harbor仓库中的镜像扫描这个功能,看似很高大上,其实等你了解了它的底层原理与流程,你就会发现就是做了那么一件事而已,用通俗的一句话概括,就是找到每个镜像文件系统中已经安装的软件包与版本,然后跟官方系统公布的信息比对,官方已经给出了在哪个系统版本上哪个软件版本有哪些漏洞,比如Debian 7系统上,nginx 1.12.1有哪些CVE漏洞,通过对逐个安装的软件包比对,就能知道当前这个镜像一共有多少CVE。当然,如果你是解压版的,那就没啥说的,这个跟windows类似,系统无法在控制面板识别。下面就harbor的具体流程进行简单介绍,让你对这个功能了如指掌。
在了解镜像扫描之前,这里先简单说下镜像的概念,镜像就是由许多Layer层组成的文件系统,重要的是每个镜像有一个manifest,这个东西跟springboot中的一个概念,就是文件清单的意思。一个镜像是由许多Layer组成,总需要这个manifest文件来记录下到底由哪几个层联合组成的。要扫描分析一个镜像,首先你就必须获取到这个镜像的manifest文件,通过manifest文件获取到镜像所有的Layer的地址digest,digest在docker镜像存储系统中代表的是一个地址,类似操作系统中的一个内存地址概念,通过这个地址,可以找到文件的内容,这种可寻址的设计是v2版本的重大改变。在docker hub储存系统中,所有文件都是有地址的,这个digest就是由某种高效的sha算法通过对文件内容计算出来的。
![]()
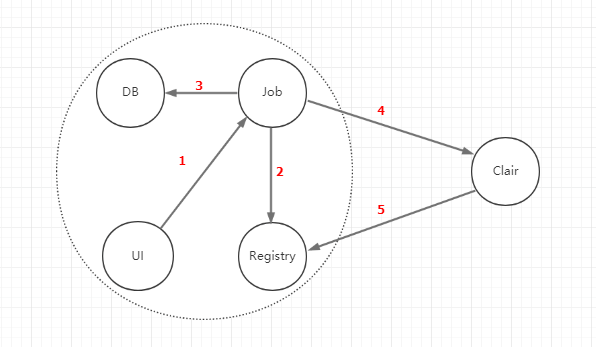
上图中虚线框中的模块是harbor自身功能,Clair是coreos开源的一个系统,镜像扫描分析工作主要由Clair完成,它具体的结构在下面再分析,这里先侧重分析harbor这块流程。箭头方向大致描述的是请求方向,系统之间交互可能产生多次请求。
1.UI向Job发起镜像扫描请求,参数中包含了仓库名称以及tag
2.Job收到请求之后,向registry发起一个Head请求(/v2/nginx/manifest/v1.12.1),判断当前镜像的manifest是否存在,取出当前manifest的digest,这个digest是存放在响应头中的Docker-Content-Digest。
3.Job把第2步获取到的digest以及仓库名、tag作为一条记录插入job表中,job的状态为pending。
这个时候Job系统则会新建一个扫描任务的job进行调度,这里则涉及到一个状态机处理流程。
4.Job系统通过manifest文件获取镜像的所有Layer digest,针对每一层,封装一个ClairLayer参数对象,然后根据层的数量,循环请求Clair系统,ClairLayer参数结构如下:
Name: sha256:7d99455a045a6c89c0dbee6e1fe659eb83bd3a19e171606bc0fd10eb0e34a7dc
Headers: tokenHeader,
Format: "Docker",
Path: http://registry:5000/v2/nginx/blobs/7d99455a045a6c89c0dbee6e1fe659eb83bd3a19e171606bc0fd10eb0e34a7dc
ParentName: a55bba68cd4925f13c34562c891c8c0b5d446c7e3d65bf06a360e81b993902e1
5.Clair系统收到请求之后,根据ParentName首先校验父Layer是否存在,不存在则报错。
下面详细讲解Clair漏洞分析流程。
1.下载镜像层文件
携带必要的headers发起对path的Get请求,得到的则是一个归档文件,然后进行解压。
2.探测镜像操作系统
遍历解压后的文件目录,探测操作系统文件路径。 首先要了解各Linux发行版的一些基础文件,比如系统版本、安装的软件包版本记录等文件。
centos:etc/os-release,usr/lib/os-release
查看文件/etc/os-release
NAME="CentOS Linux"
VERSION="7 (Core)"
ID="centos"
ID_LIKE="rhel fedora"
VERSION_ID="7"
PRETTY_NAME="CentOS Linux 7 (Core)"
ANSI_COLOR="0;31"
CPE_NAME="cpe:/o:centos:centos:7"
HOME_URL="https://www.centos.org/"
BUG_REPORT_URL="https://bugs.centos.org/"
CENTOS_MANTISBT_PROJECT="CentOS-7"
CENTOS_MANTISBT_PROJECT_VERSION="7"
REDHAT_SUPPORT_PRODUCT="centos"
REDHAT_SUPPORT_PRODUCT_VERSION="7"
clair逐行解析该文件,提取ID以及VERSION_ID字段,最终把centos:7作为clair中的一个namespace概念。
2.探测镜像已安装的软件包
上一步已经探测到了操作系统,自然可以知道系统的软件管理包是rpm还是dpkg。
debian, ubuntu : dpkg
centos, rhel, fedora, amzn, ol, oracle : rpm
centos系统的软件管理包是rpm,而debain系统的软件管理是dpkg。
rpm:var/lib/rpm/Packages
dpkg:var/lib/dpkg/status
apk:lib/apk/db/installed
比如debian系统,从文件/var/lib/dpkg/status文件则可以探测到当前系统安装了哪些版本的软件。
Package: sed
Essential: yes
Status: install ok installed
Priority: required
Section: utils
Installed-Size: 799
Maintainer: Clint Adams <clint@debian.org>
Architecture: amd64
Multi-Arch: foreign
Version: 4.4-1
Pre-Depends: libc6 (>= 2.14), libselinux1 (>= 1.32)
Description: GNU stream editor for filtering/transforming text
sed reads the specified files or the standard input if no
files are specified, makes editing changes according to a
list of commands, and writes the results to the standard
output.
Homepage: https://www.gnu.org/software/sed/
Package: libsmartcols1
Status: install ok installed
Priority: required
Section: libs
Installed-Size: 257
Maintainer: Debian util-linux Maintainers <ah-util-linux@debian.org>
Architecture: amd64
Multi-Arch: same
Source: util-linux
Version: 2.29.2-1+deb9u1
Depends: libc6 (>= 2.17)
Description: smart column output alignment library
This smart column output alignment library is used by fdisk utilities.
逐行解析文件,提取Package以及Version字段,最终获取 libsmartcols1 2.29-1+deb9u1以及sed等
3.保存信息
把上面探测到的系统版本、以及系统上安装的各种软件包版本都存入数据库。Clair系统已经获取了各linux版本操作系统软件版本,以及对应软件版本存在的CVE。官方公布了某个软件在某个版本修复了哪个CVE,Clair只需要将当前镜像中的软件的版本与官方公布的版本进行比较。比如官方维护的CVE信息中公布了nginx 1.13.1修复了漏洞CVE-2015-10203,那么当前镜像中包含的版本为1.12.1的nginx必然存在漏洞CVE-2015-10203,这些版本比较都是基于同一个版本的操作系统之上比较的。
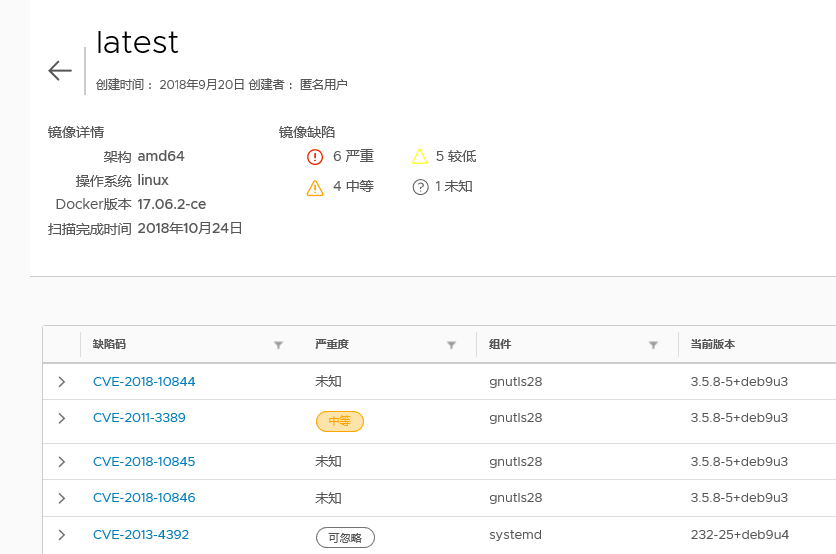
Harbor的Job系统发送完最后一层的请求之后,则会发起一个CVE分析结果的请求查询,生成一个扫描结果的概览保存在数据库中,主要是记录当前镜像发现了高风险漏洞多少个,中度风险多少个等。同时把job表中的状态设置为finished,如果请求Clair发生任何错误,则会把job记录设置为error。harbor页面具体的漏洞详细数据展示,还是通过UI系统调用Clair系统实时查询。
![]()
更多文章,请查看个人博客 https://youendless.com