近日,Google Cloud、Kyligence 和 WebEye 共同举办了「智能数据助力企业数字化转型」的线上研讨会,Kyligence 技术合伙人兼副总裁李栋在会上分享了主题为「Kyligence Cloud 简化数据湖多维分析」的演讲。
以下为李栋演讲实录
大家好,我是李栋,Kyligence 是 Google Cloud ISV Partner,今年我们最新的云原生多维数据库产品 Kyligence Cloud 也支持了 Google Cloud,今天我将会给大家介绍企业如何通过智能多维数据库,从业务视角管理数据湖。
1. 数据湖分析典型痛点
![]()
越来越多企业都开始在云上搭建数据湖,支撑企业内部的数据分析和数据决策,但在数据湖和真正的数据应用之间往往存在很多痛点。如今,多数企业面临的不再是数据量过少,而是数据量太多,这导致业务用户在查找和使用数据时,难以精准定位到想要的数据。
从数据入到数据湖,再到被业务用户使用,不仅时效性较差,而且整个过程依赖数据工程师去进行 ETL,数据开发流程比较繁重。所有 ETL 都需要消耗大量计算资源和存储资源,会大大提升数据平台的成本;而随着数据的增大,TCO 也会逐渐增长。这些可能是每一位在使用数据湖相关技术的用户都会遇到的问题。
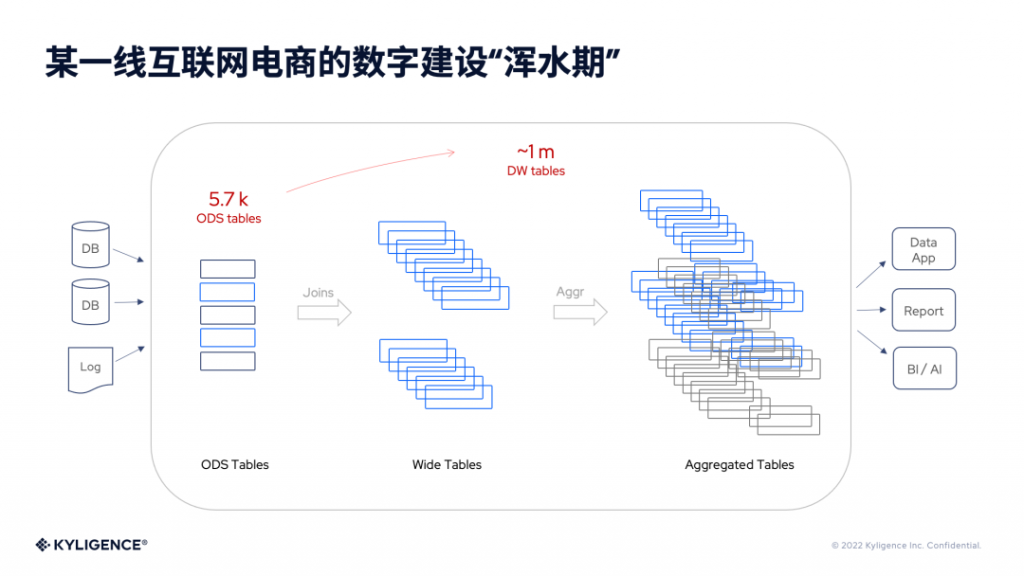
这里举 Kyligence 服务的一线互联网电商企业作为例子,这家企业在 2019 年开始搭建自己的数字分析平台,正式进入数字化转型的阶段。其所有数据要通过数据库,落到数据湖,下游是各种数据产品、报表以及 BI、AI 的应用等,用户从数据湖中分析数据,使用一段时间就会发现数据湖逐渐进入“浑水期”。
企业所有数据加载到数据湖上,起初可能只有 5700 多张贴源层 ODS 表。但是随着业务使用越来越多,每一个数据分析需求或每一个数据产品背后都需要从源表进行一系列的加工和处理,就变成超过 100 万张的宽表或聚合表。虽然现阶段数据分析和数据应用的业务可以正常开展,但是企业在数据湖的数据管理方面会逐渐地进入混乱的阶段。
![]()
举个例子,这里的 order 表就是订单表,它被业务引用的次数很多,我们可以看到它的整个后继节点。在数据血缘上来看,一个 order 表的后继节点至少有超过 1 万多张表。同样的一份原始数据,可能被加工成了一万多张宽表,应用在不同的业务和数据分析场景中,后续就会带来很多问题。
假如这里 ETL 的计算逻辑、指标加工的逻辑、数据时效性等这些生命周期的管理不一致,很容易造成同样一份数据出来的指标结果是不一样的。那么对于这家企业而言,他们就会面临“宽表爆炸”的情况。其实现在很多企业都面临类似的挑战,这大大影响了数据分析的 ROI ,短期来看数据分析的目标也许达到了,但是背后的投入和成本其实是过高的。
1.1 数据口径不一致
一个 order 表就衍生出上万张宽表,宽表间是缺少信任的。用户在使用时,很难说哪张表的数据是最可信的。对于这家电商而言,不同区域或者部门计算出来的 revenue 指标累加在一起,很可能和直接从贴源数据里加工算出来的 total revenue 是不一样的,这种情况可能在很多企业并不少见。
1.2 浑浊的数据湖
对于整个数据湖而言,数据存储方面上会变得愈加浑浊。每个业务部门或者 BU 都会有一些属于自己的数据集。对于一个订单数据而言,财务部、运营部门、市场部门都会基于这个数据去来打造自己的数据集。其实,这背后的很多数据指标往往是共享或者是逻辑一致的,但是这些数据本身却很难被复用。而这些问题的积累就会导致宽表爆炸愈加激烈,这些 ETL 和宽表的快速增长会带来大量存储和计算资源的冗余。
1.3 IT 成本过高
如果企业的用户数增长了 100 倍,那 IT 的成本难道也需要增长 100 倍吗?其实这样增长是难以控制的,不同业务的复杂程度是不一样的。如果因为某些业务很复杂,就把整个 IT 成本提高,而其他业务并不需要,就会产生成本浪费。
2. Kyligence 智能多维数据库产品
Gartner 2022 年报告指出,当前数据湖上的很多企业,在引入数据仓库等技术去支撑数据分析时,也希望通过数据仓库的理论改善数据管理方面的痛点。通过 Kyligence 智能多维数据库,企业可以把数据集市或者是 OLAP 理论引入到数据湖,解决数据管理类的问题。
![]()
2.1 产品架构
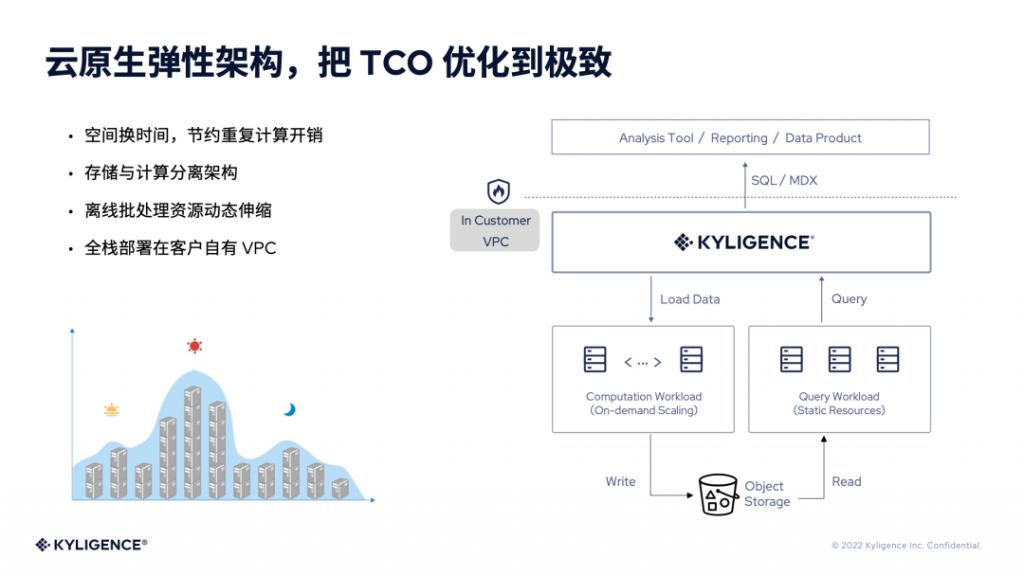
下图是 Kyligence 产品的架构,从整个技术架构上来看,只要数据已经接入到 Google Cloud ,比如说云存储、Google SQL 、Google BigQuery 等,企业就可以从该平台接入数据并创建数据模型来搭建数据集市。
![]()
Kyligence 智能多维数据库中最核心的概念就是多维数据模型,从数据源中接入数据,创建出多维数据模型,然后通过标准的 SQL 或 MDX 接口,将多维数据模型在BI 工具或 Excel 等数据分析的工具中进行消费。
Kyligence 以 Apache Kylin 为核心,融合了 ClickHouse 等技术,来支撑数据分析中高性能和高并发的场景。同时,Kyligence 的 AI 增强引擎,可以根据查询模式的变化,自动优化数据模型,一方面节约成本,另一方面优化性能。Kyligence Cloud 支持无缝兼容 Google Cloud,只要数据在 Google Cloud 上就可以直接使用,从而加速数据洞察和分析的过程。
![]()
因为多维数据模型的存在,每个模型内部会统一存储所有数据的指标,统一数据指标口径的管理,自动化和简化数据开发的过程。同时,Kyligence 的 OLAP 引擎可以针对大数据量进行优化,企业能以更低的 TCO 来支撑更大的数据量。
2.2 核心概念
在关系型数据库中,数据往往是两维的,表要么是行,要么是列。但是实际的业务往往是多维的,比如业务分析,大家会从不同维度和属性查看指标及数据洞察。如果想要从业务视角来管理和分析数据湖,多维数据库会是更好的方式。因为在多维数据库里核心概念是多维数据模型,而不是表。
![]()
传统关系型数据库中的原始表可能只有 DBA 或者懂技术的同事才能理解,但多维数据模型用的是业务语言,暴露的直接是维度和指标,业务人员能够更好地理解数据和使用数据。
同时,多维数据库把所有的业务语义和指标进行统一的管理,而不是分散地存储在各个宽表里面。从接口上,其实只要定义好一个模型,通过 SQL 或者 MDX 把指标给暴露出去,就可以直接在 BI 工具当中使用。
接下来,通过一个例子来看多维数据库如何解决上述问题。
![]()
对于电商企业而言,不同的部门有不同的分析需求。比如,美国和国内的销售团队,会去做数据加工,生成一张宽表,再进行聚合。以此类推,由于不同的团队数据分析需求不同,都会进行类似操作。慢慢平台里就会出现八张表,至少有四张大宽表,四张聚合表。但通过多维数据模型,就可以把这些表的数据模型定义在多维数据库中,把所有的数据进行整合。
![]()
从存储和计算资源上看,这里其实是从八张表变成三张表的过程,需要生成四次大宽表的超大规模数据集下计算的 ETL 任务,现在只需要一次。所以整个的存储和计算资源的消耗都会大大的降低,这也是如何通过多维数据模型解决宽表爆炸。
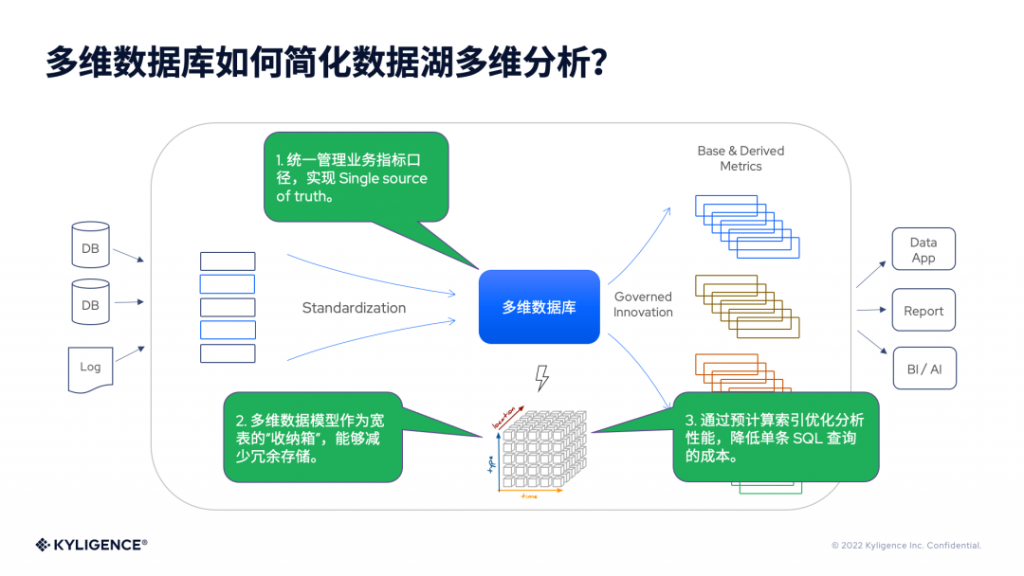
在多维数据库上,企业可以去定义业务分析使用的指标,并形成指标体系,如基础指标、衍生指标等。如果不同的指标背后对应的数据模型是同一个,那么指标的加工和计算过程是可以复用的。如果同一份数据按不同口径、服务不同业务,则通过衍生指标灵活响应业务需求,既能满足业务多变的需求,又能避免数据冗余导致的宽表爆炸。
![]()
在多维数据库中,企业可以统一管理所有业务指标的口径来实现 Single Source of Truth;其次,多维数据模型可以把所有宽表收纳在一起,减少冗余的存储;除此之外,预计算索引还可以优化查询性能,进一步降低单条 SQL 查询的使用成本。
对于客户而言,通过 Kyligence 多维数据库把最初 5700 多张 ODS 表,逐渐变成 2000 多个基础指标和一万多个衍生指标,以管理指标的方式来去管理这些数据,更好地提升数据服务的 ROI,降低冗余存储。业务人员可以更容易地使用所有指标,实现自助式数据分析;同时,整个架构又是云原生的弹性架构,在 Google Cloud 上可以实现动态的伸缩。
3. Kyligence 指标中台产品实践
Kyligence 基于指标中台实践经验和云原生 OLAP 基础能力,上线了智能指标驱动的管理和决策平台 Kyligence Zen,李栋从以下四个方面介绍了指标中台的能力:
- 指标目录:统一管理所有业务指标口径从数据湖的表开始定义指标,包括基础指标和衍生指标,并将所有指标管理在一个平台中,实现业务指标的统一管理。
- 指标自动化:以指标管理数据,消除宽表操作根据指标定义的逻辑对底层数据进行加工、预计算,并根据指标所在的数据模型进行合并,消除宽表爆炸。若是指标很少被访问或是不再被访问,可以自动清理指标数据的预计算结果。此外,系统也会智能向用户推荐常用或关联度高的指标,提升找指标的效率。
- 目标管理:用目标管理指标,形成指标体系管理指标的目的是帮助企业实现业务目标管理,因此通过管理目标的方式管理指标,形成指标体系,可帮助企业更好地达成目标。
- API 集成:构建数据应用,一致消费指标数据当指标和目标完成定义,系统需要一个出口。通过标准的指标 API ,让用户轻松构建数据应用,为应用提供一致的数据来源,消除指标割裂和数据孤岛。
如果您对 Kyligence Zen 感兴趣,欢迎点击 Kyligence Zen 指标平台申请试用。