大众点评评分爬取-图文识别ORC
十一了,没出去玩,因为老婆要加班,我陪着。
晚上的时候她说要一些点评的评分数据,我合计了一下scrapy request一下应该很好做,就答应下来了,感觉没什么难度嘛。
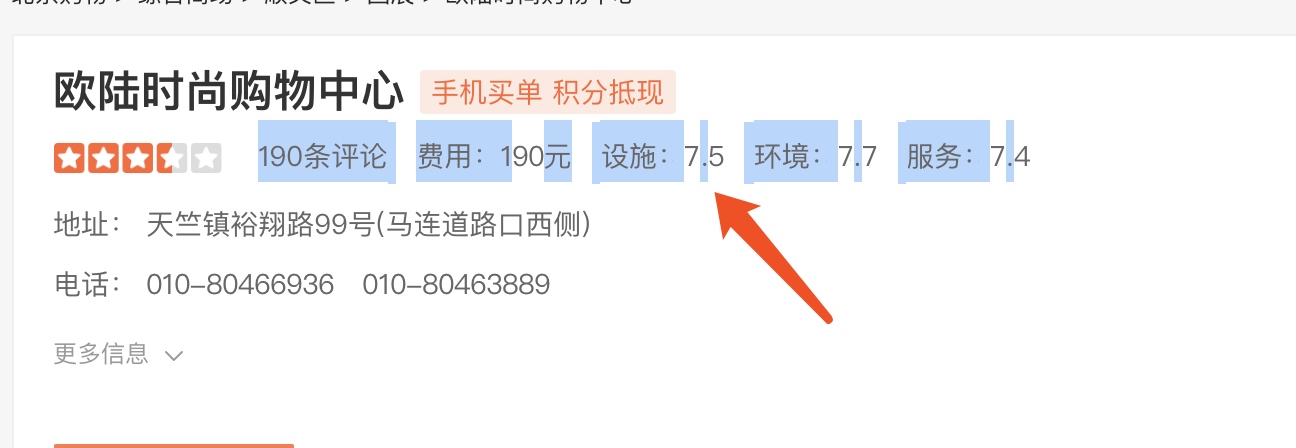
但是呢没那么简单。需要人验证的问题就不说了,我觉得这个我也解决不了,比较吸引我的是他的评分展现方式。
大众点评这块展示用的是图片,css offset方式 ![]()
![]()
selector那套行不通
这里我使用的 tesseract 图片文字识别
下面是大概流程
爬取页面
这里是使用Selenium进行页面访问,然后截屏
代码片段
opt = Options()
opt.add_argument('--headless')
self.driver = webdriver.Chrome(executable_path='/Users/xiangc/bin/chromedriver', options=opt)
self.wait = WebDriverWait(self.driver, 10)
self.driver.get('http://www.dianping.com/shop/4227604') self.driver.save_screenshot('image{}.png'.format(url_id))
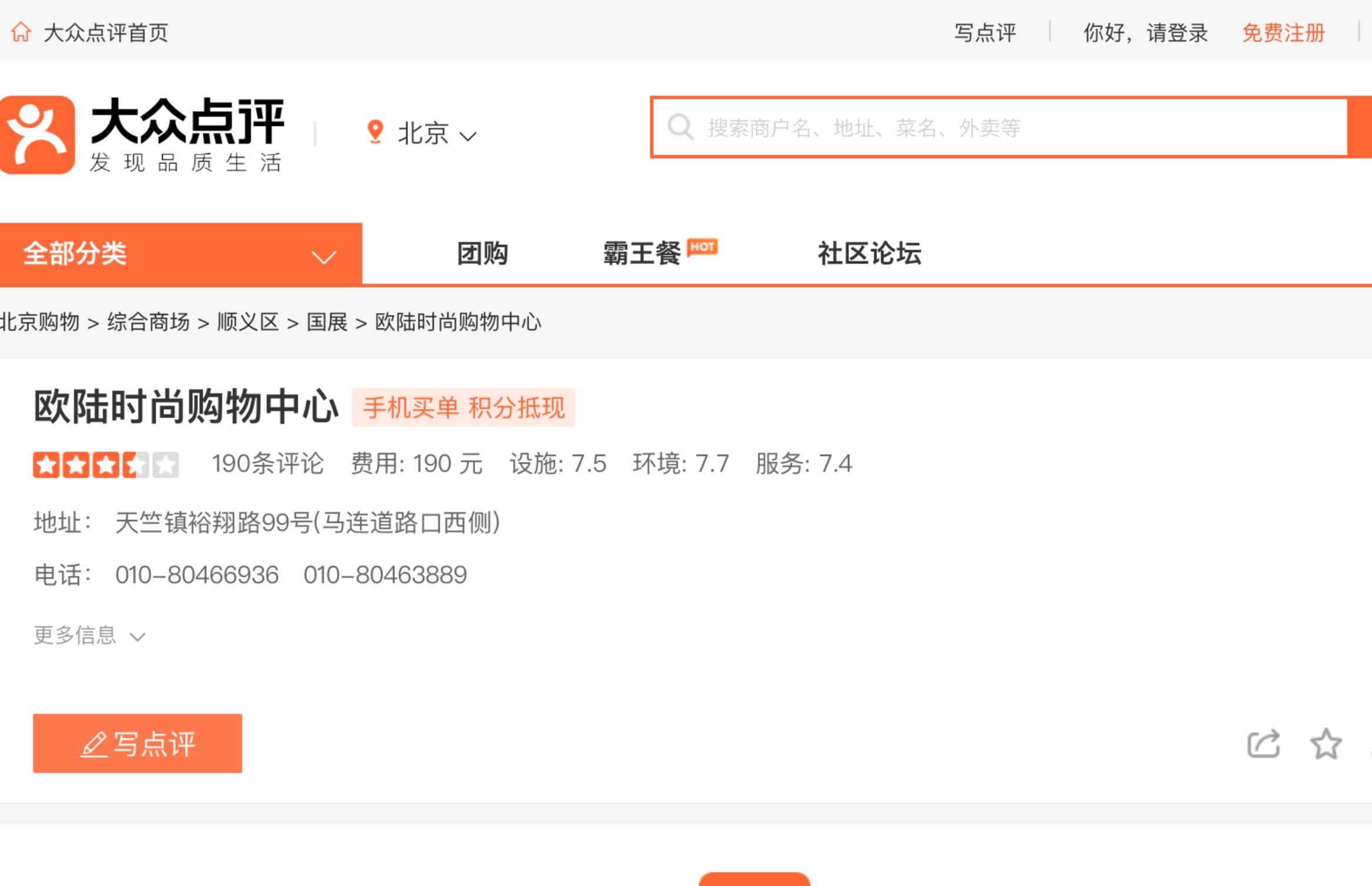
截屏页面
![]()
截取需要部分
代码片段如下,这里是hardcode,惭愧
cropped_img = im.crop((239, 500, 239 + 780, 500 + 63))
cropped_img.save('crop{}.png'.format(url_id))
![]()
图片预处理
图片预处理流程如下
- 清理噪点,如果一点四周只有一个非白点则为噪点,去掉
- 非空白点着色,色值大于200的点直接给白色
- 提高图片对比度
def get_color(image, x, y):
if isinstance(image, type(Image.new('RGB', (0, 0), 'white'))):
r, g, b = image.getpixel((x, y))[:3]
else:
r, g, b = image[x, y]
return r, g, b
def is_noise(image, x, y):
white_count = 0
for i in range(0, x + 2):
for j in range(0, y + 2):
r, g, b = get_color(image, i, j)
if (r, g, b) == (255, 255, 255):
white_count += 1
return white_count >= 7
def clear_noise(image, new_pixels):
w, h = image.size
clear_count = 0
for i in range(w):
for j in range(h):
r, g, b = get_color(image, i, j)
if r != g != b and is_noise(image, i, j):
clear_count += 1
print(clear_count)
new_pixels[i, j] = (255, 255, 255)
else:
new_pixels[i, j] = (r, g, b)
return clear_count
def clear_color(new_pixels, w, h):
for i in range(w):
for j in range(h):
r, g, b = get_color(new_pixels, i, j)
if np.average((r, g, b)) > 200:
new_pixels[i, j] = (255, 255, 255)
else:
new_pixels[i, j] = (0, 0, 0)
def pre_image(full_path):
image = Image.open(full_path)
w, h = image.size
new_image = Image.new('RGB', (w, h), 'white')
new_pixels = new_image.load()
clear_count = clear_noise(image, new_pixels)
while clear_count > 0:
clear_count = clear_noise(new_pixels, new_pixels)
print(clear_count)
if clear_count == 0:
break
clear_color(new_pixels, w, h)
# 对比度增强
enh_img = ImageEnhance.Contrast(new_image)
contrast = 3
image_contrasted = enh_img.enhance(contrast)
dir_name = os.path.dirname(full_path)
file_name = os.path.basename(full_path)
new_file_path = os.path.join(dir_name, 'sharped' + file_name)
image_contrasted.save(new_file_path)
return new_file_path
图片文字识别
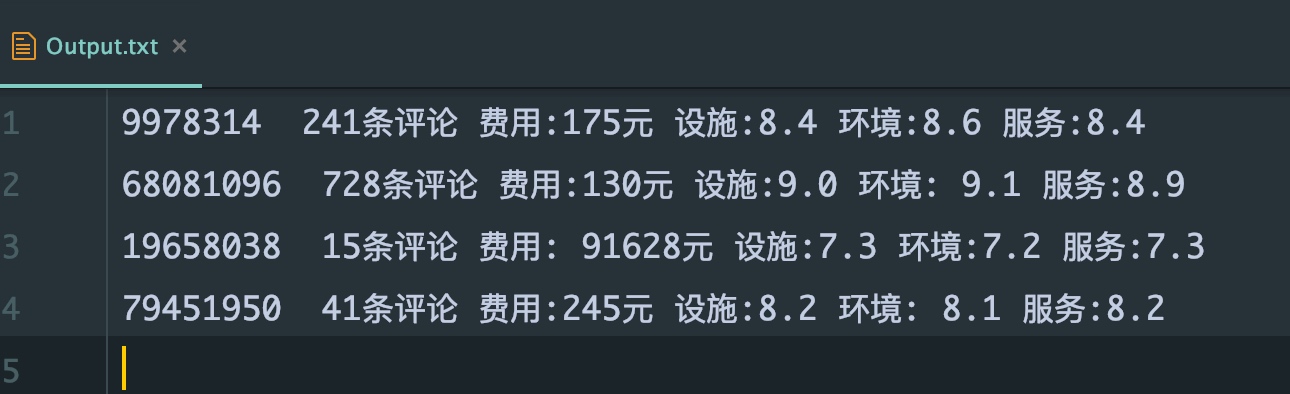
文字识别是用tesseract
注意这里加了白名单提高准确率
chi为我自己训练的识别库,训练集为10个
new_file_path = imgutils.pre_image('crop{}.png'.format(url_id))
result = pytesseract.image_to_string(
image=new_file_path,
lang='chi',
config='--psm 7 --oem 3 -c tessedit_char_whitelist=0123456789评论服务:费用设施环境条.元'
结果
还凑合哦
![]()
训练辅助脚本
下面是一些脚本集合
- 生成box文件
- 批量图片处理
- 批量训练生成训练结果文件
- 批量图片格式转换png->tiff
都是js和python脚本,比较简单哈~
gitee链接
爬虫代码就不放了哈~写的太丑~目前也没时间做代码优化。
由于python注释和Markdown的代码tag重复了,注释都去掉了,相信大家能看懂哈~