页框分配器在慢速分配中包括内存碎片化整理和内存回收,代码如下:
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
page = __alloc_pages_direct_compact(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
......
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
......
}
出于篇幅设计,这次我们只讲内存的碎片化整理,下文再讲内存回收。
什么是内存碎片化
Linux物理内存碎片化包括两种:内部碎片化和外部碎片化。
内部碎片化:
指分配给用户的内存空间中未被使用的部分。例如进程需要使用3K bytes物理内存,于是向系统申请了大小等于3Kbytes的内存,但是由于Linux内核伙伴系统算法最小颗粒是4K bytes,所以分配的是4Kbytes内存,那么其中1K bytes未被使用的内存就是内存内碎片。
外部碎片化:
指系统中无法利用的小内存块。例如系统剩余内存为16K bytes,但是这16K bytes内存是由4个4K bytes的页面组成,即16K内存物理页帧号#1不连续。在系统剩余16K bytes内存的情况下,系统却无法成功分配大于4K的连续物理内存,该情况就是内存外碎片导致。
碎片化整理算法
Linux内存对碎片化的整理算法主要应用了内核的页面迁移机制,是一种将可移动页面进行迁移后腾出连续物理内存的方法。
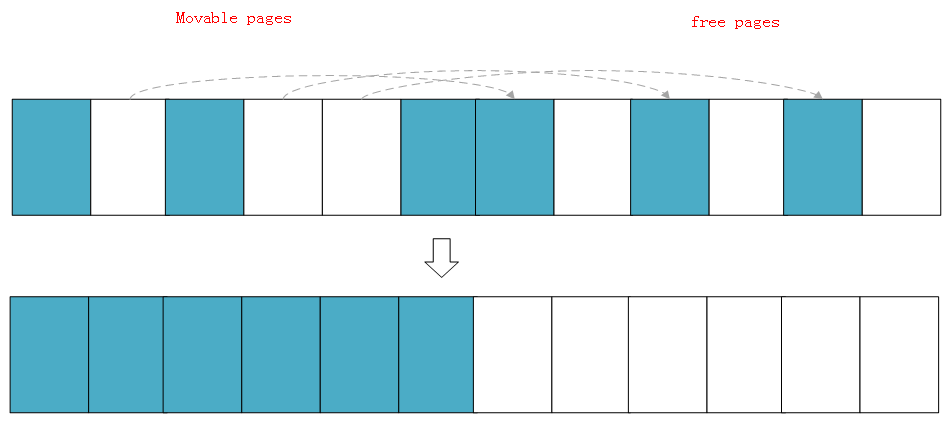
假设存在一个非常小的内存域如下:![]() 蓝色表示空闲的页面,白色表示已经被分配的页面,可以看到如上内存域的空闲页面(蓝色)非常零散,无法分配大于两页的连续物理内存。
蓝色表示空闲的页面,白色表示已经被分配的页面,可以看到如上内存域的空闲页面(蓝色)非常零散,无法分配大于两页的连续物理内存。
下面演示一下内存规整的简化工作原理,内核会运行两个独立的扫描动作:第一个扫描从内存域的底部开始,一边扫描一边将已分配的可移动(MOVABLE)页面记录到一个列表中:![]() 另外第二扫描是从内存域的顶部开始,扫描可以作为页面迁移目标的空闲页面位置,然后也记录到一个列表里面:
另外第二扫描是从内存域的顶部开始,扫描可以作为页面迁移目标的空闲页面位置,然后也记录到一个列表里面:![]() 等两个扫描在域中间相遇,意味着扫描结束,然后将左边扫描得到的已分配的页面迁移到右边空闲的页面中,左边就形成了一段连续的物理内存,完成页面规整。
等两个扫描在域中间相遇,意味着扫描结束,然后将左边扫描得到的已分配的页面迁移到右边空闲的页面中,左边就形成了一段连续的物理内存,完成页面规整。![]()
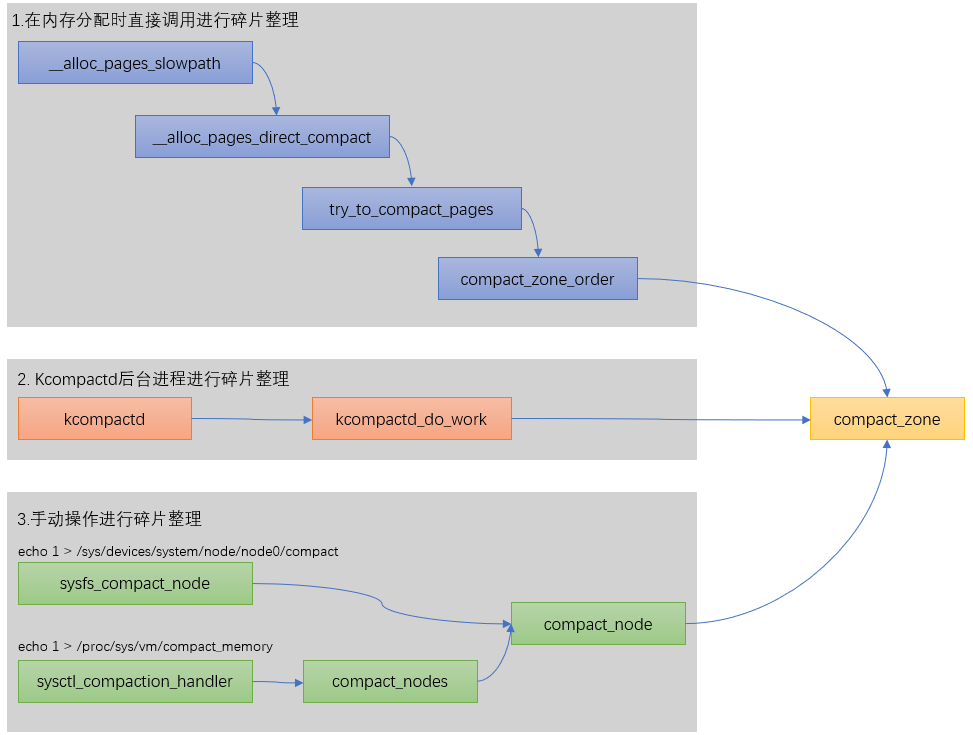
碎片化整理的三种方式
static struct page *
__alloc_pages_direct_compact(gfp_t gfp_mask, unsigned int order,
unsigned int alloc_flags, const struct alloc_context *ac,
enum compact_priority prio, enum compact_result *compact_result)
{
struct page *page;
unsigned int noreclaim_flag;
if (!order)
return NULL;
noreclaim_flag = memalloc_noreclaim_save();
*compact_result = try_to_compact_pages(gfp_mask, order, alloc_flags, ac,
prio);
memalloc_noreclaim_restore(noreclaim_flag);
if (*compact_result <= COMPACT_INACTIVE)
return NULL;
count_vm_event(COMPACTSTALL);
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page) {
struct zone *zone = page_zone(page);
zone->compact_blockskip_flush = false;
compaction_defer_reset(zone, order, true);
count_vm_event(COMPACTSUCCESS);
return page;
}
count_vm_event(COMPACTFAIL);
cond_resched();
return NULL;
}
这也是上面memory compaction算法的代码实现。
在linux内核里一共有3种方式可以碎片化整理,我们总结如下:![]()
这里就不展开源码的解析了,有了宏观的理解然后再去网上搜下具体实现细节相信不是什么难事,OK,我们进入下面的文章内容:内存回收(memory reclaim)。
![]()
 蓝色表示空闲的页面,白色表示已经被分配的页面,可以看到如上内存域的空闲页面(蓝色)非常零散,无法分配大于两页的连续物理内存。
蓝色表示空闲的页面,白色表示已经被分配的页面,可以看到如上内存域的空闲页面(蓝色)非常零散,无法分配大于两页的连续物理内存。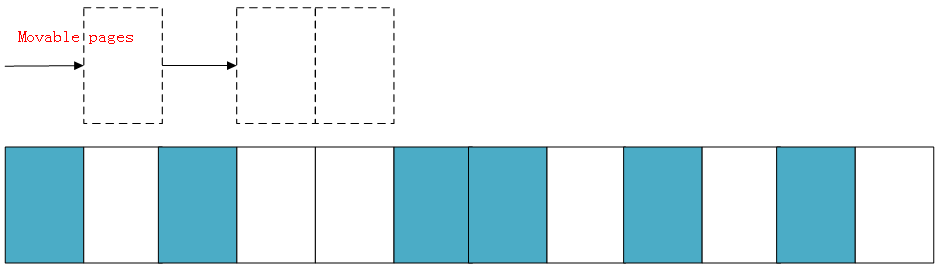 另外第二扫描是从内存域的顶部开始,扫描可以作为页面迁移目标的空闲页面位置,然后也记录到一个列表里面:
另外第二扫描是从内存域的顶部开始,扫描可以作为页面迁移目标的空闲页面位置,然后也记录到一个列表里面: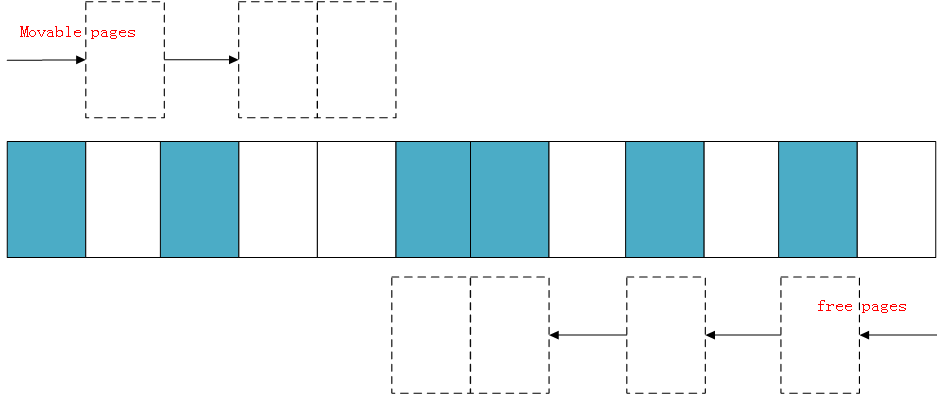 等两个扫描在域中间相遇,意味着扫描结束,然后将左边扫描得到的已分配的页面迁移到右边空闲的页面中,左边就形成了一段连续的物理内存,完成页面规整。
等两个扫描在域中间相遇,意味着扫描结束,然后将左边扫描得到的已分配的页面迁移到右边空闲的页面中,左边就形成了一段连续的物理内存,完成页面规整。