用C语言撸了个DBProxy
前言
笔者在阅读了一大堆源码后,就会情不自禁产生造轮子的想法。于是花了数个周末的时间用C语言撸了一个DBProxy(MySQL协议)。在笔者的github中给这个DBProxy起名为Hero。
为什么采用C语言
笔者一直有C情节,求学时候一直玩C。工作之后,一直使用Java,就把C渐渐放下了。在笔者最近一年阅读了一堆关于linux Kernel(C)和MySQL(C++)的源码后,就萌生了重拾C的想法。同时用纯C的话,势必要从基础开始造一大堆轮子,这也符合笔者当时造轮子的心境。
造了哪些轮子
习惯了Java的各种好用的类库框架之后,用纯C无疑就是找虐。不过,既然做了这个决定,跪着也得搞完。在写Hero的过程中。很大一部分时间就是在搭建基础工具,例如:
Reactor模型
内存池
packet_buffer
协议分包处理
连接池
......
下面在这篇博客里面一一道来
DBProxy的整体原理
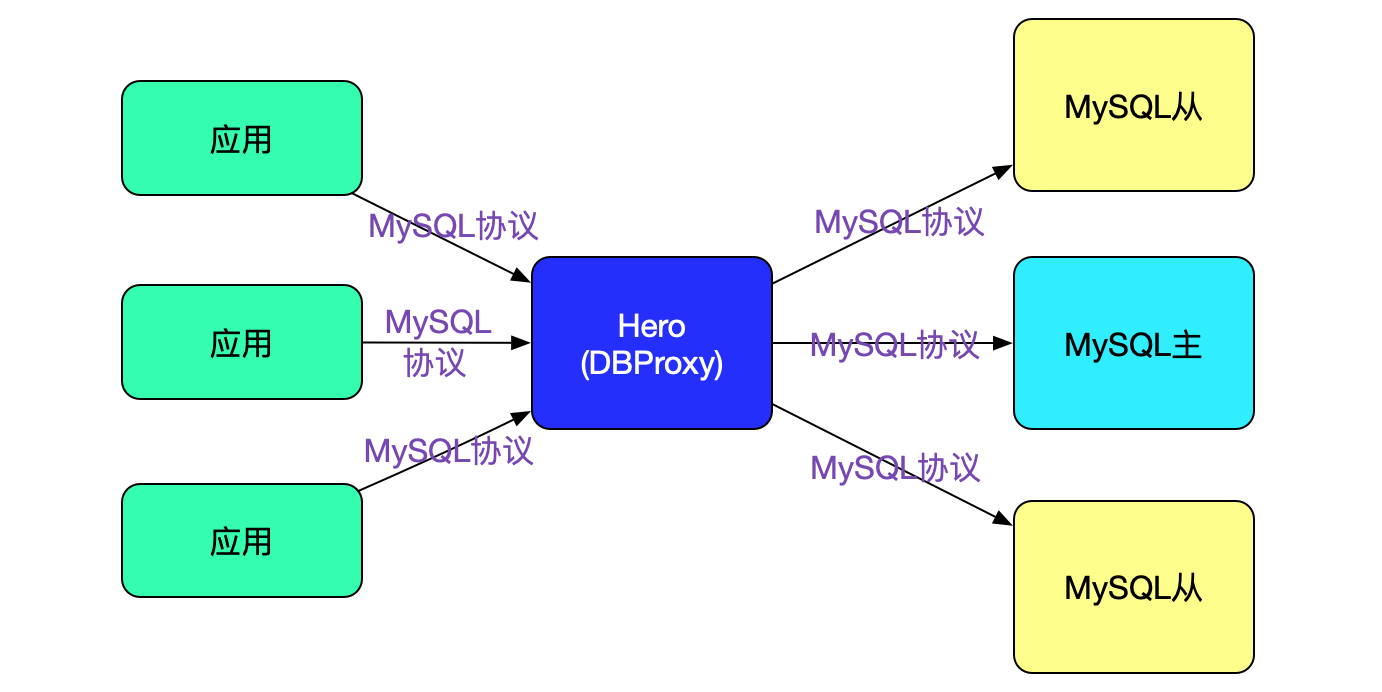
Hero(DBProxy)其实就是自己伪装成MySQL,接收到应用发过来的SQL命令后,再转发到后端。如下图所示: ![]()
由于Hero在解析SQL的时候,可以获取各种信息,例如事务这个信息就可以通过set auto_commit和begin等命令存在连接状态里面,再根据解析出来的SQL判断其是否需要走主库。这样就可以对应用透明的进行主从分离以至于分库分表等操作。
当然了,笔者现在的Hero刚把基础的功能搭建好(协议、连接池等),对连接状态还没有做进一步的处理。
Reactor模式
Hero的网络模型采用了Reactor模式,而且是多线程模型,同时采用epoll的水平触发。
采用多线程模型
为什么采用多线程,纯粹是为了编写代码简单。多进程的话,还得考虑worker进程间负载均衡问题,例如nginx就在某个worker进程达到7/8最大连接数的时候拒绝获取连接从而转给其它worker。多线程的话,在accept线程里面通过取模选择一个worker线程就可以轻松的达到简单的负载均衡结果。
采用epoll水平触发
为什么采用epoll的水平触发,纯粹也是为了编写代码简单。如果采用边缘触发的话,需要循环读取直到read返回字节数为0为止。然而如果某个连接特别活跃,socket的数据一直读不完,会造成其它连接饥饿,所以必须还得自己写个均衡算法,在读到一定程度后,去选择其它连接。
Reactor
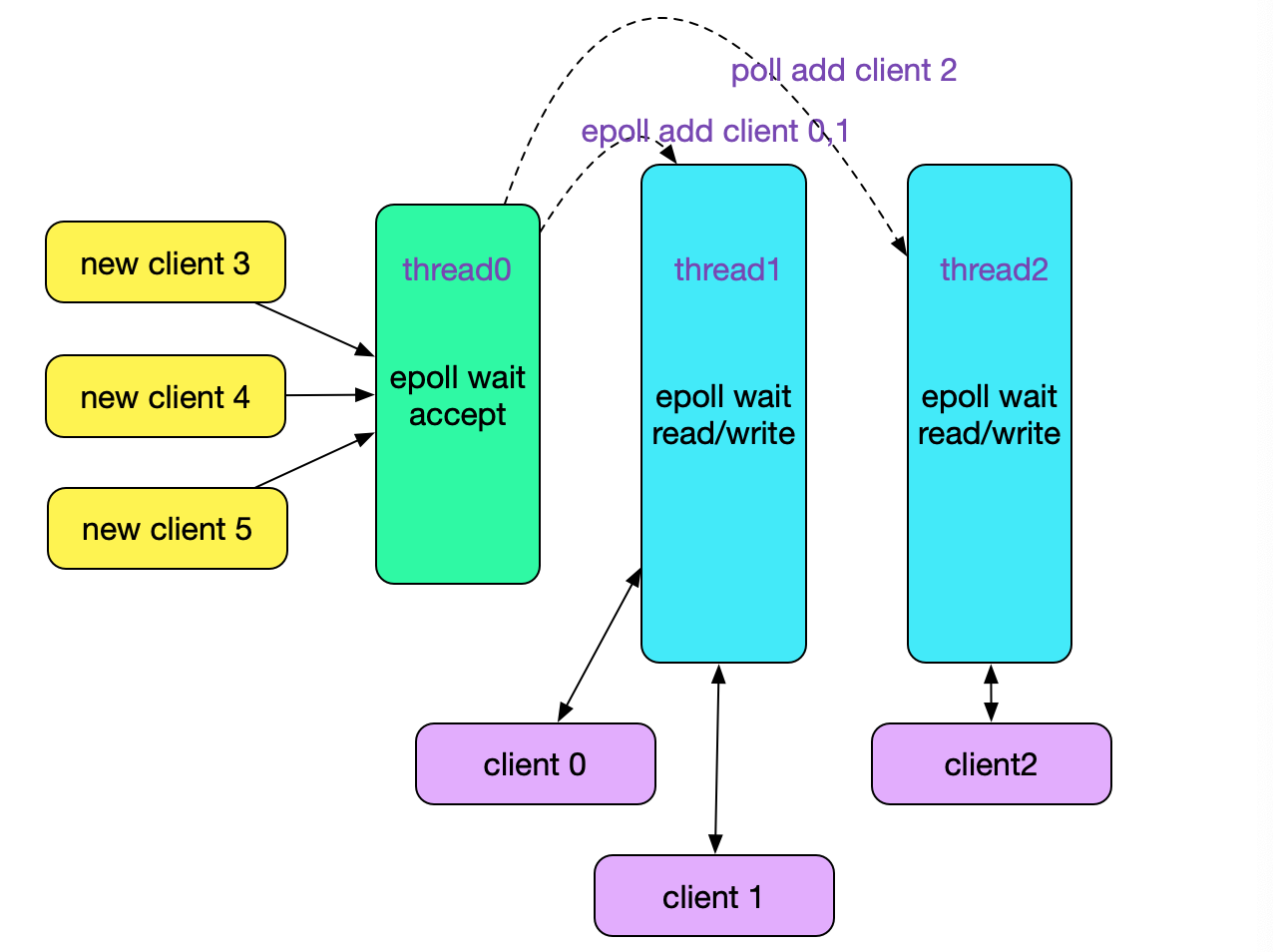
整体Reactor模型如下图所示:
![]()
其实代码是很简单的,如下面代码所示的就是reactor中的accept处理:
// 中间省略了大量的错误处理
int init_reactor(int listen_fd,int worker_count){
// 注意,这边需要是unsigned 防止出现负数
unsigned int current_worker = 0;
for(;;){
int numevents = 0;
int retval = epoll_wait(reactor->master_fd,reactor->events,EPOLL_MAX_EVENTS,500);
......
for(j=0; j < numevents; j++){
client_fd = accept(listen_fd, (struct sockaddr *) &client_addr, &client_len))
poll_add_event(reactor->worker_fd_arrays[current_worker++%reactor->worker_count],conn->sockfd,EPOLLOUT,conn)
......
}
}
上面代码中,每来一个新的连接current_worker都自增,这样取模后便可在连接层面上对worker线程进行负载均衡。 而worker线程则通过pthread去实现,如下面代码所示:
// 这里的worker_count根据调用get_nprocs得到的对应机器的CPU数量
// 注意,由于docker返回的是宿主机CPU数量,所以需要自行调整
for(int i=0;i<worker_count;i++){
reactor->worker_fd_arrays[i] = epoll_create(EPOLL_MAX_EVENTS);
if(reactor->worker_fd_arrays[i] == -1){
goto error_process;
}
// 通过pthread去创建worker线程
if(FALSE == create_and_start_rw_thread(reactor->worker_fd_arrays[i],pool)){
goto error_process;
}
}
而worker线程的处理也是按照标准的epoll水平触发去处理的:
static void* rw_thread_func(void* arg){
......
for(;;){
int numevents = 0;
int retval = epoll_wait(epfd,events,EPOLL_MAX_EVENTS,500);
......
for(j=0; j < numevents; j++){
if(event & EPOLLHUP){
// 处理断开事件
......
}else if(event & EPOLLERR){
// 处理错误事件
......
}
}else {
if(event & EPOLLIN){
handle_ready_read_connection(conn);
continue;
}
if(event & EPOLLOUT){
hanlde_ready_write_connection(conn);
continue;
}
}
}
......
}
内存池
为什么需要内存池
事实上,笔者在最开始编写的时候,是直接调用标准库里面的malloc的。但写着写着,就发现一些非常坑的问题。例如我要在一个请求里面malloc数十个结构,同时每次malloc都有失败的可能,那么我的代码可能写这样。
void do_something(){
void * a1 = (void*)malloc(sizeof(struct A));
if(a1 == NULL){
goto error_process;
}
......
void * a10 = (void*)malloc(sizeof(struct A));
if(a10 == NULL{
goto error_process;
}
error_process:
if(NULL != a1){
free(a1);
}
......
if(NULL != a10){
free(a10);
}
}
写着写着,笔者就感觉完全不可控制了。尤其是在各种条件分支加进去之后,可能本身aN这个变量都还没有被分配,那么就还不能用(NULL != aN),还得又一堆复杂的判断。 有了内存池之后,虽然依旧需要仔细判断内存池不够的情况,但至少free的时候,只需要把内存池整体给free掉即可,如下面代码所示:
void do_something(mem_pool* pool){
void * a1 = (void*)mem_pool_alloc(sizeof(struct A),pool);
if(a1 == NULL){
goto error_process;
}
......
void * a10 = (void*)mem_pool_alloc(sizeof(struct A),pool);
if(a10 == NULL{
goto error_process;
}
error_process:
// 直接一把全部释放
mem_pool_free(pool);
}
内存池的设计
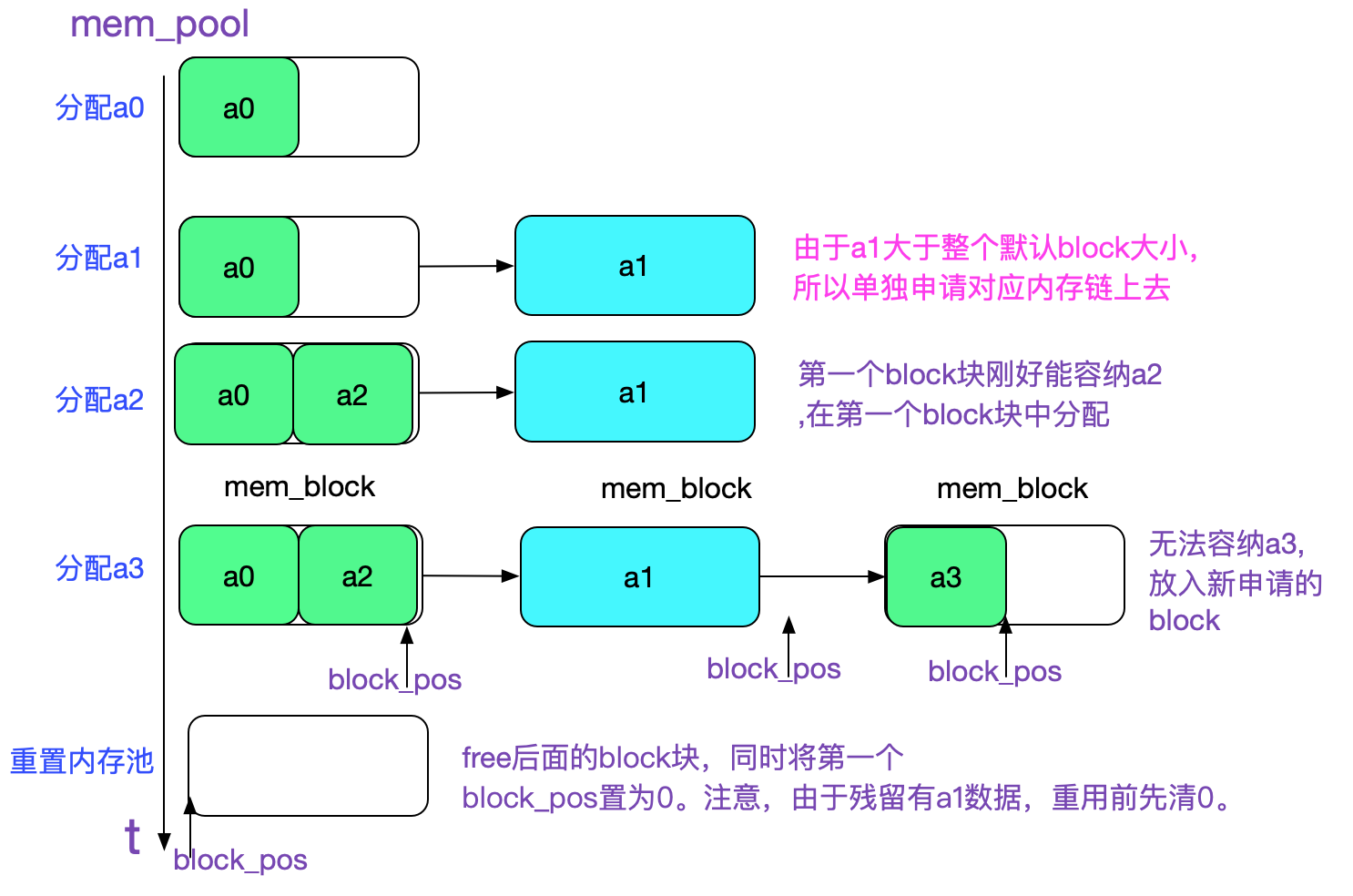
为了编写代码简单,笔者采用了比较简单的设计,如下图所示:
![]()
这种内存池的好处就在于分配很多小对象的时候,不必一一去清理,直接连整个内存池都重置即可。而且由于每次free的基本都是mem_block大小,所以产生的内存碎片也少。不足之处就在于,一些可以被立即销毁的对象只能在最后重置内存池的时候才销毁。但如果都是小对象的话,影响不大。
内存池的分配优化
考虑到内存对齐,每次申请内存的时候都按照sizeof(union hero_aligin)进行最小内存分配。这是那本采用<<c interface and implemention>>的推荐的对齐大小。
采用<<c interface and implemention>>的实现
union hero_align{
int i;
long l;
long *lp;
void *p;
void (*fp)(void);
float f;
double d;
long double ld;
};
真正的对齐则是参照nginx的写法:
size = (size + sizeof(union hero_align) - 1) & (~(sizeof(union hero_align) - 1));
其实笔者一开始还打算做一下类似linux kernel SLAB缓存中的随机着色机制,这样能够缓解false sharing问题,想想为了代码简单,还是算了。
为什么需要packet_buffer
packet_buffer是用来存储从socket fd中读取或写入的数据。 设计packet_buffer的初衷就是要重用内存,因为一个连接反复的去获取写入数据总归是需要内存的,只在连接初始化的时候去分配一次内存显然是比反复分配再销毁效率高。
为什么不直接用内存池
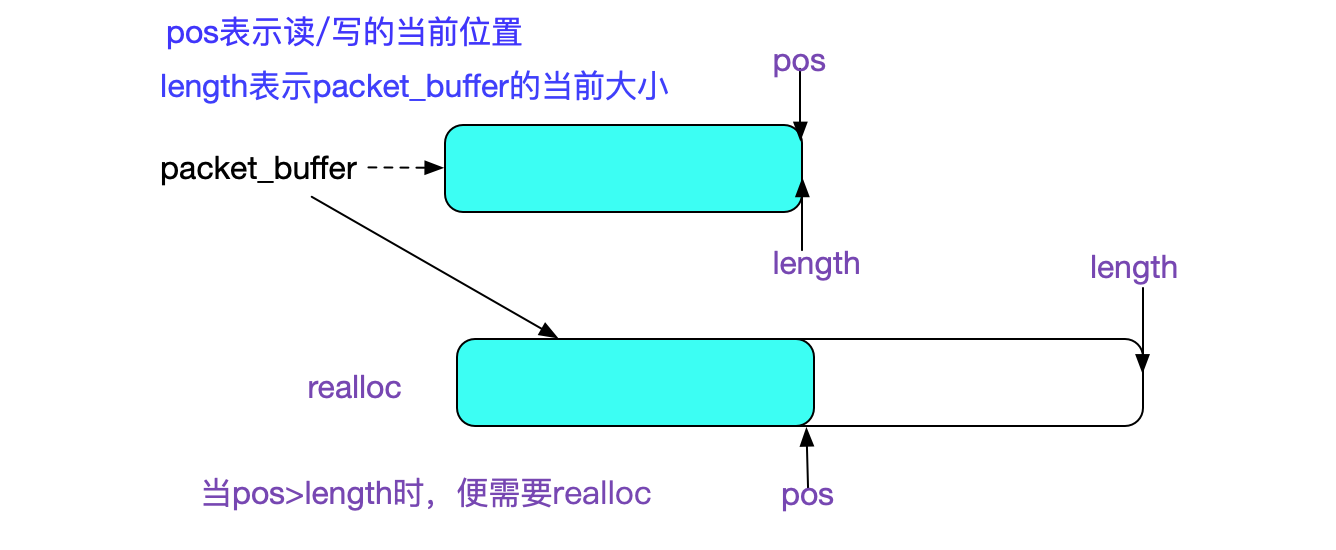
上文中说到,销毁内存必须将池里面的整个数据重置。如果packet_buffer和其它的数据结构在同一内存池中分配,要重用它,那么在packet_buffer之前分配的数据就不能被清理。如下图所示:
![]()
这样显然违背了笔者设计内存池是为了释放内存方便的初衷。
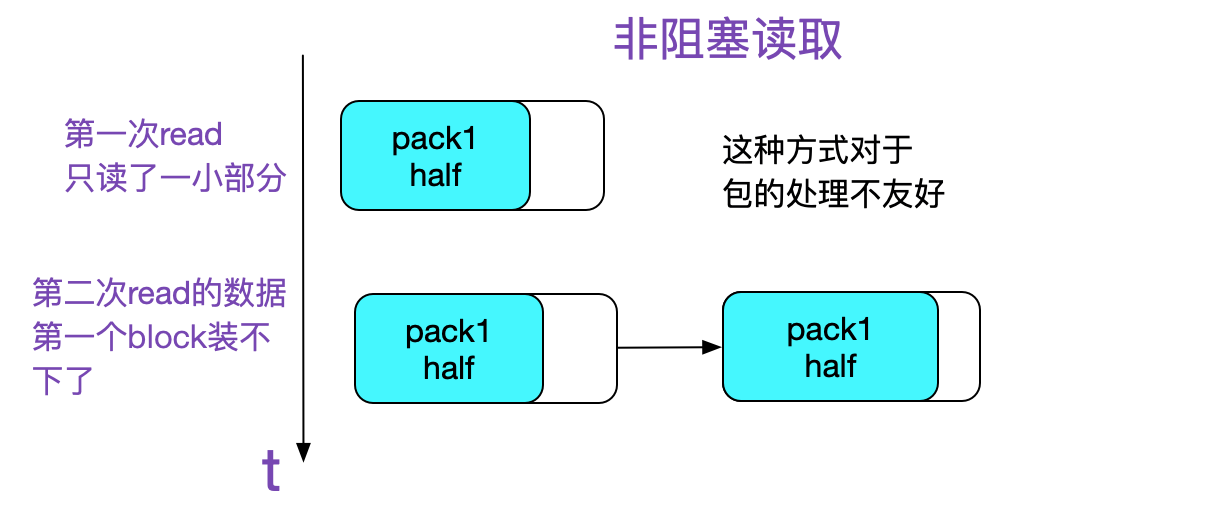
另外,如果使用内存池,那么从sockfd中读取/写入的数据就可能从连续的变成一个一个mem_block分离的数据,这种不连续性对数据包的处理会特别麻烦。如下图所示:
![]()
当然了,这种非连续的分配方式,笔者曾经在阅读lwip协议时见过(帮某实时操作系统处理一个诡异的bug),lwip在嵌入式这种内存稀缺的环境中使用这种方式从而尽量避免大内存的分配。 所以笔者采取了在连接建立时刻一次性分配一个比较大的内存来处理单个请求的数据,如果这个内存也满足不了,则realloc(当然了realloc也有坑,需要仔细编写)。
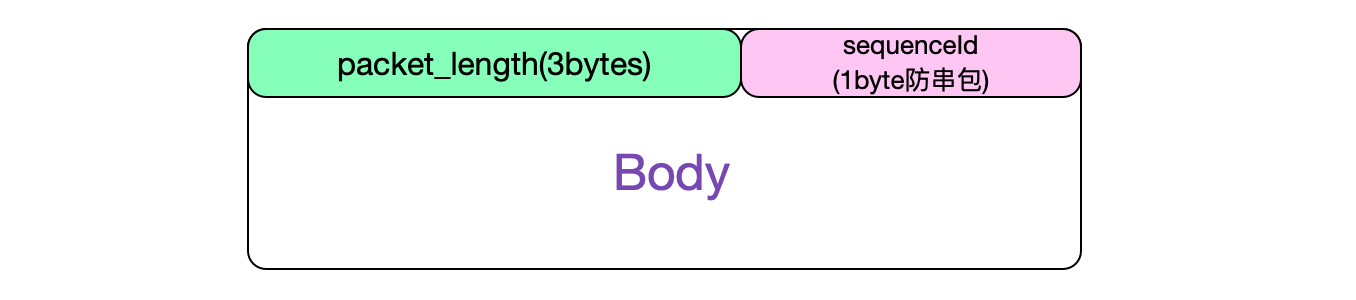
packet_buffer结构
![]()
packet_buffer这种动态改变大小而且地址上连续的结构为处理包结构提供了便利。
由于realloc的时候,packet_buffer->buffer本身指向的地址可能会变,所以尽量避免直接操作内部buffer,非得使用内部buffer的时候,不能将其赋予一个局部变量,否则buffer变化,局部变量可能指向了之前废弃的buffer。
MySQL协议分包处理
MySQL协议基于tcp(当然也有unix域协议,这里只考虑tcp)。同时Hero采用的是非阻塞IO模式,读取包时,recv系统调用可能在包的任意比特位置上返回。这时候,就需要仔细的处理分包。
MySQL协议外层格式
MySQL协议是通过在帧头部加上length field的设计来处理分包问题。如下图所示: ![]()
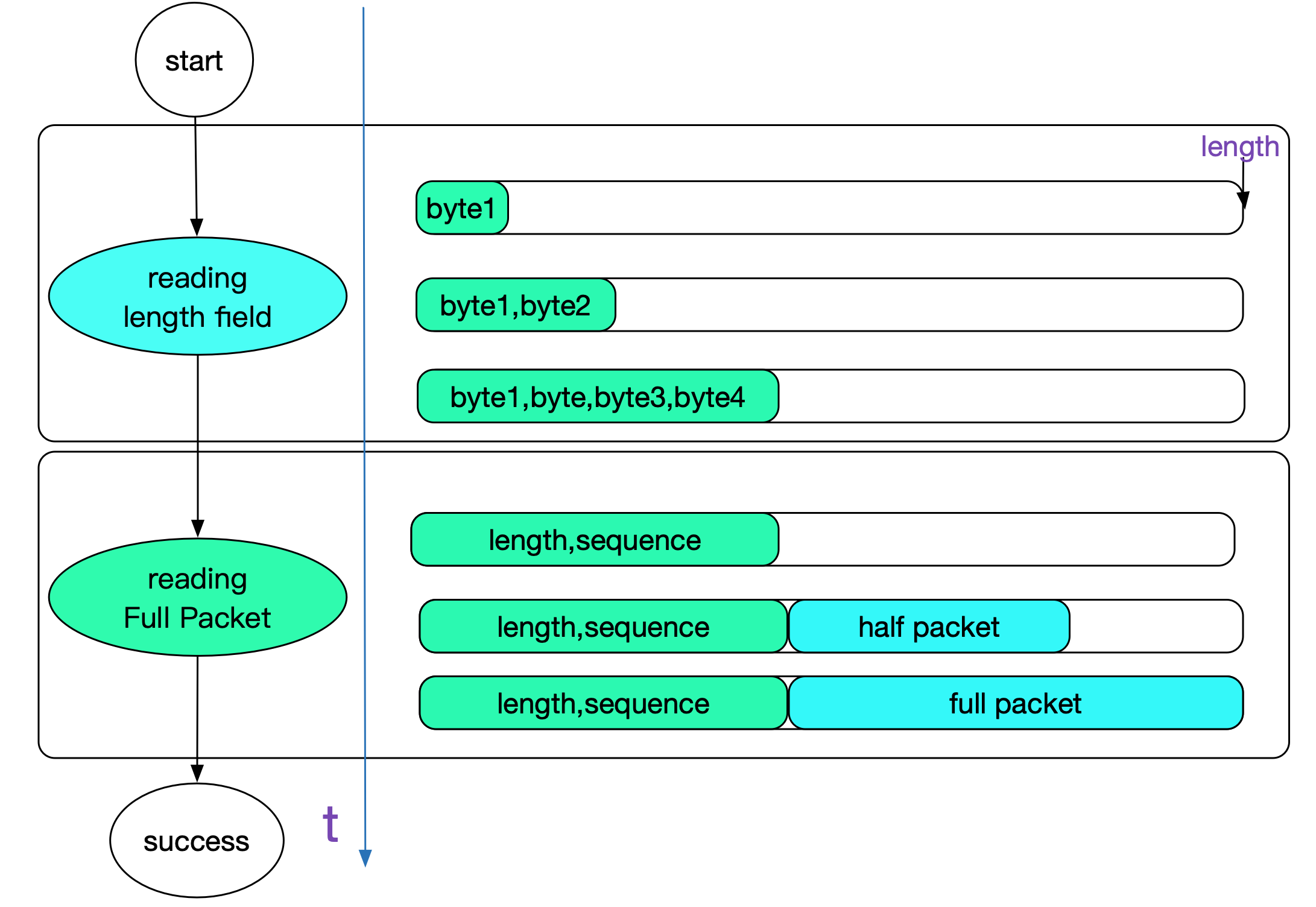
Hero的处理
Hero对于length field采用状态机进行处理,这也是通用的手法。首先读取3byte+1byte的packet_length和sequenceId,然后再通过packet_length读取剩下的body长度。如下图所示:
![]()
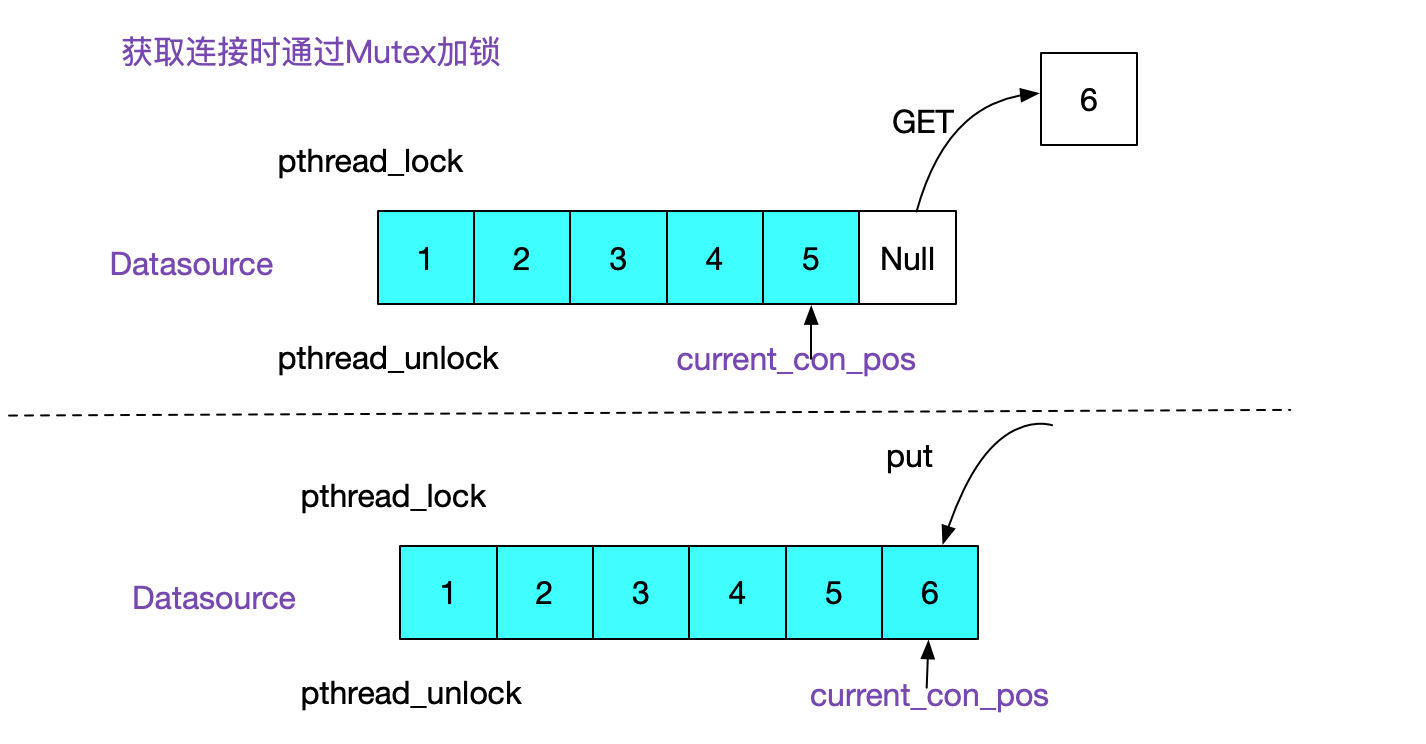
连接池
Hero的连接池造的还比较粗糙,事实上就是一个数组,通过mutex锁来控制并发的put/get ![]()
连接管理部分尚未开发。
MySQL协议格式处理
相较于前面的各种轮子,MySQL协议本身反倒显得轻松许多,唯一复杂的地方在于握手阶段的加解密过程,但是MySQL是开源的,笔者直接将MySQL本身对于握手加解密的代码copy过来就行了。以下代码copy自MySQL-5.1.59(密码学太高深,这个轮子不造也罢):
// 摘自MySQL-5.1.59,用作password的加解密
void scramble(char *to, const char *message, const char *password) {
SHA1_CONTEXT sha1_context;
uint8 hash_stage1[SHA1_HASH_SIZE];
uint8 hash_stage2[SHA1_HASH_SIZE];
mysql_sha1_reset(&sha1_context);
/* stage 1: hash password */
mysql_sha1_input(&sha1_context, (uint8 *) password, (uint) strlen(password));
mysql_sha1_result(&sha1_context, hash_stage1);
/* stage 2: hash stage 1; note that hash_stage2 is stored in the database */
mysql_sha1_reset(&sha1_context);
mysql_sha1_input(&sha1_context, hash_stage1, SHA1_HASH_SIZE);
mysql_sha1_result(&sha1_context, hash_stage2);
/* create crypt string as sha1(message, hash_stage2) */;
mysql_sha1_reset(&sha1_context);
mysql_sha1_input(&sha1_context, (const uint8 *) message, SCRAMBLE_LENGTH);
mysql_sha1_input(&sha1_context, hash_stage2, SHA1_HASH_SIZE);
/* xor allows 'from' and 'to' overlap: lets take advantage of it */
mysql_sha1_result(&sha1_context, (uint8 *) to);
my_crypt(to, (const uchar *) to, hash_stage1, SCRAMBLE_LENGTH);
}
剩下的无非就是按格式解释包中的各个字段,然后再进行处理而已。典型代码段如下:
int handle_com_query(front_conn* front){
char* sql = read_string(front->conn->read_buffer,front->conn->request_pool);
int rs = server_parse_sql(sql);
switch(rs & 0xff){
case SHOW:
return handle_show(front,sql,rs >> 8);
case SELECT:
return handle_select(front,sql,rs >> 8);
case KILL_QUERY:
......
default:
return default_execute(front,sql,FALSE);
}
return TRUE;
}
需要注意的是,hero在后端连接backend返回result_set结果集并拷贝到前端连接的write_buffer的时候,前端连接可能正在写入,也会操纵write_buffer。所以在这种情况下要通过Mutex去保护write_buffer(packet_buffer)的内部数据结构。
性能对比
下面到了令人激动的性能对比环节,笔者在一个4核8G的机器上用hero和另一个用java nio写的成熟DBProxy做对比。两者都是用show databases,这条sql并不会路由到后端的数据库,而是纯内存返回。这样笔者就能知道笔者自己造的reactor框架的性能如何,以下是对比情况:
用作对比的两个server的代码IO模型
hero(c):epoll 水平触发
proxy(java):java nio(内部也是epoll 水平触发)
benchMark:
服务器机器
4核8G
CPU主屏2399.996MHZ
cache size:4096KB
压测机器:
16核64G,jmeter
同样配置下,压测同一个简单的sql
hero(c):3.6Wtps/s
proxy(java):3.6Wtps/s
tps基本没有差别,因为瓶颈是在网络上
CPU消耗:
hero(c):10% cpu
proxy(java):15% cpu
内存消耗:
hero(c):0.2% * 8G
proxy(java):48.3% * 8G
结论:
对于IO瓶颈的情况,用java和C分别处理简单的组帧/解帧逻辑,C语言带来的微小收益并不能让tps有显著改善。
Hero虽然在CPU和内存消耗上有优势,但是限于网络瓶颈,tps并没有明显提升-_-!
相比于造轮子时候付出的各种努力,投入产出比(至少在表面上)是远远不如用Netty这种非常成熟的框架的。如果是工作,那我会毫不犹豫的用后者。
总结
造轮子是个非常有意思的过程,在这个过程中能够强迫笔者去思考平时根本无需思考的地方。
造轮子的过程也是非常艰辛的,造出来的轮子也不一定比现有的轮子靠谱。但造轮子的成就感还是满满的^_^
github链接
https://github.com/alchemystar/hero
码云链接
https://gitee.com/alchemystar/hero ![]()