版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq1010885678/article/details/45788083
整个Spark框架都是基于RDD算子来进行计算的。
What is RDD?
Resilient Distributed Dataset(RDD),分布式弹性数据集,是Spark上的一个核心抽象
表示用于并行计算的,不可修改的,对数据集合进行分片的数据结构
简单地,可以将RDD看成是Spark平台上的通用货币
在Spark上,针对各种各样的计算场景存在着各种各种的RDD,这些RDD拥有一些共同的操作,例如map,filter,persist等,就好像RDDs都是一个总RDD的子类一样,拥有所有RDD的共同特性
同时RDDs也拥有能表达自己特性的操作,例如PairRDDR有groupByKey,join等操作,而DoubleRDD有Doubles操作
所有的RDD都有以下特性:
可以表示数据分片的列表集合。将原始数据经过某些分片处理生成RDDs,这些RDD将用于并行计算
通用的算子来计算每个数据分片
包括transformation和action两大算子类别。
RDD之间拥有依赖关系
transformation只对数据进行处理而不计算,处理过程会被画成一个DAG有向无循环图,只有当action操作要获取结果时,才根据DAG图来进行并行计算。
DAG图会根据RDD之间的依赖关系被分解成一个个stage之后提交
形成DAG图的过程中也会根据RDD之间的依赖关系形成Lineage
这是Spark上一个重要的容错机制
当某个节点计算错误时,只需要根据Lineage重新计算相关的操作而不必回滚整个程序
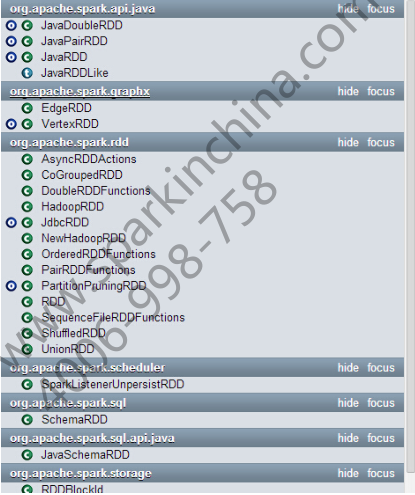
以下两张图是来源自网络的
Spark中部分RDD类的截图
transformation和action操作的Function截图
![这里写图片描述]()
![这里写图片描述]()
除了transformation和action两大类算子之外,RDD还有一个比较特殊的算子
如persist和checkpoint,它们既不属于transformation也不属于action
但是都会触发Job的运行
persist将RDD结果持久化,修改了RDD中meta info的存储级别
checkpoint在持久化RDD的同时还切断了RDD之间的依赖血缘关系。除了修改了存储级别,还修改了meta info中RDD的lineage依赖关系
两者返回的均是修改后的RDD而不是产生的RDD(transformation是产生新的RDD,action是对RDD取结果)
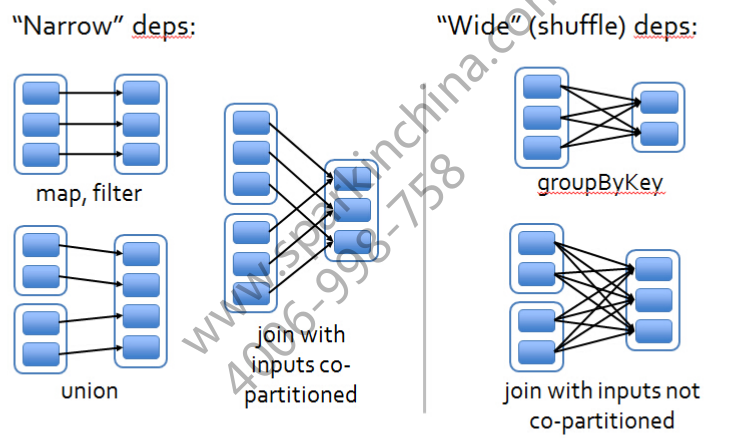
RDD之间的依赖关系可以分为Narrow,Wide:窄依赖和宽依赖两种
窄依赖:子RDD中的每个数据块只依赖于父RDD中对应的有限个固定的数据块,可以理解成父子RDD是一对一或者多对一的关系,例如:map变换,前后的数据都是一行对一行的。一个子RDD可以根据其父RDD直接计算得出,因而子RDD出现计算错误的时候,只需要重新计算对应的父RDD即可
宽依赖:子RDD中的一个数据块可以依赖于父RDD中的所有数据块。即一对多的情况,例如:groupByKey变换,子RDD中的数据块会依赖于多个父RDD中的数据块,因为一个key可能存在于父RDD的任何一个数据块中 。宽依赖中的子RDD要等到所有的父RDD计算完成之后才能进行计算,当数据丢失时需要对所有祖先RDD进行重新计算
依赖关系图:
![这里写图片描述]()
其中,宽依赖是会触发shuffle行为的
而shuffle操作可以减小集群之间网络传输的压力,对数据进行一定的提前处理工作,对于提高整个集群的处理性能是十分重要的
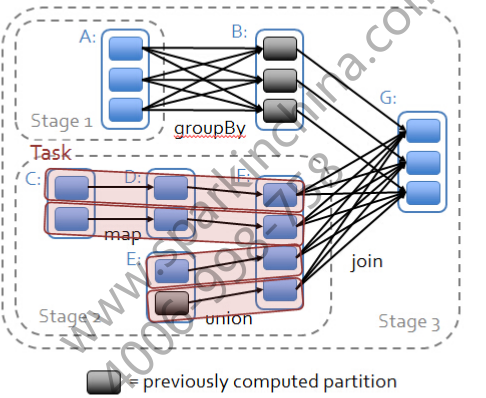
在Spark中shuffle操作会是将DAG图划分成一个个stage的起点
如图所示:
![这里写图片描述]()
map和union是属于transformation操作的。这里会涉及到一个pipeline的概念,对数据切片之后并行协同计算,从图中我们可以看到,map和union的时候Task之间的处理是并行的,而协同体现在当某个Task计算缓慢的时候,集群会启动一个新的节点来计算该Task,哪个节点先处理完毕就采用哪个节点的结果
groupBy和join操作是产生RDD之间的宽依赖的,这是一个shuffle过程,也是触发划分stages的起点,如上图中的三个stage
从物理的角度看RDD其实是一个元数据结构,存储着Block和Node之间的映射关系
关于Spark的transformation,action和划分stage等过程都是怎么处理的,整个作业的处理流程是什么,请看:
Spark(四) – Spark内核作业调度机制