今晚20:30,Kubernetes Master Class在线培训第四期《企业如何构建CI/CD流水线》即将开播,点击链接:http://live.vhall.com/729465809 即可免费预约注册!
![]()
介 绍
Kubernetes在GitHub上拥有超过48,000颗星,超过75,000个commit,拥有以Google为代表的科技巨头公司为主要贡献者。可以说,Kubernetes已迅速掌管了容器生态系统,成为容器编排平台的真正领导者。
Kubernetes提供了诸如部署的滚动和回滚、容器健康检查、自动容器恢复、基于指标的容器自动扩展、服务负载均衡、服务发现(适用于微服务架构)等强大功能。在本文中,我们将讨论Kubernetes重要的基本概念、master节点架构,并重点关注节点组件。
理解Kubernetes及其抽象
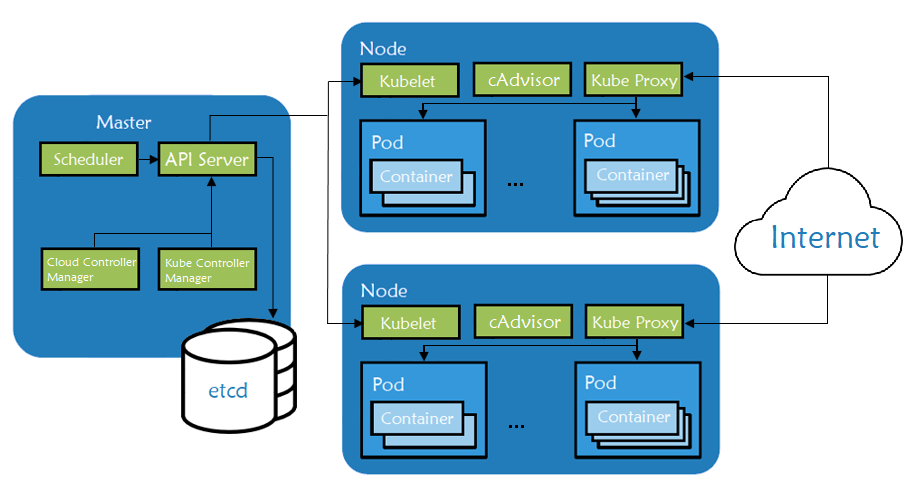
Kubernetes是一个开源的编排引擎,用于自动部署、扩展、管理和提供托管容器化应用程序的基础架构。在基础架构级别,Kubernetes集群由一组物理或虚拟机组成,每个机器都以特定角色运行。
Master机器就像是所有业务的大脑,负责编排所有运行在节点机器上的容器。每个节点都配有一个容器运行时。节点接收来自master的指令,然后执行操作来创建pod、删除pod或调整网络规则。
![]()
Master组件负责管理Kubernetes集群。它们管理pod的生命周期,pod是Kubernetes集群内部署的基本单元。Master Server运行以下组件:
-
kube-apiserver - 主要组件,为其他master组件公开API。
-
etcd - 分布式密钥/值存储库,Kubernetes使用它来持久化存储所有集群信息。
-
kube-scheduler – 依照pod规范中的信息,来决定运行pod的节点。
-
kube-controller-manager - 负责节点管理(检测节点是否出现故障)、pod复制和端点创建。
-
cloud-controller-manager - 守护进程,充当API和不同云提供商工具(存储卷、负载均衡器等)之间的抽象层。
节点组件是Kubernetes中的worker机器,受到master的管理。节点可以是虚拟机(VM)或物理机器——Kubernetes在这两种类型的系统上都能良好运行。每个节点都包含运行pod的必要组件:
-
kubelet – 为位于那个节点上的pod监视API服务器,确保它们正常运行
-
cAdvisor - 收集在特定节点上运行着的pod的相关指标
-
kube-proxy - 监视API服务器,实时获取pod或服务的变化,以使网络保持最新
-
容器运行时 - 负责管理容器镜像,并在该节点上运行容器
Kubernetes节点组件详解
总而言之就是,节点上运行着两个最重要的组件——kubelet和kube-proxy,除此之外还有一个负责运行应用容器化应用程序的容器引擎。
kubelet
kubelet处理着master和在其上运行的节点之间的所有通信。它以manifest的形式接收来自主设备的命令,manifest定义着工作负载和操作参数。它与负责创建、启动和监视pod的容器运行时进行接合。
kubelet还会周期性地对配置的活跃度探针和准备情况进行检查。它会不断监视pod的状态,并在出现问题时启动新实例。kubelet还有一个内部HTTP服务器,在端口10255上显示一个只读视图。除此之外,在/healthz上还有一个健康检查端点,以及一些其他状态端点。例如,我们可以在/pods获取正在运行的pod的列表。我们还可以在/spec获取kubelet正在运行的机器的详情。
kube-proxy
kube-proxy组件在每个节点上运行,负责代理UDP、TCP和SCTP数据包(它不了解HTTP)。它负责维护主机上的网络规则,并处理pod、主机和外部世界之间的数据包传输。它就像是节点上运行着的pod的网络代理和负载均衡器一样,通过在iptables使用NAT实现东/西负载均衡。
kube-proxy过程位于连接到Kubernetes的网络和在该特定节点上运行的pod之间。它本质上是Kubernetes的核心网络组件,负责确保跨集群的所有元素有效地进行通信。当用户创建Kubernetes服务对象时,kube-proxy实例会负责将该对象转换为位于worker节点的、本地iptables规则集上的有意义的规则。iptables用于将分配给服务对象的虚拟IP转换为服务映射的所有pod IP。
容器运行时
容器运行时负责从公有或私有镜像仓库中拉取镜像,并根据这些镜像运行容器。当下最流行的容器引擎无疑是Docker,不过Kubernetes还支持诸如rkt、runc等的其他容器运行时。正如我们在上文中提到过的,kubelet会直接与容器运行时交互,以启动、停止或删除容器。
cAdvisor
cAdvisor是一个开源代理,它能够监视资源使用情况并分析容器的性能。cAdvisor最初由谷歌创建,现在已与kubelet集成。
位于每个节点上的cAdvisor实例,会收集、聚合、处理和导出所有正在运行的容器的指标,如CPU、内存、文件和网络使用情况等。所有数据都将发送到调度程序,以确保调度程序了解节点内部的性能和资源使用情况。这些信息会被用于执行各种编排任务,如调度、水平pod扩展、管理容器资源限制等。
从动手实操了解节点组件端点
接下来,我们将安装一个Kubernetes集群(在Rancher的帮助下),以此来开始探索节点组件公开的一些API。要完成下面的操作,我们需要:
-
Google Cloud Platform帐户(任何公有云也都是一样的)
-
一台主机,后续Rancher会运行在它上面(可以是个人PC / Mac或公有云中的VM)
-
在同一主机上,安装kubectl和 Google Cloud SDK。验证好您的相关credential(gcloud init和gcloud auth login),确保gcloud能正常访问您的Google Cloud账户
-
在GKE上运行的Kubernetes集群(运行EKS或AKS也是相同的)
启动Rancher实例
首先,启动Rancher实例。这一过程非常简单,参考快速上手指南即可:
https://rancher.com/quick-start/
使用Rancher部署GKE集群
使用Rancher设置和配置Kubernetes集群,同样是按指南进行操作即可:
https://rancher.com/docs/rancher/v2.x/en/cluster-provisioning/hosted-kubernetes-clusters/gke/
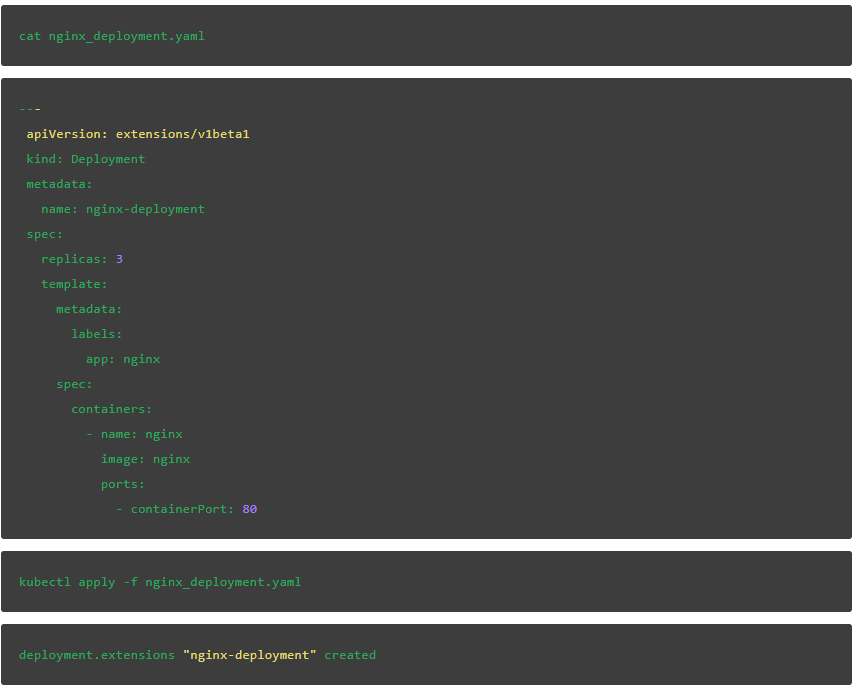
部署好集群后,我们可以快速部署Nginx以进行测试:
![]()
为了与Kubernetes API进行交互,我们需要在本地计算机上启动代理服务器:
![]()
让我们检查一下进度,看它是否正在正常运行,以及是否在监听默认端口:
![]()
现在,在浏览器中,检查kubelet公开的各种端点:
![]()
接下来,显示集群可用节点的列表:
![]()
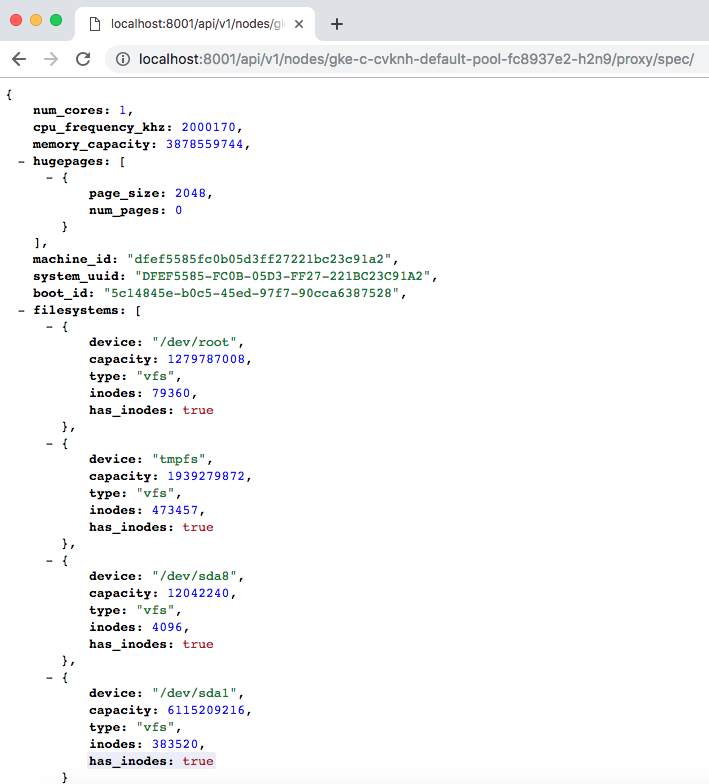
我们可以通过spec来检查所有列出的、使用API的节点。在本文的示例中,我们使用n1-standard-1机器类型(1个vCPU,3.75GB RAM,10GB的根大小磁盘)创建了一个3节点集群。我们可以通过访问专用端点来确认这些规范:
![]()
![]()
在不同端点使用相同的kubelet API,我们可以检查我们创建的Nginx pod,以查看它们正运行在什么节点上。
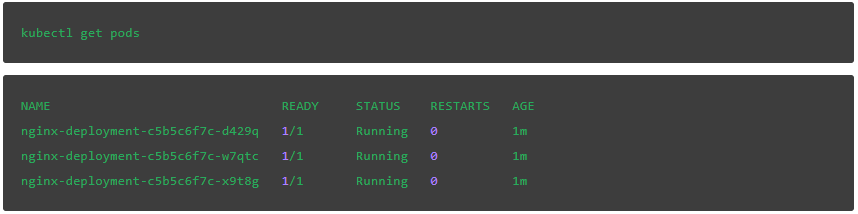
首先,列出正在运行的pod:
![]()
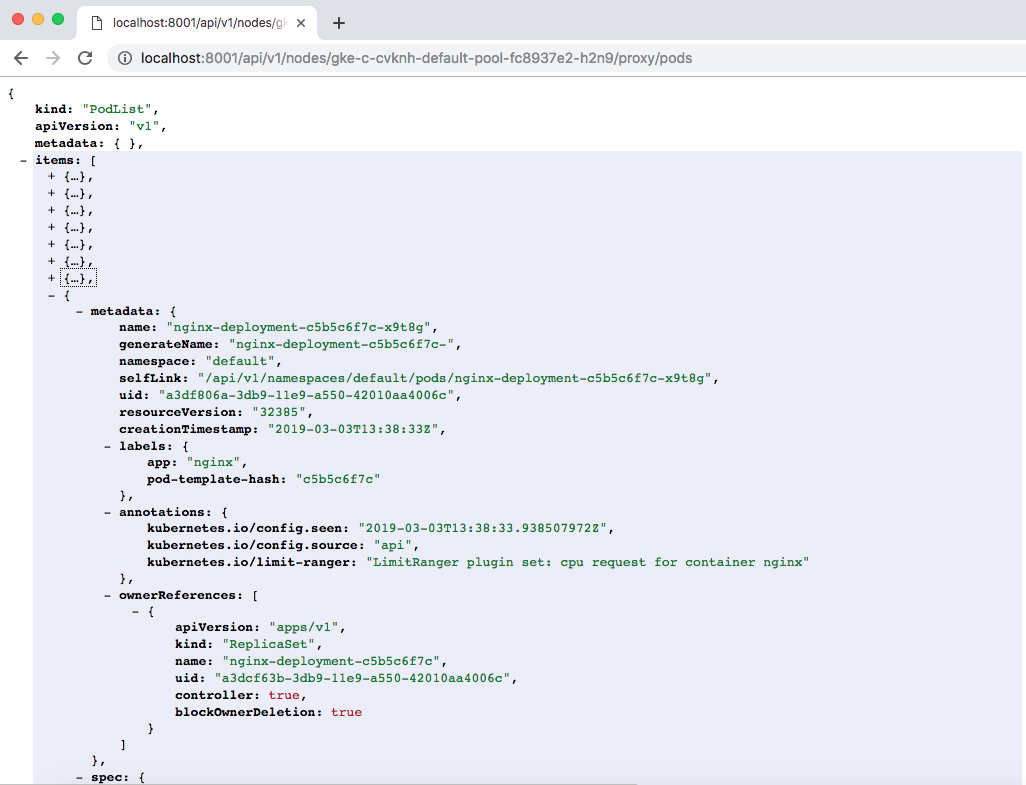
现在,curl每个节点的/proxy/pods端点,查看其运行的pod列表:
![]()
![]()
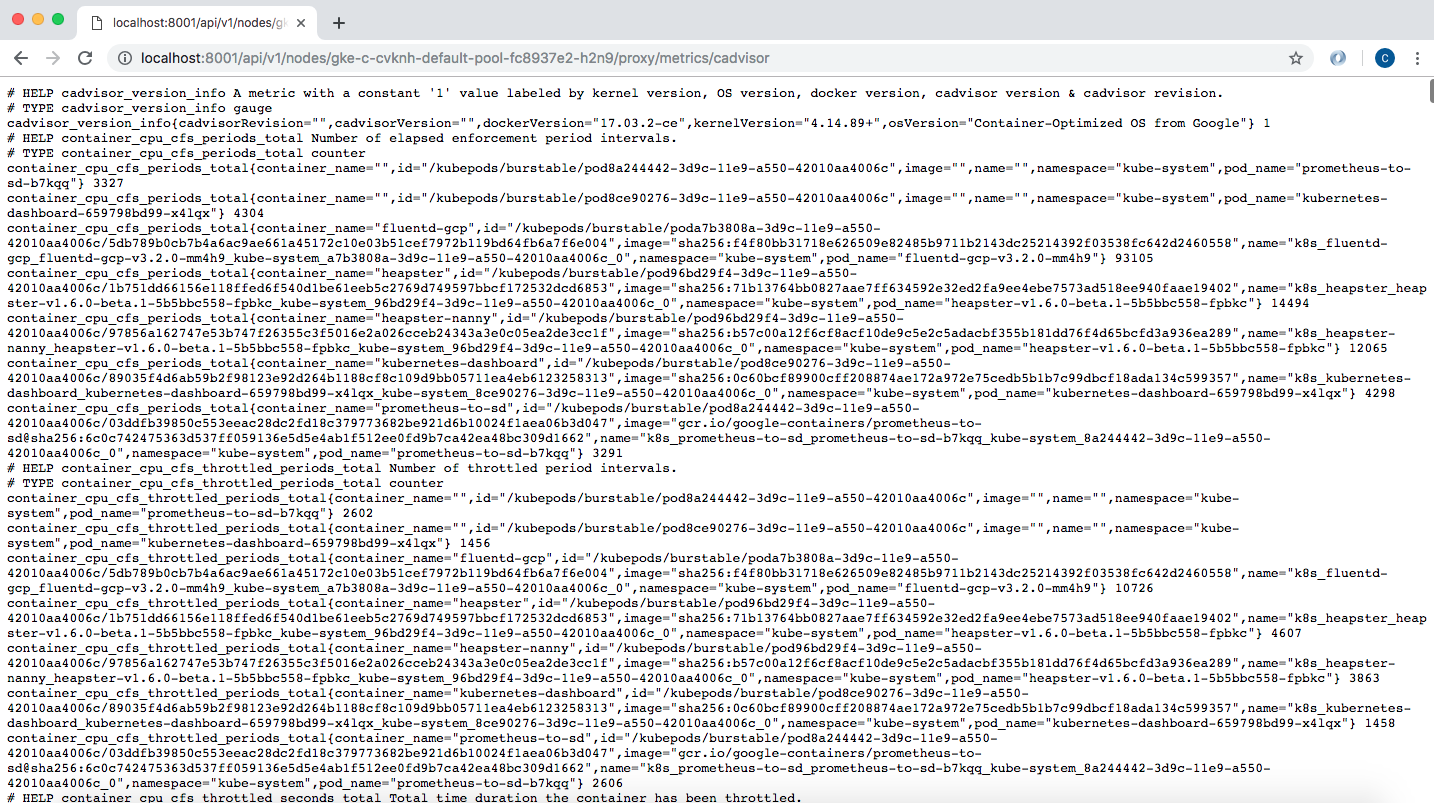
我们还可以检查cAdvisor端点,它会以Prometheus格式输出大量数据。默认情况下,这在/metrics HTTP端点可用:
![]()
![]()
SSH到节点并直接调用kubelet端口,也可以获得相同的cAdvisor或pod信息:
![]()
清理
要清理我们在本文中使用的资源,只需从Rancher UI中删除Kubernetes集群即可(选择集群并点击Delete按钮就可以了)。这将删除我们的集群正在使用的所有节点以及关联的IP地址。如果您是在公有云中使用VM来运行Rancher,那么您也需要处理它。找出您的实例名称,然后将其删除即可:
![]()
结 语
在本文中,我们讨论了Kubernetes节点机器的关键组件。之后,我们使用Rancher部署了一个Kubernetes集群,并完成了一个小型部署以帮助我们学习使用kubelet API。
若想了解有关Kubernetes及其架构的更多信息,Kubernetes官方文档是一个不错的起点:https://kubernetes.io/docs/concepts/overview/components/