❝
论文:IterDet: Iterative Scheme for ObjectDetection in Crowded Environments https://github.com/saic-vul/iterdet
❞
2020年5月莫斯科三星AI研究院提出的文章,针对密集目标进行检测,密集目标检测的难点在于既要检测出不同的目标,又要抑制重复目标框的产生。作者提出了一种「迭代检测」 的方案,不论单步检测器还是多步检测器,只需要在训练和推理上做很少的修改,就能简单高效地检测出密集目标。
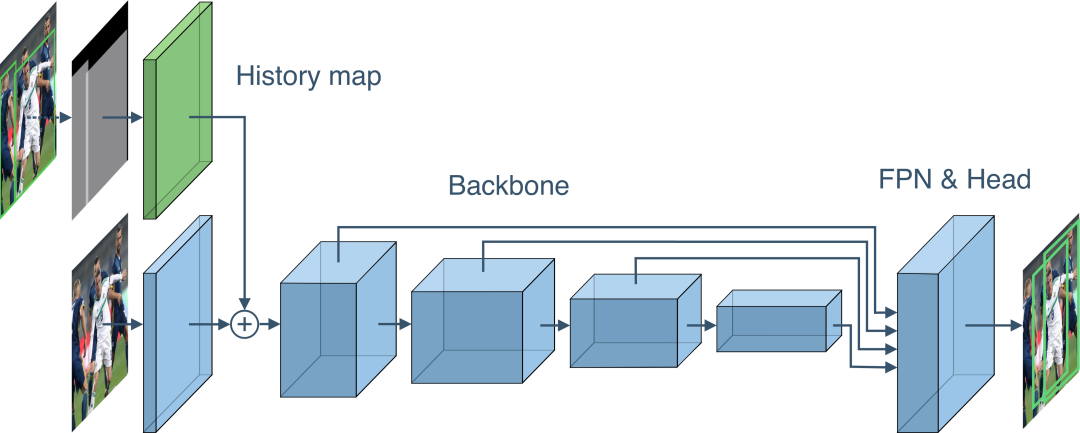
迭代检测,不用保证每次迭代的召回率,早期,检测部分目标子集,后期将检测的结果和图像再一次输入网络,使检出的目标不再被检测到,迭代检测出复杂的目标子集。
,输入图像:
,history map
为空,检测器
将输入
和
映射为一系列边框
。
「 history map 映射方式」 :每个像素点的目标个数。
,输入图像:
,history map
由
映射而得,检测器
将输入
和
映射为一系列边框
;
结束标志:以此类推,直到达到迭代次数或当前迭代未检测到新目标,即
时,结束迭代。
那么最后的检测结果就是每次迭代检测出的目标的全集,即:
要想实现上述方案,有两点必须解决:1)如何将一个检测器
转换为对历史检测敏感的新检测器
;2)如何让新检测器
在不同的迭代下检测出不同的目标子集。
随机地将标注目标框分为:
和
两个集合,且
,将
制作为history map
,使得模型训练来利用已有的目标框
信息,预测缺失的目标框集合
,同时,通过不同随机划分
和
,还可以达到了数据增强的效果。
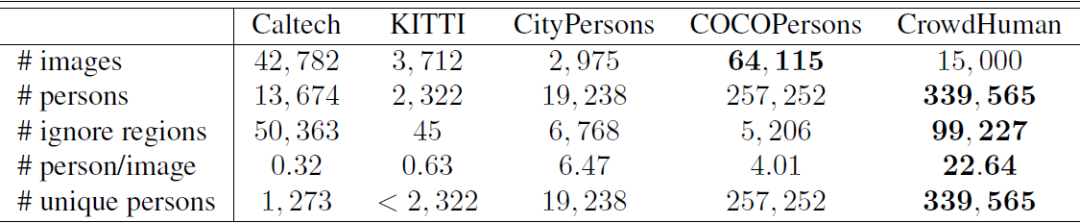
AdaptIS:包含两个子集Toy V1和Toy V2,用于实力分割任务而生成的数据集,现有标注可以使其用于目标检测,且每张图片平均有30个目标,大部分有重叠情况,绝对是一个密集目标检测的数据集。「Toy V1」 :训练集、验证集分别有2000和10000张图像,大小为:96×96。「Toy V2」 :训练集、验证集和测试集分别有25000, 1000和1000张,图片大小为128×128。
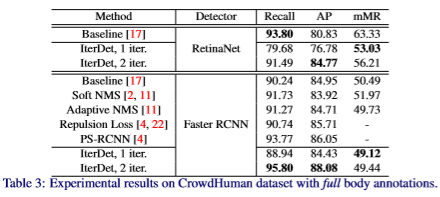
「CrowdHuman」 :训练集、验证集和测试集分别有15000, 4370和5000张图片,平均每张图的人物数量达到了22.64个,远大于其他主流的人体检测数据集,其中,每个目标有三个标注框:full body, visible body 和 head。官网:www.crowdhuman.org
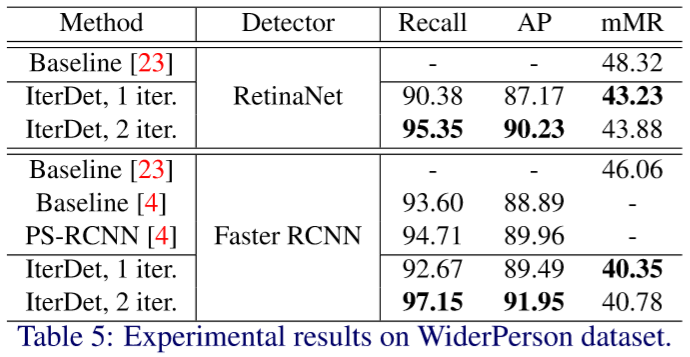
「WiderPerson」 :训练集、验证集和测试集分别有8000,1000和4382张图片,共5个类别:pedestrians, riders, partially visible persons, crowd 和 ignored regions。作者在训练和测试时,将后四类合并为了一类。www.cbsr.ia.ac.cn/users/sfzhang/WiderPerson
采用香港中文大学-商汤科技联合实验室开源的基于Pytorch实现的深度学习目标检测工具箱mmdetection,仓库地址:https://github.com/open-mmlab/mmdetection
此外,作者修改了两个个地方:1)FPN中每个卷积层之后添加了Batch Normalization;2)未冻结ResNet的第一个block,因为在这个block之前添加了历史映射和可训练的卷积层。
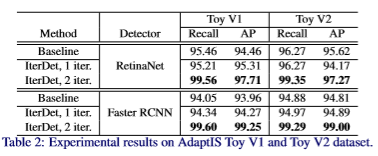
实验指标与结果如下:
今年5月,2020 CrowdHuman人体检测大赛启动上线,本届比赛是CrowdHuman人体检测赛的第二期,数据集应该就是论文中的CrowdHuman数据集。官方基于上述论文方法公布了baseline,具体可见:【Ranking第7名,2020 CrowdHuman大赛Baseline发布 】
git地址:https://github.com/thuwyh/BAAI-2020-CrowdHuman-Baseline





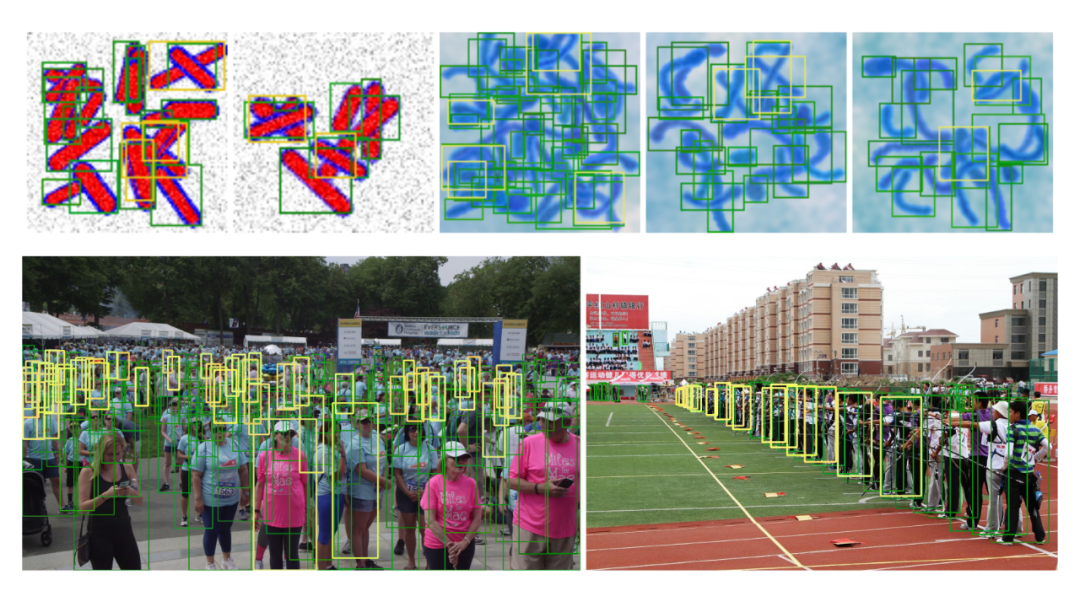
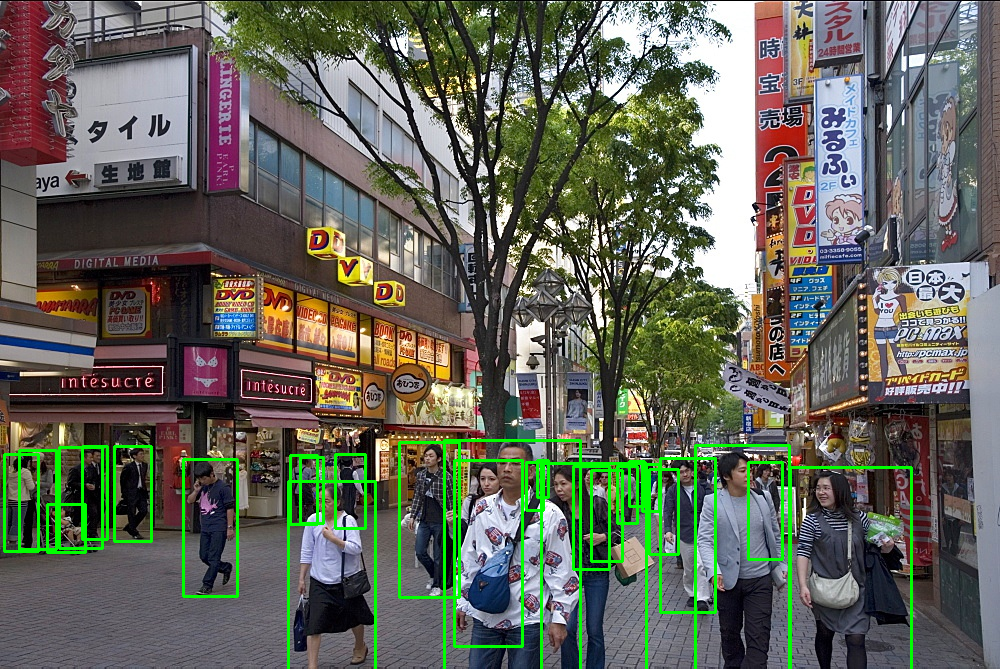
 一些检测结果:
一些检测结果: