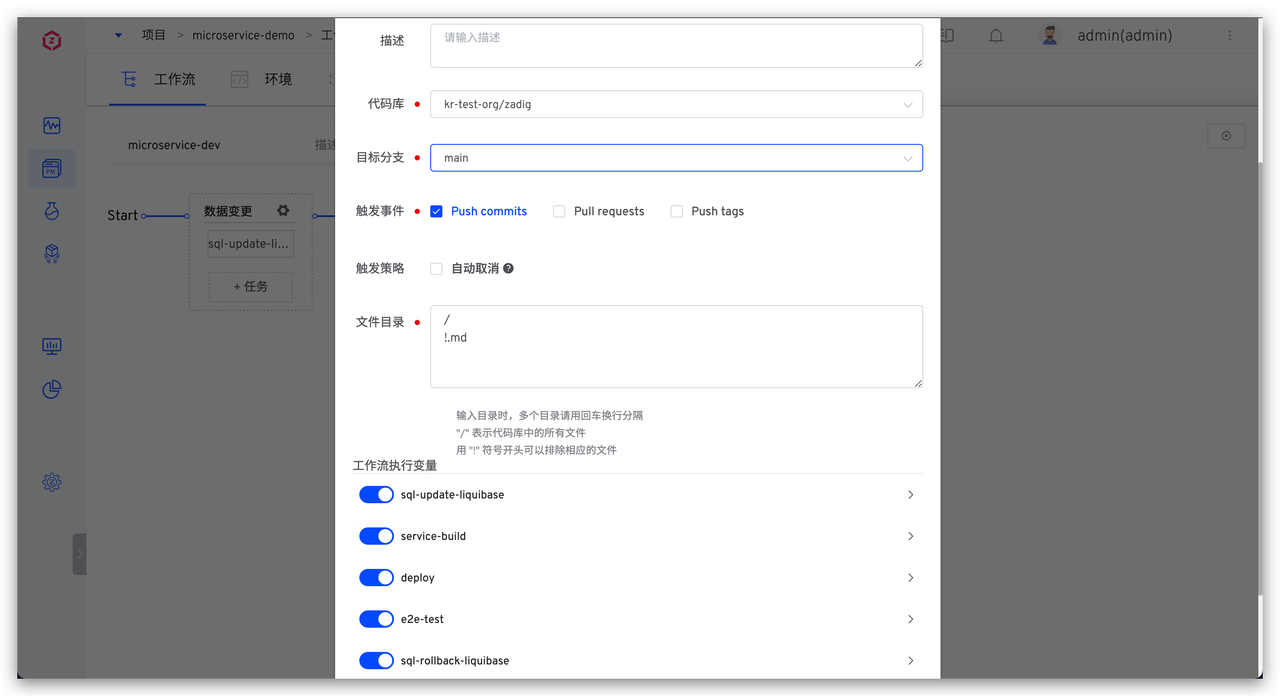
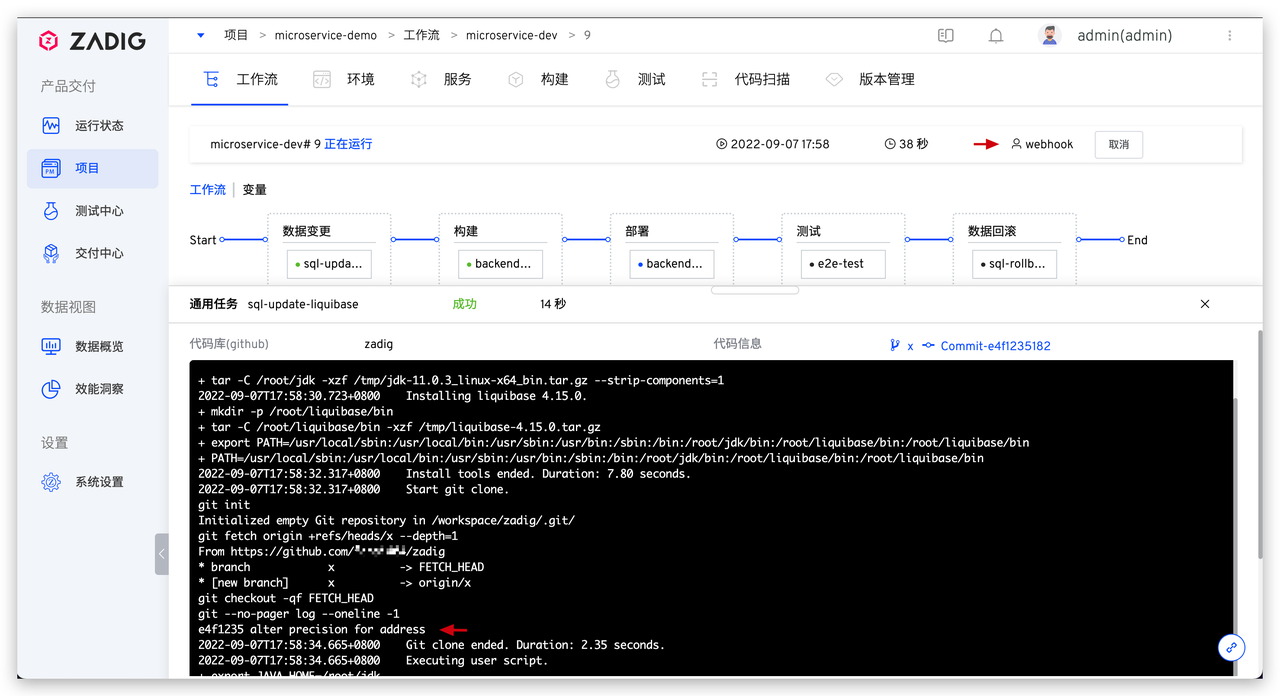
 配置数据变更任务
配置数据变更任务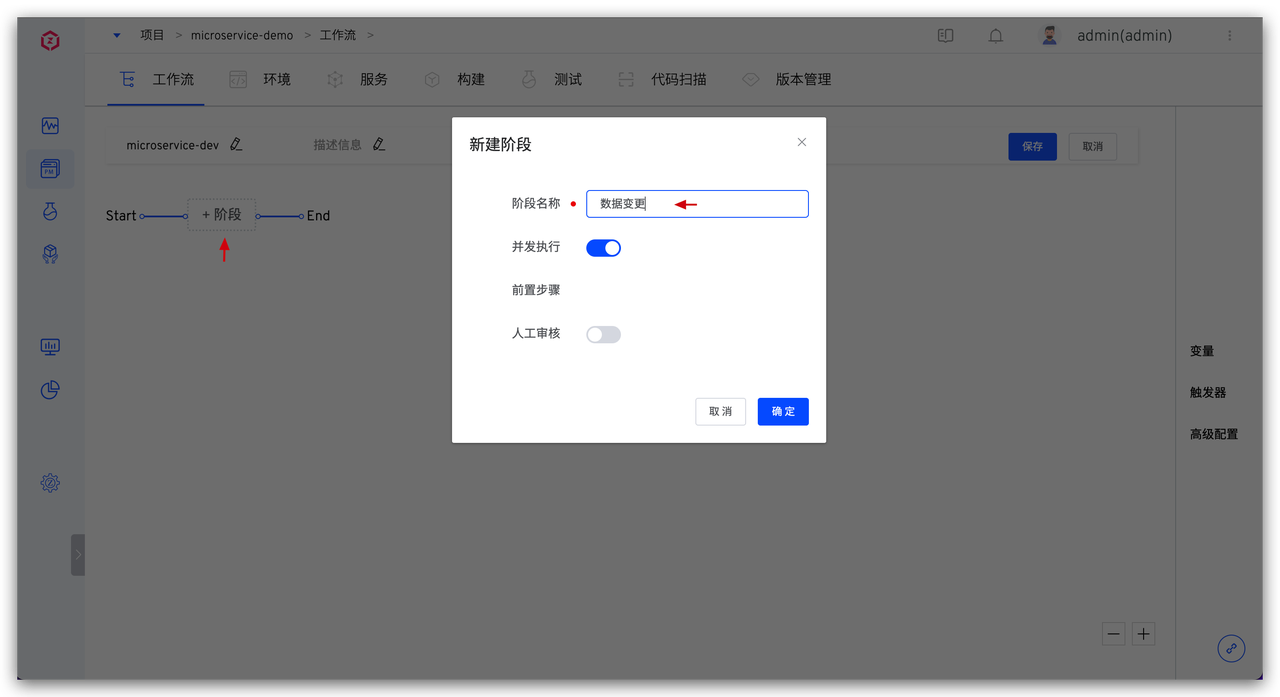
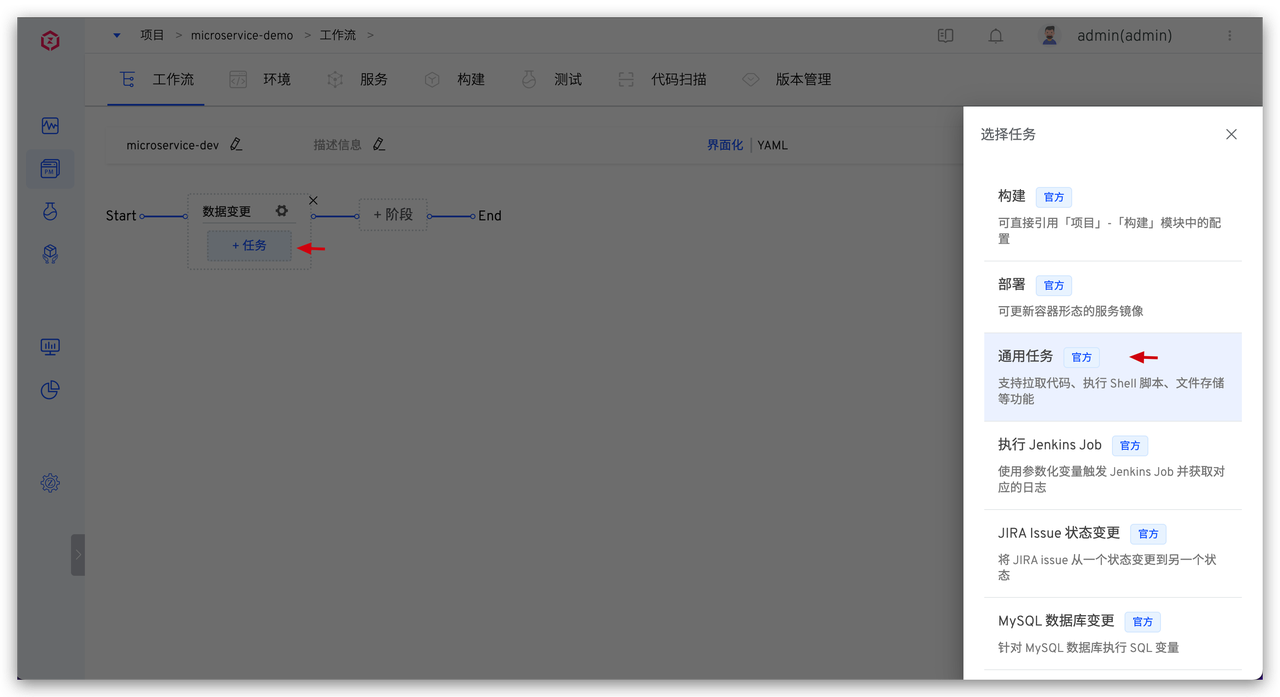
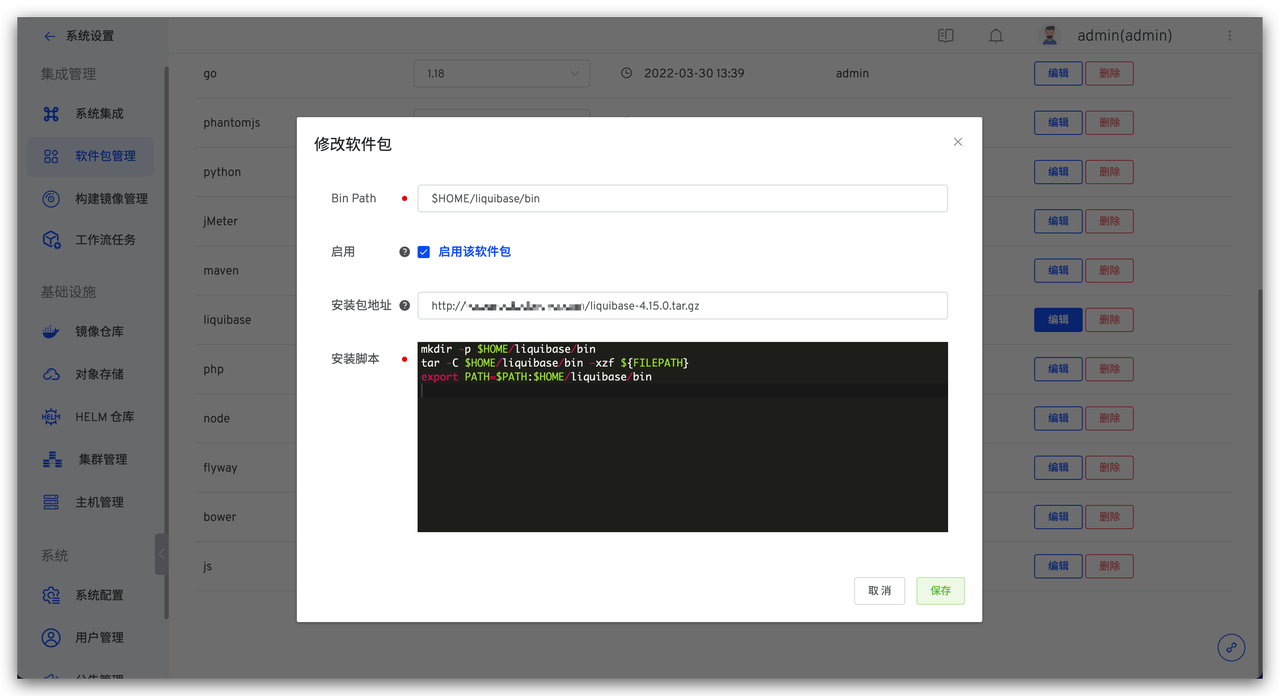
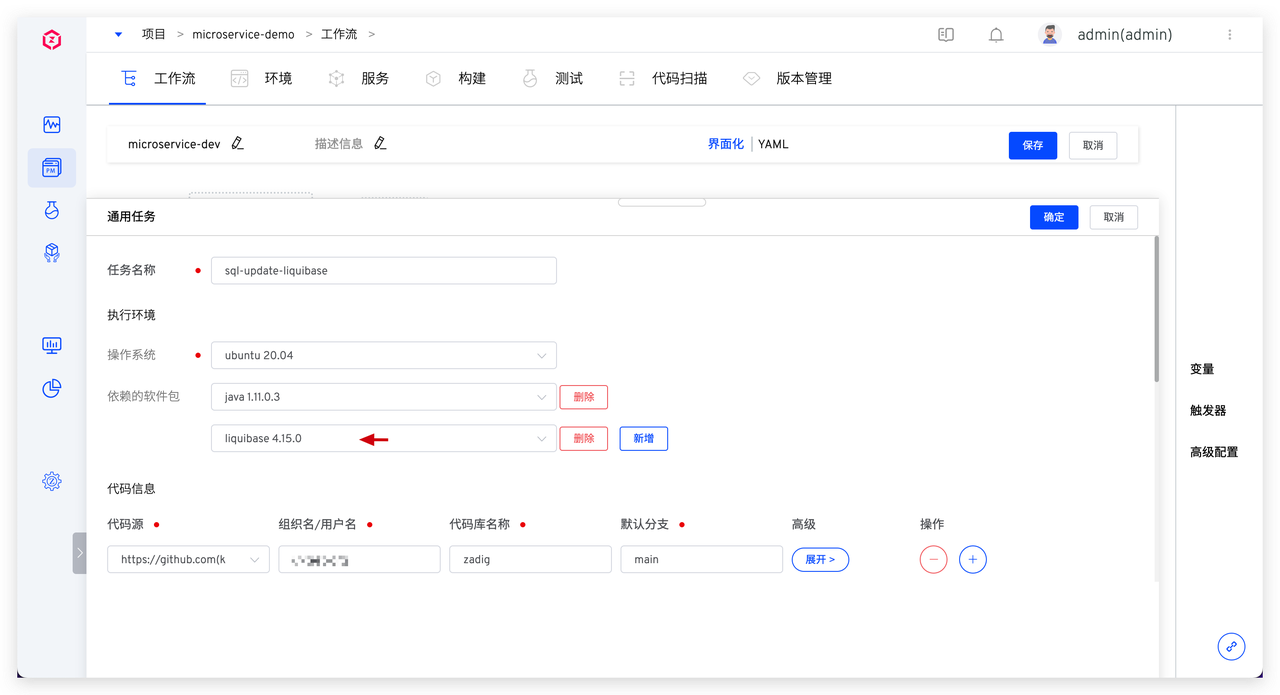
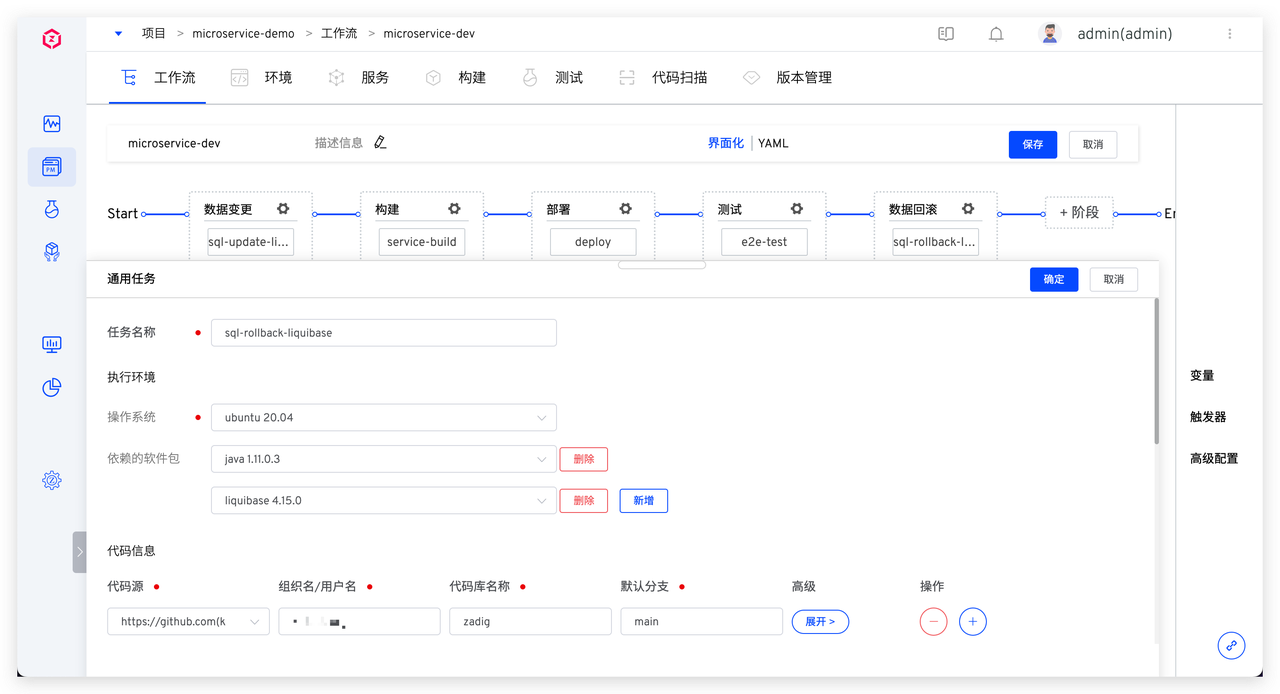
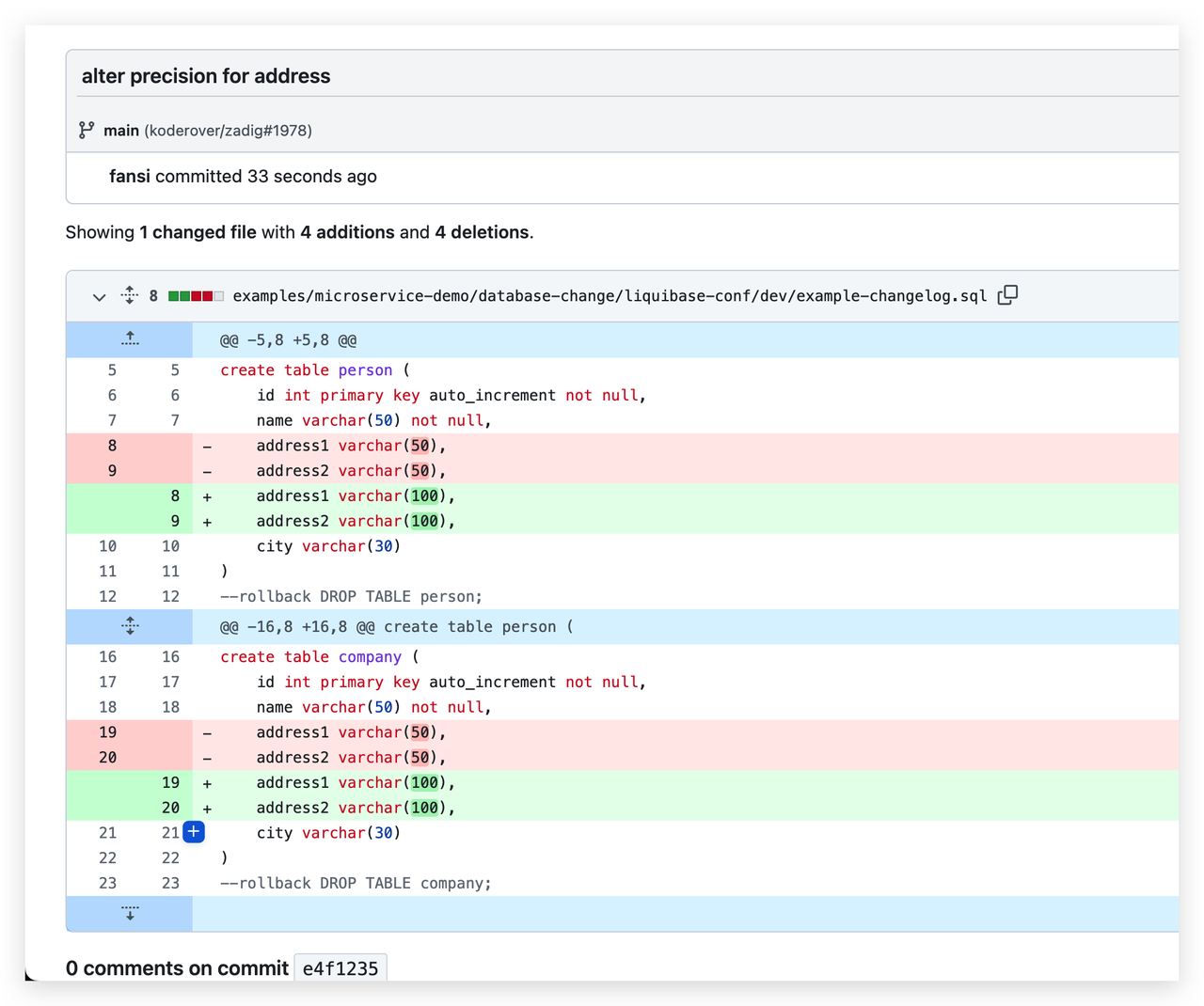
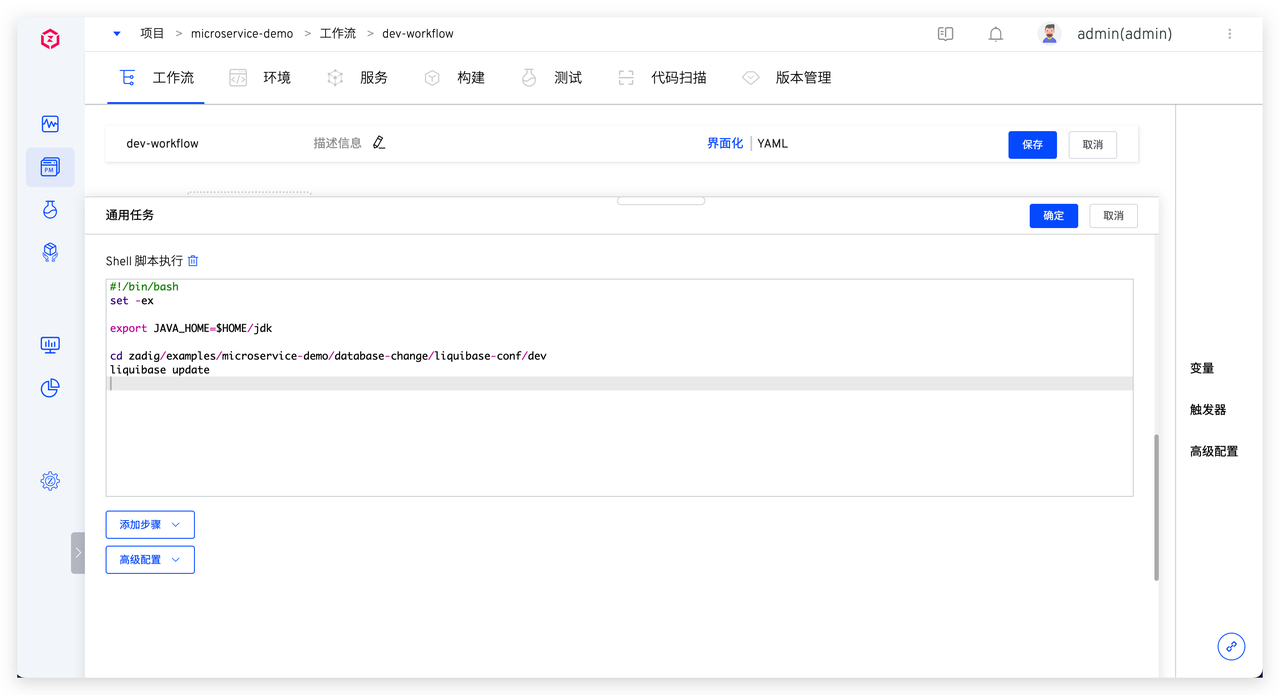 具体脚本参考如下:
具体脚本参考如下: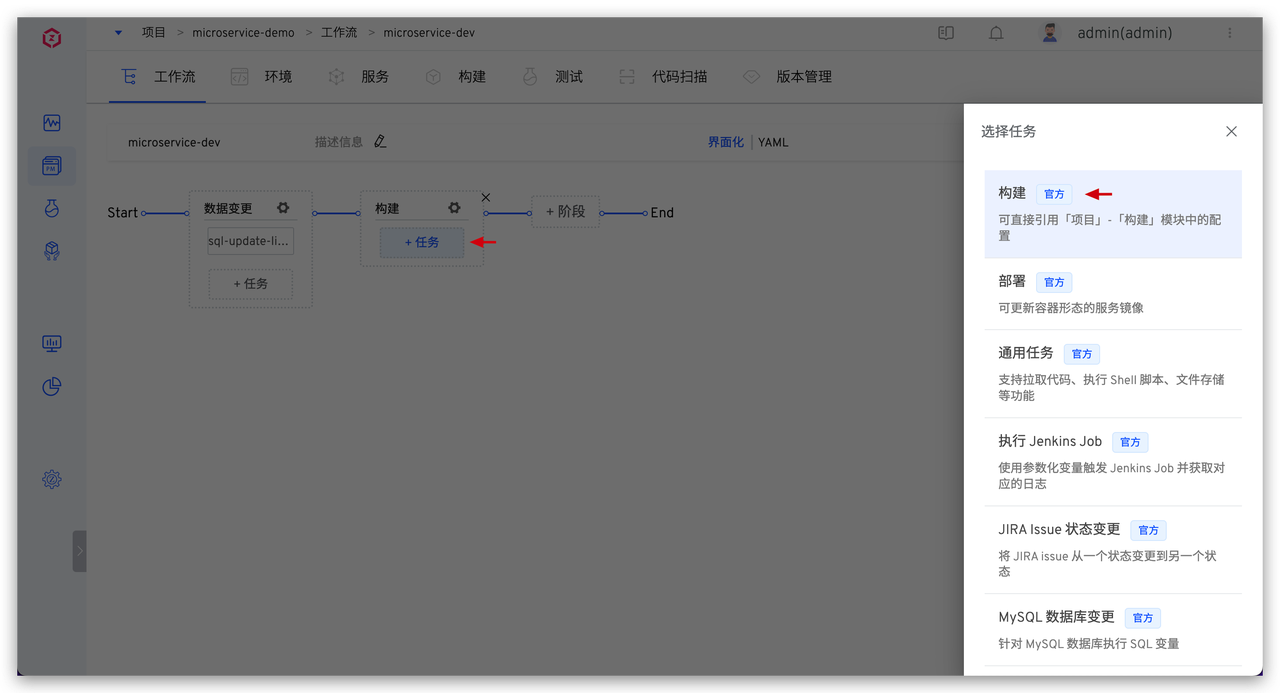
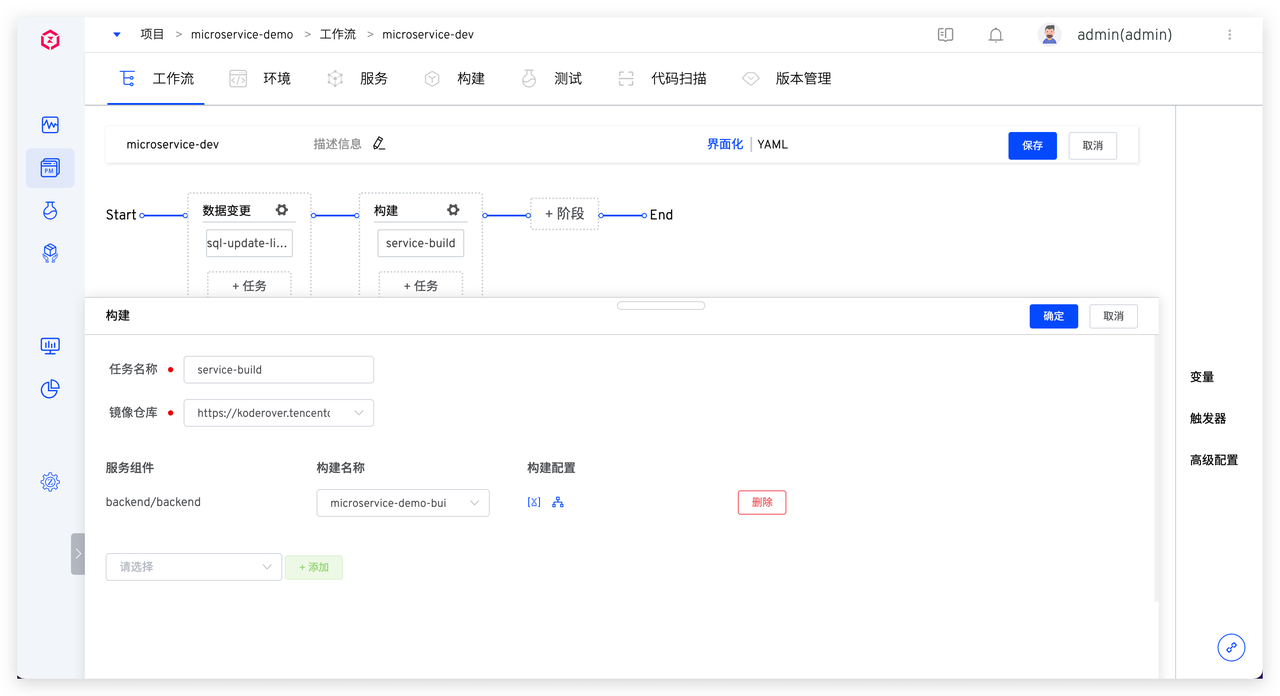
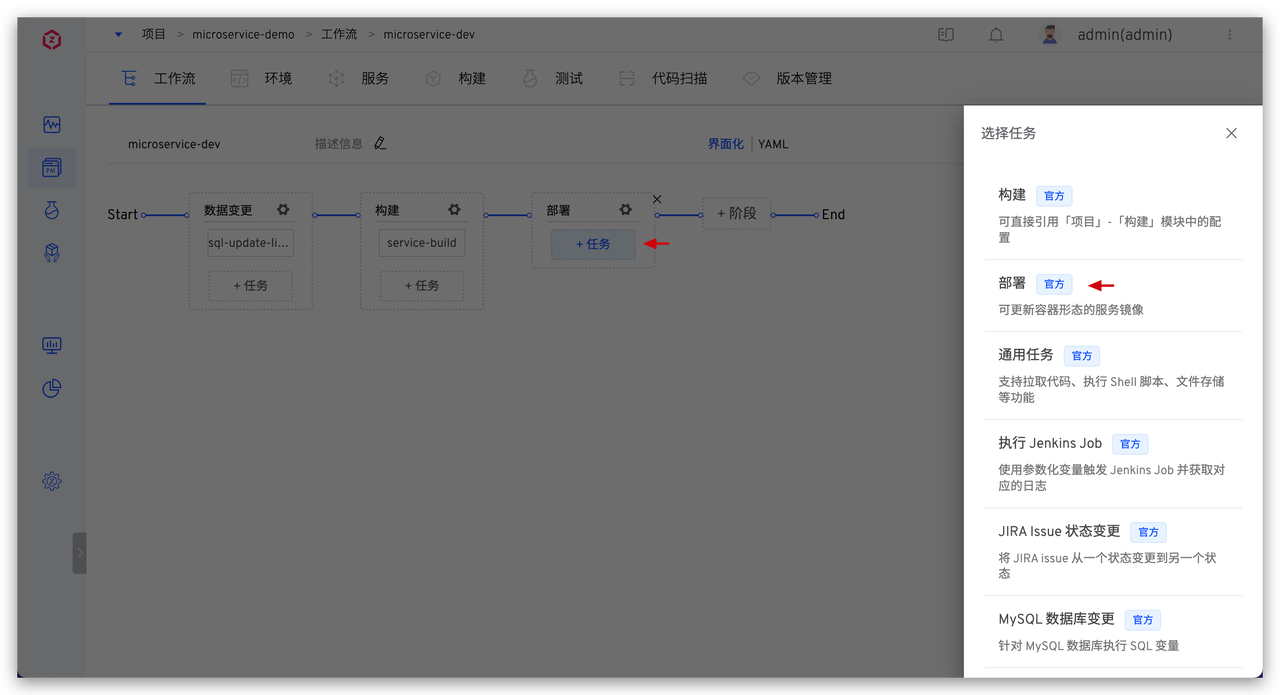
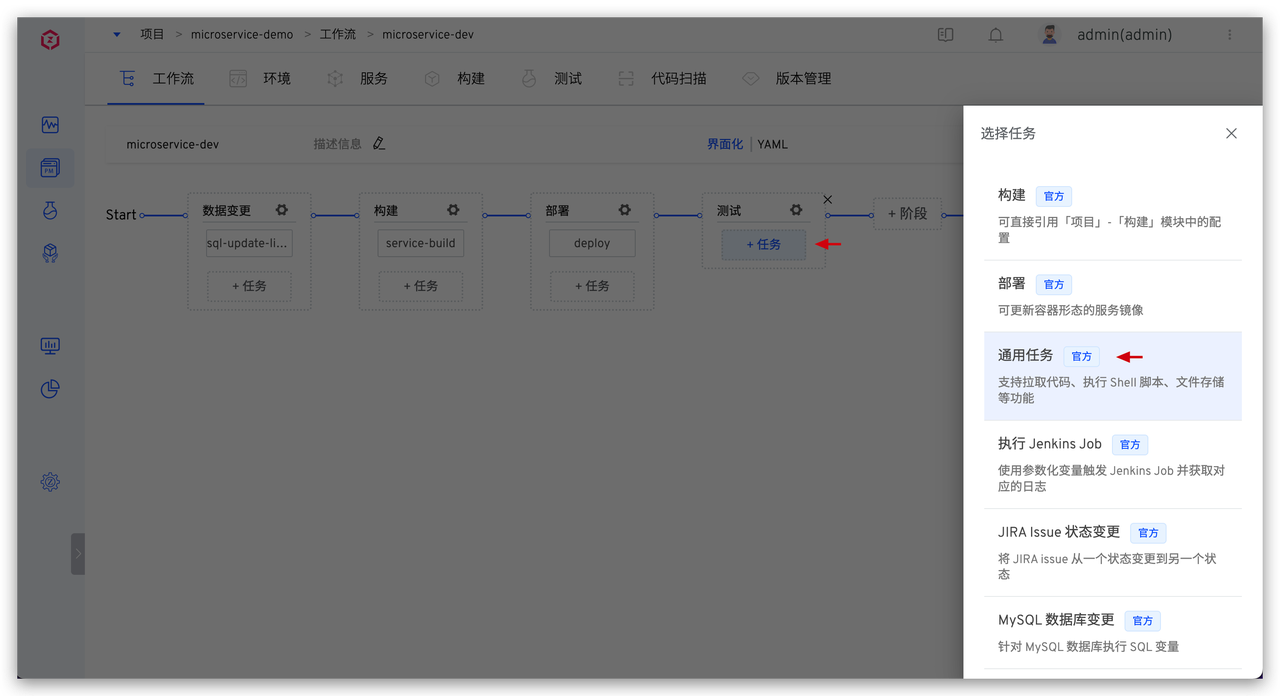
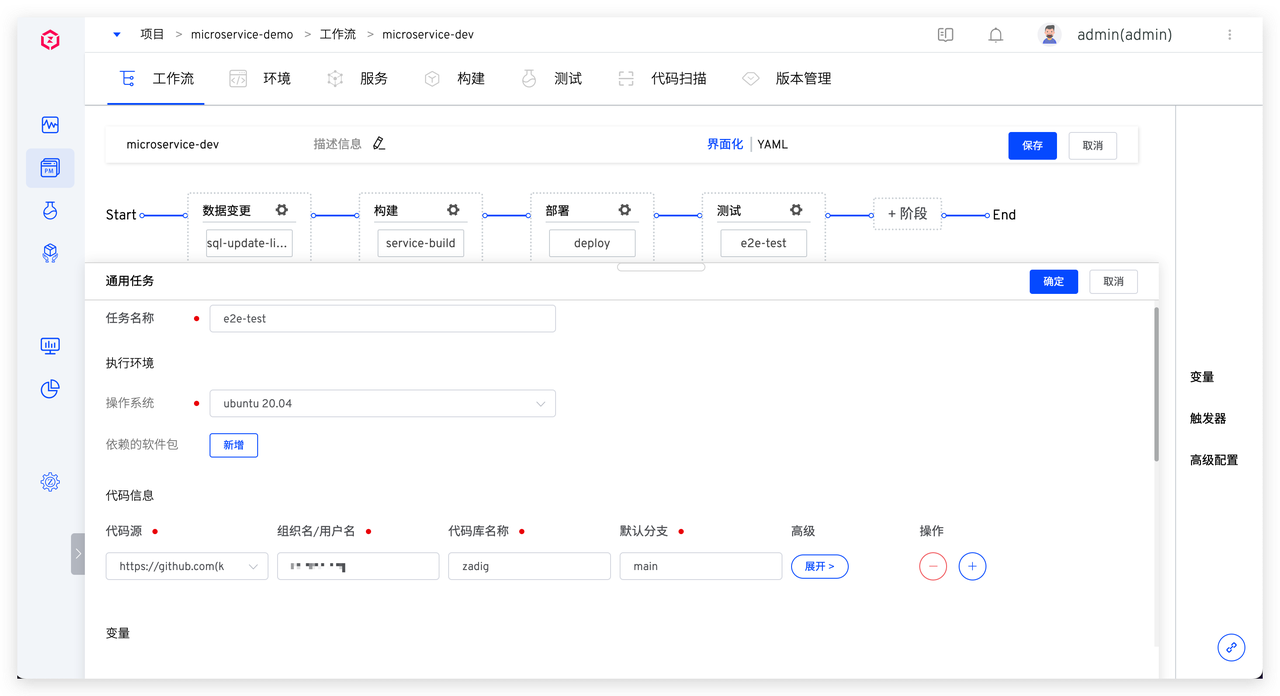
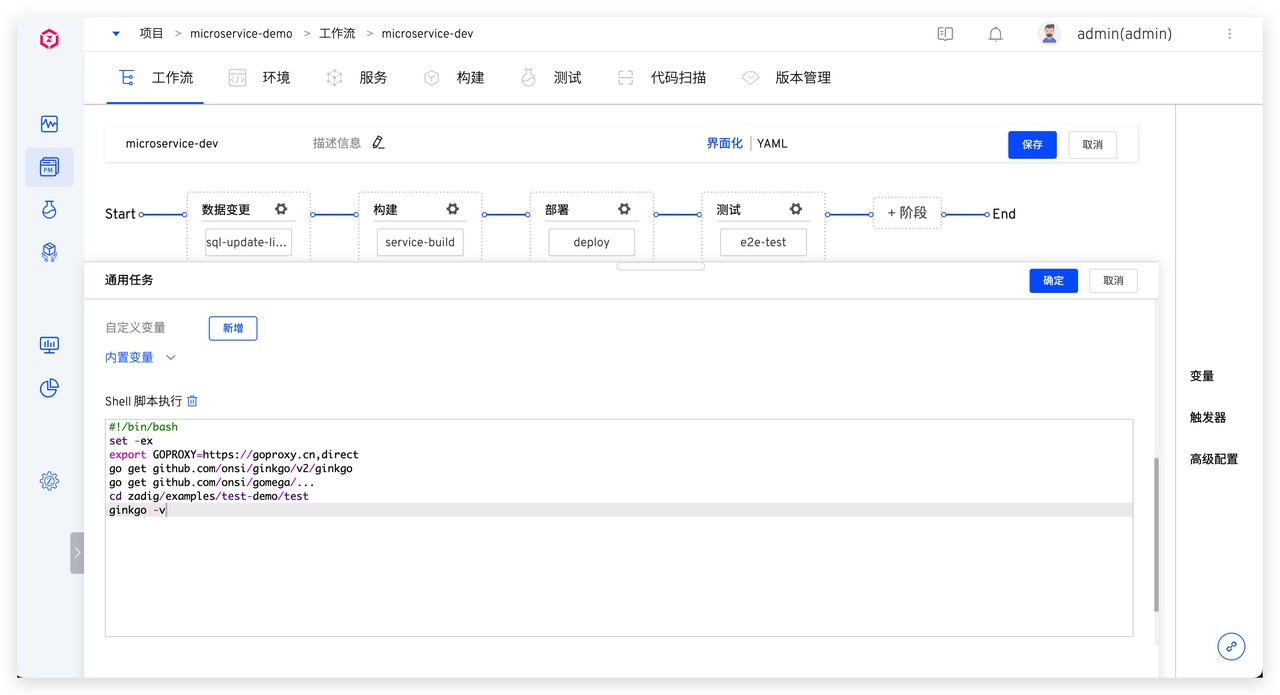
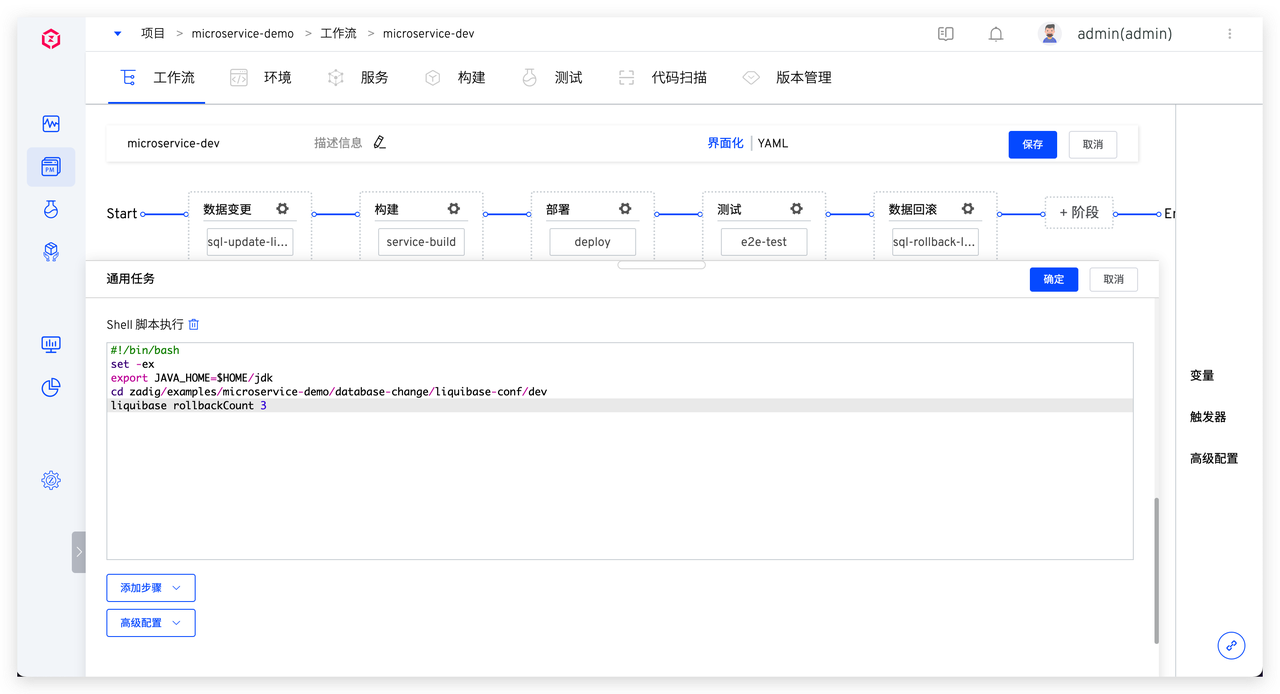 具体脚本参考如下:
具体脚本参考如下: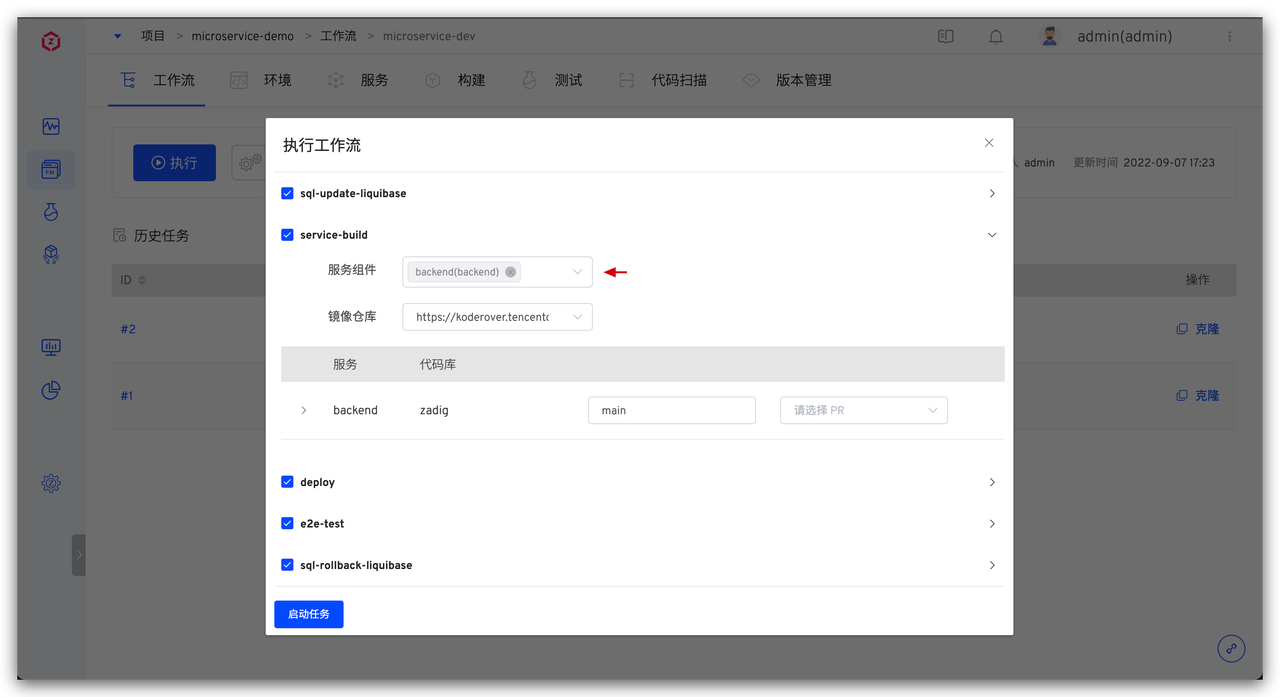 系统会顺序执行
系统会顺序执行 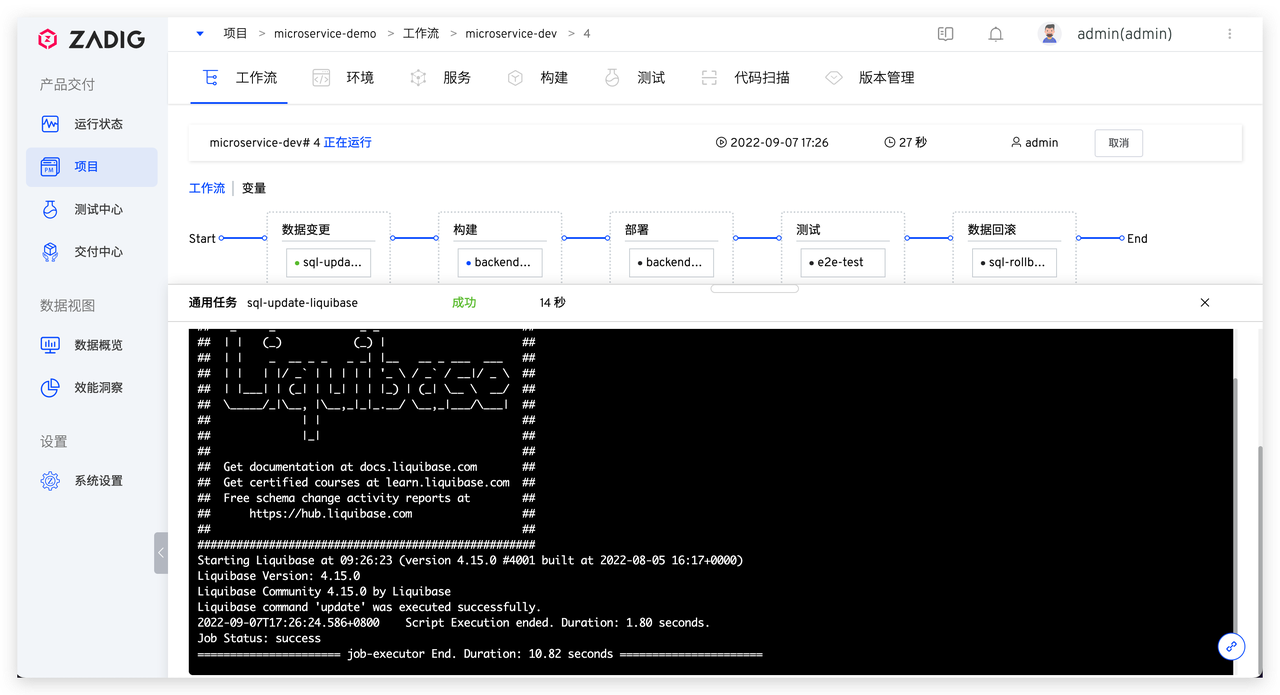
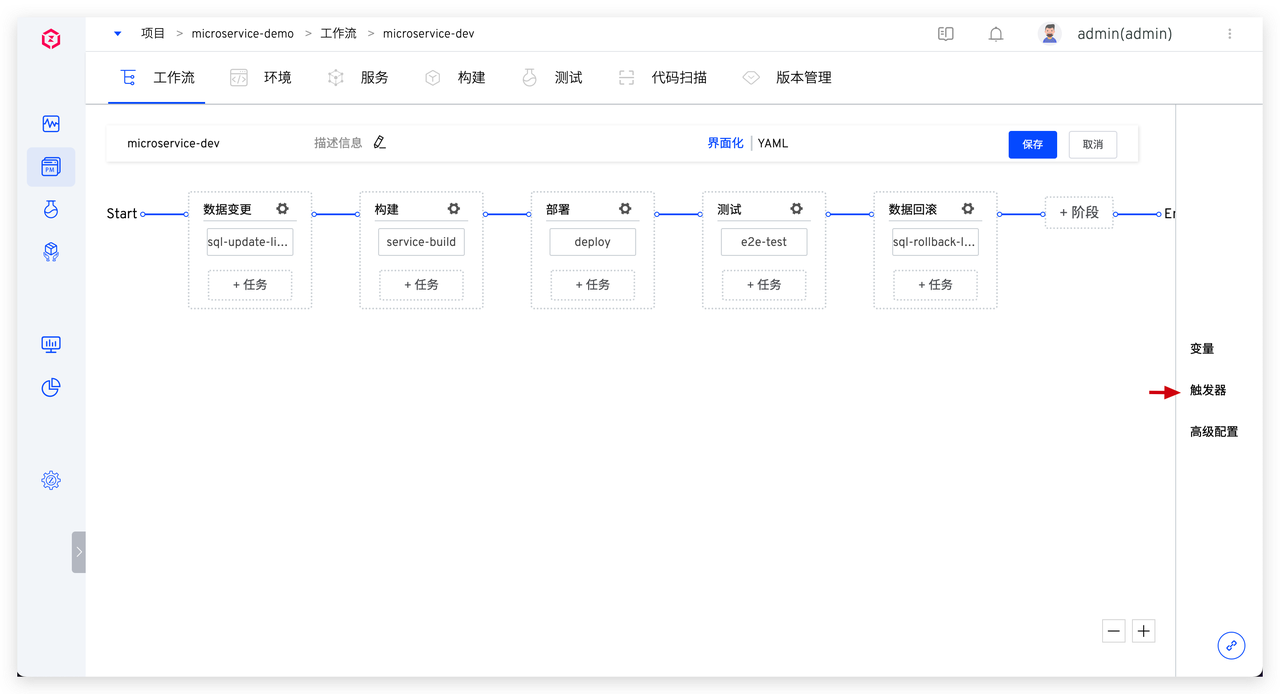
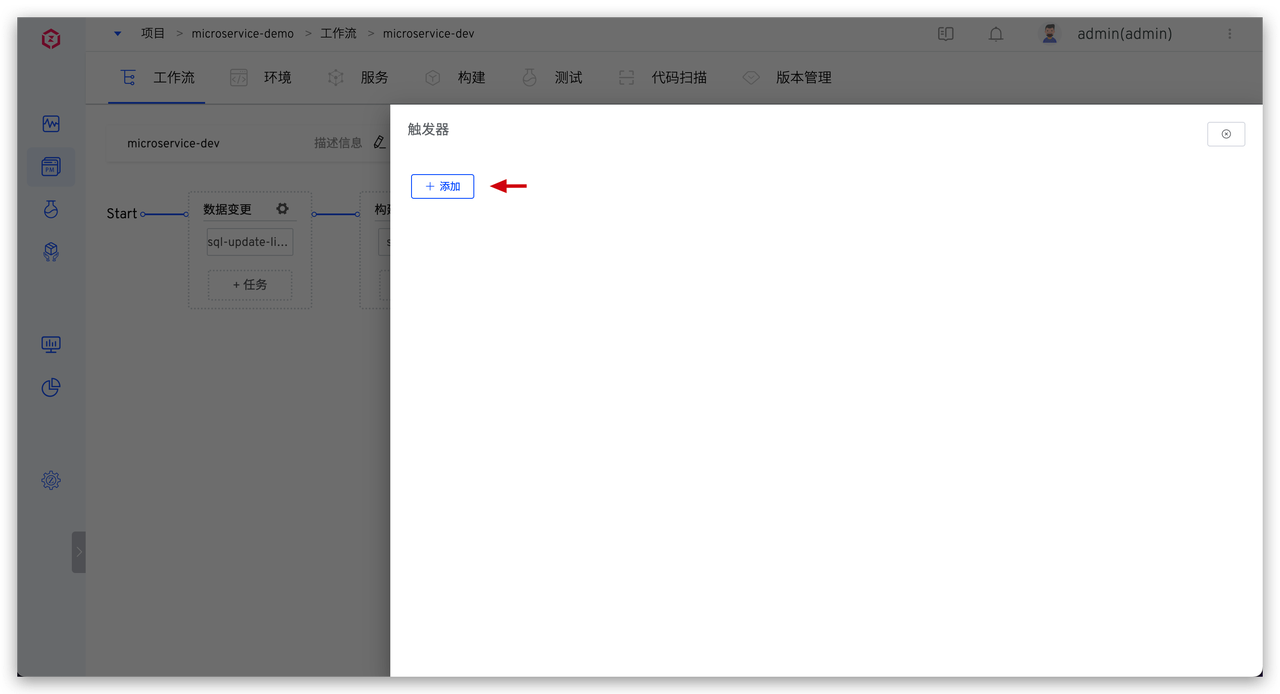
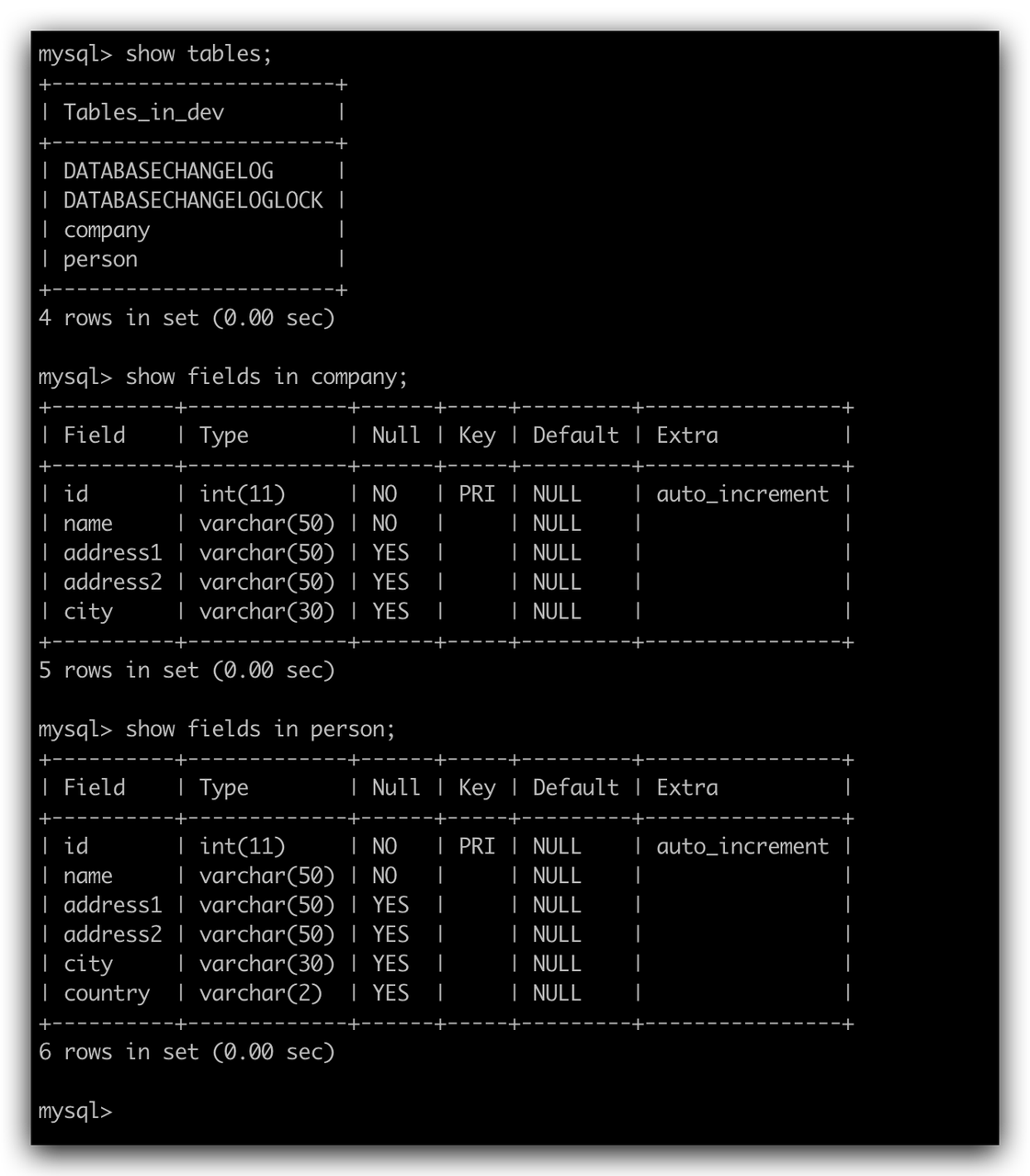 点击
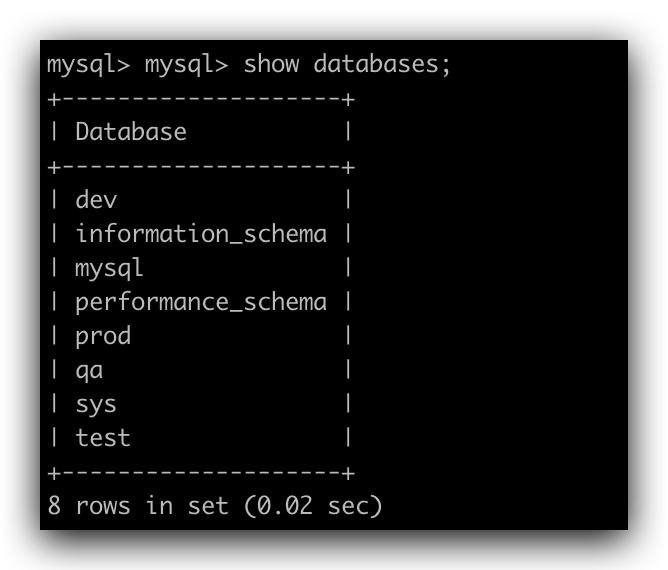
点击 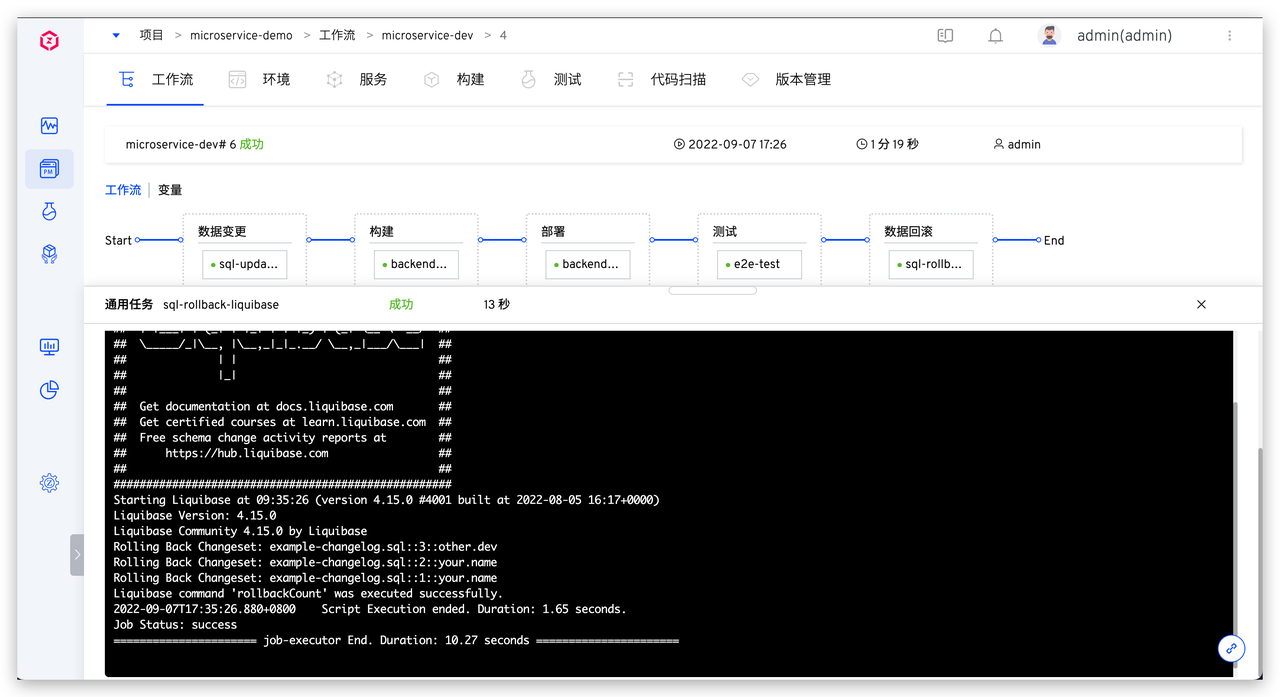 任务执行完成后再次查看数据库中数据如下,可发现在此次流程中创建的数据表均已被清理。
任务执行完成后再次查看数据库中数据如下,可发现在此次流程中创建的数据表均已被清理。 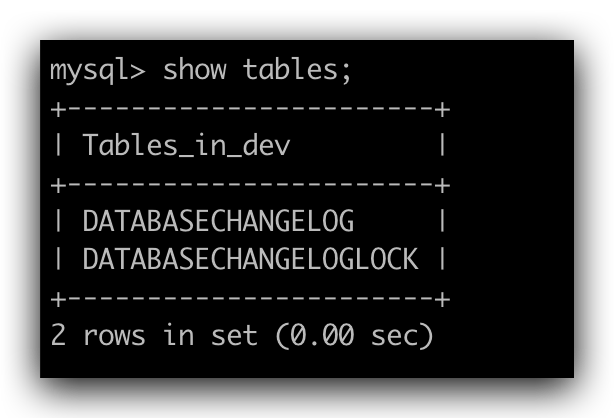

上游优先的故事
作者:tison,Apache Member & 孵化器导师,StreamNative Community Manager 微信公众号:“夜天之书”,关注开源共同体的发展,致力于回答 “如何建设一个开源社群” 的问题。 原文链接:https://mp.weixin.qq.com/s/GL2_wMxdYBpM399RmNJQKg 开源软件的用户在使用过程中遇到问题时,几乎总是先在自己的环境上打补丁绕过或快速修复问题。开源协同的语境下,开源软件以及维护开源软件的社群统称为该软件的上游,用户依赖上游软件的应用或基于上游软件复刻(fork)的版本统称为下游。上游优先(Upstream First),指的就是用户将下游发现的问题、做出的修改反馈到上游社群的策略。 网络上已经有不少文章讨论上游优先的定义、意义和通用的做法。例如,小马哥为极狐 GitLab 撰写了《Upstream First: 参与贡献开源项目的正确方式》。不过,这些文章往往是站在社群、平台或布道师的层面做笼统的介绍。本文希望从一个开发者的角度出发,由几个具体的上游优先的故事,讨论开发者角度实践上游优先策略的动机和方法。 ...