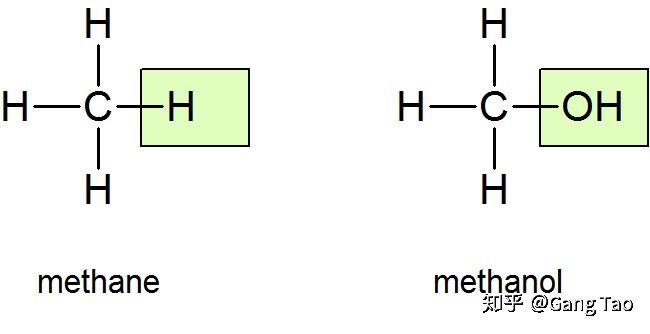最近有幸从图书馆借阅了Pedro Domingos的《The Master Alogrithm》一书,这本书的中文翻译叫《终极算法》,台湾版本叫《大演算》。英文原版的豆瓣评分是8.4,而中文翻译只有7.2。豆瓣用户对于该书的中文翻译吐槽不少,我没有读中文版本,但是对于原版,我个人认为非常值得阅读,无论你是否工作在机器学习领域,本书都能带给你足够的启发。
![]()
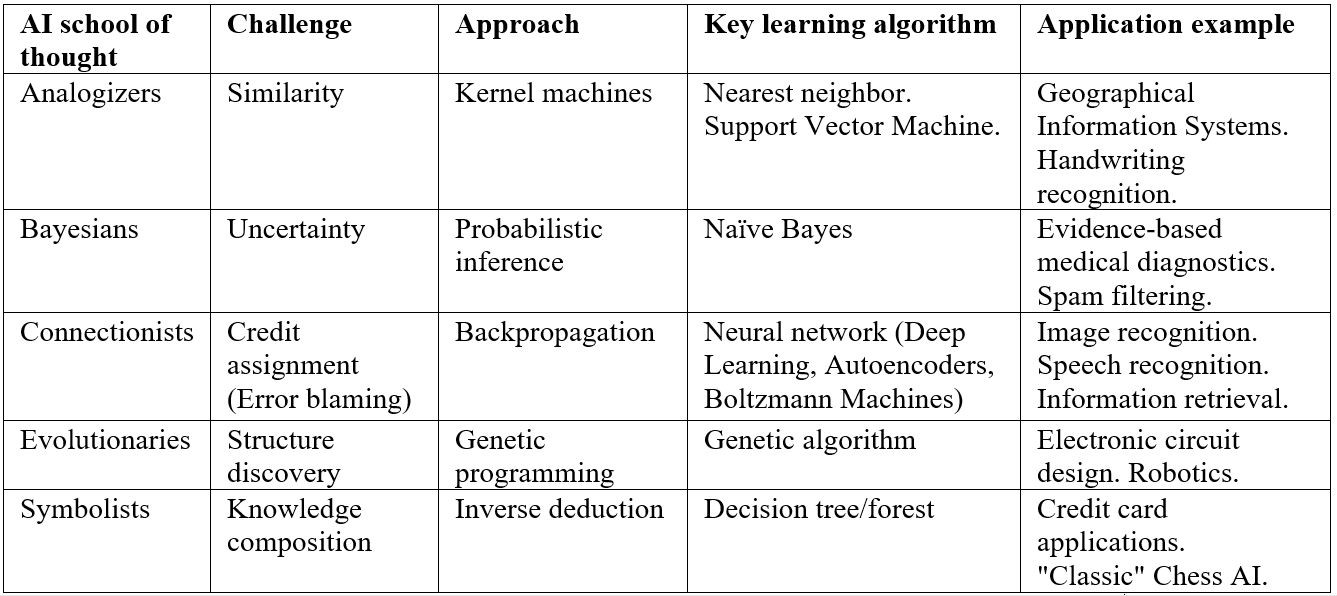
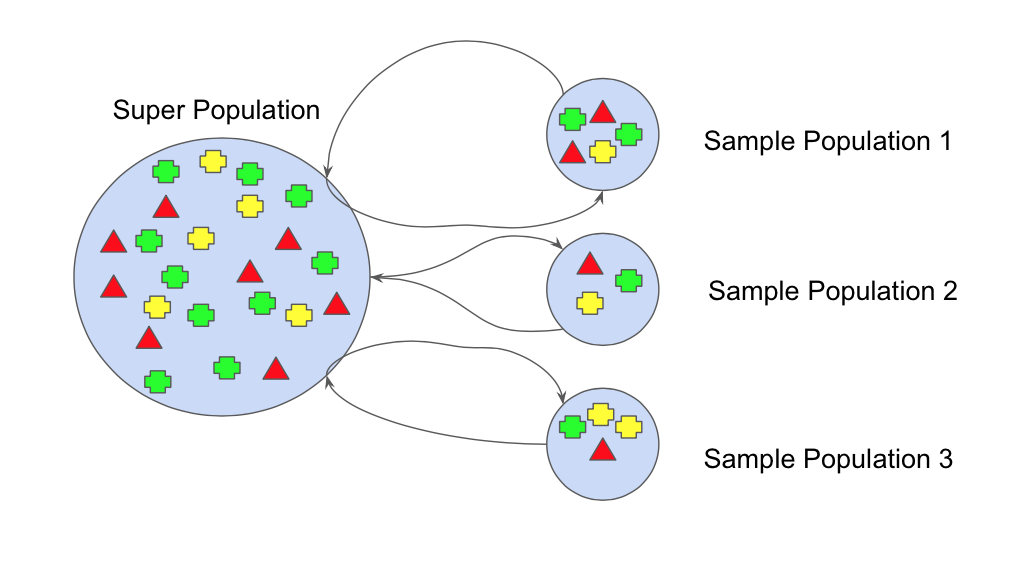
在之前学习机器学习的算法的时候,我经常有很多的疑惑,为什么机器学习的算法这么多,虽然整体上可以按照,有监督,无监督,回归,分类,聚类,降维等来归类算法,但是同一大类中算法差别又比较大,感觉体系结构混乱而嘈杂。多明戈斯把机器学习的算法分为五个大的部落,系统的阐述有这五个部落的思想和之间的联系和脉络。对于我而言就像吹散了迷雾,帮助我重构了我的机器学习算法的知识体系 。同时本书没有深奥的数学公式,非常适合对数学不太感冒,又希望了解机器学习的读者。
这里献上我的读书笔记。
序章
![]()
在序章中,作者提出了机器学习算法的五大部落:
- 符号主义:把学习看成是基于哲学,心理学和逻辑的逆向演绎。
- 连接主义:受神经科学和物理学的启发,对人类大脑进行逆向工程。
- 进化主义:引用生物科学和基因科学,在计算机上模拟进化
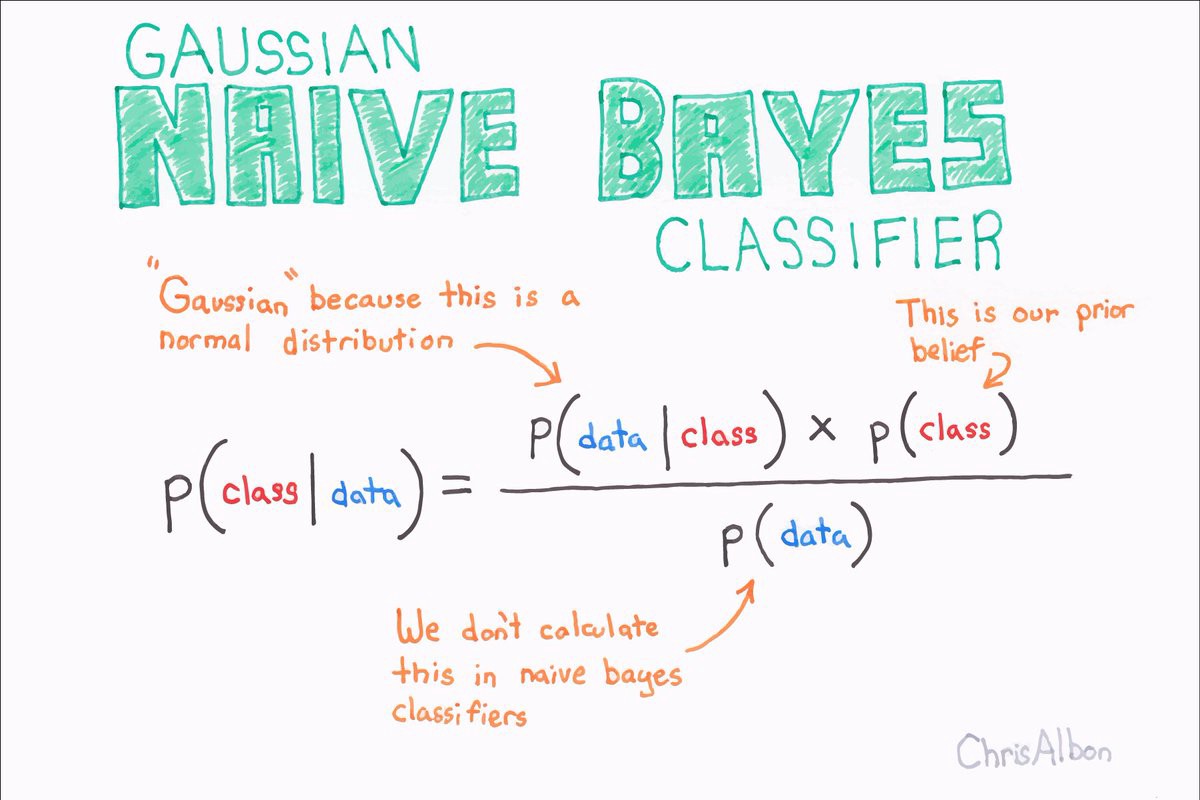
- 贝叶斯主义:认为学习是基于统计学的概率推理的一种形式
- 类比主义:受心理学和数学优化的影响,通过推测证据之间的类似性来学习。
第一章 机器学习的变革
我们生活在一个算法的时代,算法面临最大的挑战是复杂性(这里推荐一本书 《Complexity》,豆瓣评分9.1),无论是时间还是空间的复杂度。
机器学习和普通算法的区别在于,学习算法是用来生成算法的算法。机器学习就像种植,算法是种子,数据是土壤,学习的过程就是庄稼生长的过程,而我们这些写算法的程序猿果不其然就是码农了。同时,机器学习又是我们手中的利剑,用于杀戮复杂性怪兽。
工业革命使得手工劳动自动化,而信息革命使得大脑的工作自动化。而机器学习自动化自动化本身,如果做不到这一点,程序猿就会是系统的瓶颈。那么问题来了,程序猿为什么要和自己过不去?成为瓶颈不好么?
第二章 终极算法
在这一章中,作者提出了本书的基本假说:
所有的知识,无论过去,当下和未来,都可以利用某个单一,通用的学习算法中从数据中获取。
作者称其为终极算法或者主算法 - Master Algorithm
有以下的的论点来证明终极算法的存在:
- 从神经科学上来说,通过实验发现,科学家们通过改变神经元的“接受域”或它对应的视觉域触发了可塑性。
- 从进化论的角度来说,生命的无限多种形式,都是一个简单机制,自然选择的结果。
- 从物理学的角度来看,物理学由简单的数学公式主导。
- 从统计学的角度,贝叶斯理论可以把数据变成知识。
- 从计算机科学的角度,计算机本身的存在是一个很好的迹象表明存在终极算法。
在这一章中,作者正式引入了五个部落的概念,而终极算法必须能够有效的同时解决这五个问题。
![]()
第三章 休谟的归纳推理
哲学中的经典问题是关于理性主义和经验主义,理性主义者喜欢在行动之前把所有的计划都做好,而经验主义者通过不断的试错来找到方向。对于程序猿来说这就像是传统的瀑布流式软件工程之于敏捷式的开发。
大卫休谟是经验主义哲学家,休谟的怀疑论实际上是对于“因果性”的怀疑,休谟想要说明的是:相关性无法保证因果关系。我们看到一个东西,但是我们无法通过这个东西证明一个普遍存在的真理。
英国哲学家、数学家、思想家伯特兰·罗素提出过一个著名的火鸡问题(Russell's Turkey):在火鸡饲养场里,一只火鸡发现,每天上午9点钟主人给它喂食。它并不马上做出结论,而是慢慢观察,一直收集了有关上午9点给它喂食这一事实的大量观察证据:雨天和晴天,热天和冷天,星期三和星期四,各种各样的情况。最后,它得出了下面的结论:“主人总是在上午9点钟给我喂食。”可是,事情并不像它所想象的那样简单和乐观:在圣诞节前一天的9点,主人没有给它喂食,而是把它宰杀。
在休谟之后的250年,“没有免费的午餐”定理由美国斯坦福大学的Wolpert和Macready教授提出,简称NFL定理(和美国橄榄球联盟并没有鸟关系)。 在机器学习算法中的体现为在没有实际背景下,没有一种算法比随机胡猜的效果好。该定律类似帕斯卡的赌注,帕斯卡假定所有人类对上帝存在或不存在下注。由于上帝可能确实存在,并假设这情况下信者和不信者会分别得无限的收益或损失,一个理性的人应该相信上帝存在。如果上帝实际上不存在,这样信者将只会有限的损失;而如果上帝存在,信者得永生。但实际上这个赌注你可以把上帝换成任意的神,安拉,土地,白骨精,效果是一样的。把‘上帝’换成‘学习算法’,把‘永生’换成‘精准预测’就是NFL定律了。
Tom Mitchell, 是机器学习领域符号主义的领袖,他称之为“无用的无偏见学习”。在我们的日常生活中,‘偏见’是个贬义词,然而在机器学习中‘偏见’是非常重要的,没有它你将无法学习。实际上在人类的认知中,我们也一直在使用偏见。我们称这种偏见为“知识”。
我曾经在一家存储公司开发一种基于规则的引擎,该组件的核心是一组组的规则,每一个规则可以简化为一个条件和一个操作,也就是再满足某个条件的时候做某个事情。基于规则的学习也是类似的,它给出在在某个数据输入条件下的输出是什么。
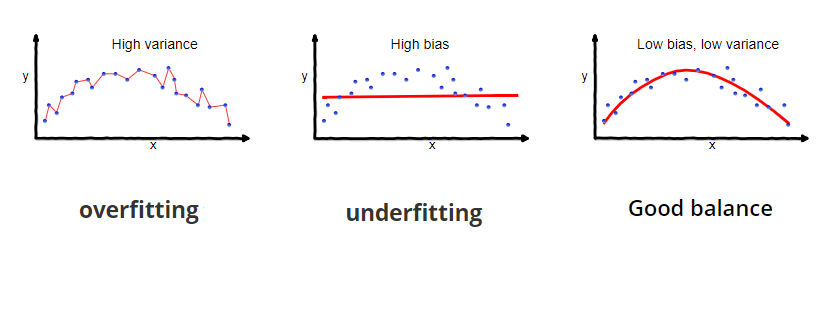
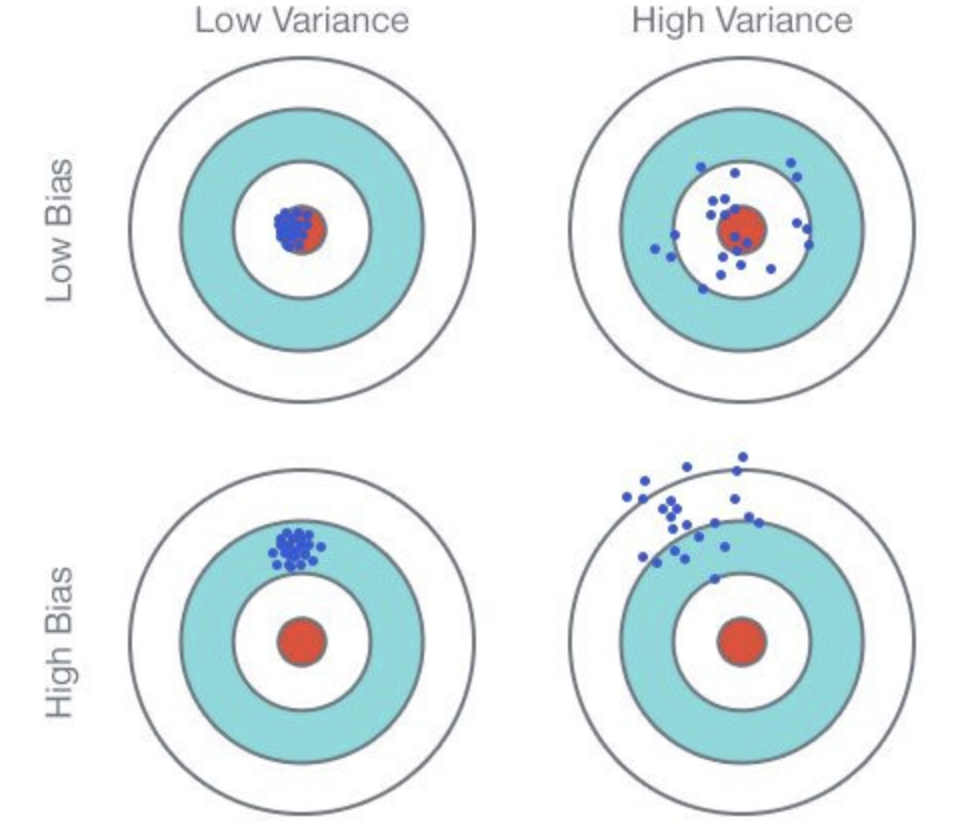
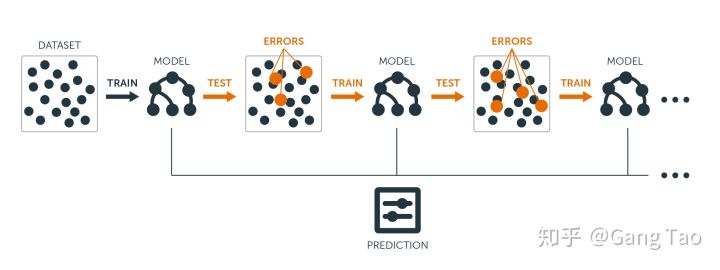
一个好的学习算法就像是在幻觉(overfit)和失明(underfit)之间左右摇摆。人类也不能免疫overfitting。阿里士多德认为力使物体保持运动就是一个overfitting的例子。算法学习是你的数据量和你的假说的数量之间的竞赛,更多数据可以有效的减少假说,但是如果你一开始就有很多假说,很有可能最后还是会留下来一些不太好的假说。这里我觉得可以参考奥卡姆剃刀,我的另一篇博客。但是在机器学习里,该假说会有误导。更简单的理论也许是underfitting。
![]()
![]()
![]()
归纳是逆向演绎。
![]()
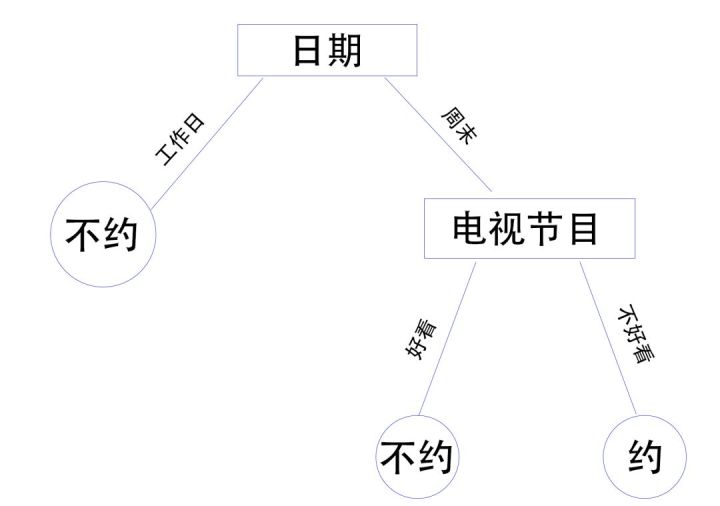
对于符号主义的学习算法的典型是决策树。决策树确保每一个实例都有唯一一个对应的规则。
如果某位男士想追求一名倾心的女生,已经有过几次约会记录,但并不是次次都成功,他面临一个不知所措的局面,继续约不约,怎么约?当然,影响能否约会成功的因素:周末与非周末、吃饭或泡吧、天气冷或暖、电视节目好看或不好看,也就是有2*2*2*2=16种可能性,导致她说“yes” or “no”的不同结果。这就需要策略,需要一棵树,一棵决策树。
![]()
符号主义认为所有的智能都可以通过符号的方式来推导。早期的人工智能使用被称作基于知识的系统,曾经迅速发展,但是很快就遇到了瓶颈。因为从专家身上抽取知识成为规则实在是太难了,即耗时耗力,又容易出错。
尽管决策树很流行,逆向演绎更接近终极算法。逆向演绎就像一位超级科学家系统的检查所有的证据,思考可能的归纳假说,并用新的证据来构建进一步的假说。当然所有的这一切都是由计算机来完成。以符号主义这的角度来看它简单而优雅。但是它的问题是,可能的归纳假说数量实在太大了,而且实际问题大多是不是非黑即白的问题,有很多的灰色地带,这时候规则也就不那么管用了。
连接主义对符号主义就非常不满,根据他们的观点,能通过逻辑规则定义的概念仅仅是冰山一角,表面之下还有很多的东西是推理无法完成的。
第四章 大脑如何学习
连接主义认为知识存在于神经元之间的连接中。不想符号主义认为的概念和符号存在一对一的映射,在连接主义中,概念和神经元是多对多的关系,每一个概念分布在多个神经元连接中,而每一个神经元也要参与构建多个概念。另一个区别,在符号主义中学习是穿行的,而在连接主义中,学习是并行的。
人类的大脑可以进行大量的并行运算,数十亿的神经元同时工作,但是每一个都很慢,因为神经元每秒只能触发上千次。(爱因斯坦,牛顿们可能超过频,会快一些)
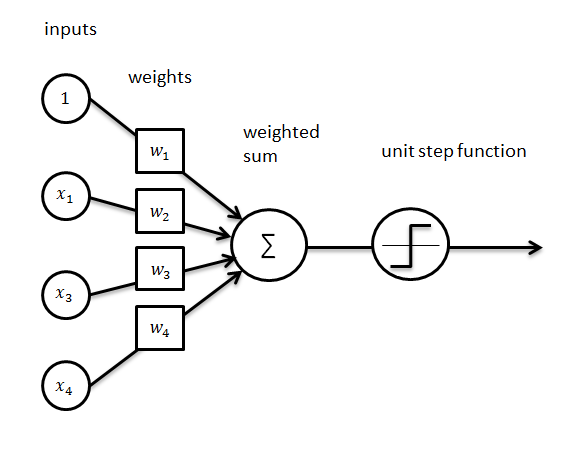
1943年,心理学家Warren McCulloch和数理逻辑学家Walter Pitts在合作的《A logical calculus of the ideas immanent in nervous activity》论文中提出并给出了人工神经网络的概念及人工神经元的数学模型,从而开创了人工神经网络研究的时代。感知器是Frank Rosenblatt在1957年所发明的一种人工神经网络。它可以被视为一种最简单形式的前馈神经网络,是一种二元线性分类器。
![]()
我们看到上图中的感知器和符号主义的规则是不是有一点点像,它是一个由神经元对于输入数据求和再由激活函数判定输出的数学规则。
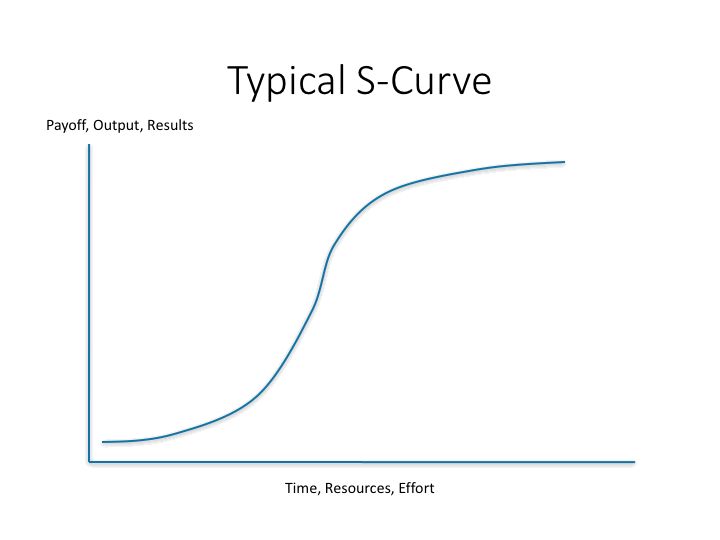
但是感知器不能解决简单的异或(XOR)等线性不可分问题。不像逻辑门,神经元更像是电压频率转换器。可以用S曲线来描述:
![]()
我们生活中的许多现象都可以用S曲线来描述,当我们面对指数增长的时候,你需要想一想,他什么时候会变成S曲线,想一想统治IT多年的摩尔定律吧。
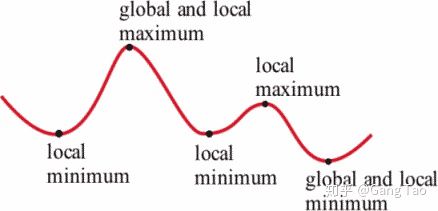
通过反向传播算法,连接主义迎来了他们的春天,多层感知器可以有效的进行学习了。但是这里有一个致命的问题,就是局部的最小值。
![]()
在高维空间中,学习很容易陷入局部最小值。虽然很多时候,这个值并不算太坏。而更严重的问题是,符号主义的规则和推理是我们人类很容易理解的,然而鬼才知道这个神经网络究竟在干些什么。没有人能偶解释它。神经网络的调优更像是在碰运气。
第五章 进化,大自然的学习算法
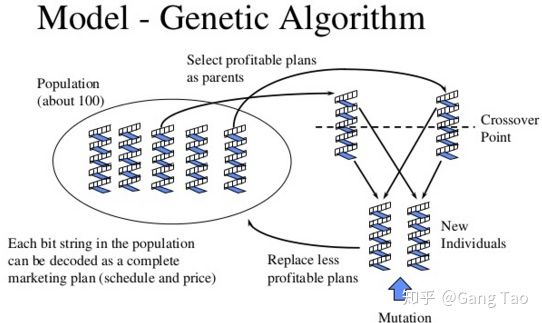
进化主义的学习算法是遗传算法,它是计算数学中用于解决最优化的搜索算法,最初是借鉴了进化生物学中的一些现象而发展起来的,这些现象包括遗传、突变、自然选择以及杂交等。
![]()
遗传算法的核心是杂交和变异:
![]()
当遗传算法达到局部的极值的时候,他会停留在那里很长一段时间,但是由于变异和杂交的存在,再加上一定运气,他有机会越过局部极值达到全局最优解。相比较神经网络的调优,这里程序猿只需静静的祈祷,等着变异就好了。
在神经网络中学习的是各个神经元的权重,而网络结构是固定的,而遗传算法能够通过进化来学习结构,这个是连接主义做不到的。终极算法既不是遗传算法也不是反向传播,但是它必须包含这两个关键元素,结构的学习和权重的学习。
连接主义和进化主义都是对自然的模拟,通过模拟大脑或者自然选择来进行学习。然而符号主义和贝叶斯主义不满足于并不完美的自然,大脑经常会做出错误的决定而,大自然也不总是给出最优解。这就是科学和哲学的冲突,科学追求的是真理,“这就是真相”,而哲学给出的是方法,“就该这么搞”。
第六章 在神圣的贝叶斯教堂里
对于贝叶斯主义者来说,学习只不过是贝叶斯定理的另一个应用,把模型看成是假说,把数据看成是证据:你得到越多的数据,某些模型就变得更可能为真,直到某一个模型明显胜出。
在拉普拉斯的一个思想实验中,如果太阳过去升起n天,那么明天太阳照样升起的概率是(n+1)/(n+2)。过度悲观的人和过度乐观的人都得不到这个数。前者不信均匀分布的假设,我想他们得到的概率下限该是1/2。而后者不相信整个概率模型的假设,因此得到概率为1。
![]()
朴素贝叶斯其实和感知器算法紧密关联。感知器对权重求和而朴素贝叶斯对概率求积,但是乘法做对数运算就是加法。所有这两个其实可以看成是如果-那么的规则模型。
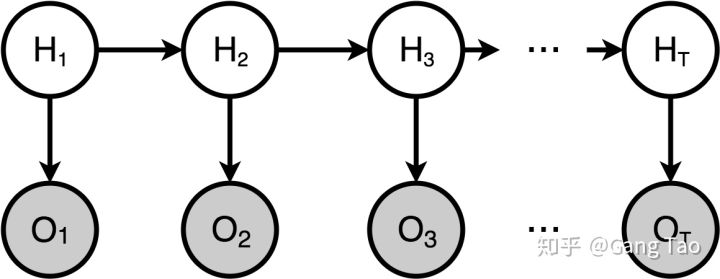
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析。
![]()
当状态和观察都是连续变量的时候,HMM就变成了卡曼滤波器。
贝叶斯网络(Bayesian network),又称信念网络(Belief Network),或有向无环图模型(directed acyclic graphical model),是一种概率图模型,于1985年由Judea Pearl首先提出。它是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓朴结构是一个有向无环图(DAG)。我们将有因果关系(或非条件独立)的变量或命题用箭头来连接(换言之,连接两个节点的箭头代表此两个随机变量是具有因果关系,或非条件独立)。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(children)”,两节点就会产生一个条件概率值。 例如,假设节点E直接影响到节点H,即E→H,则用从E指向H的箭头建立结点E到结点H的有向弧(E,H),权值(即连接强度)用条件概率P(H|E)来表示,如下图所示:
![]()
把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。
朴素贝叶斯,马尔可夫链和隐马尔可夫模型都可以看成是贝叶斯网络的特例。
对贝叶斯主义者来说,并不存在真相,你可以有一个对于假说的先验分布,验证数据后变为后验分布,仅此而已。
在以上的理论中,学习都是又一个明确的模型,可以是一组规则,多层感知器,基因算法,或者贝叶斯网络。但是他们都有一个限制,当数据量非常小的时候,他们都无法很好的工作。然而类比主义可以从很少的数据中学习,因为他不需要建立模型。
第七章 像什么就是什么
类比主义的算法核心就是基于已有的数据判定输入数据和已有数据最接近,或者说最像的分类。
近邻算法是最简单也最高效的学习算法。对于近邻算法而言,其实并没有一个学习的过程,因为没有模型,数据来了直接算相似度就好了,这也是类比主义和其它几个部落的一个大的区别。
近邻算法的一个问题就是如果有很多不相关的特性,分类会很糟糕因为算法会找和这些不相关特性的相似处。另外在高维空间,计算相似会变得很困难。实际上,没有一个学习算法可以免疫高维度带来的诅咒,维度灾难是机器学习中仅次于过拟合(overfitting)大问题。
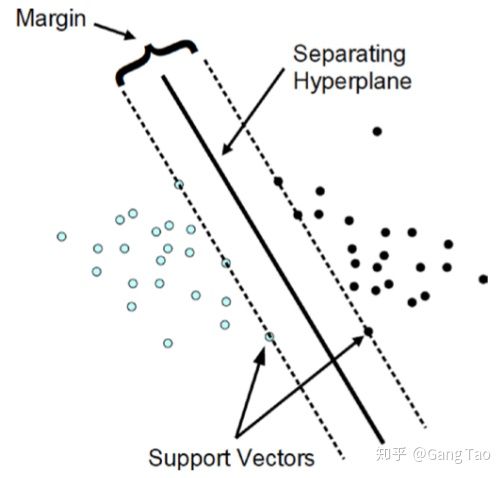
支持向量机使用支持向量和权重来产生最大可能的边界。如下图所示,找到一个超平面使得Margin最大。
![]()
SVM其实也可以看成是感知器,但是它相比较多层感知器的主要优点是SVM的权重有唯一的最优解,而不像神经网络存在许多的局部最优解。但是神经网络有更丰富的表现能力。
类比主义的一个问题是,两个事物相像,并不一定表明它们就是一个类别。
![]()
从分子结构看,甲烷(也就是沼气)和甲醇就差了一个氧原子。然而这两种分子的物理和化学特性都截然不同。
所有我们之前提到的算法都需要老师来教它们,它们并不能自发的学习。最于终极算法而言,这可不行。
第八章 无师自通
这一章中,作者从无监督学习的聚类和主成分分析开讲。这两个都是属于无师自通型的算法。
当你需要学习一个统计模型但是又缺乏关键信息的时候,你可以使用EM,最大似然估计。K均值算法和EM算法有些类似。它们都是把实体分配到某一个聚类,然后更新聚类的属性。实际上,K均值是EM算法在所有的特性都符合正态分布时的一个特例。
之前的算法有一个问题就是计算最大回报,然而在现实中,我们并以一定每一步都需要最大回报来得到最终的胜利,有时候倒车是为了更好的前进。这里就需要引入强化学习。
第九章 所有的拼图一目了然
在这一章里,作者希望像秦始皇同一六国一样统一机器学习所有的五个部落。许多重要的科技都是因为发明了统一的机制,例如电作为统一的能源,互联网作为统一的通信机制。物理学家一直在找寻大一统的理论统一所有的力。作者也希望终极算法能统一所有的学习算法。
把不同的算法合并为一个并不难,我们称之为元学习。现在的 AI 系统可以通过大量时间和经验从头学习一项复杂技能。但是,我们如果想使智能体掌握多种技能、适应多种环境,则不应该从头开始在每一个环境中训练每一项技能,而是需要智能体通过对以往经验的再利用来学习如何学习多项新任务,因此我们不应该独立地训练每一个新任务。这种学习如何学习的方法,是通往可持续学习多项新任务的多面智能体的必经之路。
引导聚集算法(Bagging)通过对训练集随机采样,并应用在同一个学习算法上,然后通过投票表决来决定最终结果。
![]()
另一个元学习算法是Boosting,不同于合并不同的学习器,Boosting重复在数据上应用同一分类器,然后通过在训练集上分配不同的权重,用新的模型来纠正之前的错误,每一个被错误分类的样本都会被增加权重。
![]()
![]()
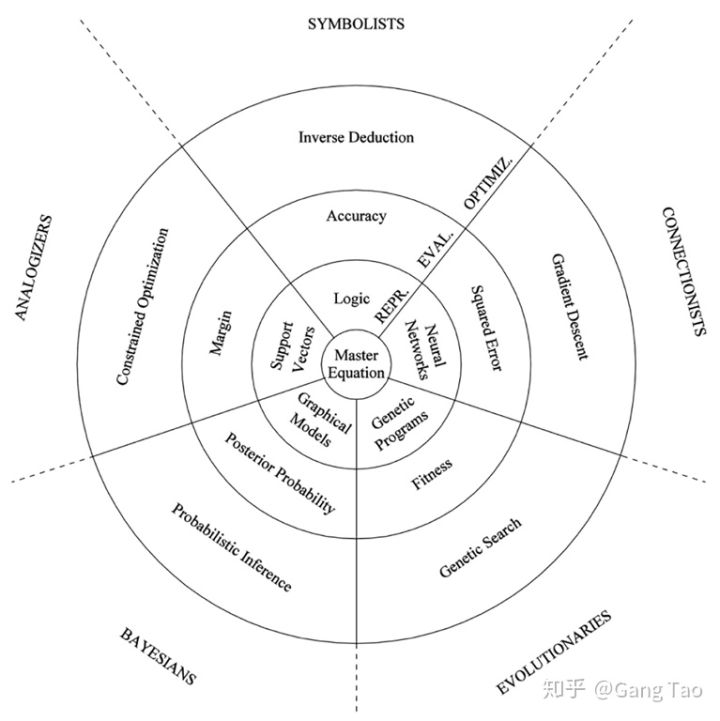
最终,如上图所示,所有的部落都可以用三个关键元素来描述,表示层,评估单元(代价Cost)和优化器。
- 表示层定义学习器如何表示模型,对于符号主义来说是逻辑和规则,对于连接主义是神经网络,对于进化主义是基因算法,对于贝叶斯是图模型(贝叶斯网络或者马尔可夫网络),对于类比主义来说是用于某些权重的特例(SVM)
- 评估单元就是记分函数,用于评价一个模型究竟是好还是不好。对于符号主义来说是准确度或者信息增益。对于连接主义是连续误差,例如均方差。对于贝叶斯来说是后验概率。对于进化主义来说是适应度。对于类比主义来说是Margin或者距离。同时所有的部落都会考虑到一些通用的属性例如模型是否简洁。
- 优化器是如何找到得分最高的模型,并返回该模型的算法。对于符号主义是逆向归纳。对于连接主义是梯度下降。对于进化主义是基因搜索包含突变和杂交。对于贝叶斯来说有些特殊,它并不搜索最佳模型,它使用概率推测计算所有模型的概率。对于类比主义使用有限制条件的优化方法。
我们可以看出各个部落之间存在着这样或者那样的联系,每一个符号主义的规则可以看成是一个特殊的神经元,而SVM可以看成是一个感知器,进化主义的适应度和连接主义的均方差也并没有本质上的区别。
第十章 建立在机器学习之上的世界
最后一章其实非常有趣,作者展望了机器学习对人类社会的影响。
我们在和不同的应用在交互,其实是在训练一个能够理解我们的模型,如果你讨厌google,facebook,那么你要做的就是拼了老命去点击那些你不喜欢的广告,因为这样google,facebook就会训练出一个错误的模型,哈哈!
在不远的将来,没个人都会有自己的一个数字拷贝,它就是基于你的数据训练出的你的模型,它帮你选择购买什么样的产品,它帮你决定和谁约会,它帮你寻找合适的工作机会,它决定你早餐应该吃什么,它决定你的病要吃什么药。
随着机器能够做越来越多的工作,失业率将被就业率取代,国家富强的标志不是看你提高了多少就业,而是看你是不是应用了更多的科技来解放人力。
It’s Difficult to Make Predictions, Especially About the Future
The best way to predict the future is to invent it. -- Alan Kay
总结
如果你觉得本读书笔记内容凌乱,那绝对是我的错误,和原书无关,这是一本五星推荐的书,对于我而言,它就像是一串串珠,把凌乱的机器学习算法穿在一条线索上,这是一本我希望早点能读到的书,欢迎大家和我交流!
参考