听说微信搜索《Java鱼仔》会变更强哦!
本文收录于JavaStarter,里面有我完整的Java系列文章,学习或面试都可以看看哦
(一)概述
很多人会把Java内存区域(运行时数据区)和Java内存模型(JMM)搞混,这两者是完全不一样的东西。
Java内存区域是指JVM运行时数据分区域存储,而Java内存模型是定义了线程和主内存之间的抽象关系,了解Java内存模型是学好Java并发编程的基础。
(二)Java内存模型
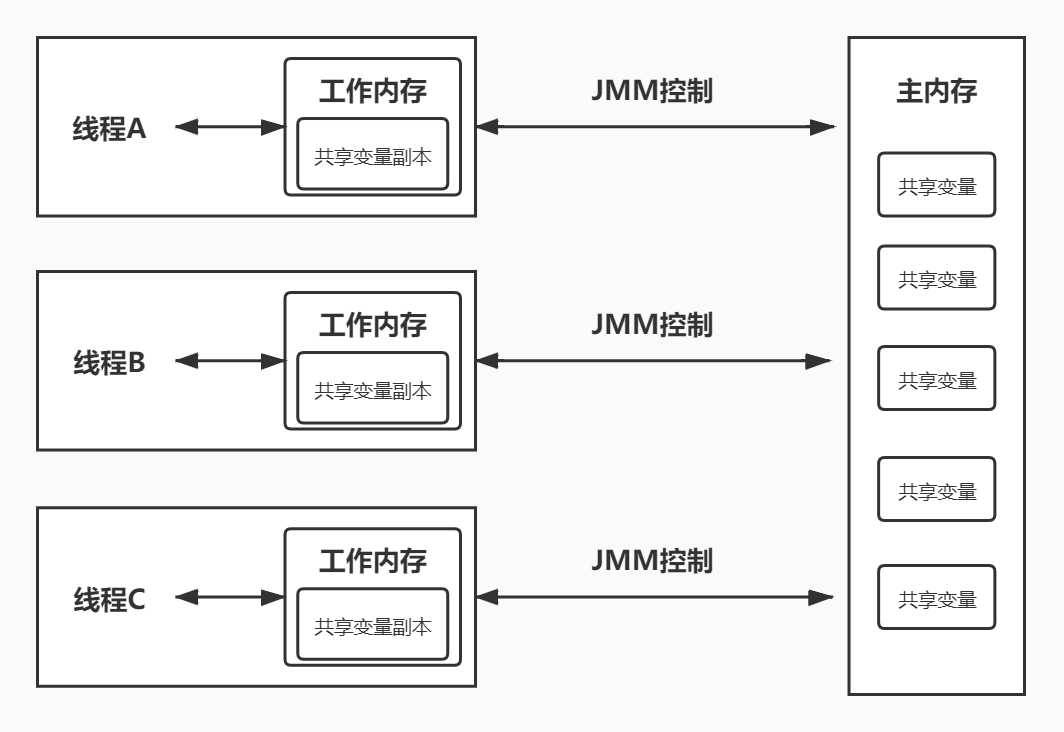
Java内存模型中规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存中的变量。我们来看一张图:
![在这里插入图片描述]()
每个线程拥有一个自己的私有工作内存,需要变量时从主内存中拷贝一份到工作内存,如果更新过变量之后再将共享变量刷新到主内存。
但是两个线程之间,是没有办法读取对方工作内存中的变量值的。看一个例子:
public class Test {
private static boolean flag=false;
public static void main(String[] args) throws InterruptedException {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("waiting");
while (!flag){}
System.out.println("in");
}
}).start();
Thread.sleep(2000);
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("change flag");
flag=true;
System.out.println("change success");
}
}).start();
}
}
首先定义了一个静态变量flag为false,A线程等待flag等于true后输出in,于是我们新开一个线程将flag修改为true。结果是A线程依旧无法输出in。
![在这里插入图片描述]()
原理看Java内存模型的图就理解了,不同的线程修改变量,对本地线程是不可见的。
(三)JMM数据的原子操作
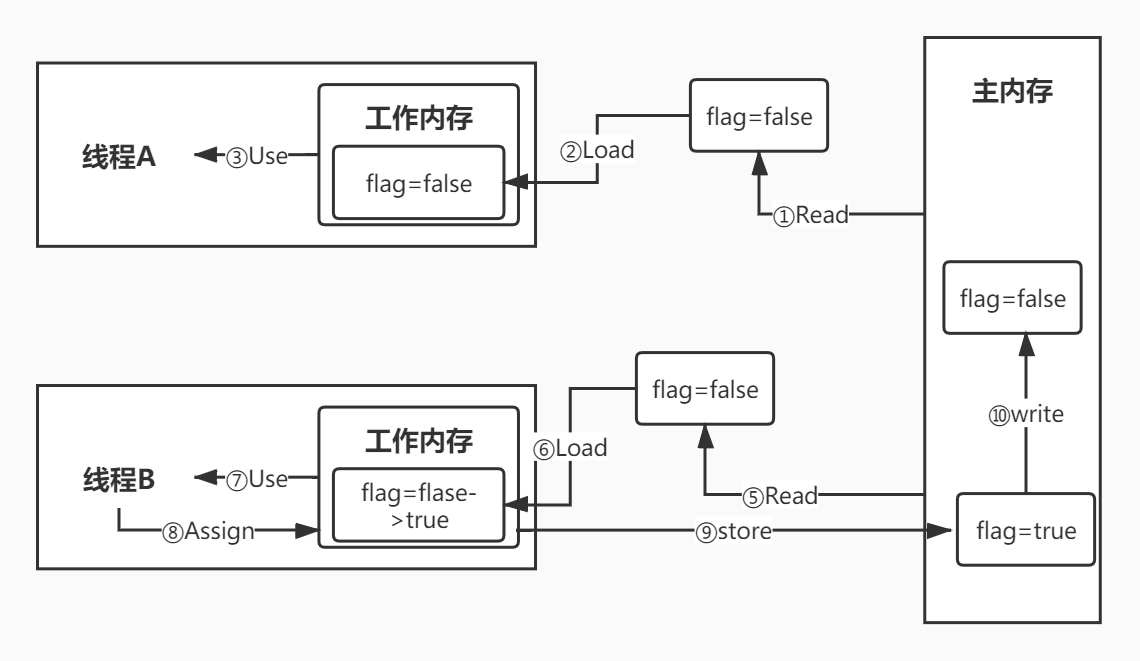
通过上面这段代码,我们已经知道了Java内存模型的结构,那么工作内存和主内存之间是如何读取变量又是如何修改变量的呢?JMM提供了对变量的一系列原子操作。我们先不讲理论,看个图,这个图描述了上面一段代码的执行过程:
![在这里插入图片描述]()
整个过程一共十步,重复几个步骤不讲了,我把不重复的六个操作列一下:
read:从主内存读取数据
load:将主内存读取到的数据写入工作内存
use :从工作内存中读取数据来使用
assign:把计算好的值重新赋值到工作内存中
store:将工作内存数据写入主内存
write:将store过去的变量赋值给主内存中的变量
通过上面的图,对下面六个原子操作的理解应该可以更加深刻了。JMM的原子操作一共有八个,下面列出剩下的两个
lock:将主内存变量加锁,标识为线程独占状态
unlock:将主内存变量解锁,解锁后其他线程可以锁定该变量
(四)JMM缓存不一致问题
从前面的例子我们已经看到了,一个线程修改完数据,另外一个线程无法立即可见,这就是JMM缓存不一致的问题,有两种解决办法:
加锁:
还记得我们没有用到过的JMM原操作的最后两个吗,lock和unlock,使用这两个操作就可以实现缓存一致性,一个线程想要获取某个主内存变量时,先使用lock将主内存变量加锁,只有他才能使用,等用完后再unlock,其他线程才能竞争。但是加锁意味着性能低。
MESI缓存一致性协议:
这个协议涉及到cpu的总线嗅探机制,从上面的JMM执行的流程图中我们可以看到当某个线程修改了共享变量后,他会回写到主内存,MESI缓存一致性协议就是通过cpu的总线嗅探机制,将其他也正在使用该变量的线程的数据失效掉,使得这些线程要重新读取主内存中的值,从而保证缓存最终一致性。(volatile的实现原理)
(五)总结
Java内存模型在多并发中十分重要,包括后面学习volatile或者synchronized这个关键字的时候,都会回到这个Java内存模型中。