背景
1.通常我们在获取到一个list列表后需要一个挨着一个的进行遍历处理数据,如果每次处理都需要长时间操作,那整个流程下来时间就是每一次处理时间的总和。
2.Java8的stream接口极大地减少了for循环写法的复杂性,stream提供了map/reduce/collect等一系列聚合接口,还支持并发操作:parallelStream。
例子
定义一个位置类和服务,其中创建10个地址位置
package cn.chinotan.dto;
/**
* @program: test
* @description: 位置
* @author: xingcheng
* @create: 2018-11-17 19:36
**/
public class Location {
String name;
public Location() {
}
public Location(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
package cn.chinotan.controller;
import cn.chinotan.dto.Location;
import org.apache.commons.lang3.StringUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
/**
* @program: test
* @description: 位置服务
* @author: xingcheng
* @create: 2018-11-17 19:42
**/
@RestController
public class LocationController {
@GetMapping("/location")
public List<Location> getLocations() {
List<Location> locations = new ArrayList<>();
for (int i = 0; i < 10; i++) {
locations.add(new Location(StringUtils.join("London", i)));
}
return locations;
}
}
定义一个温度类和服务,其中温度值介于30到50之间。 在实现中添加500 ms的延迟以模拟耗时操作
package cn.chinotan.dto;
/**
* @program: test
* @description: 温度
* @author: xingcheng
* @create: 2018-11-17 19:35
**/
public class Temperature {
private Double temperature;
private String scale;
public Double getTemperature() {
return temperature;
}
public void setTemperature(Double temperature) {
this.temperature = temperature;
}
public String getScale() {
return scale;
}
public void setScale(String scale) {
this.scale = scale;
}
}
package cn.chinotan.controller;
import cn.chinotan.dto.Temperature;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.util.Random;
/**
* @program: test
* @description: 温度服务
* @author: xingcheng
* @create: 2018-11-17 19:45
**/
@RestController
public class TemperatureController {
@GetMapping("/temperature/{city}")
public Temperature getAverageTemperature(@PathVariable("city") String city) {
Temperature temperature = new Temperature();
temperature.setTemperature((double) (new Random().nextInt(20) + 30));
temperature.setScale("Celsius");
try {
Thread.sleep(500);
} catch (InterruptedException ignored) {
}
return temperature;
}
}
定义一个天气预报类和响应
package cn.chinotan.dto;
/**
* @program: test
* @description: 天气预报
* @author: xingcheng
* @create: 2018-11-17 19:37
**/
public class Forecast implements Comparable<Forecast> {
private Location location;
private Temperature temperature;
public Forecast(Location location) {
this.location = location;
}
public Forecast setTemperature(final Temperature temperature) {
this.temperature = temperature;
return this;
}
public Location getLocation() {
return location;
}
public void setLocation(Location location) {
this.location = location;
}
public Temperature getTemperature() {
return temperature;
}
@Override
public int compareTo(Forecast o) {
if (o.getTemperature().getTemperature() > temperature.getTemperature()) {
return 1;
} else {
return -1;
}
}
}
package cn.chinotan.dto.response;
import cn.chinotan.dto.Forecast;
import java.util.ArrayList;
import java.util.List;
/**
* @program: test
* @description: 服务响应
* @author: xingcheng
* @create: 2018-11-17 19:39
**/
public class ServiceResponse {
private long processingTime;
private List<Forecast> forecasts = new ArrayList<>();
public void setProcessingTime(long processingTime) {
this.processingTime = processingTime;
}
public ServiceResponse forecasts(List<Forecast> forecasts) {
this.forecasts = forecasts;
return this;
}
public long getProcessingTime() {
return processingTime;
}
public List<Forecast> getForecasts() {
return forecasts;
}
public void setForecasts(List<Forecast> forecasts) {
this.forecasts = forecasts;
}
}
package cn.chinotan.controller;
import cn.chinotan.dto.Forecast;
import cn.chinotan.dto.Location;
import cn.chinotan.dto.Temperature;
import cn.chinotan.dto.response.ServiceResponse;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.http.HttpEntity;
import org.springframework.http.HttpMethod;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import rx.Observable;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
/**
* @program: test
* @description: 天气预报
* @author: xingcheng
* @create: 2018-11-17 19:47
**/
@RestController
public class ForecastController {
@Autowired
RestTemplate restTemplate;
private final static String SERVER_ADDRESS = "http://localhost:9000";
@GetMapping("/v1/forecast")
public ServiceResponse getLocationsWithTemperatureV1() {
long startTime = System.currentTimeMillis();
ServiceResponse response = new ServiceResponse();
List<Location> locations = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/location"), HttpMethod.GET,
HttpEntity.EMPTY, new ParameterizedTypeReference<List<Location>>() {
}).getBody();
locations.forEach(location -> {
Temperature temperature = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/temperature/", location.getName()),
HttpMethod.GET, HttpEntity.EMPTY, Temperature.class).getBody();
response.getForecasts().add(new Forecast(location).setTemperature(temperature));
});
long endTime = System.currentTimeMillis();
response.setProcessingTime(endTime - startTime);
return response;
}
@GetMapping("/v2/forecast")
public ServiceResponse getLocationsWithTemperatureV2() {
long startTime = System.currentTimeMillis();
ServiceResponse response = new ServiceResponse();
List<Location> locations = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/location"), HttpMethod.GET,
HttpEntity.EMPTY, new ParameterizedTypeReference<List<Location>>() {
}).getBody();
List<Forecast> collect = locations.parallelStream().map(location -> {
Temperature temperature = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/temperature/", location.getName()),
HttpMethod.GET, HttpEntity.EMPTY, Temperature.class).getBody();
return new Forecast(location).setTemperature(temperature);
}).collect(Collectors.toList());
long sortStart = System.currentTimeMillis();
List<Forecast> collectResponse = collect.parallelStream().sorted().collect(Collectors.toList());
long sortEnd = System.currentTimeMillis();
System.out.println("排序花费时间:" + (sortEnd - sortStart));
response.setForecasts(collectResponse);
long endTime = System.currentTimeMillis();
response.setProcessingTime(endTime - startTime);
return response;
}
@GetMapping("/v3/forecast")
public ServiceResponse getLocationsWithTemperatureV3() {
long startTime = System.currentTimeMillis();
ServiceResponse response = new ServiceResponse();
List<Location> locations = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/location"), HttpMethod.GET,
HttpEntity.EMPTY, new ParameterizedTypeReference<List<Location>>() {
}).getBody();
locations.parallelStream().forEachOrdered(location -> {
Temperature temperature = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/temperature/", location.getName()),
HttpMethod.GET, HttpEntity.EMPTY, Temperature.class).getBody();
response.getForecasts().add(new Forecast(location).setTemperature(temperature));
});
long endTime = System.currentTimeMillis();
response.setProcessingTime(endTime - startTime);
return response;
}
}
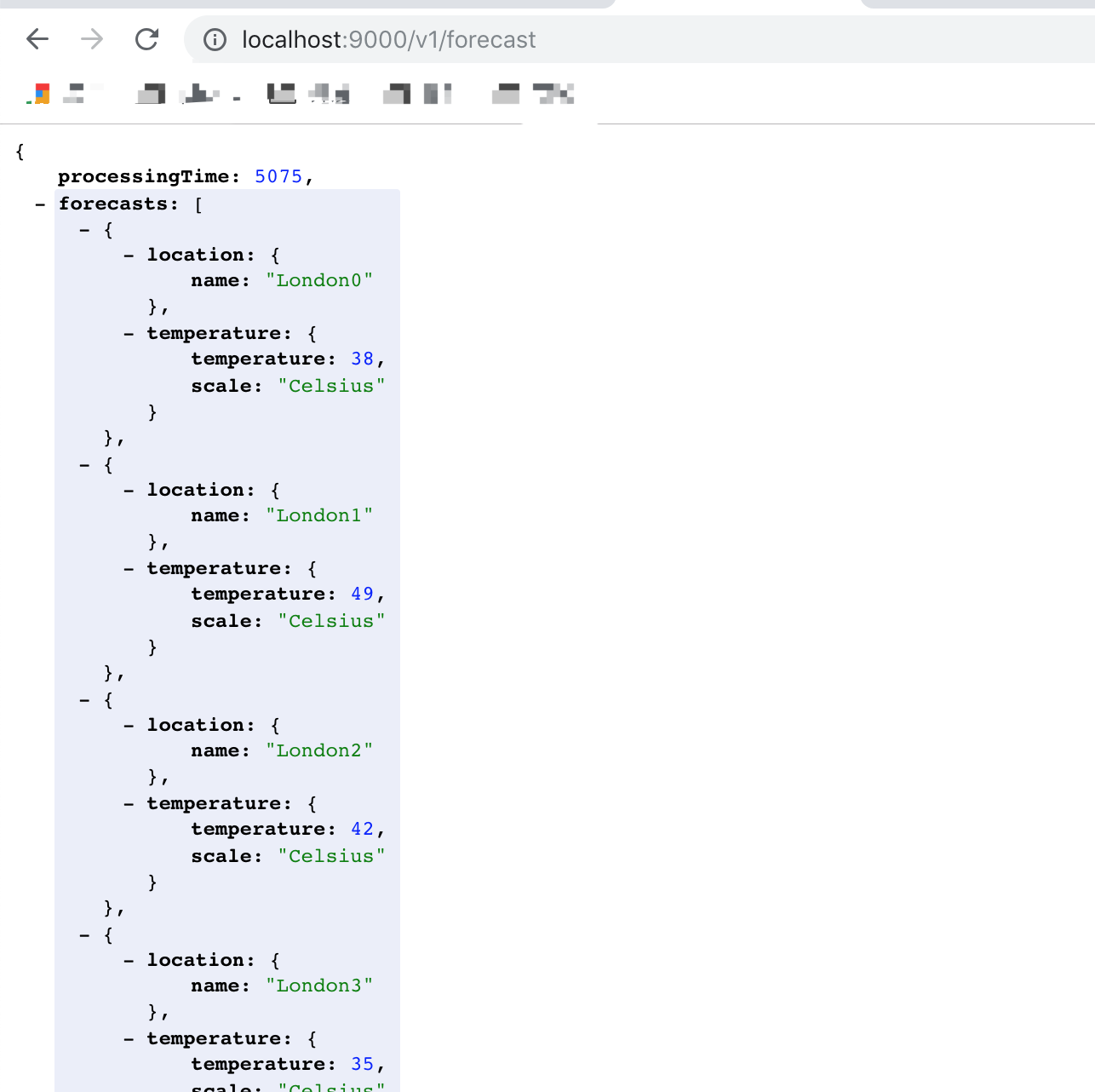
其中,v1接口是普通的list遍历实现,接口响应:
![]()
可以看到接口响应时间是每次http调用的时间(500毫秒)总和多一些
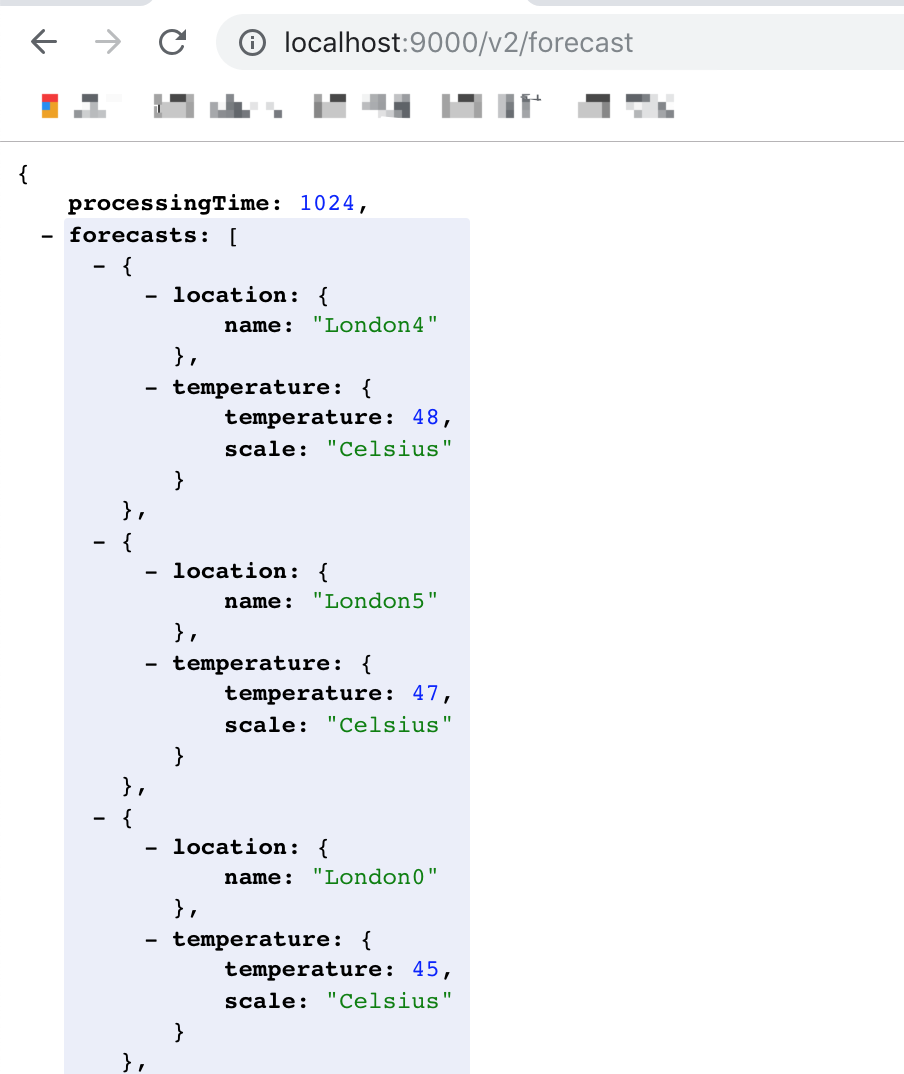
接下来调用v2接口:
![]()
可以看到时间缩短了5倍
分析
先了解什么是流?
Stream是java8中新增加的一个特性, 统称为流.
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的 Stream,用户只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程。Java 的并行 API 演变历程基本如下:
-
.0-1.4 中的 java.lang.Thread
-
5.0 中的 java.util.concurrent
-
6.0 中的 Phasers 等
-
7.0 中的 Fork/Join 框架
-
8.0 中的 Lambda
parallelStream是什么
parallelStream其实就是一个并行执行的流.它通过默认的ForkJoinPool,可能提高你的多线程任务的速度.
parallelStream的作用
Stream具有平行处理能力,处理的过程会分而治之,也就是将一个大任务切分成多个小任务,这表示每个任务都是一个操作,因此像以下的程式片段:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream()
.forEach(out::println);
你得到的展示顺序不一定会是1、2、3、4、5、6、7、8、9,而可能是任意的顺序,就forEach()这个操作來讲,如果平行处理时,希望最后顺序是按照原来Stream的数据顺序,那可以调用forEachOrdered()。例如:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream()
.forEachOrdered(out::println);
注意:如果forEachOrdered()中间有其他如filter()的中介操作,会试着平行化处理,然后最终forEachOrdered()会以原数据顺序处理,因此,使用forEachOrdered()这类的有序处理,可能会(或完全失去)失去平行化的一些优势,实际上中介操作亦有可能如此,例如sorted()方法。
例如:执行v3接口:
![]()
可以看到执行时间和普通的流一样。。。
parallelStream细节探秘: ForkJoinPool
要想深入的研究parallelStream之前,那么我们必须先了解ForkJoin框架和ForkJoinPool.因为两种关系甚密,故在此简单介绍一下ForkJoinPool,如有兴趣可以更深入的去了解下ForkJoin***(当然,如果你想真正的搞透parallelStream,那么你依然需要先搞透ForkJoinPool).*
ForkJoin框架是从jdk7中新特性,它同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法。这里的要点在于,ForkJoinPool需要使用相对少的线程来处理大量的任务。比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
那么使用ThreadPoolExecutor或者ForkJoinPool,会有什么性能的差异呢?
首先,使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。但是,使用ThreadPoolExecutor时,是不可能完成的,因为ThreadPoolExecutor中的Thread无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,显然这是不可行的。
工作窃取算法
forkjoin最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的cpu,那么如何利用好这个空闲的cpu就成了提高性能的关键,而这里我们要提到的工作窃取(work-stealing)算法就是整个forkjion框架的核心理念,工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
那么为什么需要使用工作窃取算法呢?
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
用看forkjion的眼光来看ParallelStreams
上文中已经提到了在Java 8引入了自动并行化的概念。它能够让一部分Java代码自动地以并行的方式执行,也就是我们使用了ForkJoinPool的ParallelStream。
Java 8为ForkJoinPool添加了一个通用线程池,这个线程池用来处理那些没有被显式提交到任何线程池的任务。它是ForkJoinPool类型上的一个静态元素,它拥有的默认线程数量等于运行计算机上的处理器数量。当调用Arrays类上添加的新方法时,自动并行化就会发生。比如用来排序一个数组的并行快速排序,用来对一个数组中的元素进行并行遍历。自动并行化也被运用在Java 8新添加的Stream API中。
对于列表中的元素的操作都会以并行的方式执行。forEach方法会为每个元素的计算操作创建一个任务,该任务会被前文中提到的ForkJoinPool中的通用线程池处理。以上的并行计算逻辑当然也可以使用ThreadPoolExecutor完成,但是就代码的可读性和代码量而言,使用ForkJoinPool明显更胜一筹。
对于ForkJoinPool通用线程池的线程数量,通常使用默认值就可以了,即运行时计算机的处理器数量。我这里提供了一个示例的代码让你了解jvm所使用的ForkJoinPool的线程数量, 你可以可以通过设置系统属性:-Djava.util.concurrent.ForkJoinPool.common.parallelism=N (N为线程数量),来调整ForkJoinPool的线程数量,可以尝试调整成不同的参数来观察每次的输出结果。
但是它会将执行forEach本身的线程也作为线程池中的一个工作线程。因此,即使将ForkJoinPool的通用线程池的线程数量设置为1,实际上也会有2个工作线程。因此在使用forEach的时候,线程数为1的ForkJoinPool通用线程池和线程数为2的ThreadPoolExecutor是等价的。
所以当ForkJoinPool通用线程池实际需要4个工作线程时,可以将它设置成3,那么在运行时可用的工作线程就是4了。
小结
1. 当需要处理递归分治算法时,考虑使用ForkJoinPool。
2. 仔细设置不再进行任务划分的阈值,这个阈值对性能有影响。
3. Java 8中的一些特性会使用到ForkJoinPool中的通用线程池。在某些场合下,需要调整该线程池的默认的线程数量。
ParallelStreams 的陷阱
上文中我们已经看到了ParallelStream他强大无比的特性,但这里我们就讲告诉你ParallelStreams不是万金油,而是一把双刃剑,如果错误的使用反倒可能伤人伤己.
可能有很多朋友在jdk7用future配合countDownLatch自己实现的这个功能,但是jdk8的朋友基本都会用上面的实现方式,那么自信深究一下究竟自己用future实现的这个功能和利用jdk8的parallelStream来实现这个功能有什么不同点呢?坑又在哪里呢?
让我们细思思考一下整个功能究竟是如何运转的。首先我们的集合元素engines 由ParallelStreams并行的去进行map操作(ParallelStreams使用JVM默认的forkJoin框架的线程池由当前线程去执行并行操作).
然而,这里需要注意的一地方是我们在调用第三方的api请求是一个响应略慢而且会阻塞操作的一个过程。所以在某时刻所有线程都会调用 get() 方法并且在那里等待结果返回.
再回过头仔细思考一下这个功能的实现过程是我们一开始想要的吗?我们是在同一时间等待所有的结果,而不是遍历这个列表按顺序等待每个回答.然而,由于ForkJoinPool workders的存在,这样平行的等待相对于使用主线程的等待会产生的一种副作用.
现在ForkJoin pool (关于forkjion的更多实现你可以去搜索引擎中去看一下他的具体实现方式) 的实现是: 它并不会因为产生了新的workers而抵消掉阻塞的workers。那么在某个时间所有 ForkJoinPool.common() 的线程都会被用光.也就是说,下一次你调用这个查询方法,就可能会在一个时间与其他的parallel stream同时运行,而导致第二个任务的性能大大受损。或者说,例如你在这个功能里是用来快速返回调用的第三方api的,而在其他的功能里是用于一些简单的数据并行计算的,但是假如你先调用了这个功能,同一时间之后调用计算的函数,那么这里forkjionPool的实现会让你计算的函数大打折扣.
不过也不要急着去吐槽ForkJoinPool的实现,在不同的情况下你可以给它一个ManagedBlocker实例并且确保它知道在一个阻塞调用中应该什么时候去抵消掉卡住的workers.现在有意思的一点是,在一个parallel stream处理中并不一定是阻塞调用会拖延程序的性能。任何被用于映射在一个集合上的长时间运行的函数都会产生同样的问题.
正如我们上面那个列子的情况分析得知,lambda的执行并不是瞬间完成的,所有使用parallel streams的程序都有可能成为阻塞程序的源头,并且在执行过程中程序中的其他部分将无法访问这些workers,这意味着任何依赖parallel streams的程序在什么别的东西占用着common ForkJoinPool时将会变得不可预知并且暗藏危机.
此外,parallelStream是并行操作,不是线程安全的,那么是不是在其中的进行的非原子操作都要加锁呢?
答案是:paralleStream的forEach接口确实不能保证同步,同时也提出了解决方案:使用collect和reduce接口,Collections框架提供了同步的包装,使得其中的操作线程安全。
即代码中的:
![]()
怎么正确使用parallelStream
如果你正在写一个其他地方都是单线程的程序并且准确地知道什么时候你应该要使用parallel streams,这样的话你可能会觉得这个问题有一点肤浅。然而,我们很多人是在处理web应用、各种不同的框架以及重量级应用服务。一个服务器是怎样被设计成一个可以支持多种独立应用的主机的?谁知道呢,给你一个可以并行的却不能控制输入的parallel stream.
很抱歉,请原谅我用的标注[怎么正确使用parallelStream],因为目前为止我也没有发现一个好的方式来让我真正的正确使用parallelStream.下面的网上写的两种方式:
一种方式是限制ForkJoinPool提供的并行数。可以通过使用-Djava.util.concurrent.ForkJoinPool.common.parallelism=1 来限制线程池的大小为1。不再从并行化中得到好处可以杜绝错误的使用它(其实这个方式还是有点搞笑的,既然这样搞那我还不如不去使用并行流)。
另一种方式就是,一个被称为工作区的可以让ForkJoinPool平行放置的 parallelStream() 实现。不幸的是现在的JDK还没有实现。
Parallel streams 是无法预测的,而且想要正确地使用它有些棘手。几乎任何parallel streams的使用都会影响程序中无关部分的性能,而且是一种无法预测的方式。。但是在调用stream.parallel() 或者parallelStream()时候在我的代码里之前我仍然会重新审视一遍他给我的程序究竟会带来什么问题,他能有多大的提升,是否有使用他的意义.
stream or parallelStream?
上面我们也看到了parallelStream所带来的隐患和好处,那么,在从stream和parallelStream方法中进行选择时,我们可以考虑以下几个问题:
1. 是否需要并行?
2. 任务之间是否是独立的?是否会引起任何竞态条件?
3. 结果是否取决于任务的调用顺序?
对于问题1,在回答这个问题之前,你需要弄清楚你要解决的问题是什么,数据量有多大,计算的特点是什么?并不是所有的问题都适合使用并发程序来求解,比如当数据量不大时,顺序执行往往比并行执行更快。毕竟,准备线程池和其它相关资源也是需要时间的。但是,当任务涉及到I/O操作并且任务之间不互相依赖时,那么并行化就是一个不错的选择。通常而言,将这类程序并行化之后,执行速度会提升好几个等级。
对于问题2,如果任务之间是独立的,并且代码中不涉及到对同一个对象的某个状态或者某个变量的更新操作,那么就表明代码是可以被并行化的。
对于问题3,由于在并行环境中任务的执行顺序是不确定的,因此对于依赖于顺序的任务而言,并行化也许不能给出正确的结果。
参考文章:https://blog.csdn.net/u011001723/article/details/52794455