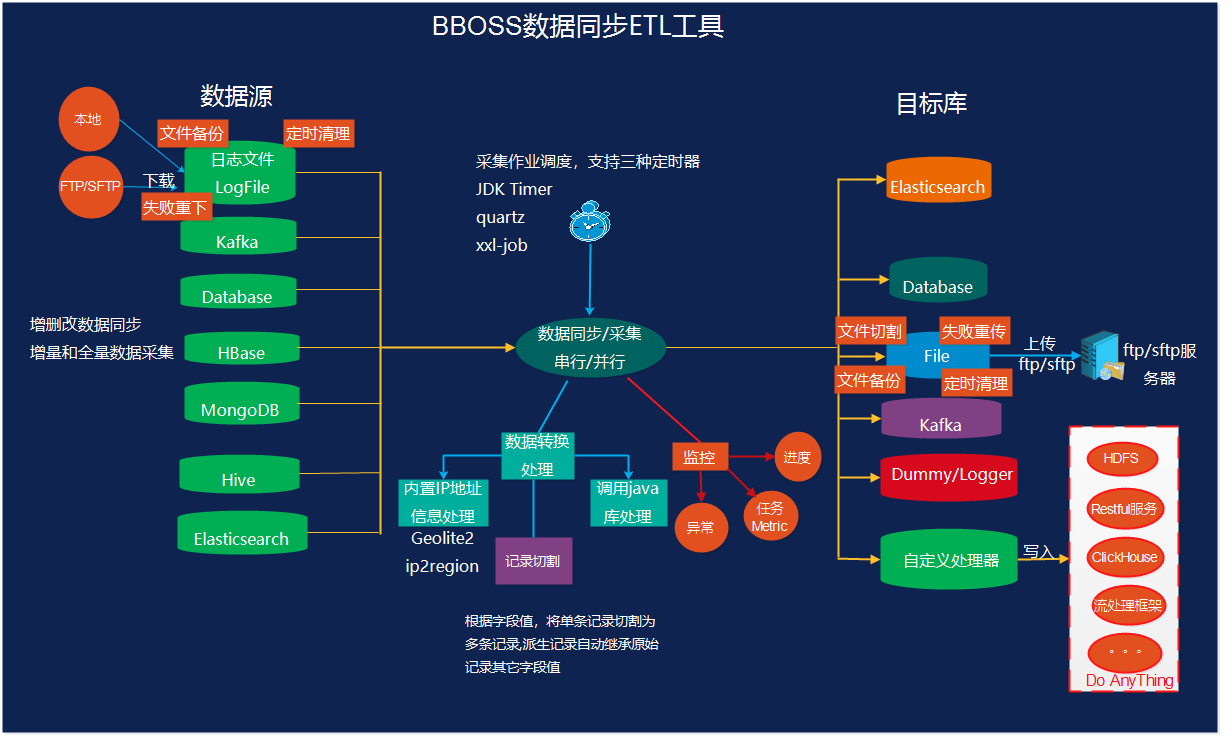
数据采集ETL工具 Elasticsearch-datatran v6.5.0 发布。
Elasticsearch-datatran 由 bboss 开源的数据采集同步ETL工具,提供数据采集、数据清洗转换处理和数据入库功能。支持在Elasticsearch、关系数据库(mysql,oracle,db2,sqlserver、达梦等)、Mongodb、HBase、Hive、Kafka、文本文件、SFTP/FTP多种数据源之间进行海量数据采集同步;支持本地/ftp日志文件实时增量采集到kafka/elasticsearch/database;支持根据字段进行数据记录切割;支持根据文件路径信息将不同文件数据写入不同的数据库表。
提供自定义处理采集数据功能,可以按照自己的要求将采集的数据处理到目的地,支持数据来源包括:database,elasticsearch,kafka,mongodb,hbase,file,ftp等,想把采集的数据保存到什么地方,由自己实现CustomOutPut接口处理即可。
Elasticsearch版本兼容性:支持各种Elasticsearch版本(1.x,2.x,5.x,6.x,7.x,+)之间相互数据迁移
![]()
一般项目导入下面的maven坐标即可:
<dependency>
<groupId>com.bbossgroups.plugins</groupId>
<artifactId>bboss-elasticsearch-rest-jdbc</artifactId>
<version>6.5.0</version>
</dependency>
如果是spring boot项目还需要导入下面的maven坐标:
<dependency>
<groupId>com.bbossgroups.plugins</groupId>
<artifactId>bboss-elasticsearch-spring-boot-starter</artifactId>
<version>6.5.0</version>
</dependency>
-
filelog插件添加子目录/ftp子目录/sftp子目录下日志文件采集功能
-
对filelog插件文件选择过滤器FileFilter接口方法accept进行了重构,增加目录和文件区分标识对象FilterFileInfo,以适配本地目录、ftp和sftp三种场景,调整如下
重构前
public boolean accept(String parentDir,String fileName, FileConfig fileConfig)
重构后
public boolean accept(FilterFileInfo filterFileInfo, //包含Ftp文件名称,文件父路径、是否为目录标识
FileConfig fileConfig)
使用案例
fileConfit.setFileFilter(new FileFilter() {//指定ftp文件筛选规则
@Override
public boolean accept(FilterFileInfo filterFileInfo, //包含Ftp文件名称,文件父路径、是否为目录标识
FileConfig fileConfig) {
if(filterFileInfo.isDirectory())//由于要采集子目录下的文件,所以如果是目录则直接返回true,当然也可以根据目录名称决定哪些子目录要采集
return true;
String name = filterFileInfo.getFileName();
//判断是否采集文件数据,返回true标识采集,false 不采集
boolean nameMatch = name.startsWith("731_tmrt_user_login_day_");
if(nameMatch){
String day = name.substring("731_tmrt_user_login_day_".length());
SimpleDateFormat format = new SimpleDateFormat("yyyyMMdd");
try {
Date fileDate = format.parse(day);
if(fileDate.after(startDate))//下载和采集2020年12月11日以后的数据文件
return true;
} catch (ParseException e) {
logger.error("",e);
}
}
return false;
}
})
因此升级到6.5.0时需要对采集作业的FileFilter接口方法accept进行相应调整
- db管理dsl mysql无法创建加载dsl问题处理
- log4j2版本升级2.17.1、slfj版本升级1.7.32
- 修复空行处理器Record问题:关闭key大写机制后,根据字段名称获取数据失效
- 忽略mysql stream机制情况下获取rowid失败异常
- 增加excel csv文件采集案例
https://github.com/bbossgroups/csv-dbhandle
https://gitee.com/bboss/csv-dbhandle
-
优化运行容器工具,增加从环境变量、jvm属性配置检索mainclass功能
默认使用org.frameworkset.elasticsearch.imp.DB2CSVFile作为作业主程序,
如果设置了环境变量mainclassevn,则使用mainclassevn作为作业主程序
环境变量名称不能和属性名称一致,否则报循环引用异常,并将原始值返回
mainclass=#[mainclassevn:org.frameworkset.elasticsearch.imp.DB2CSVFile]
使用参考文档:
https://my.oschina.net/bboss/blog/469411
-
升级mysql驱动版本号为8.0.28
-
增加通用异步批处理组件
使用案例:
https://gitee.com/bboss/eshelloword-booter/blob/master/src/test/java/org/bboss/elasticsearchtest/bulkprocessor/PersistentBulkProcessor.java
使用文档
https://esdoc.bbossgroups.com/#/bulkProcessor-common