
百度发布 PLATO-XL,全球首个百亿参数中英文对话预训练生成模型
【导读】和AI进行无障碍的对话,是什么样的体验?你或许能够在这篇文章里找到答案!百度全新发布PLATO-XL,参数达到了110亿,超过之前最大的对话模型 Blender,是当前最大规模的中英文对话生成模型,并再次刷新了开放域对话效果。
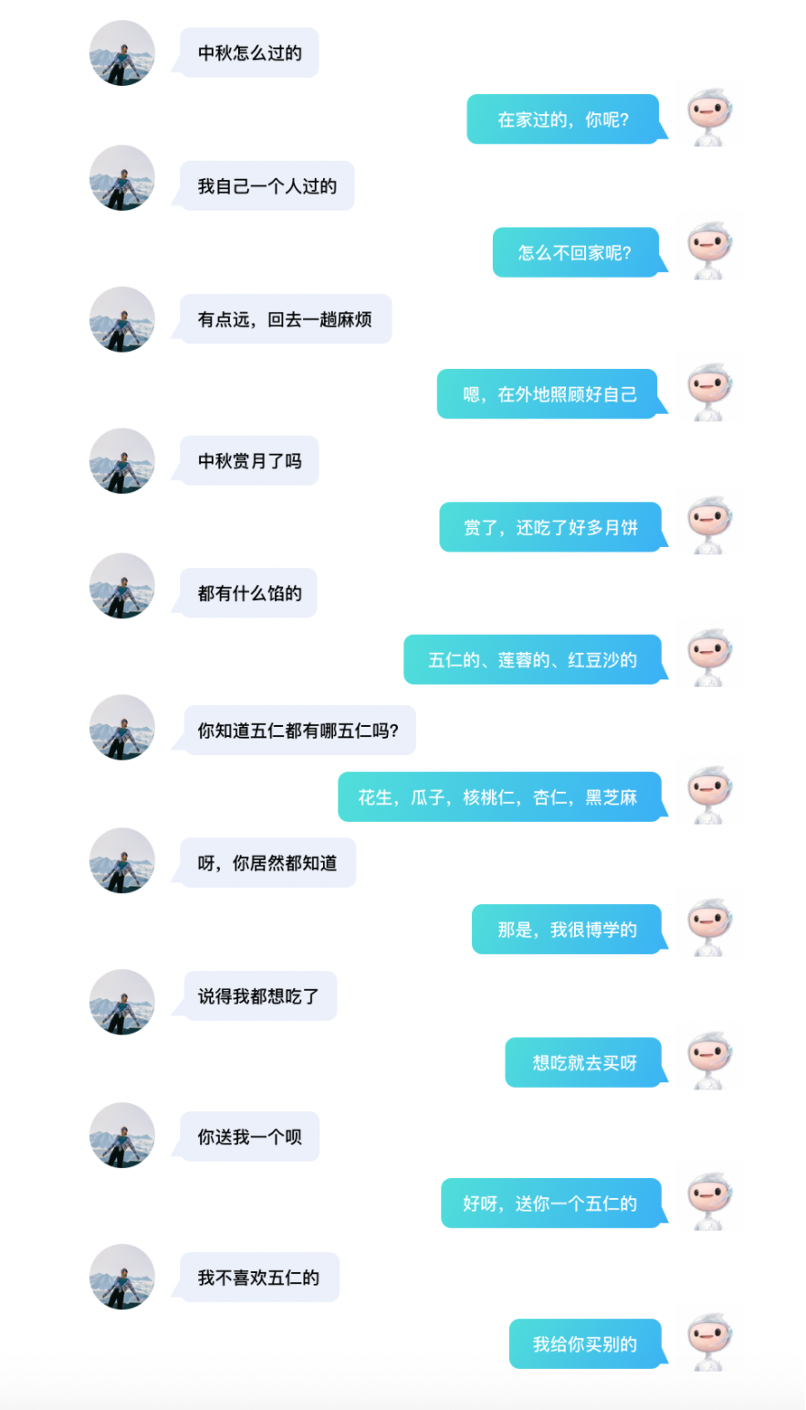
很难相信,以上是AI与人交流的真实对话记录。近日,百度发布新一代对话生成模型 PLATO-XL,一举超过Facebook Blender、谷歌Meena和微软DialoGPT,成为全球首个百亿参数中英文对话预训练模型,再次刷新了开放域对话效果,打开了对话模型的想象空间。
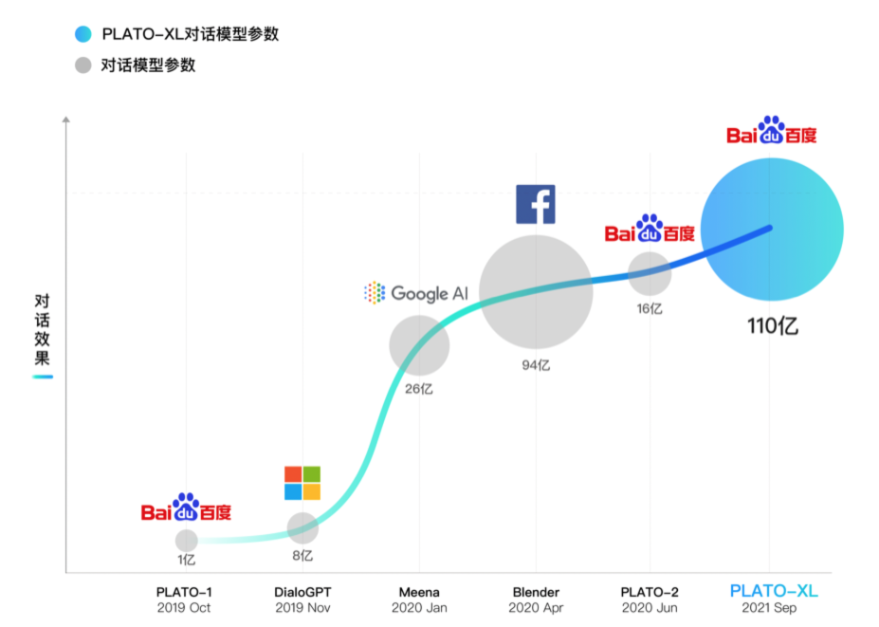
尽管大规模参数的模型在自然语言处理领域如雨后春笋出现,并且在多个自然语言理解和生成任务上取得了很多成果,但多轮开放域对话的主动性和常识性问题一直无法很好解决。百度NLP于2019年10月预发布了通用领域的对话生成预训练模型PLATO,在ACL 2020正式展示。2020年升级为超大规模模型PLATO-2,参数规模扩大到16亿,涵盖中英文版本,可就开放域话题深度畅聊。如今,百度全新发布PLATO-XL,参数规模首次突破百亿达到110亿,是当前最大规模的中英文对话生成模型。
论文名称:
PLATO-XL:Exploring the Large-scale Pre-training of Dialogue Generation
论文地址:
https://arxiv.org/abs/2109.09519
PLATO-XL,全球首个百亿参数对话预训练生成模型
让机器进行像人一样有逻辑、有知识、有情感的对话,一直是人机智能交互的重要技术挑战;另一方面,开放域对话能力是实现机器人情感陪伴、智能陪护、智能助理的核心,被寄予了很高的期望。
预训练技术大幅提升了模型对大规模无标注数据的学习能力,如何更高效、充分的利用大规模数据提升开放域对话能力,成为主流的研究方向。
从谷歌Meena、Facebook Blender到百度PLATO,开放域对话效果不断提升。在全球对话技术顶级比赛DSTC-9上,百度PLATO-2创造了一个基础模型取得5项不同对话任务第一的历史性成绩。
如今,百度发布PLATO-XL,参数达到了110亿,超过之前最大的对话模型Blender(最高94亿参数),是当前最大规模的中英文对话生成模型,并再次刷新了开放域对话效果。
百度PLATO一直有其独特的从数据到模型结构到训练方式上的创新。PLATO-1, PLATO-2不仅刷新了开放域对话效果,也具有非常好的参数性价比,即在同等参数规模下效果超越其他模型。PLATO-XL在参数规模达到新高的同时,其对话效果也不出意外地再次达到新高。下面,我们将展开介绍PLATO-XL模型的核心技术特点。
PLATO-XL模型:更高参数性价比,大幅提升训练效果
PLATO-XL网络架构上承袭了PLATO unified transformer结构,可同时进行对话理解和回复生成的联合建模,参数性价比很高。通过灵活的注意力机制,模型对上文进行了双向编码,充分利用和理解上文信息;对回复进行了单向解码,适应回复生成的auto-regressive特性。此外,unified transformer结构在对话上训练效率很高,这是由于对话样本长短不一,训练过程中padding补齐会带来大量的无效计算,unified transformer可以对输入样本进行有效的排序,大幅提升训练效率。
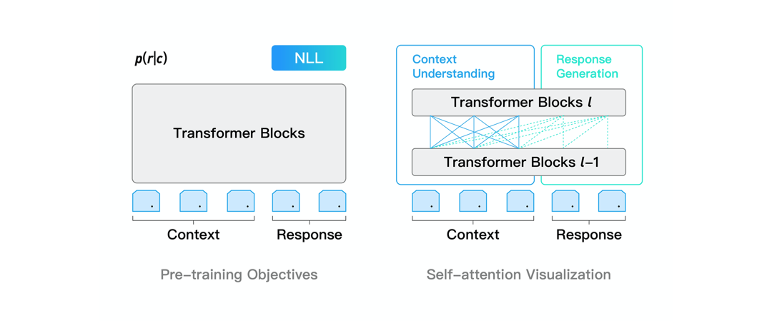
为了进一步改善对话模型有时候自相矛盾的问题,PLATO-XL引入了多角色感知的输入表示,以提升多轮对话上的一致性。对话模型所用的预训练语料大多是社交媒体对话,通常有多个用户参与,表述和交流一些观点和内容。在训练时,模型较难区分对话上文中不同角度的观点和信息,容易产生一些自相矛盾的回复。针对社交媒体对话多方参与的特点,PLATO-XL进行了多角色感知的预训练,对多轮对话中的各个角色进行清晰区分,辅助模型生成更加连贯、一致的回复。
PLATO-XL包括中英文2个对话模型,预训练语料规模达到千亿级token,模型规模高达110亿参数。PLATO-XL也是完全基于百度自主研发的飞桨深度学习平台,利用了飞桨FleetX库的并行能力,使用了包括 recompute、sharded data parallelism等策略,基于高性能GPU集群进行了训练。
PLATO-XL效果:多种类型、多种任务,对话效果全面领先
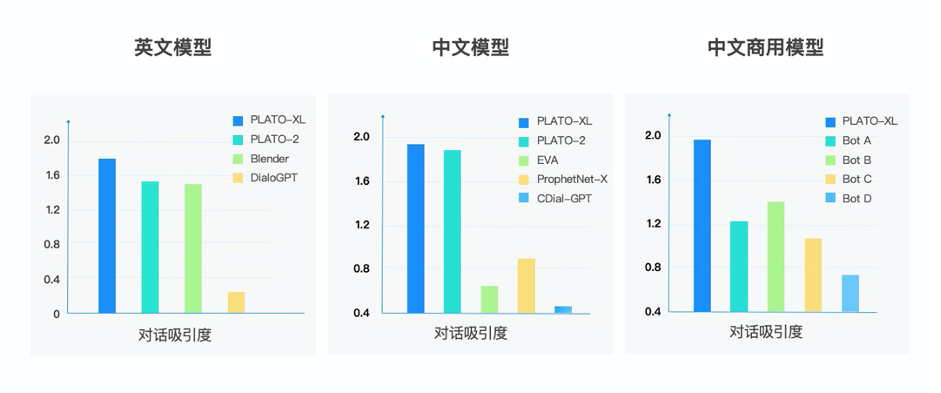
为了全面评估模型能力,PLATO-XL与当前开源的中英文对话模型进行了对比,评估中采用了两个模型针对开放域进行相互对话(self-chat)的形式,然后再通过人工来评估效果。PLATO-XL与Facebook Blender、微软DialoGPT、清华EVA模型相比,取得了更优异的效果,也进一步超越了之前PLATO-2取得的最好成绩。此外,PLATO-XL也显著超越了目前主流的商用聊天机器人。
除了开放域闲聊对话,模型也可以很好的支持知识型对话和任务型对话,在多种对话任务上效果全面领先。
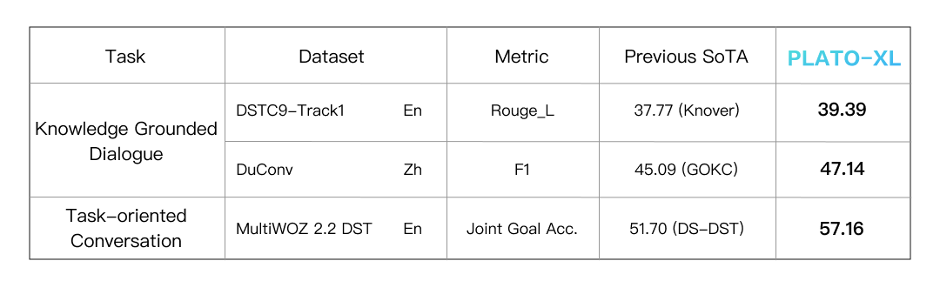
PLATO系列涵盖了不同规模的对话模型,参数规模从9300万到110亿。下图可以看出,模型规模扩大对于效果提升也有显著作用,呈现较稳定的正相关关系。
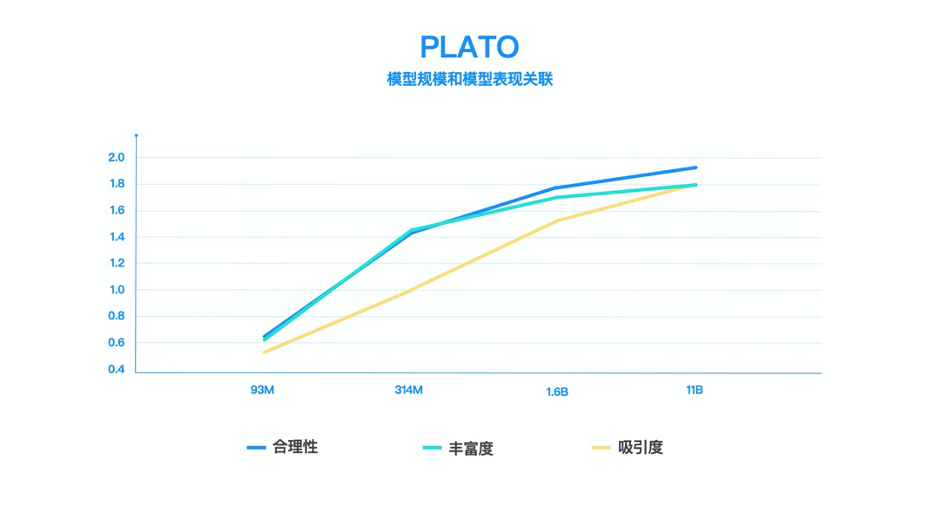
PLATO-XL不管是在英文,还是中文上的多轮对话,模型都可以与用户进行有逻辑、有内容且有趣的深入聊天。

百度PLATO-XL模型英文对话效果
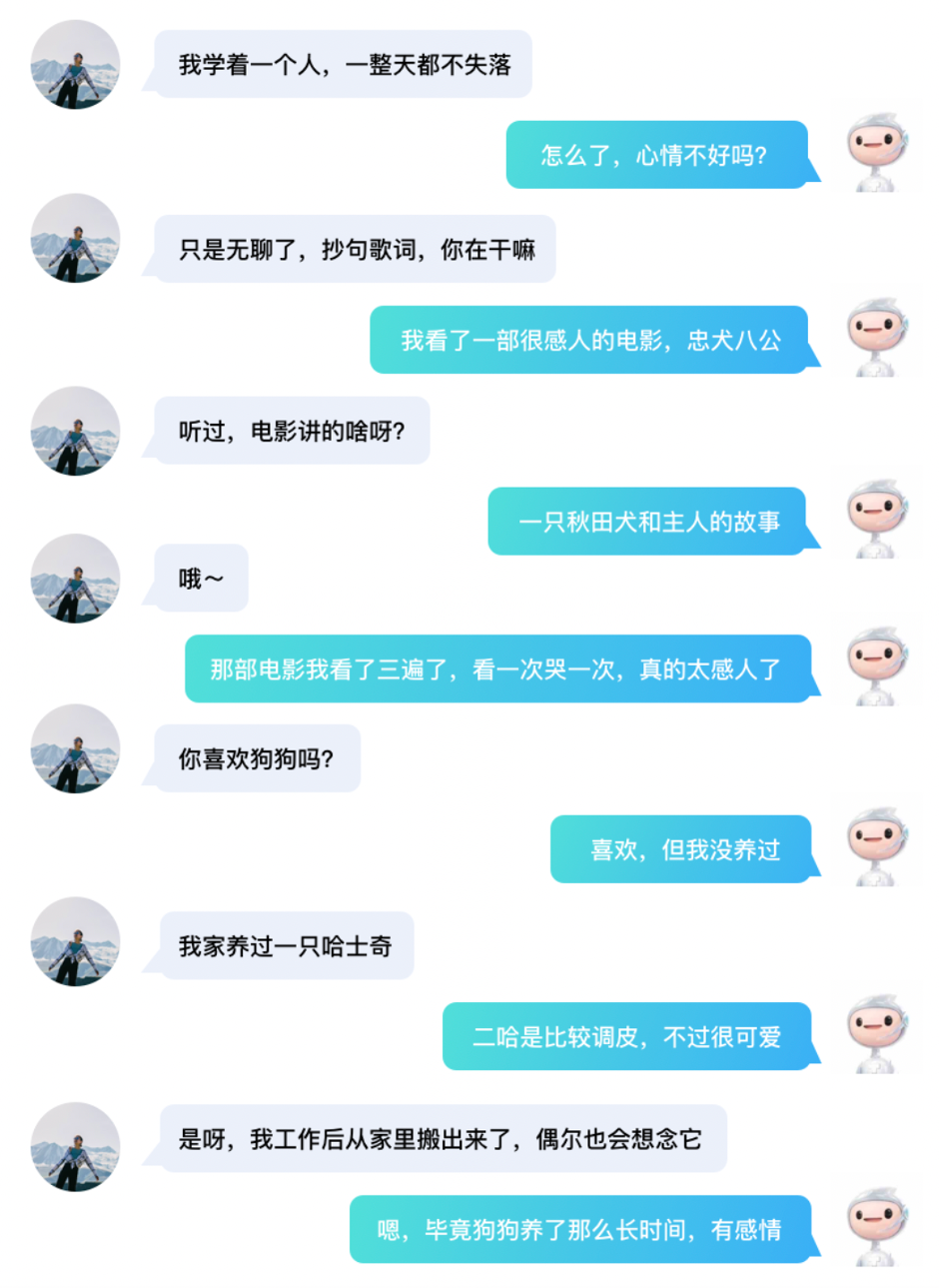
百度PLATO-XL模型中文对话效果
结语
让机器用自然语言与人自由地交流,是人工智能的终极目标之一。百度PLATO-XL的发布,是开放域对话在大模型上的一次深入探索。相信在不久的将来,更加强大的对话预训练模型将会陆续发布。未来,对话模型可以更加拟人、更有知识。
百度开放接口服务供大家体验最新中文PLATO百亿模型的效果,对智能对话感兴趣的小伙伴一定不能错过。
 关注公众号
关注公众号 低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。
持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
转载内容版权归作者及来源网站所有,本站原创内容转载请注明来源。
- 上一篇

云原生爱好者周刊:Antrea 1.3.0 发布;Envoy 项目开源 5 周年
云原生一周动态要闻: Crossplane 成为 CNCF 孵化项目 VMware Tanzu Kubernetes Grid 1.4 发布 Sqlcommenter 与 OpenTelemetry 合并 Antrea 1.3.0 发布 Envoy 项目开源 5 周年 开源项目推荐 文章推荐 云原生动态 Crossplane 成为 CNCF 孵化项目 CNCF 技术监督委员会(TOC)已经投票接受 Crossplane 作为 CNCF 的孵化项目。Crossplane 是一个开源的 Kubernetes 附加组件,使现代组织能够通过一个开放的、社区驱动的、基于标准的通用控制平面来使用基础设施。这种由 Kubernetes 社区最先提出的控制平面方法,正在改变平台团队如何自动化基础设施,并通过自助服务供应使开发人员能够更快地构建。 Crossplane 是由 Upbound 的一个团队在 2018 年底创建并开源的。2020 年 6 月,它被纳入 CNCF 沙箱。 详情见 VMware Tanzu Kubernetes Grid 1.4 发布 VMware Tanzu Kubernete...
- 下一篇
OpenKruise v0.10.0 新特性 WorkloadSpread 解读
1.背景 Workload 分布在不同 zone,不同的硬件类型,甚至是不同的集群和云厂商已经是一个非常普遍的需求。过去一般只能将一个应用拆分为多个 workload(比如 Deployment)来部署,由 SRE 团队手工管理或者对 PaaS 层深度定制,来支持对一个应用多个 workload 的精细化管理。 进一步来说,在应用部署的场景下有着多种多样的拓扑打散以及弹性的诉求。其中最常见就是按某种或多种拓扑维度打散,比如: 应用部署需要按 node 维度打散,避免堆叠(提高容灾能力)。 应用部署需要按 AZ(available zone)维度打散(提高容灾能力)。 按 zone 打散时,需要指定在不同 zone 中部署的比例数。 随着云原生在国内外的迅速普及落地,应用对于弹性的需求也越来越多。各公有云厂商陆续推出了 Serverless 容器服务来支撑弹性部署场景,如阿里云的弹性容器服务 ECI,AWS 的 Fragate 容器服务等。以 ECI 为例,ECI 可以通过Virtual Kubelet对接 Kubernetes 系统,给予 Pod 一定的配置就可以调度到 virtual...
相关文章
文章评论
共有0条评论来说两句吧...
文章二维码
点击排行

推荐阅读






最新文章
- CentOS关闭SELinux安全模块
- CentOS8安装Docker,最新的服务器搭配容器使用
- SpringBoot2编写第一个Controller,响应你的http请求并返回结果
- Hadoop3单机部署,实现最简伪集群
- SpringBoot2初体验,简单认识spring boot2并且搭建基础工程
- Linux系统CentOS6、CentOS7手动修改IP地址
- Eclipse初始化配置,告别卡顿、闪退、编译时间过长
- Springboot2将连接池hikari替换为druid,体验最强大的数据库连接池
- Windows10,CentOS7,CentOS8安装Nodejs环境
- 设置Eclipse缩进为4个空格,增强代码规范
 微信收款码
微信收款码 支付宝收款码
支付宝收款码